.NET效能系列文章一:.NET7的效能改進
這些方法在.NET7中變得更快

照片來自 CHUTTERSNAP 的 Unsplash
歡迎閱讀.NET效能系列的第一章。這一系列的特點是對.NET世界中許多不同的主題進行研究、比較效能。正如標題所說的那樣,本章節在於.NET7中的效能改進。你將看到哪種方法是實現特定功能最快的方法,以及大量的技巧和敲門,如何付出較小的代價就能最大化你程式碼效能。如果你對這些主題感興趣,那請您繼續關注。
.NET 7目前(17.10.2022)處於預覽階段,將於2022年11月釋出。通過這個新版本,微軟提供了一些大的效能改進。這篇 .NET效能系列的第一篇文章,是關於從.NET6到.NET7最值得注意的效能改進。
LINQ
最相關的改進肯定是在LINQ中,在.NET 7中dotnet社群利用LINQ中對數位陣列的處理來使用Vector<T>(SIMD)。這大大改善了一些LINQ方法效能,你可以在List<int>或int[]以及其他數位集合上呼叫。現在LINQ方法也能直接存取底層陣列,而不是使用列舉元存取。讓我們來看看這些方法相對於.NET 6是如何表現的。
我使用BenchmarkDotNet來比較.NET6和.NET7相同程式碼的效能。
1. Min 和 Max 方法
首先是LINQ方法Min()和Max()。它們被用來識別數位列舉中的最低值或最高值。新的實現特別要求有一個先前列舉的集合作為源,因此我們必須在這個基準測試中建立一個陣列。
[Params(1000)]
public int Length { get; set; }
private int[] arr;
[GlobalSetup]
public void GlobalSetup() => arr = Enumerable.Range(0, Length).ToArray();
[Benchmark]
public int Min() => arr.Min();
[Benchmark]
public int Max() => arr.Max();
在.NET 6和.NET 7上執行這些基準,在我的機器上會得出以下結果。
| 方法 | 執行時 | 陣列長度 | 平均值 | 比率 | 分配 |
|---|---|---|---|---|---|
| Min |  |
1000 | 3,494.08 ns | 53.24 | 32 B |
| Min |  |
1000 | 65.64 ns | 1.00 | - |
| Max | |
1000 | 3,025.41 ns | 45.92 | 32 B |
| Max | |
1000 | 65.93 ns | 1.00 | - |
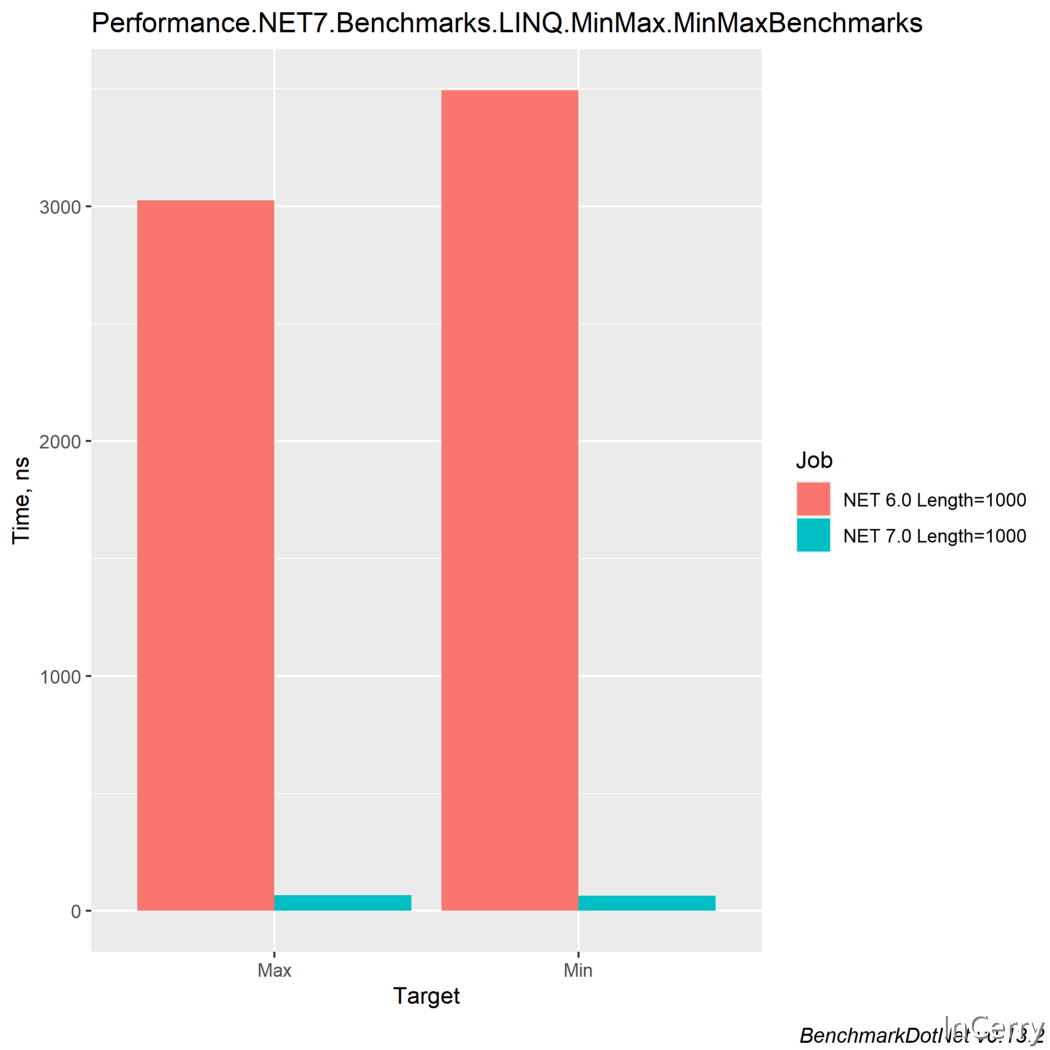
這裡非常突出的是新的.NET7所展示的效能改進有多大。我們可以看到與.NET 6相比,改進幅度超過4500%。這不僅是因為在內部實現中使用了另一種型別,而且還因為不再發生額外的堆記憶體分配。
2. Average 和 Sum
另一個很大的改進是Average()和Sum()方法。當處理大的double集合時,這些效能優化能展現出更好的結果,這就是為什麼我們要用一個double[]來測試它們。
[Params(1000)]
public int Length { get; set; }
private double[] arr;
[GlobalSetup]
public void GlobalSetup()
{
var random = new Random();
arr = Enumerable
.Range(0, Length)
.Select(_ => random.NextDouble())
.ToArray();
}
[Benchmark]
public double Average() => arr.Average();
[Benchmark]
public double Sum() => arr.Sum();
結果顯示,效能顯著提高了500%以上,而且同樣沒有了記憶體分配!
| 方法 | 執行時 | 陣列長度 | 平均值 | 比率 | 分配 |
|---|---|---|---|---|---|
| Average | |
1000 | 3,438.0 ns | 5.50 | 32 B |
| Average | |
1000 | 630.3 ns | 1.00 | - |
| Sum | |
1000 | 3,303.8 ns | 5.25 | 32 B |
| Sum | |
1000 | 629.3 ns | 1.00 | - |
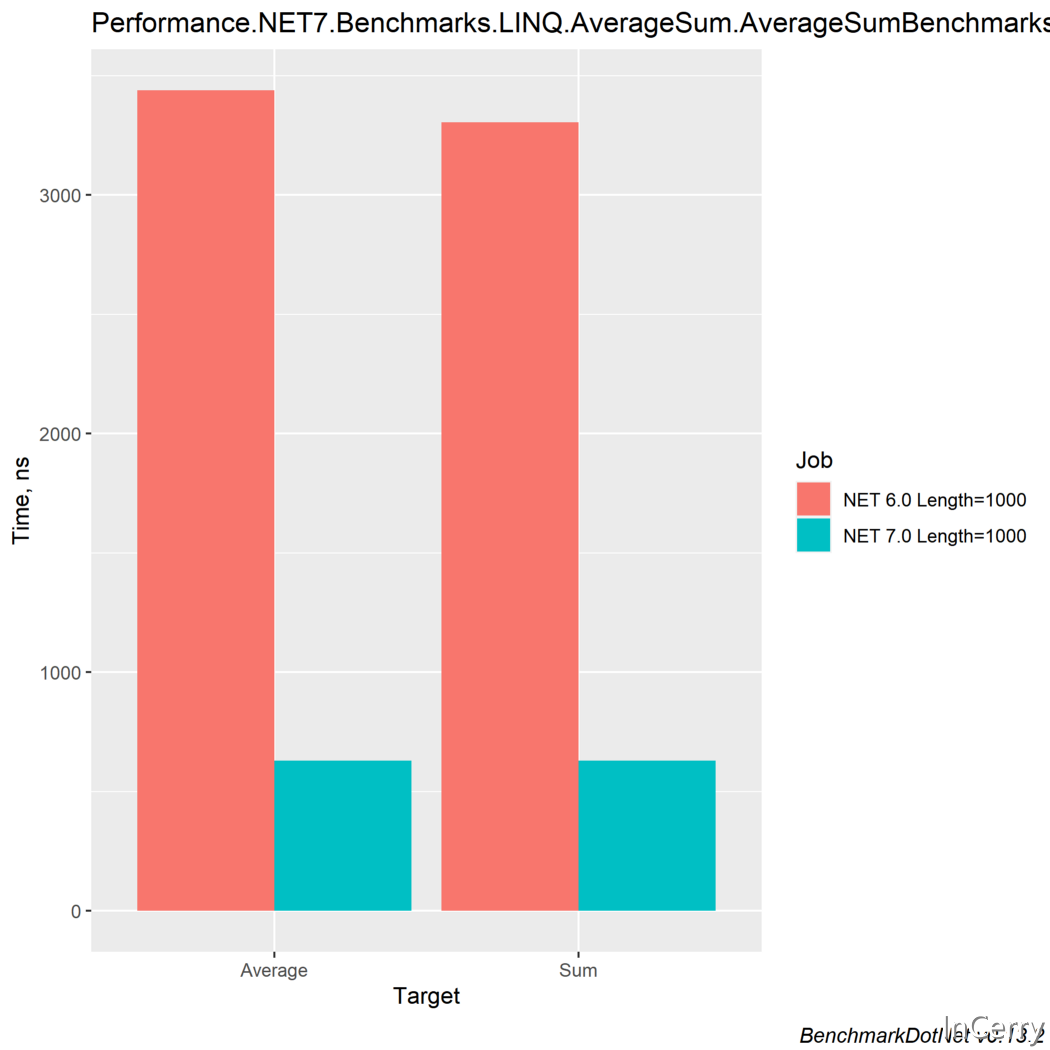
這裡的效能提升並不像前面的例子那麼突出,但還是非常高的!
3. Order
接下來是這是新增了兩個排序方法Order()和OrderDescending()。當你不想對映到IComparable 型別時,應該使用新的方法取代.NET7中舊的OrderBy()和OrderByDescending()方法。
[Params(1000)]
public int Length { get; set; }
private double[] arr;
[GlobalSetup]
public void GlobalSetup()
{
var random = new Random();
arr = Enumerable
.Range(0, Length)
.Select(_ => random.NextDouble())
.ToArray();
}
[Benchmark]
public double[] OrderBy() => arr.OrderBy(d => d).ToArray();
#if NET7_0
[Benchmark]
public double[] Order() => arr.Order().ToArray();
#endif
| 方法 | 陣列長度 | 平均值 | 分配 |
|---|---|---|---|
| OrderBy | 1000 | 51.13 μs | 27.61 KB |
| Order | 1000 | 50.82 μs | 19.77 KB |
在這個基準中,只使用了.NET 7,因為Order()方法在舊的執行時中不可用。
我們無法看到這兩種方法之間的效能影響。然而,我們可以看到的是在堆記憶體分配方面有很大的改進,這將顯著減少垃圾收集,從而節省一些GC時間。
System.IO
在.NET 7中,Windows下的IO效能有了些許改善。WriteAllText()方法不再使用那麼多分配的記憶體,ReadAllText()方法與.NET 6相比也快了一些。
[Benchmark]
public void WriteAllText() => File.WriteAllText(path1, content);
[Benchmark]
public string ReadAllText() => File.ReadAllText(path2);
| 方法 | 執行時 | 平均值 | 比率 | 分配 |
|---|---|---|---|---|
| WriteAllText | |
193.50 μs | 1.03 | 10016 B |
| WriteAllText | |
187.32 μs | 1.00 | 464 B |
| ReadAllText | |
23.29 μs | 1.08 | 24248 B |
| ReadAllText | |
21.53 μs | 1.00 | 24248 B |
序列化 (System.Text.Json)
來自System.Text.Json名稱空間的JsonSerializer得到了一個小小的升級,一些使用了反射的自定義處理程式會在幕後為你快取,即使你初始化一個JsonSerialzierOptions的新範例。
private JsonSerializerOptions options = new JsonSerializerOptions();
private TestClass instance = new TestClass("Test");
[Benchmark(Baseline = true)]
public string Default() => JsonSerializer.Serialize(instance);
[Benchmark]
public string CachedOptions() => JsonSerializer.Serialize(instance, options);
[Benchmark]
public string NoCachedOptions() => JsonSerializer.Serialize(instance, new JsonSerializerOptions());
public record TestClass(string Test);
在上面程式碼中,對NoCachedOptions()的呼叫通常會導致JsonSerialzierOptions的額外範例化和一些自動生成的處理程式。在.NET 7中這些範例是被快取的,當你在程式碼中使用這種方法時,你的效能會好一些。否則,無論如何都要快取你的JsonSerialzierOptions,就像在CachedOptions例子中,你不會看到很大的提升。
| 方法 | 執行時 | 平均值 | 比率 | 分配 | 分配比率 |
|---|---|---|---|---|---|
| Default | |
135.4 ns | 1.04 | 208 B | 3.71 |
| CachedOptions | |
145.9 ns | 1.12 | 208 B | 3.71 |
| NoCachedOptions | |
90,069.7 ns | 691.89 | 7718 B | 137.82 |
| Default | |
130.2 ns | 1.00 | 56 B | 1.00 |
| CachedOptions | |
129.8 ns | 0.99 | 56 B | 1.00 |
| NoCachedOptions | |
533.8 ns | 4.10 | 345 B | 6.16 |
基本型別
1. Guid 相等比較
有一項改進,肯定會導致現代應用程式的效能大增,那就是對Guid相等比較的新實現。
private Guid guid0 = Guid.Parse("18a2c952-2920-4750-844b-2007cb6fd42d");
private Guid guid1 = Guid.Parse("18a2c952-2920-4750-844b-2007cb6fd42d");
[Benchmark]
public bool GuidEquals() => guid0 == guid1;
| 方法 | 執行時 | 平均值 | 比率 |
|---|---|---|---|
| GuidEquals | |
1.808 ns | 1.49 |
| GuidEquals | |
1.213 ns | 1.00 |
可以感覺到,新的實現也使用了SIMD,比舊的實現快30%左右。

由於有大量的API使用Guid作為實體的識別符號,這肯定會積極的產生影響。
2. BigInt 解析
一個很大的改進發生在將巨大的數位從字串解析為BigInteger型別。就我個人而言,在一些區塊鏈專案中,我曾使用過BigInteger型別,在那裡有必要使用這種型別來表示ETH代幣的精度。所以在效能方面,這對我來說會很方便。
private string bigIntString = string.Concat(Enumerable.Repeat("123456789", 100000));
[Benchmark]
public BigInteger ParseBigInt() => BigInteger.Parse(bigIntString);
| 方法 | 執行時 | 平均值 | 比率 | 分配 |
|---|---|---|---|---|
| ParseBigInt | |
2.058 s | 1.62 | 2.09 MB |
| ParseBigInt | |
1.268 s | 1.00 | 2.47 MB |
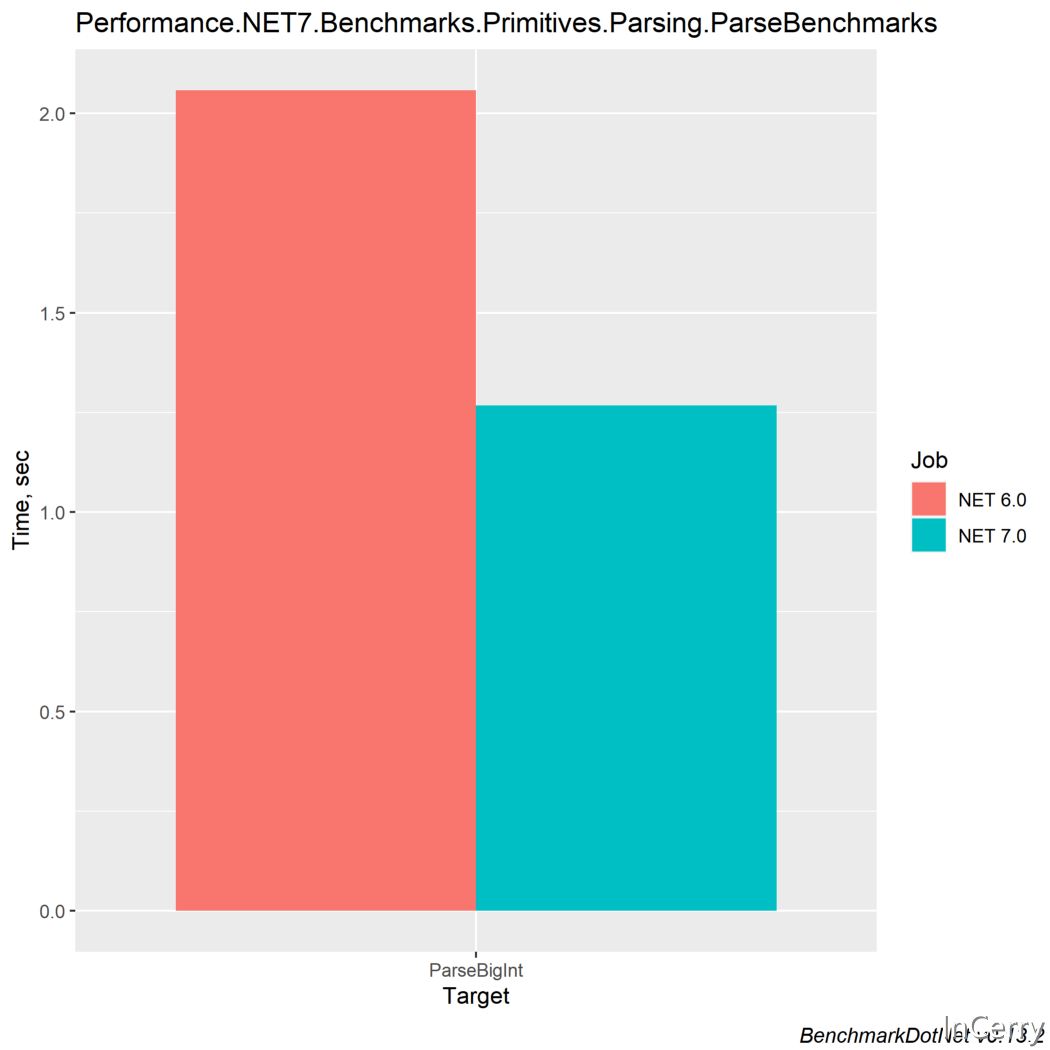
我們可以看到效能有了明顯的提高,不過我們也看到它比.NET6上多分配一些記憶體。
3. Boolean 解析
對於解析boolean型別,我們也有顯著的效能改進:
[Benchmark]
public bool ParseBool() => bool.TryParse("True", out _);
| 方法 | 執行時 | 平均值 | 比率 |
|---|---|---|---|
| ParseBool | |
8.164 ns | 5.21 |
| ParseBool | |
1.590 ns | 1.00 |
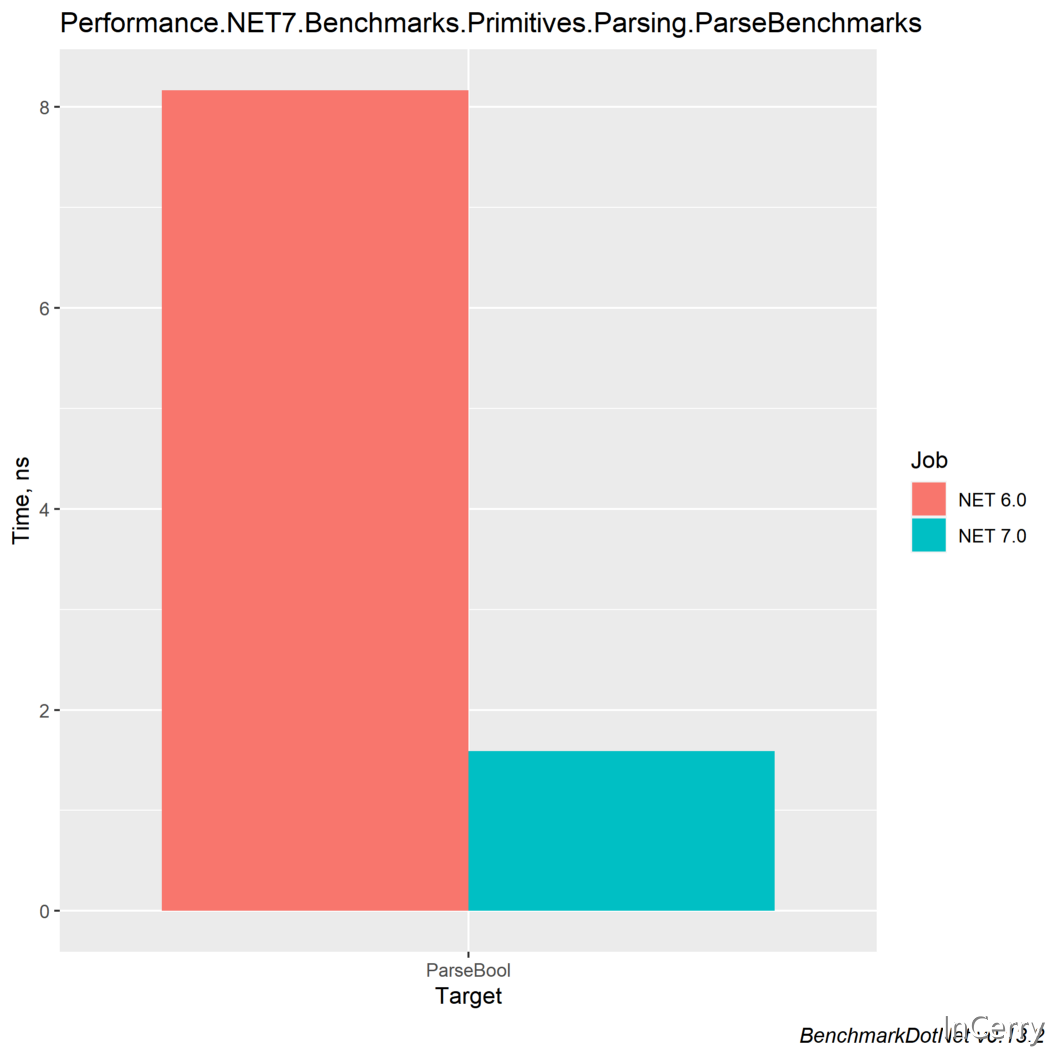
診斷
System.Diagnostics名稱空間也進行了升級。程序處理有兩個重大改進,Stopwatch有一個新功能。
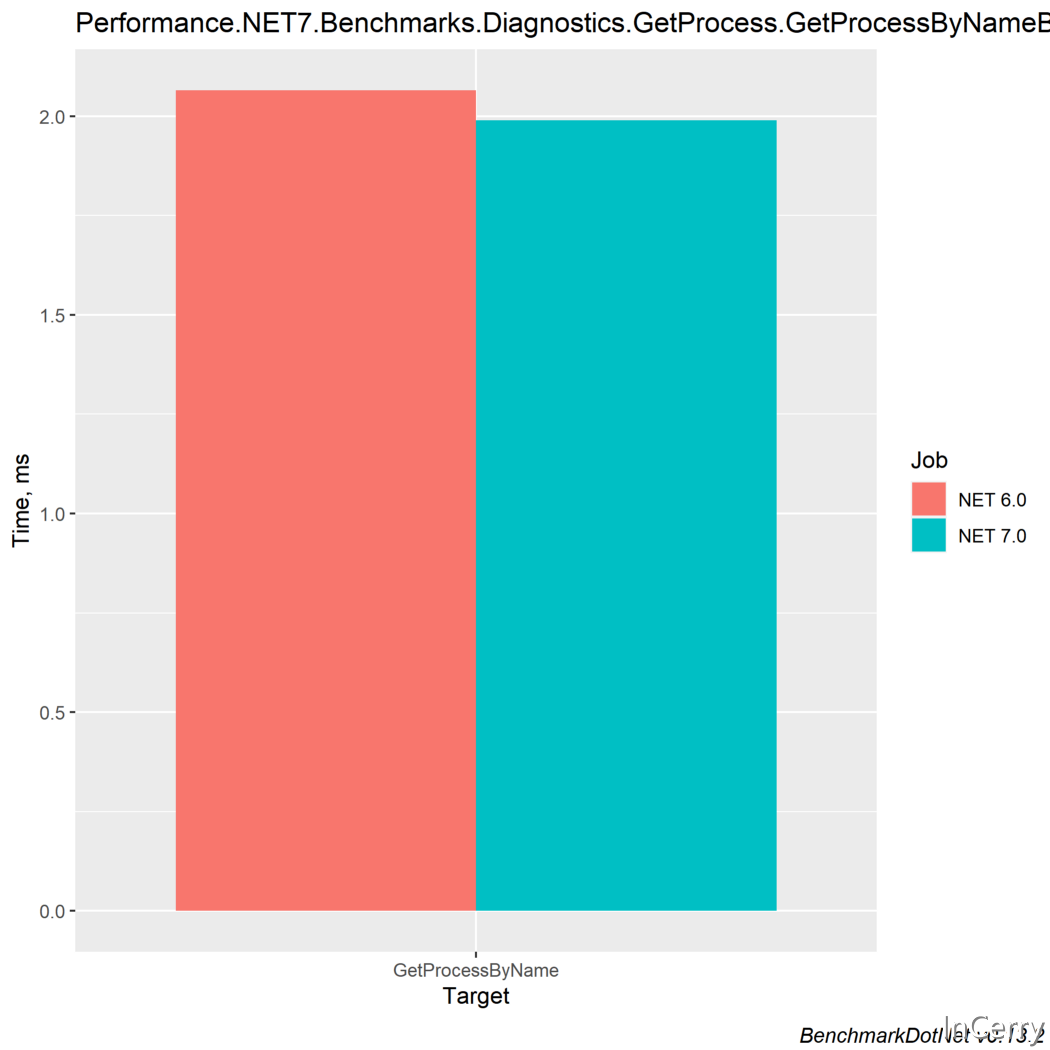
1. GetProcessByName
[Benchmark]
public Process[] GetProcessByName()
=> Process.GetProcessesByName("dotnet.exe");
| 方法 | 執行時 | 平均值 | 比率 | 分配 | 分配比率 |
|---|---|---|---|---|---|
| GetProcessByName | |
2.065 ms | 1.04 | 529.89 KB | 247.31 |
| GetProcessByName | |
1.989 ms | 1.00 | 2.14 KB | 1.00 |
新的GetProcessByName()的速度並不明顯,但使用的分配記憶體比前者少得多。
2. GetCurrentProcessName
[Benchmark]
public string GetCurrentProcessName()
=> Process.GetCurrentProcess().ProcessName;
| 方法 | 執行時 | 平均值 | 比率 | 分配 | 分配比率 |
|---|---|---|---|---|---|
| GetCurrentProcessName | |
1,955.67 μs | 103.02 | 3185 B | 6.98 |
| GetCurrentProcessName | |
18.98 μs | 1.00 | 456 B | 1.00 |
在這裡,我們可以看到一個更有效的記憶體方法,對.NET 7的實現有極高的效能提升。

3. Stopwatch
Stopwatch被廣泛用於測量執行時的效能。到目前為止,存在的問題是,使用Stopwatch需要分配堆記憶體。為了解決這個問題,dotnet社群實現了一個靜態函數GetTimestamp(),它仍然需要一個複雜的邏輯來有效地獲得時間差。現在又實現了另一個靜態方法,名為GetElapsedTime(),在這裡你可以傳遞之前的時間戳,並在不分配堆記憶體的情況下獲得經過的時間。
[Benchmark(Baseline = true)]
public TimeSpan OldStopwatch()
{
Stopwatch sw = Stopwatch.StartNew();
return sw.Elapsed;
}
[Benchmark]
public TimeSpan NewStopwatch()
{
long timestamp = Stopwatch.GetTimestamp();
return Stopwatch.GetElapsedTime(timestamp);
}
| Method | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|
| OldStopwatch | 39.44 ns | 1.00 | 40 B | 1.00 |
| NewStopwatch | 37.13 ns | 0.94 | - | 0.00 |
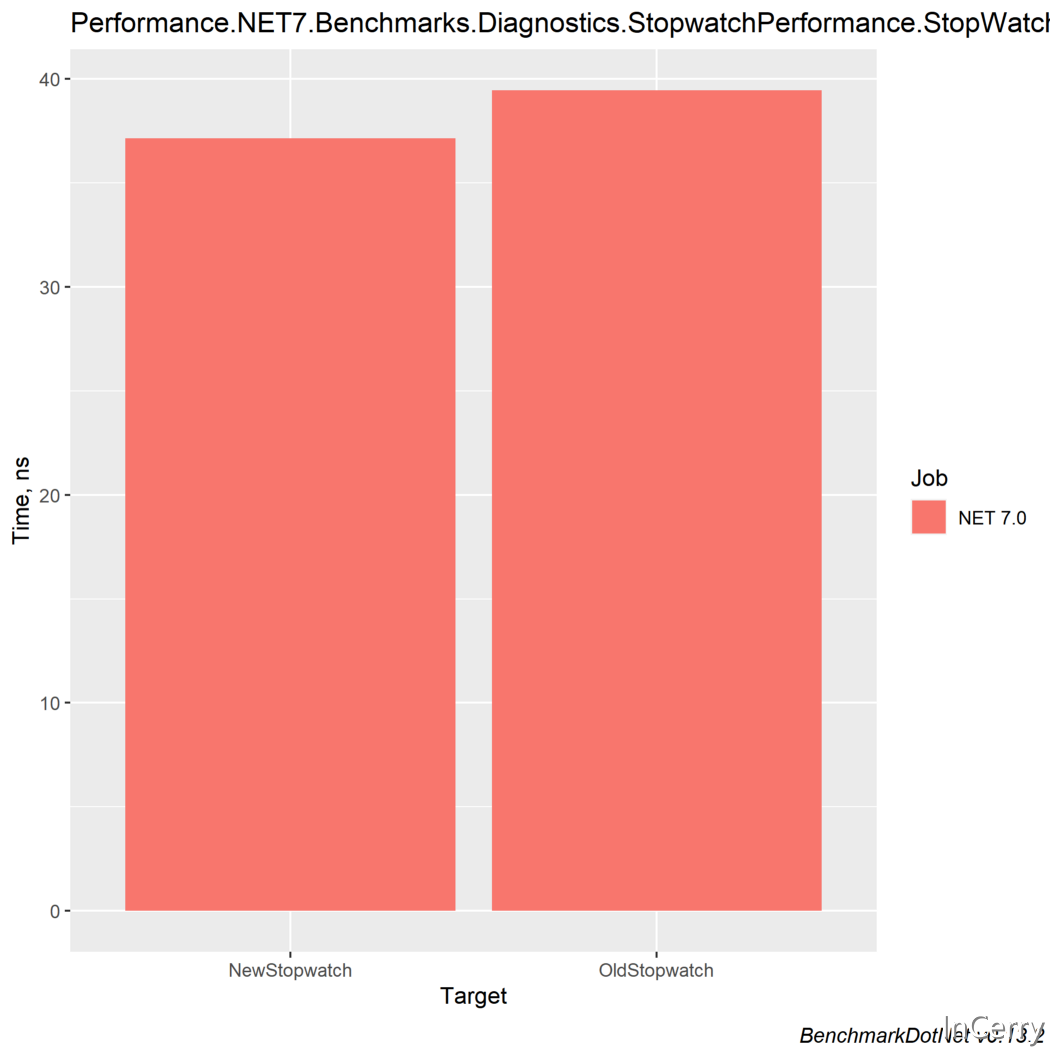
這種方法的速度優化並不明顯,然而節省堆記憶體分配可以說是值得的。
結尾
我希望,我可以在效能和基準測試的世界裡給你一個有趣的切入點。如果你關於特定效能主題想法,請在評論中告訴我。
如果你喜歡這個系列的文章,請務必關注我,因為還有很多有趣的話題等著你。
謝謝你的閱讀!
版權
原文版權:Tobias Streng
翻譯版權:InCerry
原文連結:
https://medium.com/@tobias.streng/net-performance-series-1-performance-improvements-in-net-7-fb793f8f5f71