微服務系列之分散式紀錄檔 ELK
1.ELK簡介
ELK是ElasticSearch+LogStash+Kibana的縮寫,是現代微服務架構流行的分散式紀錄檔解決方案,旨在大規模服務的紀錄檔集中管理檢視,極大的為微服務開發人員提供了排查生產環境的便利。如果規模較小的紀錄檔量,直接使用ElasticSearch、Logstash、Kibana是可以滿足其應用的,但是對於紀錄檔量較大的中大規模服務叢集來說,這3箇中間會引入Filebeat、Kafka、Zookpeer三個中間來大幅度提升採集效能、可靠性、可延伸性。目前來說,大部分公司使用的解決方案架構如下圖:

此篇文章,我們一起來熟悉整個流程的搭建,為了方便演示,環境基於docker(正常情況下,因為這套系統是直接linux部署的,因為開銷實在是很大)。
2.API服務
先建一個api服務,使用過濾器,讓請求前後都會產生紀錄檔
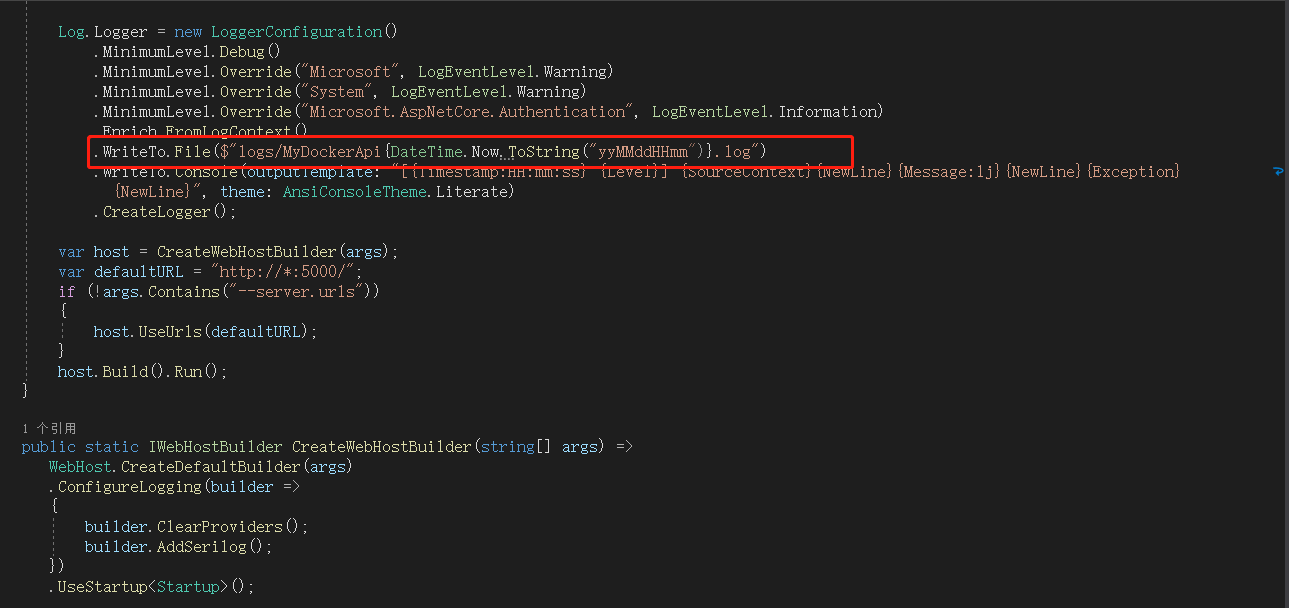
我這裡,將紀錄檔寫到根目錄下logs資料夾,以MyDockerApi *.log產生紀錄檔檔案,接下來,釋出,並上傳到linux伺服器,並用docker啟動,不會的同學傳送門:https://www.cnblogs.com/saltlight-wangchao/p/16646005.html。

由於docker的隔離性,想要採集紀錄檔,必須給服務docker掛載到linux宿主機的盤內,上圖就是我為該API服務建立的紀錄檔寫入目錄,因為可能一個宿主機上可能有多個API服務,所以,可以按照規則,繼續新建服務資料夾,用於存放不同API服務的紀錄檔,我這裡就弄了一個先。
docker run --name API8082 -p 8081:5000
-v /etc/localtime:/etc/localtime --解決 docker 容器時間與本地時間不一致
-v /home/fileBeate/logs/mydockerapi1:/app/logs --掛載目錄,降容器的app/logs目錄掛載到宿主機,我們要指定該服務採集的目錄
my1api
啟動後,請求該服務
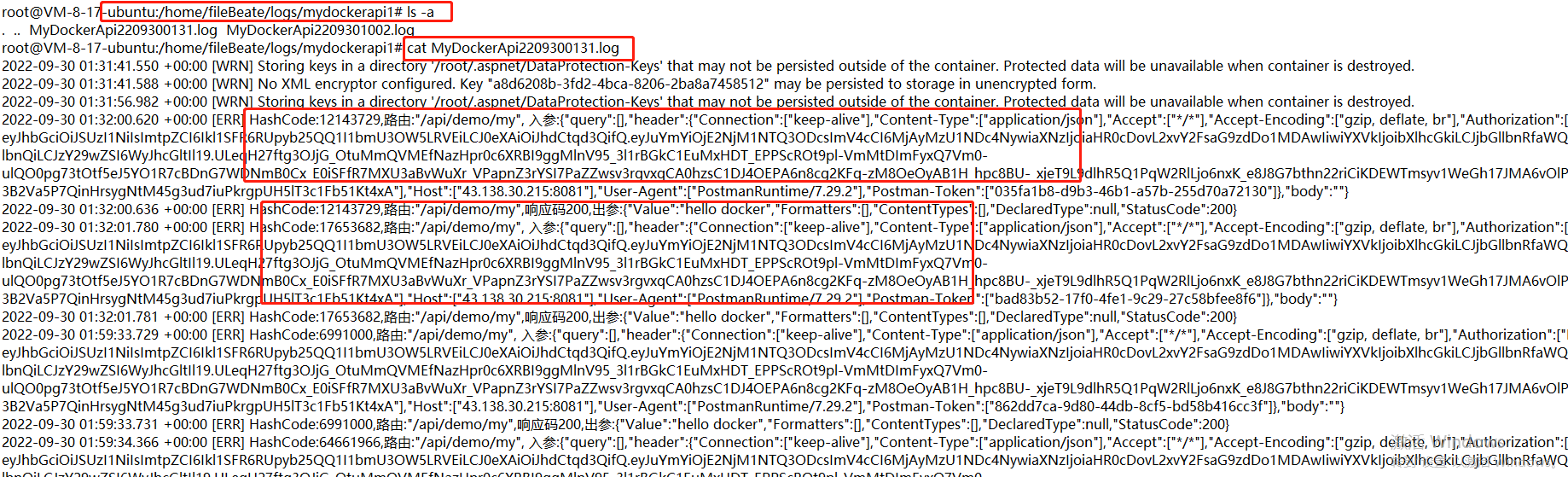
至此,api服務所產生的紀錄檔,已經寫到我們要採集的指定目錄裡。
3.Filebeat
Filebeat是用於監視、採集、轉發指定位置的檔案輕量級開源工具,使用golang編寫,就採集來說,其效能和資源利用率遠好於基於jvm的logstash。
在這裡,filebeat做為kafka的生產者
1)拉取filebeat映象
docker pull docker.elastic.co/beats/filebeat:6.4.2
2)建立filebeat.yml組態檔,進行vim修改
基礎的設定
--- filebeat.inputs: - type:log enabled: true fields: log_topics: mydockerapi1 --命名以服務名字,注意,因為一臺宿主機可能有多個服務,而我們採集也要分開,再來一組-type paths: - /usr/share/filebeat/mydockerapi1-logs/*.log --這裡是docker內的路徑,千萬別寫錯了。如果是 output.kafka: hosts: - "10.0.8.17:9092" --kafka的地址 topic: "elk-%{[fields][log_topics]}" --訊息佇列的topic
3)執行
docker run --restart=always --name filebeat -d
-v /home/filebeat.yml:/usr/share/filebeat/filebeat.yml
-v /home/fileBeate/logs/mydockerapi1/:/usr/share/filebeat/mydockerapi1-logs
docker.elastic.co/beats/filebeat:6.4.2
進入filebeat容器內部如下圖,可以看到已經採集到紀錄檔檔案

使用 docker logs -f filebeat 命令,檢視filebeat紀錄檔

上圖可見,採集完紀錄檔後,像kafka傳送了
4.Zookeeper/Kafka
kafka是結合zookeeper一起使用的,kafka通過zookeeper管理叢集設定,選舉leader,以及在consumer group發生變化時進行rebalance。producer使用push模式將訊息釋出到broker,consumer使用pull模式從broker訂閱並消費訊息,這裡不過多描述,感興趣的可以去詳細檢視。
1)拉取zookeeper映象並執行
docker pull zookeeper:latest docker run -d --name zookeeper -p 2181:2181 -t zookeeper:latest

2)拉取kafka映象並執行
docker pull wurstmeister/kafka:latest docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=10.0.8.17:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://10.0.8.17:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -t wurstmeister/kafka:latest

3)檢視filebeat是否採集完紀錄檔,是否之前設定的topic寫進來,直接執行下面命令
docker exec -it kafka bash cd /opt/kafka/bin kafka-topics.sh --zookeeper 10.0.8.17:2181 --list

可見,我們採集的紀錄檔已經寫進來了。接下來,使用exit命令退出容器。
5.Logstash
Logstash是一個接收、過濾、輸出的元件,三塊形成一個管道,其實這個的功能性很強大,設定起來也很繁瑣,我們這裡主要是收集各個API服務的紀錄檔用,所以就做基礎設定即可
1)拉取映象
docker pull docker.elastic.co/logstash/logstash:6.4.3
2)建立組態檔並設定
input{ kafka{ 資料來源來自kafka,此時logstash做為消費者 bootstrap_servers => "10.0.8.17:9092" kafka地址 topics_pattern => "elk-.*" 消費的主題匹配elk-開頭的 consumer_threads => 5 -消費執行緒數 decorate_events => true codec => "json" auto_offset_reset => "latest" } } output { elasticsearch { 輸出到es hosts => ["10.0.8.17:9200"] es地址 index => "ts-mydockerapi1" es的索引 } }
上述是簡單的設定,生產中在輸出output塊中,,要根據topic來輸出到不同的索引設定如下:
output { if [@metadata][kafka][topic] == "elk-mydockerapi1" { elasticsearch { hosts => "http://10.0.8.17:9200" index => "ts-mydockerapi1" timeout => 300 } } 這裡可以多個if判斷,輸出到不同的索引中 stdout {} }
3)執行
docker run --name logstash -d -e xpack.monitoring.enabled=false -v /home/logstash:/config-dir docker.elastic.co/logstash/logstash:6.4.3 -f /config-dir/logstash.conf

至此logstash啟動成功,紀錄檔顯示正常。至於繁瑣的過濾設定,主做運維的同學,可以深研究下,後端同學瞭解下就行了。我這期間,老是遇到記憶體溢位的情況,可以改一下,logstash的組態檔,進入docker容器,位置在config/jvm.options,可以修改下記憶體使用。
6.ElasticSearch
簡稱es,elasticsearch 是一個分散式、高擴充套件、高實時的搜尋與資料分析引擎。它能很方便的使大量資料具有搜尋、分析和探索的能力。充分利用elasticsearch的水平伸縮性,能使資料在生產環境變得更有價值。官方概念,我們本篇文章不做深入研究,只就ELK分散式紀錄檔應用來說。
1)拉取映象
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.4.2
2)執行es
docker run --name myes --restart=always -p 9200:9200 -p 9300:9300 -d -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.4.2
3)檢視logstash輸入到es的資料
瀏覽器執行http://你的IP:9200/_search?pretty

紀錄檔資料已經進來了,接下來最後一步,展示紀錄檔。
7.Kibana
kibana是一個開源的分析與視覺化平臺,設計出來用於和elasticsearch一起使用的。你可以用kibana搜尋、檢視、互動存放在elasticsearch索引裡的資料,使用各種不同的圖表、表格、地圖等kibana能夠很輕易地展示高階資料分析與視覺化.
1)拉取映象
docker pull docker.elastic.co/kibana/kibana:6.4.3
2)執行
docker run -d --name kibana -p 5601:5601 -e ELASTICSEARCH_URL=http://10.0.8.17:9200 docker.elastic.co/kibana/kibana:6.4.3
3設定展示
執行起來後,開啟你的ip:5601,剛進來會讓你建立索引,步驟如下圖

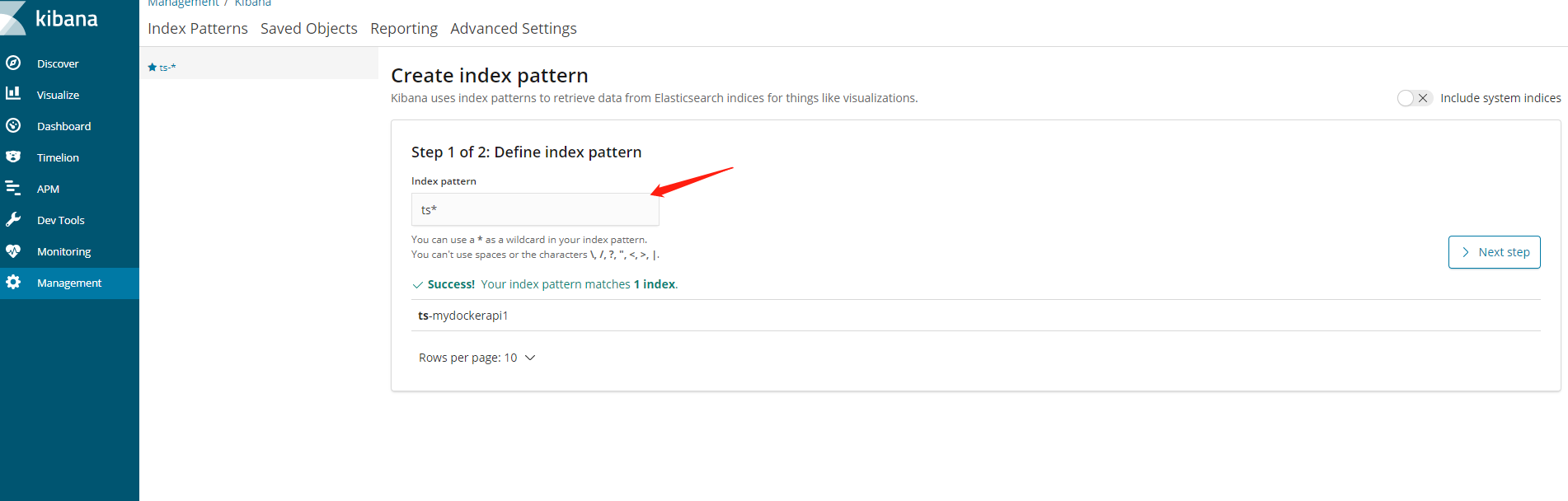
選擇next step按鈕,建立完畢,如下圖
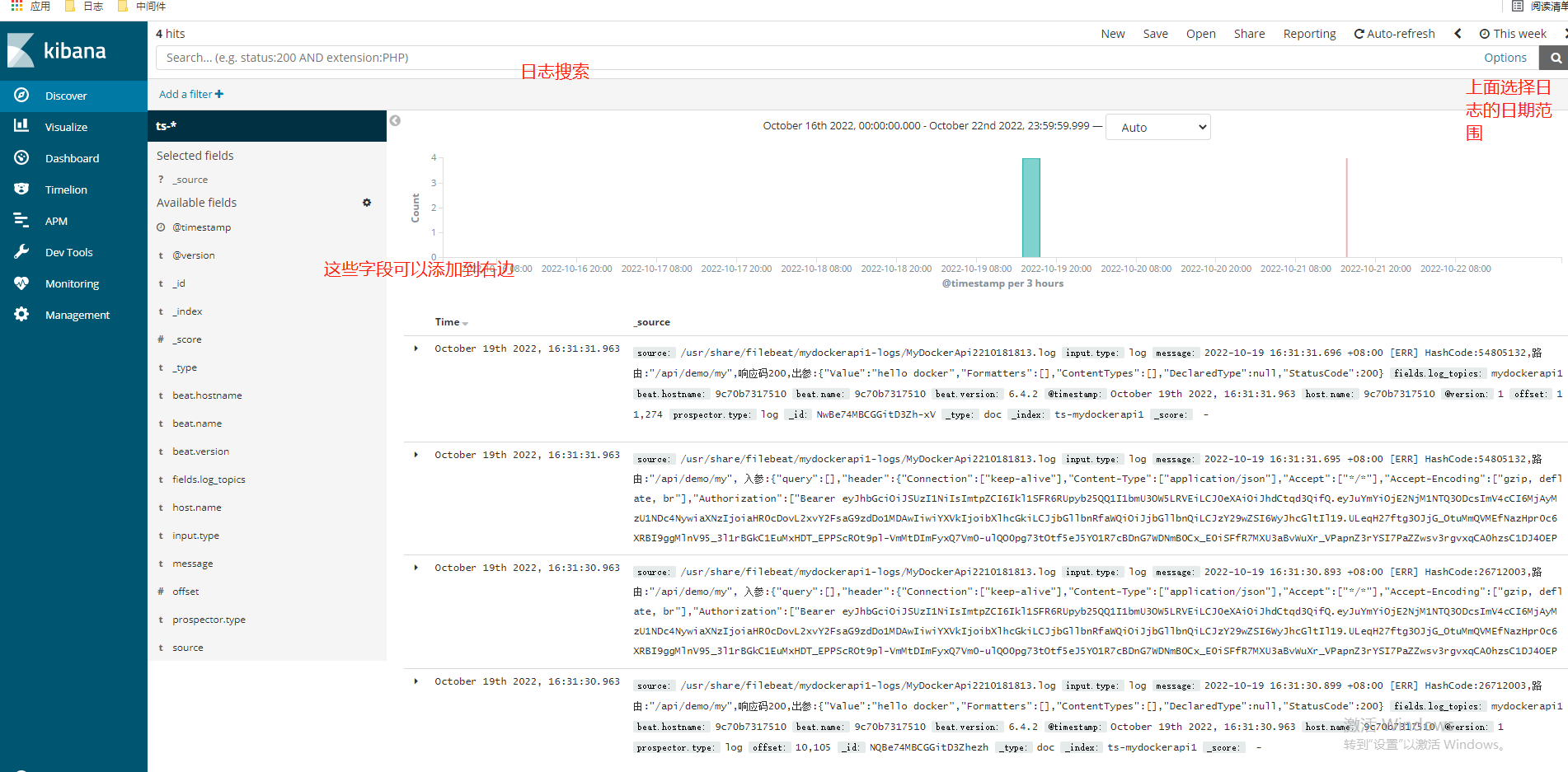
由於我這個linux伺服器太弱了,ELK完全執行起來太卡了,就不繼續做了,可以再建個API服務,模擬多個服務紀錄檔,通過ELK採集,在kibana裡,根據logstash輸入進es的索引,來展示對應服務的紀錄檔,如下圖:
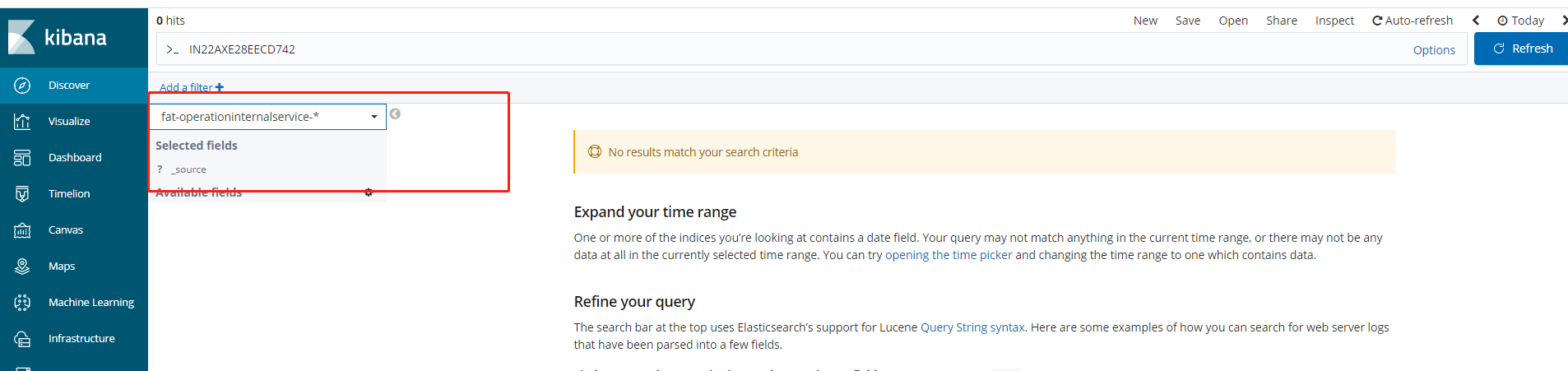
這裡就可以選擇對應API服務的索引紀錄檔了。。。
最後做為後端研發來說,一個有規模的做微服務的團隊,ELK的搭建不是直接購買雲產品,就是由運維來搭建,但是小規模團隊,還是需要後端同學來搞的,總之,後端研發人員可以不實踐,但是最好要了解一下整體流程。OK本文到此結束。