day50-正規表示式01
2022-10-23 06:01:49
正規表示式01
5.1正規表示式的作用
正規表示式的便利
在一篇文章中,想要提取相應的字元,比如提取文章中的所有英文單詞,提取文章中的所有數位等。
- 傳統方法是:使用遍歷的方式,對文字中的每一個字元進行ASCII碼的對比,如果ASCII碼處於英文字元的範圍,就將其擷取下來,再看後面是否有連續的字元,將連續的字元拼接成一個單詞。這種方式程式碼量大,且效率不高。
- 使用正規表示式
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//體驗正規表示式的便利
public class Regexp_ {
public static void main(String[] args) {
//假設有如下文字
String content = "1995年,網際網路的蓬勃發展給了Oak機會。業界為了使死板、單調的靜態網頁能夠「靈活」起來," +
"急需一種軟體技術來開發一種程式,這種程式可以通過網路傳播並且能夠跨平臺執行。於是,世界各大IT企" +
"業為此紛紛投入了大量的人力、物力和財力。這個時候,Sun公司想起了那個被擱置起來很久的Oak,並且" +
"重新審視了那個用軟體編寫的試驗平臺,由於它是按照嵌入式系統硬體平臺體系結構進行編寫的,所以非常" +
"小,特別適用於網路上的傳輸系統,而Oak也是一種精簡的語言,程式非常小,適合在網路上傳輸。Sun公" +
"司首先推出了可以嵌入網頁並且可以隨同網頁在網路上傳輸的Applet(Applet是一種將小程式嵌入到網" +
"頁中進行執行的技術),並將Oak更名為Java。5月23日,Sun公司在Sun world會議上正式釋出Java和" +
"HotJava瀏覽器。IBM、Apple、DEC、Adobe、HP、Oracle、Netscape和微軟等各大公司都紛紛停止" +
"了自己的相關開發專案,競相購買了Java使用許可證,併為自己的產品開發了相應的Java平臺。";
String content2 = "無類域間路由(CIDR,Classless Inter-Domain Routing)地址根據網路拓撲來分配,可以" +
"將連續的一組網路地址分配給一家公司,並使整組地址作為一個網路地址(比如使用超網技術),在外部路由表上" +
"只有一個路由表項。這樣既解決了地址匱乏問題,又解決了路由表膨脹的問題。另外,CIDR還將整個世界分為四" +
"個地區,給每個地區分配了一段連續的C類地址,分別是:歐洲(194.0.0.0~195.255.255.255)、北美(19" +
"8.0.0.0~199.255.255.255)、中南美(200.0.0.0~201.255.255.255)和亞太(202.0.0.0~203.2" +
"55.255.255)。這樣,當一個亞太地區以外的路由器收到前8位元為202或203的資料包時,它只需要將其放到通向亞" +
"太地區的路由即可,而對後24位元的路由則可以在資料包到達亞太地區後再進行處理,這樣就大大緩解了路由表膨脹的問題";
//正規表示式來完成
// (1)先建立一個Pattern物件,模式物件,可以理解成就是一個正規表示式物件
//Pattern pattern = Pattern.compile("[a-zA-Z]+");//提取文章中的所有英文單詞
//Pattern pattern = Pattern.compile("[0-9]+");//提取文章中的所有數位
//Pattern pattern = Pattern.compile("([0-9]+)|([a-zA-Z]+)");//提取文章中的所有的英文單詞和數位
Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+");//提取文章中的ip地址
// (2)建立一個匹配器物件
// 理解:就是 matcher 匹配器按照pattern(模式/樣式),到content文字中去匹配
// 找到就返回true,否則就返回false(如果返回false就不再匹配了)
Matcher matcher = pattern.matcher(content2);
// (3)可以開始迴圈匹配
while (matcher.find()) {
//匹配到的內容和文字,放到 m.group(0)
System.out.println("找到:" + matcher.group(0));
}
}
}
提取所有英文單詞:
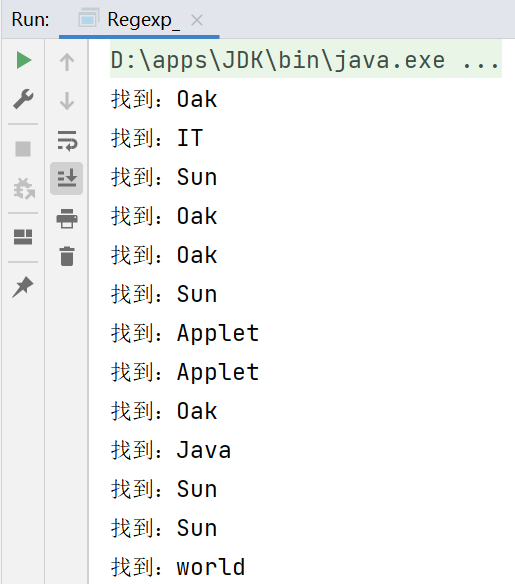

- 應用範例
-
[a-z]說明:[a-z]表示可以匹配 a-z 之間任意的一個字元[A-Z]表示可以匹配 A-Z 之間任意的一個字元[0-9]表示可以匹配 0-9 之間任意的一個字元比如[a-z]、[A-Z]去匹配「a11c8」會得到什麼結果?結果是:a、c
-
java正規表示式預設是區分大小寫的,如何實現不區分大小寫?
(?i)abc表示abc都不區分大小寫a(?i)bc表示bc不區分大小寫a((?i)b)c表示只有b不區分大小寫Pattern pattern = Pattern.compile(regStr,Pattern.CASE_INSENSITIVE);
-
[^a-z]說明:[^a-z]表示可以匹配不是a-z中的任意一個字元[^A-Z]表示可以匹配不是A-Z中的任意一個字元[^0-9]表示可以匹配不是0-1中的任意一個字元如果用 [^a-z]去匹配「a11c8」會得到什麼結果?結果:1、1、8
用 [^a-z]{2}又會得到什麼結果?結果是:11
-
[abcd]表示可以匹配abcd中的任意一個字元 -
[^abcd]表示可以匹配不是abcd中的任意一個字元 -
\\d表示可以匹配0-9的任意一個數位,相當於[0-9] -
\\D表示可以匹配不是0-9的任意一個數位,相當於[^0-9],即匹配非數位字元 -
\\w表示可以匹配任意英文字元、數位和下劃線,相當於[a-zA-Z0-9_] -
\\W相當於[^a-zA-Z0-9_],與\\w相反 -
\\s匹配任何空白字元(空格,製表符等) -
\\S匹配任何非空白字元,與\\s相反 -
.匹配除\n和\r之外的所有字元,如果要匹配.本身則需要使用\\
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//演示字元匹配符的使用
public class RegExp03 {
public static void main(String[] args) {
String content = "a1 1\r@c^8ab_c\nA BC\r\n";
//String regStr = "[a-z]";//匹配 a-z 之間任意的一個字元
//String regStr = "[A-Z]";//匹配 A-Z 之間任意的一個字元
//String regStr = "[0-9]";//匹配 0-9 之間任意的一個字元
//String regStr = "abc";//匹配 abc 字串[預設區分大小寫]
//String regStr = "(?i)abc";//匹配 abc 字串[不區分大小寫]
//String regStr = "[^a-z]";//匹配不在 a-z 之間任意的一個字元
//String regStr = "[^0-9]";//匹配不在 0-9 之間任意的一個字元
//String regStr = "[abcd]";//匹配在 abcd 中任意的一個字元
//String regStr = "\\D";//匹配不在 0-9 中的任意的一個字元[匹配非數位字元]
//String regStr = "\\w";//匹配任意英文字元、數位和下劃線
//String regStr = "\\W";//\[^a-zA-Z0-9_]
//String regStr = "\\s";//匹配任何空白字元(空格,製表符等)
//String regStr = "\\S";//匹配任何非空白字元
String regStr = ".";//.匹配除\n之外的所有字元,如果要匹配.本身則需要使用\\
//說明:當建立Pattern物件時,指定Pattern.CASE_INSENSITIVE,表示匹配是不區分字母大小寫的
//Pattern pattern = Pattern.compile(regStr,Pattern.CASE_INSENSITIVE);
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
5.4.3元字元-選擇匹配符
在匹配某個字串的時候是選擇性的,即:既可以匹配這個,又可以匹配那個,這時需要用到選擇匹配符號|

例子:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegExp04 {
public static void main(String[] args) {
String content ="hangshunping 韓 寒冷";
String regStr="han|韓|寒";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
