微服務架構學習與思考(11):開源 API 閘道器02-以 Java 為基礎的 API 閘道器詳細介紹
微服務架構學習與思考(11):開源 API 閘道器02-以 Java 為基礎的 API 閘道器詳細介紹
上一篇關於閘道器的文章:
微服務架構學習與思考(10):微服務閘道器和開源 API 閘道器01-以 Nginx 為基礎的 API 閘道器詳細介紹,介紹了為什麼會有閘道器及以 Nginx 為基礎的閘道器。
一、閘道器 zuul
zuul 閘道器使用 java 語言開發,是 Netflix 公司出品的開源閘道器。它是 SpringCloud 的元件之一。zuul 有 2 個大的版本:
-
zuul1:zuul1 wiki
-
zuul2:zuul2 wiki
1.1 zuul1 架構
zuul1 是基於 Servlet 構建的,採用的是阻塞和多執行緒方式,它一個執行緒處理一次連線。I/O 操作是通過從執行緒池中選擇一個工作執行緒執行 I/O 來完成的,並且請求執行緒將阻塞,直到工作執行緒完成為止。工作執行緒在其工作完成時通知請求執行緒。如下圖:
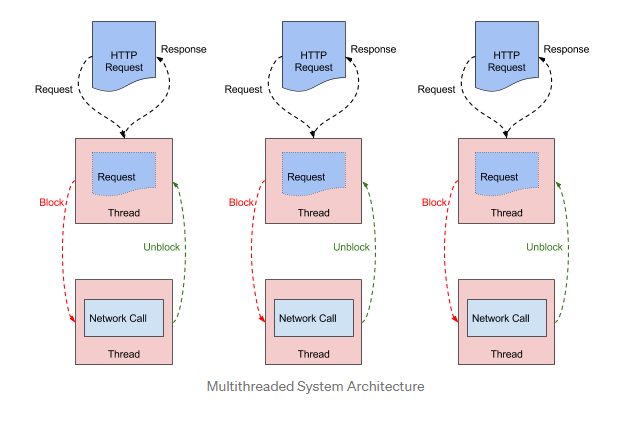
(netflix blog: https://netflixtechblog.com/zuul-2-the-netflix-journey-to-asynchronous-non-blocking-systems-45947377fb5c)
這種處理執行緒模型,當後端API延遲增加或錯誤導致重試,執行緒數也會隨之增加。這種情況發生時,就會給節點伺服器帶來麻煩,使伺服器負載激增,為了消除這種麻煩,構建了限流機制(比如hystrix)保持系統的穩定。
zuul1 中閘道器功能怎麼實現,在請求週期通過 Filter 實現,如下圖:

(from:https://github.com/Netflix/zuul/wiki/How-it-Works)
1.2 zuul2 架構
zuul2 對 zuul1 進行了重大的重構,採用非同步和事件驅動模式處理程式。請求和響應的生命週期通過事件和回撥機制來處理。沒有像 zuul1 那樣針對每個請求使用一個執行緒,不需要大量的執行緒成本,只需要一個檔案描述符和一個監聽器。而且像 zuul1 發生後端延遲和「重試風暴」,不是增加執行緒,zuul2 中是在佇列中增加事件,這個開銷比多個執行緒開銷小得多。
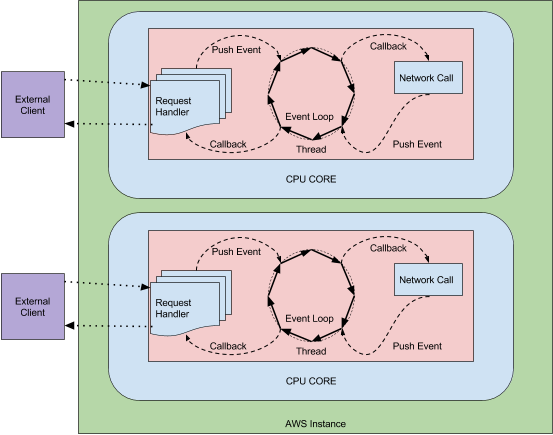
(netflix blog: https://netflixtechblog.com/zuul-2-the-netflix-journey-to-asynchronous-non-blocking-systems-45947377fb5c)
關於高效能網路IO程式設計模型,可以看我之前的文章,點選這裡看文章
zuul2 閘道器中那麼多功能是怎麼實現的呢?是在請求週期(request cycle)中,通過 Filter 來處理實現。
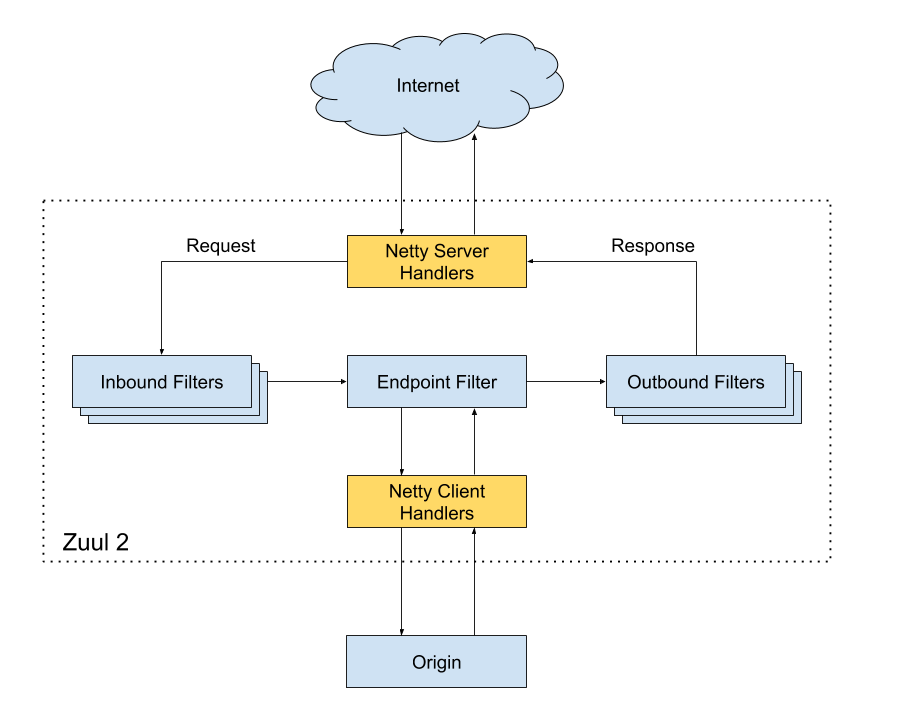
(from:https://github.com/Netflix/zuul/wiki/How-It-Works-2.0)
Filter:
Filter 過濾器是 zuul2 業務邏輯處理的核心,它可以在請求-響應週期的不同部分執行。分為 3 個 Filter:
- Inbound Filters:Inbound 過濾器,在請求到源之前執行,可用於身份驗證、路由和裝飾請求等處理操作
- Endpoint Filters:Endpoint 過濾器,可用於返回靜態響應,否則內建的 ProxyEndpoint 過濾器會將請求路由到源。
- Outbound Filters:Outbound 過濾器,請求處理之後執行,可用於度量、裝飾處理之後的請求或增加自定義 header。
更多 zuul2 Filter 用法請檢視 Filter wiki。
說明:在 zuul2 中編寫 Filter,使用的是 groovy 語言,它可以動態更新,不需要重啟伺服器。
1.3 zuul2 特性
- Core Features
- Push Messaging
二、SpringCloud Gateway
2.1 介紹
Spring Cloud Gateway3.1.x 旨在提供一種簡單而有效的方式路由到 API,併為它們它們提供橫切關注,比如:安全、監控和彈性。
它是構建在 Spring 生態之上,包括 Spring5、Spring2 和 Project Reactor(Spring WebFlux)。
Spring WebFlux 框架底層使用了 Reactor 模式高效能通訊框架 Netty。
官網:官網地址
github: github 地址
Spring Cloud Gateway 是用來替代 zuul 閘道器,因為 zuul2 開發進度落後。
2.2 Spring Cloud Gateway 特性
Features:
- 基於 Spring Framework 5、Project Reactor 和 Spring 2.0 構建
- 能夠在任何請求屬性上匹配路由
- Predicates 和 Filters 作用於特定路由,易於編寫的 Predicates 和 Filters
- 整合了斷路器
- 整合了 Spring Cloud DiscoveryClient
- 很容易編寫 Predicates 和 Filters
- 具備閘道器一些高階功能:動態路由、限流、路由重寫
Spring Cloud Gateway 與 Eureka、Ribbon、Hystrix 等元件配合使用,實現路由轉發、負載均衡、鑑權、熔斷、路由重寫、紀錄檔監控等功能。
Spring Cloud Gateway 中的重要概念:
(1) Filter(過濾器)
可以使用它來攔截和修改請求,並且對它的上文的響應進行處理。
(2) Route(路由)
閘道器設定的基本組成模組。一個 Route 模組由一個 ID,一個目標 URI,一組斷言(Predicate)和一組過濾器(Filter)組成。如果斷言為真,則路由匹配,目標 URI 會被存取。
(3)Predicate(斷言):
路由轉發的判斷條件,可以使用它來匹配來自 HTTP 請求的任何內容,例如修改請求方式、請求頭內容、請求路徑、請求引數等。如果匹配成功,則轉發到相應的服務裡。
Predicate 是路由的匹配條件,匹配之後,Filter 就對請求和響應進行精細化處理。有了這兩個工具,再加上目標 URI 可以實現一個具體的路由,就可以對具體的路由進行處理操作。
2.3 Gateway 處理流程
流程圖:

- 使用者端向 Spring Cloud Gateway 發出請求
- Spring Cloud Gateway 通過 Gateway Handler Mapping 找到與請求相匹配的路由,將其傳送到 Gateway Web Handler。
- Gateway Web Handler 通過指定的過濾器鏈(Filter Chain)來處理請求,然後傳送到實際的執行業務服務中,業務邏輯執行完後返回。
- 業務邏輯執行完成後,又經過了過濾器鏈(Filter Chain),這裡又可以對執行完後的業務邏輯進行加工處理。
說明:過濾器鏈中的虛線分開過過濾器,是表示過濾器會在業務邏輯處理之前進行 Filter 或處理完之後在進行 Filter。
在請求轉發到伺服器端前(Proied Service 前),可以進行 Filter 處理(上圖中虛線左邊部分),例如許可權檢查、引數效驗、流量監控、協定轉換等處理。
在伺服器端處理完業務邏輯後,也可以進行 Filter 處理(上圖中虛線右邊部分),例如修改響應頭、紀錄檔輸出、流量監控等處理。
三、Apache ShenYu(神禹)
3.1 介紹
Apache ShenYu 是使用 Java reactor 程式設計方式開發的,是一個可延伸、高效能、響應式的 API 閘道器。
官網:ShenYu 官網
Doc: ShenYu Doc
3.2 架構
ShenYu version:2.5.0
整體架構流程圖
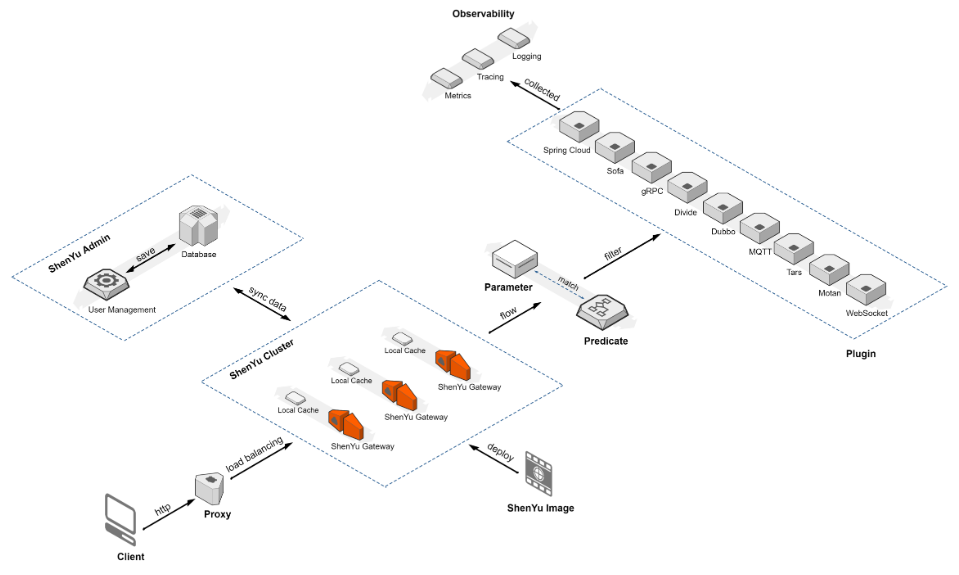
(來自:https://github.com/apache/shenyu)
- ShenYu Cluster
- ShenYu Admin,管理 ShenYu gateway
- Plugin
流量進入 -> ShenYu Cluster —> Predicate斷言匹配 -> Filter -> Plugins
ShenYu 中的一些概念
外掛、選擇器、規則,這些元素都可以在 ShenYu Admin UI 後臺進行設定管理。
- 外掛:Apache ShenYu 使用外掛化設計思想,可以實現外掛的熱插拔,易擴充套件。內建了豐富的外掛,包括 RPC 代理、熔斷和限流、許可權認證、監控等等。
- 選擇器:每個外掛可以設定多個選擇器,對流量進行初步篩選。
- 規則:每個選擇器可以設定多個規則,對流量進行更細粒度的控制。
外掛、選擇器和規則執行規則:
當流量進入到 Apache ShenYu 閘道器之後,會先判斷是否有對應的外掛,該外掛是否開啟;
然後判斷流量是否匹配該外掛的選擇器。
然後再判斷流量是否匹配該選擇器的規則。
如果請求流量能滿足匹配條件才會執行該外掛,否則外掛不會被執行,處理下一個。
他們之間的資料關係,資料庫 UML 圖:
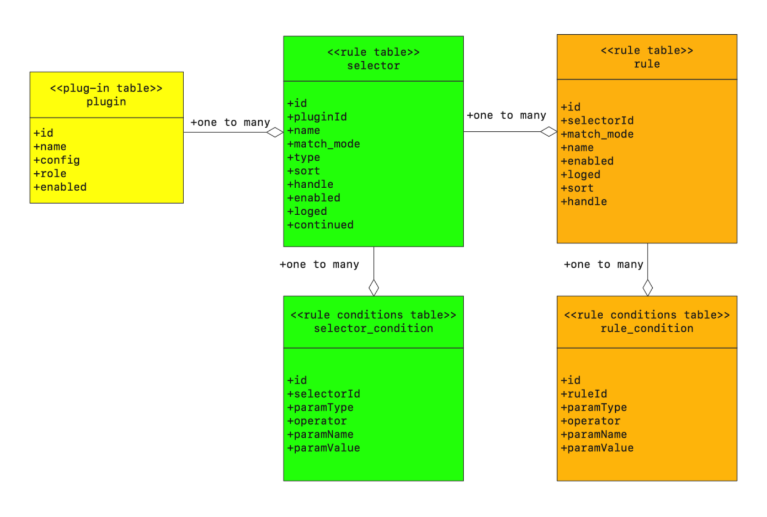
(來自:https://shenyu.apache.org/zh/docs/design/database-design)
說明:一個外掛可以對應多個選擇器,一個選擇器可以對應多個規則,一個規則可以對應多個匹配條件。
3.3 ShenYu Admin 後臺管理
Apache ShenYu Admin 是閘道器的後臺管理系統,能夠視覺化管理所有外掛、選擇器和規則,設定使用者、角色、控制資源。
這些更改通過資料同步到閘道器的 JVM 記憶體裡。
Admin 使用檔案:https://shenyu.apache.org/zh/docs/user-guide/admin-usage/data-permission
後臺介面:

3.3 外掛
內建外掛
ShenYu 內建了很多外掛。在 ShenYu Admin 後臺可以設定這些外掛。
比如設定 hystrix 熔斷保護服務的外掛。新增外掛、設定插進的步驟詳情請檢視檔案。
內建外掛的檔案:https://shenyu.apache.org/zh/docs/plugin-center/http-process/contextpath-plugin。
ShenYu 閘道器內建了很多外掛,詳情看檔案。
自定義外掛
檔案:https://shenyu.apache.org/zh/docs/developer/custom-plugin
3.4 擴充套件功能
SPI 擴充套件
比如自定義負載均衡策略,可以對 org.apache.shenyu.loadbalancer.spi.LoadBalancer 進行自定義擴充套件。
詳情檔案:https://shenyu.apache.org/zh/docs/developer/spi/custom-load-balance
外掛擴充套件
也就是自定義外掛功能,上文有講到過。
自定義 Filter
這裡有一個範例,對 org.springframework.web.server.WebFliter 進行擴充套件。檔案地址 -> filter 擴充套件
3.5 叢集
第一種:
利用 Nginx 負載均衡能力實現叢集功能,檔案地址->叢集。
第二種:
Apache Shenyu-nginx 模組實現叢集,https://github.com/apache/shenyu-nginx,在 github 上的 README 看到這個功能模組還是一個實驗性質的(到目前2022.10.21)。
四、參考
- https://github.com/Netflix/zuul/wiki/Getting-Started zuul1 wiki
- https://github.com/Netflix/zuul/wiki/Getting-Started-2.0 zuul2 wiki
- https://netflixtechblog.com/zuul-2-the-netflix-journey-to-asynchronous-non-blocking-systems-45947377fb5c
- https://github.com/Netflix/zuul/wiki/Filters zuul2 filter doc
- https://spring.io/projects/spring-cloud-gateway
- https://shenyu.apache.org/ ShenYu site
- https://shenyu.apache.org/zh/docs/plugin-center/http-process/contextpath-plugin ShenYu 外掛檔案
- https://shenyu.apache.org/zh/docs/developer/custom-filter ShenYu Filter 擴充套件
- https://shenyu.apache.org/zh/docs/deployment/deployment-cluster ShenYu 叢集