說說 Redis pipeline
更多技術文章,請關注我的個人部落格 www.immaxfang.com 和小公眾號
Max的學習札記。
Redis 使用者端和伺服器端之間是採用 TCP 協定進行通訊的,是基於 Request/Response 這種一問一答的模式,即請求一次響應一次。
普通模式
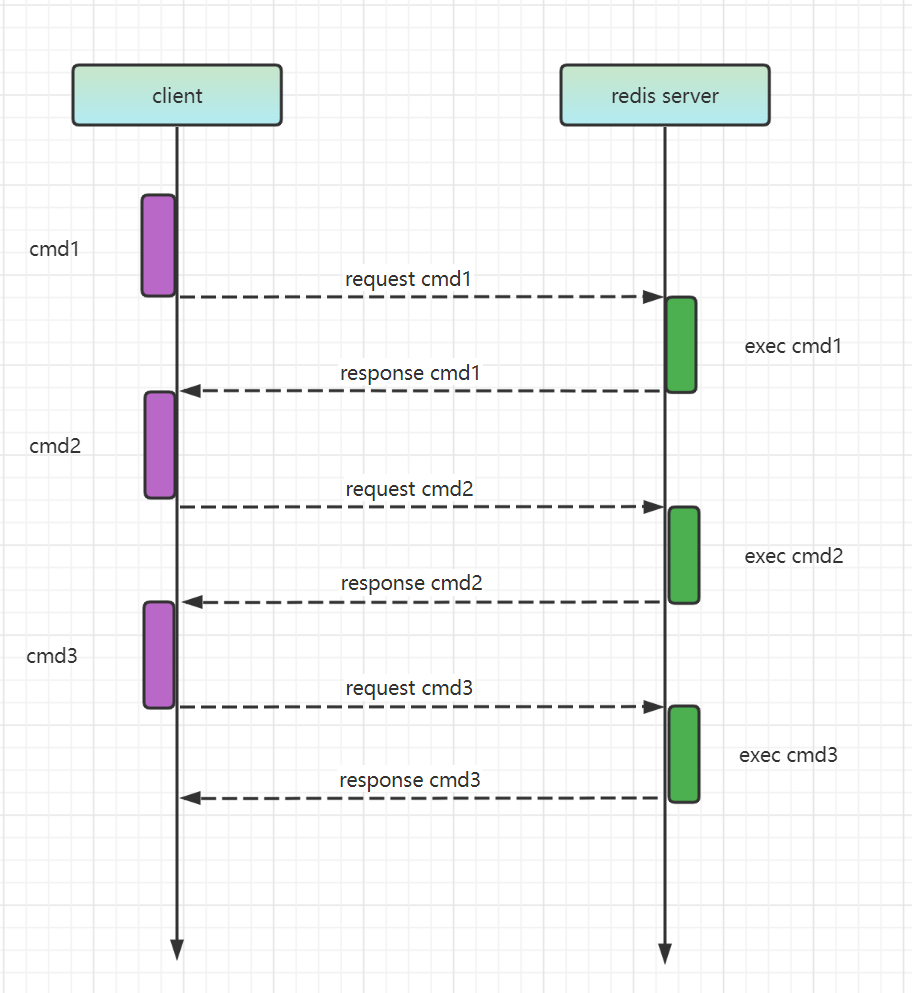
我們先來看下普通模式下,一條 Redis 命令的簡要執行過程:
- 使用者端傳送一條命令給 redis-server,阻塞等待 redis-server 應答
- redis-server 接收到命令,執行命令
- redis-server 將結果返回給使用者端
下面我們來簡要了解下一個完整請求的互動過程。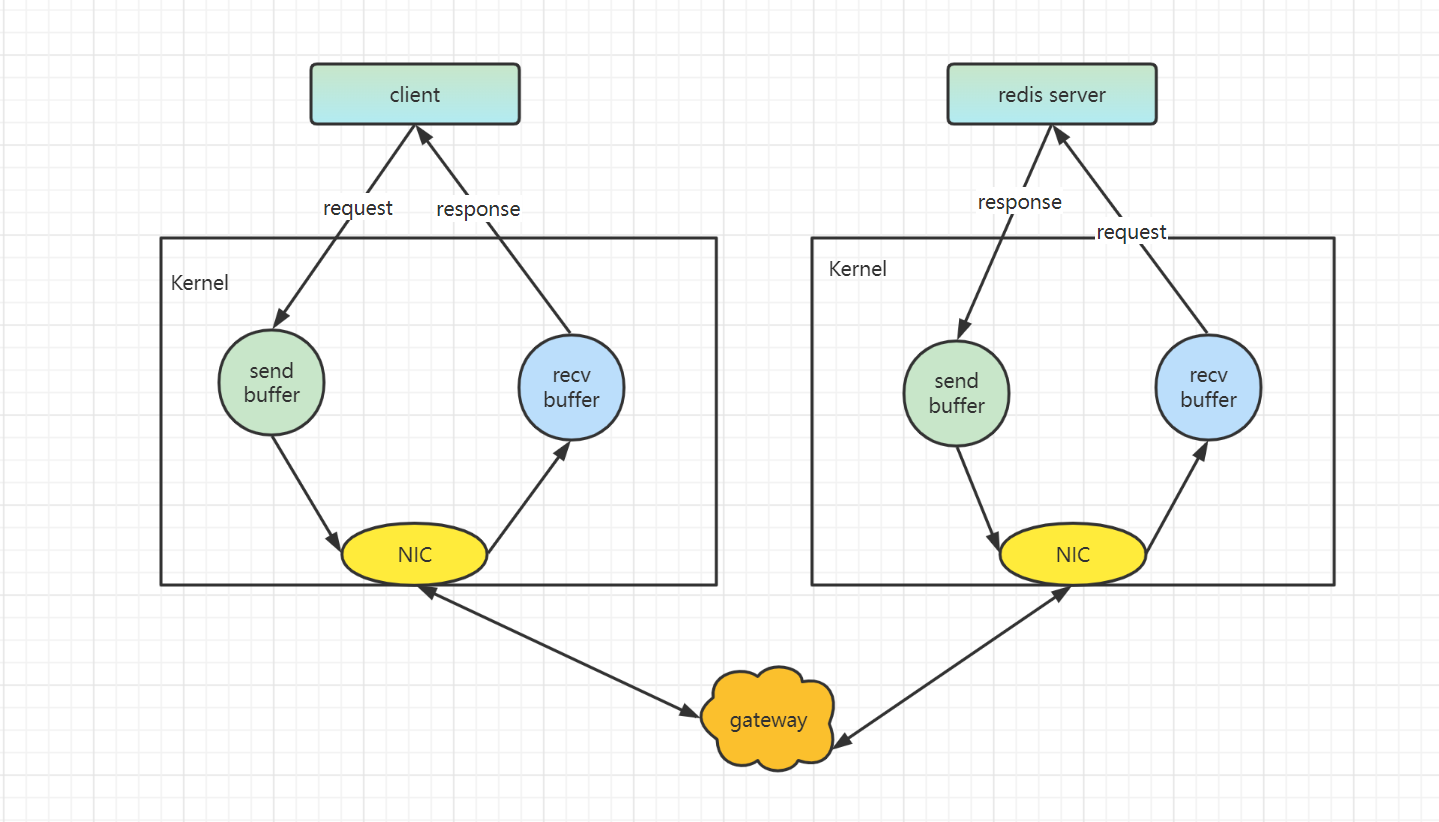
- 使用者端呼叫 write() 將訊息寫入作業系統為 socket 分配的 send buffer 中
- 作業系統將 send buffer 中的內容傳送到網路卡,網路卡通過閘道器路由把內容傳送到伺服器網路卡
- 伺服器網路卡將接受到的訊息寫入作業系統為 socket 分配的 recv buffer
- 伺服器程序呼叫 read() 從 recv buffer 中讀取訊息進行處理
- 處理完成之後,伺服器呼叫 write() 將響應內容傳送的 send buffer 中
- 伺服器將 send buffer 中的內容通過網路卡,傳送到使用者端
- 使用者端作業系統將網路卡中的內容放入 recv buffer 中
- 使用者端程序呼叫 read() 從 recv buffer 中讀取訊息
普通模式的問題
我們來想一下,這種情況下可能導致什麼問題。
如果同時執行大量的命令,那對於每一個命令,都要按上面的流程走一次,當前的命令需要等待上一條命令執行應答完畢之後,才會執行。這個過程中會有多次的 RTT ,也還會伴隨著很多的 IO 開銷,傳送網路請求等。每條命令的傳送和接收的過程都會佔用兩邊的網路傳輸。
簡單的來說,每個命令的執行時間 = 使用者端傳送耗時 + 伺服器處理耗時 + 伺服器返回耗時 + 一個網路來回耗時。
在這裡,一個 網路來回耗時(RTT) 是不好控制的,也是不穩定的。它的影響因素很多,比如使用者端到伺服器的網路線路是否擁堵,經過了多少跳。還有就是 IO 系統呼叫也是耗時的,一個 read 系統呼叫,需要從使用者態,切換到核心態。上文我們講述一個命令的請求過程時多次降到 read 和 write 系統呼叫。
可以說一個命令的執行時間,很大程度上受到它們的限制。
pipeline 模式
有沒有什麼方法來解決這種問題呢。
第一種方法,就是利用多執行緒機制,並行執行命令。
第二種方法,呼叫批次命令,例如 mget等,一次操作多個鍵。
很多時候我們要執行的命令並不是一樣的命令,而是一組命令,這個時候就無法使用類似 mget這樣的批次命令了。那還有其他的方法嗎?
回想一下,我們初學程式設計的時候,老手都會告訴我們,不要在迴圈裡面做查詢。我有一個 books 列表資料,要根據 book_id 查詢它們的 price,如果我們迴圈 books 列表,在每次迴圈裡面取查詢單個 book_id 的 price,那效能肯定是不理想的。一般我們的優化方式是將多個 book_id 取出來,一次性去查多個 book_id 的 price,這樣效能就有明顯的提示。即將多次小命令中的耗時操作合併到一次,從而減少總的執行時間。
類似的,Redis pipeline 出現了,一般稱之為管道。它允許使用者端一次可以傳送多條命令,而不用像普通模式那樣每次執行一個小命令都要等待前一個小命令執行完,伺服器在接收到一堆命令後,會依次執行,然後把結果打包,再一次性返回給使用者端。
這樣可以避免頻繁的命令傳送,減少 RTT,減少 IO 呼叫次數。前面已經介紹了,IO 呼叫會涉及到使用者態和核心態之間的切換,在高效能的一些系統中,我們都是儘可能的減少 IO 呼叫。
簡要流程如下圖: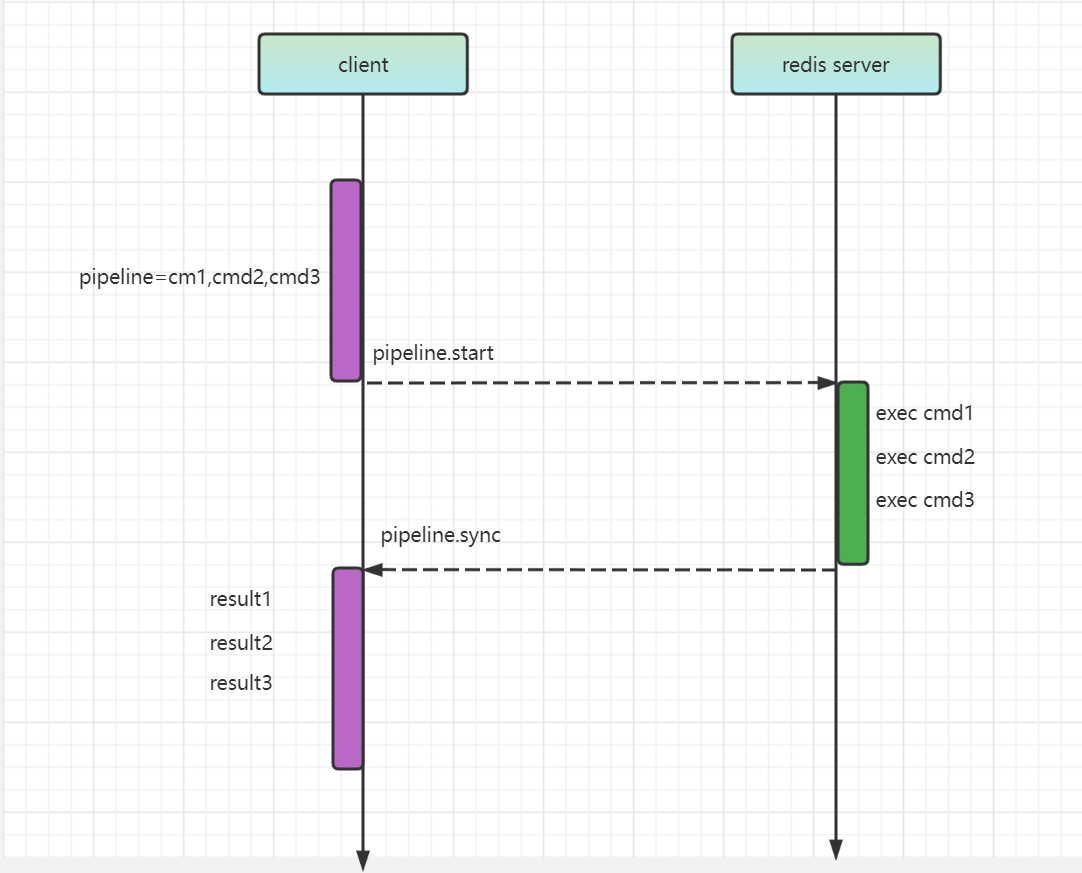
- pipeline 的優點
- 減少 RTT
- 減少 IO 呼叫次數
- 基本使用
Pipeline pipeline =jedis.pipelined();
for(int i = 0; i < 100; i++){
pipeline.rpush("rediskey", i + "");
}
pipeline.sync()
總結一下 pipeline 的核心,就是使用者端將一組 Redis 命令進行組裝,通過一次 RTT 傳送給伺服器,同時伺服器再將這組命令的執行結果按照順序一次返回給使用者端。
pipeline 注意問題
雖然 pipeline 在某些情況下會帶來不小的效能提升,但是,我們在使用的時候也需要注意。
- pipeline 中的命令數量不宜過多。
使用者端會先將多個命令寫入記憶體 buffer 中(打包),命令過多,如果是超過了使用者端設定的 buffer 上限,被使用者端的處理策略處理了(不同的使用者端實現可能會有差異,比如 jedis pipeline ,限制每次最大的傳送位元組數為 8192,緩衝區滿了就傳送,然後再寫緩衝,最後才處理 Redis 伺服器的應答)。如果使用者端沒有設定 buffer 上限或不支援上限設定,則會佔用更多的使用者端機器記憶體,造成使用者端癱瘓。官方推薦是每次 10k 個命令。
建議做好規範,遇到一次包含大量命令的 pipeline,可以拆分成多個稍小的 pipeline 來完成。
- pipeline 一次只能執行在一個 Redis 節點上,一些叢集或者 twemproxy 等中介軟體使用需要注意。
在叢集環境下,一次 pipeline 批次執行多個命令,每個命令需要根據 key 計算槽位,然後根據槽位去特定的節點上去執行命令,這樣一次 pipeline 就會使用多個節點的 redis 連線,這種當前也是不支援的。
- pipeline 不保證原子性,如要求原子性,不建議使用 pipeline
它僅是將多個命令打包傳送出去而已,如果中間有命令執行異常,也會繼續執行剩餘命令。
pipeline 與批次操作 mget 等區別
其實 meget和 pipeline 優化的方向是一致的,即多個命令打包一次傳送,減少網路時間。但是也是有區別的。
mget等的場景是一個命令對應多個鍵值對,而 pipeline 一般是多條命令(不同的命令)mget操作是一個原子操作,而 pipeline 不是原子操作mget是伺服器端實現,而 pipeline 是使用者端和伺服器端共同實現
pipeline 與事務的區別
這兩者關注和解決的問題不是一個東西,原理也不一樣。
- pipeline 是一次請求,伺服器端順序執行,一次返回。而事務是多次請求(先 multi,再多個操作命令,最後 exec),伺服器端順序執行,一次返回
- pipeline 關注的是 RTT 時間和 IO 呼叫,事務關注的是一致性問題
總結
本文主要講了多命令執行時耗時問題,以及 pipeline 的解決方法,和其簡單的原理,以及注意點。今天的學習就到這裡,改天我們接著肝。