構建端到端的開源現代資料平臺
瞭解使用開源技術構建現代資料棧的詳細指南。
在過去的幾年裡,資料工程領域的重要性突飛猛進,為加速創新和進步開啟了大門——從今天開始,越來越多的人開始思考資料資源以及如何更好地利用它們。這一進步反過來又導致了資料技術的「第三次浪潮」。
「第一次浪潮」包括 ETL、OLAP 和關係資料倉儲,它們是商業智慧 (BI) 生態系統的基石,無法應對巨量資料的4V的指數增長。
由於面向 BI 的棧的潛力有限,我們隨後見證了「第二次浪潮」:由於 Hadoop 生態系統(允許公司橫向擴充套件其資料平臺)和 Apache Spark(為大規模高效的記憶體資料處理開啟了大門)。
稱之為「第三次浪潮」的是這個我們不再擔心可延伸性或分散式儲存的時代。相反我們正在成熟的分散式資料平臺之上構建新功能,現在我們可以考慮後設資料管理、大規模資料發現和資料可靠性等主題。我們正處於可互換的 SaaS 模組、基於雲的平臺、ELT 和民主化資料存取的時代。歡迎來到現代資料棧浪潮。
本文中我們將從頭開始構建一個端到端的現代資料平臺,完全依賴開源技術和雲提供商提供的資源。 這篇文章還附有一個 GitHub 儲存庫,其中包含構建平臺所需的必要程式碼和基礎設施即程式碼 (IaC) 指令碼。
該平臺將由以下元件組成:
-
資料倉儲:這是我們平臺設計中最重要的元件,因為無論其他元件變得多麼複雜,低效的資料倉儲都會給我們帶來問題。從根本上說資料倉儲背後的 40 年曆史概念和正規化至今仍然適用,但結合了「第二次浪潮」帶來的水平可延伸性,從而實現了高效的 ELT 架構。
-
資料整合:不出所料我們需要將資料輸入至平臺,而以前設定和實現聯結器的繁瑣任務現在已通過現代資料棧解決。
-
資料轉換:一旦資料進入資料倉儲(因此完成了 ELT 架構的 EL 部分),我們需要在它之上構建管道來轉換,以便我們可以直接使用它並從中提取價值和洞察力——這個過程是我們 ELT 中的 T,它以前通常由不易管理的大的查詢 SQL 或複雜的 Spark 指令碼組成,但同樣在這「第三次浪潮」中我們現在有了必要的工具更好地管理資料轉換。
-
編排(可選):我們仍然需要執行編排管道以確保資料儘快可用,並且資料生命週期從一個元件順利執行到下一個元件,但目前是可選的,因為我們使用的一些工具提供了開箱即用的排程功能,因此在平臺生命週期的第一階段不需要專門的編排元件(它會新增不必要的複雜)。儘管如此我們將在本文中討論編排,因為最終需要將新增到平臺中。
-
資料監控(可選):更多資料意味著更多潛在的資料質量問題。為了能夠信任資料,我們需要對其進行監控並確保基於它生成準確的見解,但目前是可選的,因為在開始時最有效的選擇是利用其他元件的資料測試功能,但我們將在本文中討論資料監控工具。
-
資料視覺化:這是我們實際探索資料並以不同資料產品(如儀表板和報告)的形式從中產生價值的地方。這個時代的主要優勢之一是現在擁有成熟的開源資料視覺化平臺並可以以簡化的方式進行部署。
-
後設資料管理:平臺的大部分功能(如資料發現和資料治理)都依賴於後設資料,因此需要確保後設資料在整個平臺中共用和利用。
最後請記住儘管討論的技術和工具是開源的,但我們將在雲環境中構建平臺以及使用的資源(用於計算、儲存等)、雲環境本身並不免費,但不會超過 GCP 免費試用提供的 300 美元預算。
如果想避免設定雲環境,可以在本地嘗試不同的工具,只需將資料倉儲(範例中的 BigQuery)替換為開源替代品(像 PostgreSQL 這樣的 RDBMS 就可以了)。
事不宜遲,讓我們開始構建現代資料平臺。
首先,談談資料
要構建範例資料平臺,第一步是選擇一個或多個要使用的資料集,這是一個探索線上可用的多個開放資料集之一的機會,建議使用一個感興趣的資料集——這將使構建過程更加愉快,因為對資料真正感興趣。如果您想要一些靈感,可以使用以下資料集之一:
- 一級方程式世界錦標賽(1950-2021):該資料集可以從 Kaggle 下載或直接從 Ergast HTTP API 檢索,其中包含一級方程式比賽、車手、車隊、排位賽、賽道、單圈時間、維修站的所有可用資料點停止,從 1950 年到 2021 年的冠軍。如果你像我一樣是 F1 粉絲,這個資料集可以為你提供關於這項運動的許多有趣的見解。
- 世界發展指標(1960-2020):世界銀行提供的這個資料集無疑是可以在網上找到的最豐富的開放資料集之一,它包含大約 1500 個發展指標。
資料倉儲:BigQuery
如上所述選擇正確的資料倉儲是我們難題中最重要的部分。主要的三個選項是 Snowflake、BigQuery 和 Redshift。它們都不是開源但都是無伺服器託管形態,這意味著我們可以利用複雜的現代資料倉儲的功能,同時只需為消耗的儲存和計算資源付費。
無伺服器託管正是現階段尋找的,即使該產品不是開源的,那是因為我們的訴求是可以在儲存和查詢效能方面進行擴充套件,而不需要專門的運維。因此入門時的理想選擇是無伺服器託管產品——這適用於我們所有需要彈性的元件,而不僅僅是資料倉儲。
BigQuery 非常適合這個要求,原因有很多,其中兩個如下:
- 首先它本質上是無伺服器的。由於儲存和計算的解耦,其背後的設計提高了效率,使其成為所有型別用例的非常可靠的選擇。另一方面Redshift 的無伺服器產品仍處於測試階段。
- 其次它是雲提供商產品的一部分,因此已經與 GCP 生態系統的所有元件無縫整合。這進一步簡化了我們的架構,因為它最大限度地減少了設定工作。
因此我們將 BigQuery 用作該平臺的資料倉儲,但這並不是一定的,在其他情況下選擇其他選項可能更適合。在選擇資料倉儲時,應該考慮定價、可延伸性和效能等因素,然後選擇最適合您的用例的選項。
首先我們只需要建立一個資料集,也可以隨時熟悉 BigQuery 的一些更高階的概念,例如分割區和物化檢視。
在 ELT 架構中資料倉儲用於儲存我們所有的資料層,這意味著我們不僅將使用它來儲存資料或查詢資料以進行分析用例,而且還將利用它作為執行引擎進行不同的轉換。
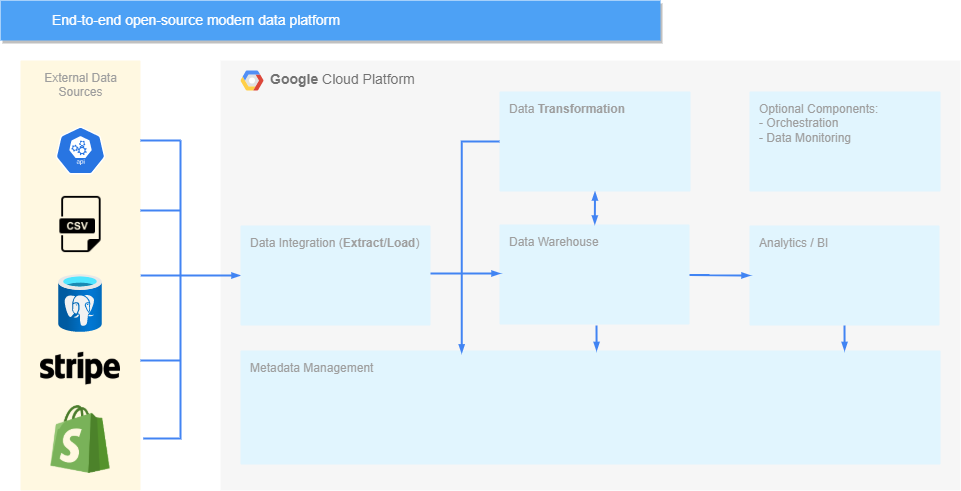
現在已經選擇了資料倉儲,架構如下所示:
在進入下一個元件之前,將 BigQuery 審計紀錄檔儲存在專用資料集中(附加說明),這些資訊在設定後設資料管理元件時會被用到。
攝取資料:Airbyte
在考慮現代資料棧中的資料整合產品時會發現少數公司(使用閉源產品)競相在最短的時間內新增更多數量的聯結器,這意味著創新速度變慢(因為為每種產品做出貢獻的人更少)和客製化現有解決方案的可能性更少。
異常亮點肯定是 Airbyte,這是該領域唯一一家從一開始就選擇開源其核心產品的大公司,這使其能夠迅速發展一個大型貢獻者社群,並在其成立不到一年的時間內提供 120 多個聯結器。
部署 Airbyte 對所有云提供商來說都是輕而易舉的事。在 GCP 上,我們將使用具有足夠資源的 Compute Engine 範例。理想情況下希望通過 IaC 設定部署,這樣可以更輕鬆地管理版本控制和自動化流程。(隨附的儲存庫中提供了範例 Terraform 設定。)
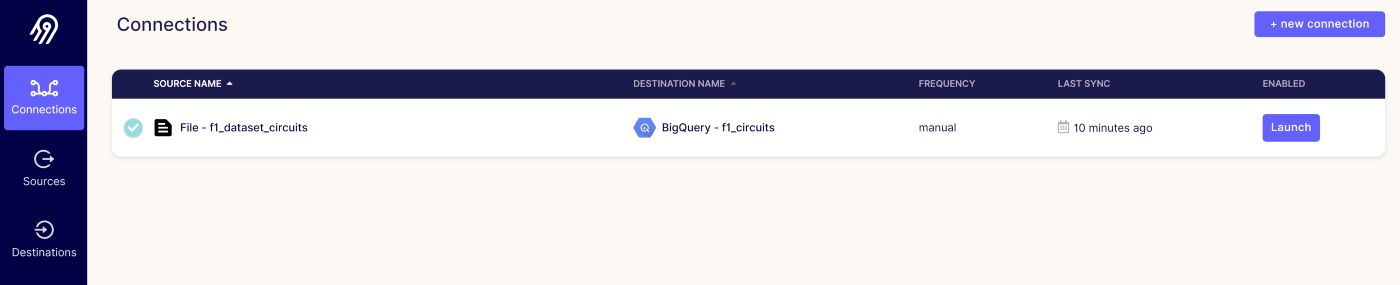
一旦它啟動並執行,我們只需要通過定義新增一個連線:
- Source:可以使用 UI 選擇「檔案」來源型別,然後根據資料集和上傳資料的位置進行設定,或者可以利用 Airbyte 的 Python CDK 構建一個新的 HTTP API 源,用於從您要使用的 API 中獲取資料。
- Destination:這裡只需要指定與資料倉儲(在我們的例子中為「BigQuery」)互動所需的設定。
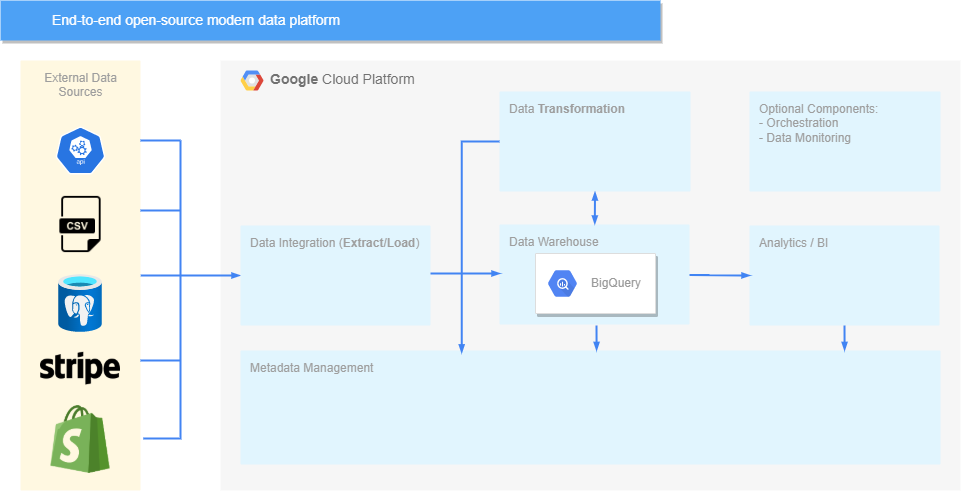
值得注意的是 Airbyte 目前專為批次資料攝取(ELT 中的 EL)而設計,因此如果正在構建一個事件驅動的平臺,那麼它不會成為選擇之一。 如果有這樣的用例,那麼可以選擇 Jitsu,Segment 的開源替代品。
現在我們已經啟動並執行了 Airbyte 並開始攝取資料,資料平臺如下所示:
ELT 中管理 T:dbt
當想到現代資料棧時,dbt 可能是第一個想到的工具。該專案始於 2016 年(從一開始就是開源的)解決了當時普遍存在的問題:資料管道的版本控制不當、檔案記錄不完善,並且沒有遵循軟體工程的最佳實踐。
dbt 是第三次資料技術浪潮的理想典範,因為它代表了這一浪潮背後的主要目標:新增特性和功能以更輕鬆地管理現有資料平臺,並從底層資料中提取更多價值。多虧了 dbt,資料管道(我們 ELT 中的 T)可以分為一組 SELECT 查詢(稱為「模型」),可以由資料分析師或分析工程師直接編寫。然後此功能為資料血緣、版本控制、資料測試和檔案等多種功能開啟了大門。
可以通過兩種不同的方式設定 dbt 環境:
- dbt Cloud:這是由 dbt Labs 託管的基於 Web 的整合式開發環境 (IDE)。該選項需要最少的工作量,但提供更多功能,如排程作業、CI/CD 和警報。值得注意的是它實際上對開發者計劃是免費的。
- dbt CLI:此選項允許直接與 dbt Core 互動,無論是通過使用 pip 在本地安裝它還是像之前部署的 Airbyte 一樣在 Google Compute Engine 上執行 docker 映像。通過使用 CLI可以試驗不同的 dbt 命令並在選擇的 IDE 中工作。
要允許 dbt 與 BigQuery 資料倉儲互動,需要生成所需的憑據(可以建立具有必要角色的服務帳戶),然後在 profiles.yml 檔案中指明專案特定的資訊。這在 dbt Labs 的「入門」教學中得到了很好的解釋,該教學介紹了需要熟悉的所有概念。
現在可以享受資料樂趣了:您可以使用 dbt 來定義模型和它們之間的依賴關係。例如對於 F1 資料集,可以生成包含冠軍資料(總積分、每場比賽的平均進站時間、整個賽季最快圈數、平均排位賽位置等)的 Championship_winners 模型。對於正在處理的任何資料集,當涉及到資料可以回答的問題時,您會發現無限可能性——這是一個很好的練習,可以讓您在處理新資料集時感到更加自信。
處理完模型後可以執行命令 dbt docs generate來生成專案的檔案(目錄和清單檔案)。
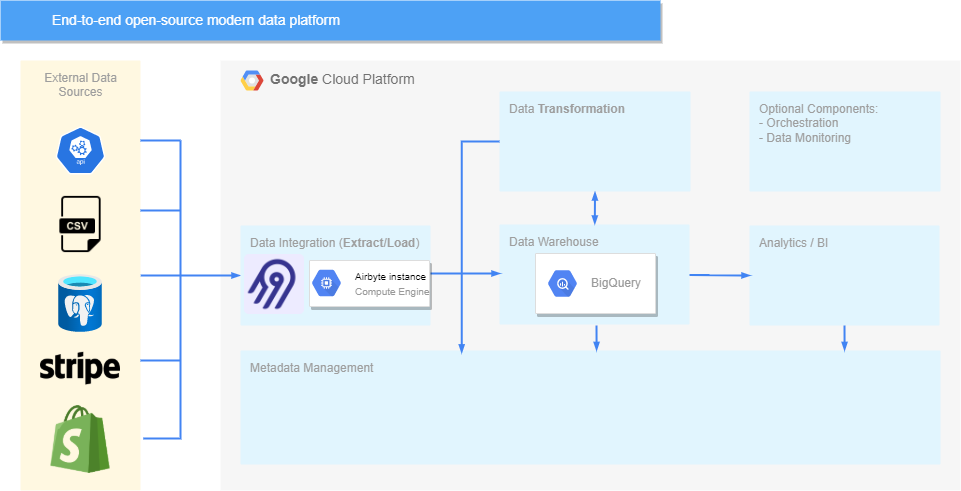
在完成 dbt 設定之後,我們現在擁有可以處理 ELT 流程的三個步驟的元件,架構如下所示:
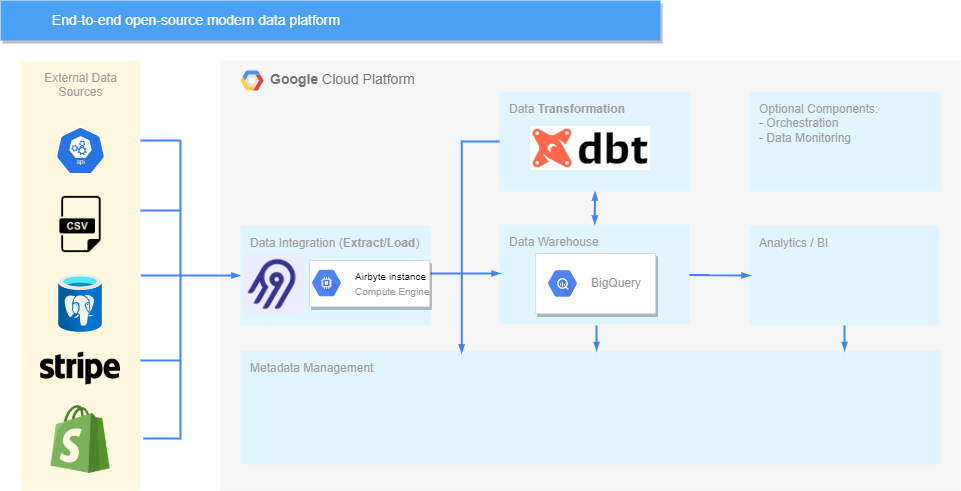
當第一次介紹架構時,我們說過編排和資料監控/測試現在都可以由另一個元件處理——您可能已經猜到該元件是 dbt。 使用 dbt Cloud可以管理管道的排程並定義不同的執行觸發器(例如通過 webhook),而 dbt 還具有強大的基於 SQL 的測試功能,可以利用它來確保不會發現資料質量問題。
資料視覺化:Apache Superset
現在我們已經處理了我們的資料並生成了可以提供見解的不同檢視和表格,需要通過一組資料產品實際視覺化這些見解。(如果你不熟悉這個詞,這篇很棒的文章對不同型別的資料產品進行了詳盡的概述。)
這個階段的目標是構建可以由我們的終端使用者直接存取的儀表板和圖表(無論是用於分析還是監控,取決於資料集)。
BI 是少數幾個沒有被「第二次浪潮」資料技術打亂的領域之一,主要是因為 Hadoop 生態系統專注於大規模處理資料而不影響終端使用者的消費方式。這意味著在很長一段時間內,BI 和資料視覺化領域由專有工具(Tableau、PowerBI 和最近的 Looker)主導,缺乏開源專案,只有小眾用例。
然後是 Apache Superset。當 Airbnb 在 2016 年首次開源時,它通過提供企業級所需的所有功能,代表了現有 BI 工具的第一個開源真正替代品。如今由於其龐大的開源社群,它已成為「第三次浪潮」(以及 Metabase 和 Looker 等替代品)的領先技術之一。
Superset 部署由多個元件組成(如專用後設資料資料庫、快取層、身份驗證和潛在的非同步查詢支援),因此為了簡單起見,我們將依賴非常基本的設定。
我們將再次利用 Google Compute Engine 來啟動一個 Superset 範例,我們將在該範例上通過 Docker Compose 執行一個容器。本文隨附的儲存庫中提供了必要的 Terraform 和 init 指令碼。
一旦 Superset 啟動並執行,可以通過以下命令連線到範例:
gcloud --project=your-project-id beta compute ssh superset-instance -- -L 8088:localhost:8088 -N
登入到 Superset 範例後(通過官方檔案中提供的步驟),只需將其連線到 BigQuery 即可開始與您的不同資料集進行互動。
建立連線後,您可以試驗不同的圖表型別、構建儀表板,甚至可以利用內建 SQL 編輯器向您的 BigQuery 範例提交查詢。
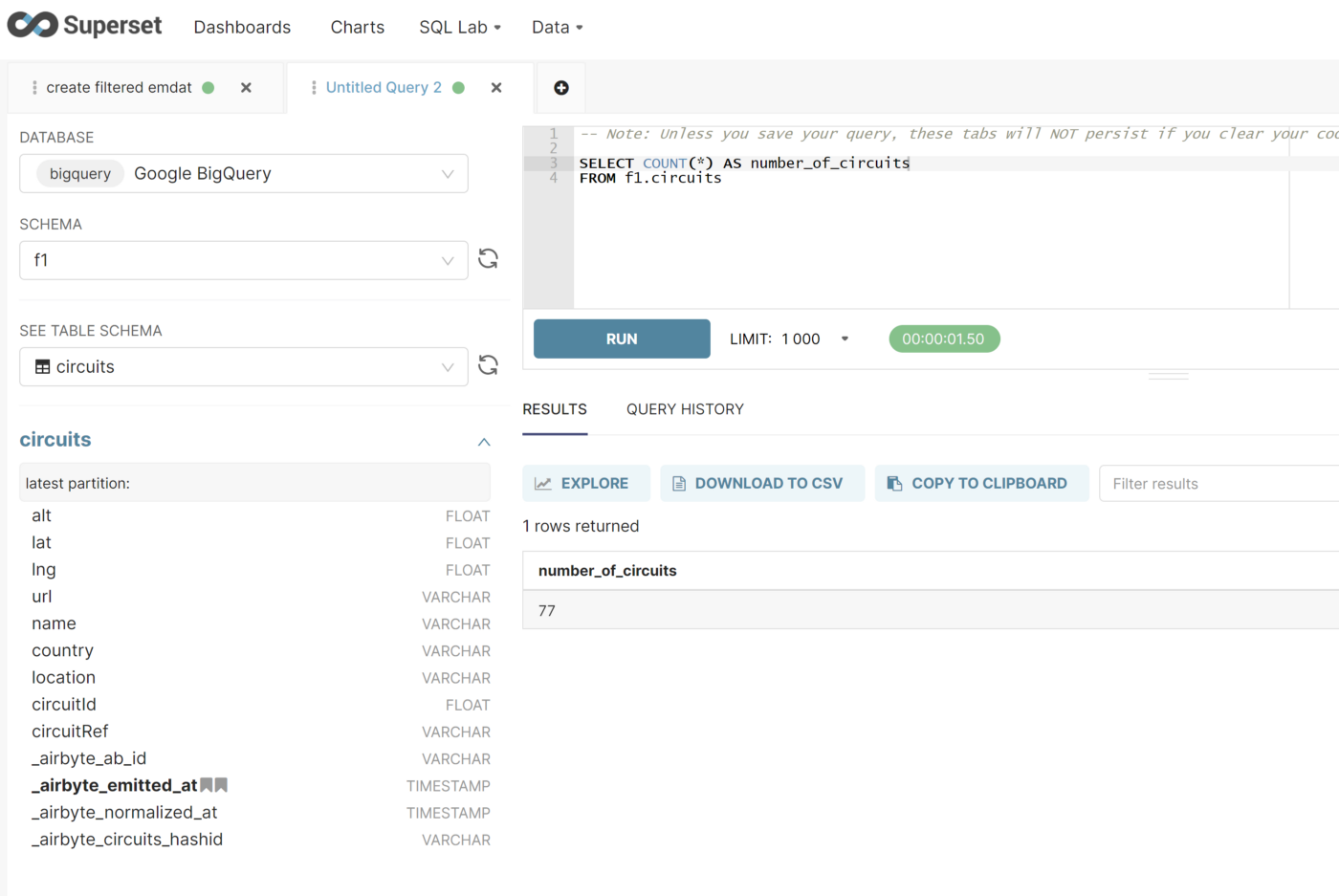
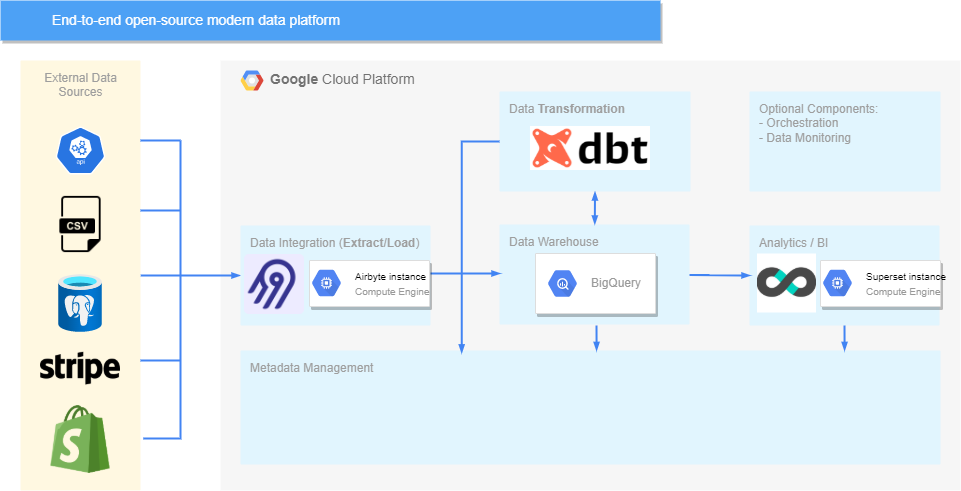
現在我們可以通過 Superset 為終端使用者提供對資料的直接存取,我們的資料平臺如下所示:
在 Superset 的功能方面,上述我們只觸及了皮毛,還可以管理存取角色、利用快取、構建自定義視覺化外掛、使用其豐富的 API,甚至強制執行行級存取策略。 此外通過 Preset,還可以選擇一個託管版本而無需考慮部署。
技術棧的基石:OpenMetadata
後設資料管理可能是資料社群存在最大分歧的領域,這是一個非常分散的空間(存在25 種工具並且還在增加),不同的工具在如何解決這個問題上採取了截然不同的方法。
在我個人看來 Uber 資料平臺團隊開源的產品 OpenMetadata 在這個領域採取了正確的方法。通過專注於提供水平後設資料產品,而不是僅僅成為架構中的一部分,它使集中式後設資料儲存成為可能。它有非常豐富的 API,強制執行後設資料模式,並且已經有很長的聯結器列表。
其他產品正在實施自己的後設資料管理方式,並且是在閉門造車的情況下這樣做,這會在將它們新增到我們的平臺時造成不必要的開銷,而 OpenMetadata 專注於為其他產品可以與之互動的後設資料提供單一真實來源它的 API。通過將其新增到架構中,資料發現和治理成為必然,因為它已經具備實現這些目標所需的所有功能。如果您想在將其新增到平臺之前瞭解它的功能,可以先探索它的沙箱。
與 Airbyte 和 Superset 一樣,我們將通過 Google Compute Engine 範例部署 OpenMetadata(與往常一樣,隨附的儲存庫中提供了 Terraform 和 init 指令碼)。部署完成後會注意到虛擬機器器上實際上執行了四個容器,用於以下目的:
- 在 MySQL 上儲存後設資料目錄
- 通過 Elasticsearch 維護後設資料索引
- 通過 Airflow 編排後設資料攝取
- 執行 OpenMetadata UI 和 API 伺服器

OpenMetadata 在後臺盡職盡責地管理這些元件,而無需進行任何設定,因此我們可以立即開始像任何其他產品一樣使用它,啟動並執行後可以首先通過以下命令連線到 Airflow 埠:
gcloud --project=your-project beta compute ssh openmetadata-instance -- -L 8080:localhost:8080 -N
然後可以通過 http://localhost:8080/ 存取 Airflow UI(使用者名稱:admin,密碼:admin)。 您會注意到一些 DAG 已經執行以載入和索引一些範例資料。 之後通過以下命令連線到 OpenMetadata UI(然後可以通過 http://localhost:8585/ 存取該 UI):
gcloud --project=your-project beta compute ssh openmetadata-instance -- -L 8585:localhost:8585 -N
現在可以通過 SSH 登入 GCE 範例,並將 OpenMetadata 連線到 BigQuery、BigQuery 使用資料、dbt 和 Superset。 然後可以探索其不同的特性和功能,例如資料發現和血緣。
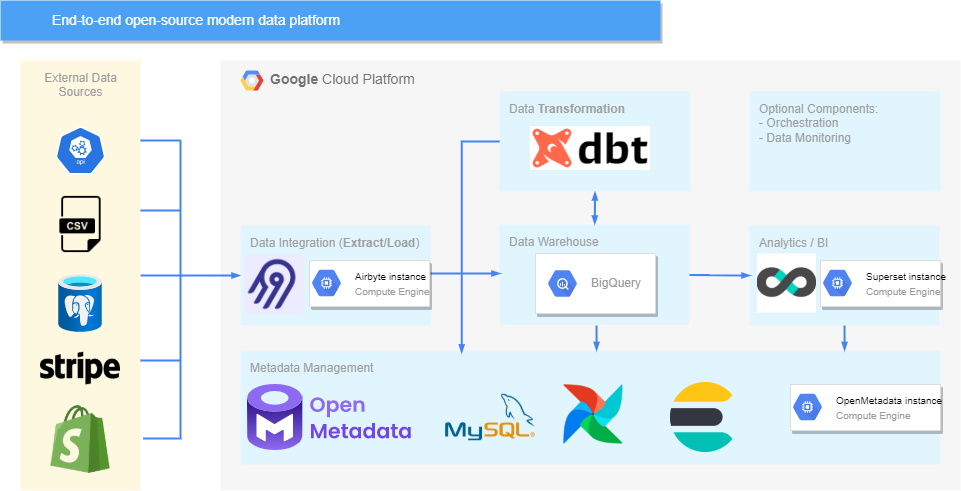
現在已經將 OpenMetadata 新增到了平臺中,來看看我們最終的架構:
提升到新水平:可選元件
在文章開頭我們提到了兩個可選元件:編排和資料監控。理論上這對於資料平臺來說是兩個非常重要的功能,但正如我們所見,dbt 在這個階段可以很好地實現它們。儘管如此讓我們討論一下如何在需要時整合這兩個元件。
編排管道:Apache Airflow
當平臺進一步成熟,開始整合新工具和編排複雜的工作流時,dbt 排程最終將不足以滿足我們的用例。一個簡單的場景是在更新特定的 dbt 模型時使 Superset 快取失效——這是我們僅通過 dbt Cloud 的排程無法實現的。
自 2015 年 Airbnb 開源以來,Airflow 一直是資料工作流編排領域的首選工具。這使其成為多家科技公司大型資料平臺不可或缺的一部分,確保了一個大型且非常活躍的開放式圍繞它的源社群——這反過來又幫助它在編排方面保持了標準,即使在「第三次浪潮」中也是如此。
應該推遲考慮 Airflow(或其替代方案)的原因是專用編排工具帶來的額外複雜性。 Airflow 以自己的方式處理問題,為了能夠充分利用它,需要做出妥協並調整工作流程以匹配其特性。
在整合編排工具時還應該考慮如何觸發管道/工作流,Airflow 支援基於事件的觸發器(通過感測器),但問題很快就會出現,使您僅僅因為該工具而適應您的需求,而不是讓該工具幫助您滿足您的需求。
資料監控:Soda SQL
就像編排一樣,資料監控(最終我們將考慮資料可觀測性)是 dbt 最終將停止為我們的平臺處理需求。
我們不只是驗證 dbt 模型的資料,而是希望在整個平臺上跟蹤資料問題,以便可以立即確定特定問題的來源並相應地修復它。
與資料整合一樣,資料可觀測性是公司仍然採用閉源方法,這不可避免地減緩創新和進步。另一方面有兩種開源產品可以滿足我們實現這一目標的大部分需求:Soda SQL 和 Great Expectations。
Soda SQL 是一個很好的開始,因為它不需要太多投資,而且提供了多種方便的功能,基本上只需要幾個 YAML 檔案即可啟動和執行,然後可以定義自定義測試和編排掃描。
接下來是什麼?
這是一段漫長的過程,我們經歷了不同的技術——其中一些是我們正在目睹的「第三次浪潮」的產品,而另一些則是經過時間考驗的「第二次浪潮」老手,在這一點上的主要收穫是構建一個功能齊全的資料平臺比以往任何時候都更容易——如果你跟著實施,你會發現自己在不到一個小時的時間內就構建了一個現成的現代資料平臺。
當然現代資料棧仍然是分散的,押注我們討論的某些技術可能是一個冒險的決定。除了 dbt 之外,沒有任何現代資料棧工具在其所做的事情上是明顯的贏家,因此生態系統將在未來幾年通過整合和競爭不斷變化,不過可以肯定的是激動人心的時代即將到來。
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

