Magnet: Push-based Shuffle Service for Large-scale Data Processing
本文是閱讀 LinkedIn 公司2020年發表的論文 Magnet: Push-based Shuffle Service for Large-scale Data Processing 一點筆記。
什麼是Shuffle
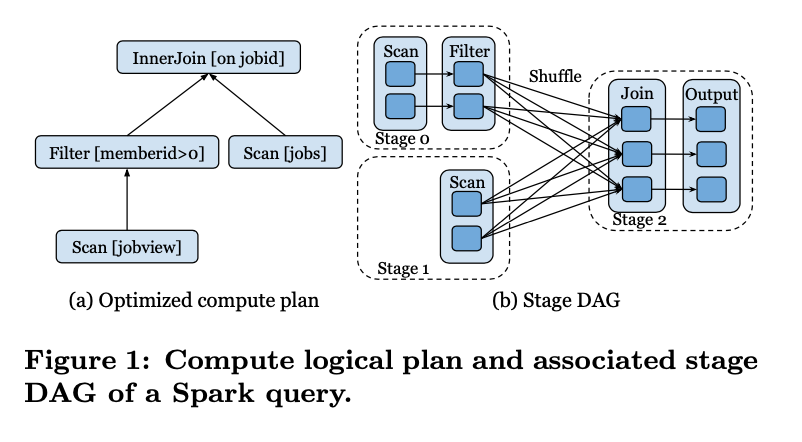
以上圖為例,在一個DAG的執行圖中,節點與節點之間的資料交換就是Shuffle的過程。雖然Shuffle的過程很簡單,但是不同的引擎有不同的實現。
以shuffle資料傳輸的媒介來看
- 有基於磁碟的shuffle,例如Map/Reduce ,Spark,Flink Batch中,上下游之前的資料都是需要落盤後來進行傳輸,這類通常是離線處理框架,對延遲不敏感,基於磁碟更加可靠穩定。
- 有基於記憶體的pipeline模式的shuffle方案,例如Presto/Flink Streaming中,主要是對時延比較敏感的場景,基於記憶體Shuffle,通過網路rpc直接傳輸記憶體資料
而基於本地磁碟的Shuffle實現中又有很多種不同的實現
- 有基於Hash的方案,每個map端的task為每個reduce task 產生一個 shuffle檔案
- 有基於Sort方案,每個map端的task按照 partitionId + hash(key) 排序,並最終merge成一個檔案以及一個index檔案,在reduce端讀取時根據每個task的index檔案來讀取相應segment的資料
以部署方式來看
- 有基於worker的本地shuffle的方案,直接通過worker來提供讀寫的功能
- 有基於external shuffle的實現,通常託管於資源管理框架,在Yarn框架中就可以實現這種輔助服務,這樣就可以及時的釋放worker計算資源
- 有基於Remote shuffle的實現,在雲端計算時代逐漸成為主流,因為其存算分離的架構往往能帶來更好的可延伸性並且網路頻寬的提高使得
co-locate_也許_不再那麼重要。
Spark Shuffle實現
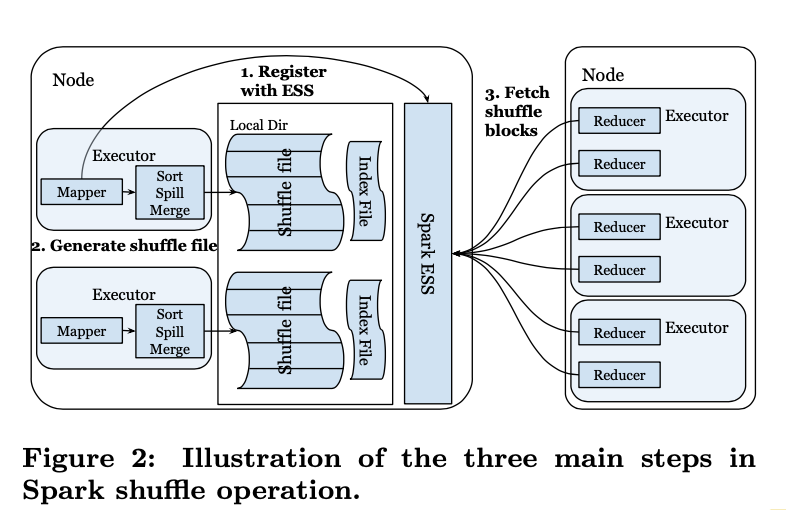
這裡再大致介紹下spark原生的external sort shuffle的詳細流程
- 每個spark executor啟動後和本地節點的external shuffle service註冊,同一個機器的多個executor會共用這個機器上的shuffle service服務。
- map stage處理完資料之後會產出兩個檔案 shuffle data 和 index檔案,map task會按照partition key 來進行排序,屬於同一個reduce 的資料作為一個Shuffle Block,而index檔案中則會記錄不同的Shuffle Block 之間的邊界offset,輔助下游讀取
- 當下遊reduce task開始執行,首先會查詢Spark driver 得到input shuffle blocks的位置資訊,然後開始和spark ESS建立連結開始讀取資料,讀取資料時就會根據index檔案來skip讀取自己task那個shuffle blocks
痛點
在LinkedIn公司主要採用了Spark自帶的基於Yarn的External sorted shuffle實現,主要遇到痛點:
All-To-All Connections
map 和 reduce task之間需要維護all-to-all 的連結,以M個Map端task,R和Reducer端task為例,理論上就會建立M * R 個connection。
在實際實現中,一個executor上的reducer可以共用一個和ess的tcp連結。因此實際上的連結數是和executor個數 E 和ess節點數 S相關。但是在生產叢集中 E 和 S 可能都會達到上千,這時連結數就會非常的客觀,很容易帶來穩定性的問題,如果建立連結失敗可能會導致相關stage進行重跑,失敗代價很高。
Random IO
從上面的讀取流程我們可以看到因為多個reduce task資料在同一個檔案中,很容易產生隨機讀取的問題,並且從linkedin公司觀察到的這些block通常都比較小,平均只有10KB。而LinkedIn shuffle叢集主要使用的HDD磁碟,這個問題就會更大。並且隨機讀取以及大量的網路小包會帶來效能的損失。
也許我們會想到說是否可以有辦法來通過調參來讓Shuffle Block 變大而減輕隨機小IO的問題呢?比如把reduce task端的並行調小,這樣每個task的資料量必然就變大了。
論文中也對此做了闡述,沒法通過簡單的調整reduce task的並行來增大shuffle block size的大小。
假設有一個M個mapper,R個reducer的任務,總的shuffle資料量為D。為了保持每個task處理的資料量恆定,當總資料量增長的時候,map和reduce的並行都要等比增長。
而shuffle block 大小就是  , 為什麼 是
, 為什麼 是  呢,從上面的流程中可以看到每個map端可以近似看做是維護了R個reduce的block。所以總的block數是 。
呢,從上面的流程中可以看到每個map端可以近似看做是維護了R個reduce的block。所以總的block數是 。
那麼當資料量增長時,並且為了保證每個task處理的資料量恆定,即效能不下降,那麼shuffle block size必然會減小。最後也因為reduce端資料分散在所有的map端的task,導致不太能利用data locality的特性。
Magent 設計概要
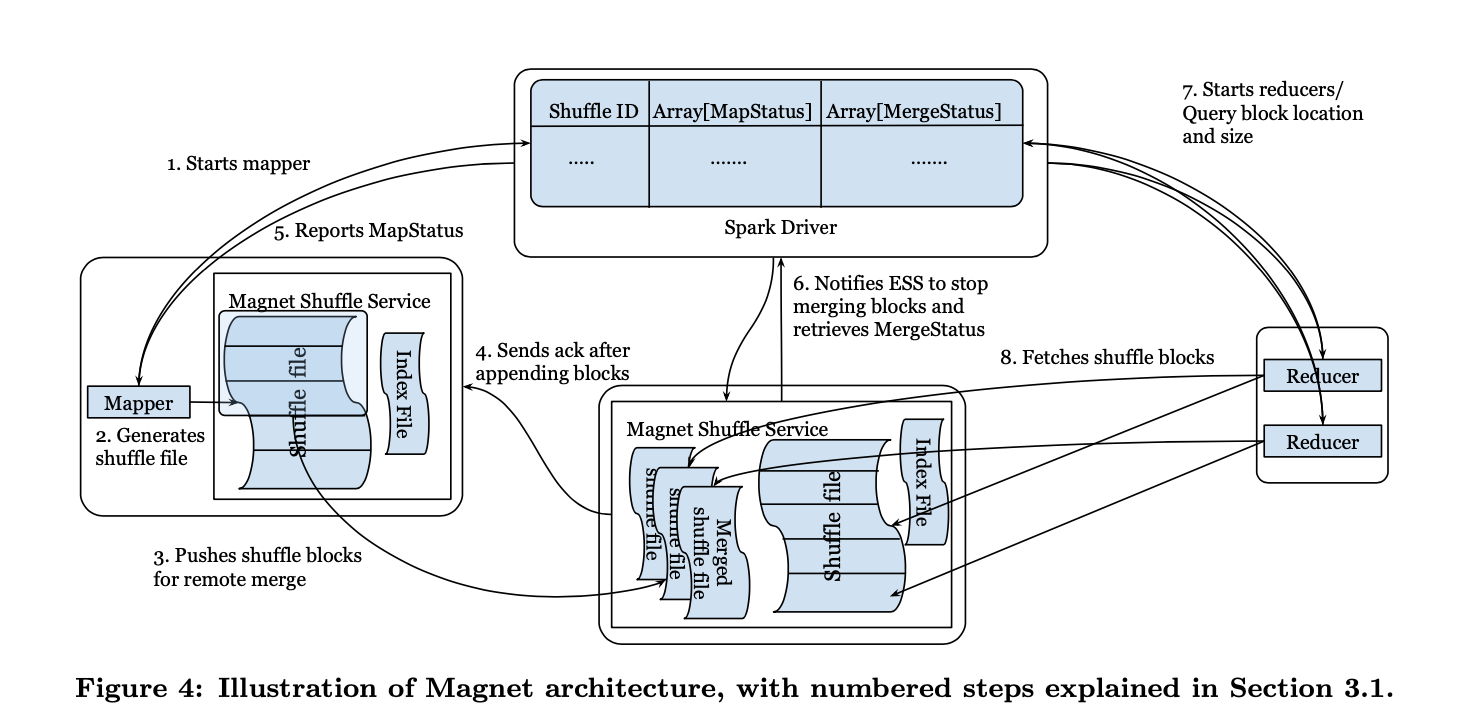
總體架構
Push Merge Shuffle
Mapper 端的shuffle資料會push到遠端的 shuffle service,並按照reduce端合併成一個檔案。這樣shuffle 檔案的大小就可以提高到MB級別。
這裡Magnet主要考慮儘可能避免給shuffle service帶來過大的壓力(為了穩定性和可延伸性考慮),因此在Magent中,在mapper端,依然會將shuffle資料,首先儲存到本地,然後再按照以下的演演算法,將shuffle blocks打包成一個個chunks傳送到shuffle service。

計算blocks劃分到chunks演演算法
這個演演算法的含義如下:
- 按照
 計算 第 i 個 reduce 資料所應該傳送的shuffle service的下標,
計算 第 i 個 reduce 資料所應該傳送的shuffle service的下標, 表示每臺shuffle service機器所需要分配的Reduce task的數量,當其大於 k 時表示需要傳送到下一個機器,則更新 k 的值為
表示每臺shuffle service機器所需要分配的Reduce task的數量,當其大於 k 時表示需要傳送到下一個機器,則更新 k 的值為 k++ - 當chunk長度沒有超過限制L,將
 (長度為
(長度為  )append到chunk中,並將chunk長度更新為
)append到chunk中,並將chunk長度更新為 
- 當chunk長度超過了限制L,那麼就把 append 到 下一個 chunk中,並將chunk 長度置為 , shuffe service 機器還是為 k。
演演算法最終輸出的是每個 shuffle service 機器和對應的所需要接收的chunk的集合。
這個演演算法保證,每個chunks只包含一個shuffle file中連續的不同shuffle partition 的 shuffle blocks。當達到一定大小後會另外建立一個chunk。但是不同mapper上的同一個shuffle parititon的資料最終會路由到同一個shuffle service節點上。
並且為了避免同時mapper端都按照同一順序往shuffle service 節點寫資料造成擠兌和merge時的檔案並行鎖,所以在mapper端處理chunk的順序上做了隨機化。
在完成打包chunk和隨機化之後,就交由一個專門的執行緒池來將資料從按照chunk順序從本地磁碟load出來,所以這裡就是順序的讀取本地磁碟再push到遠端的shuffle service。Push操作是和Mapper端的task解耦的,push操作失敗不會影響map端的task。
Magnet Metadata
當magnet收到打包傳送來的chunks,首先會根據block的後設資料獲取他的分割區資訊,然後根據shuffle service本地維護的後設資料做處理,shuffle service本地為每個Shuffle partition (reduce partition)維護了以下元資訊
- bitmap 儲存了以及merge的mapper的id
- position offset 記錄了merge 檔案中最近一次成功merge的 offset
- currentMapId 記錄了當前正在merge的 mapper的 shuffle block id
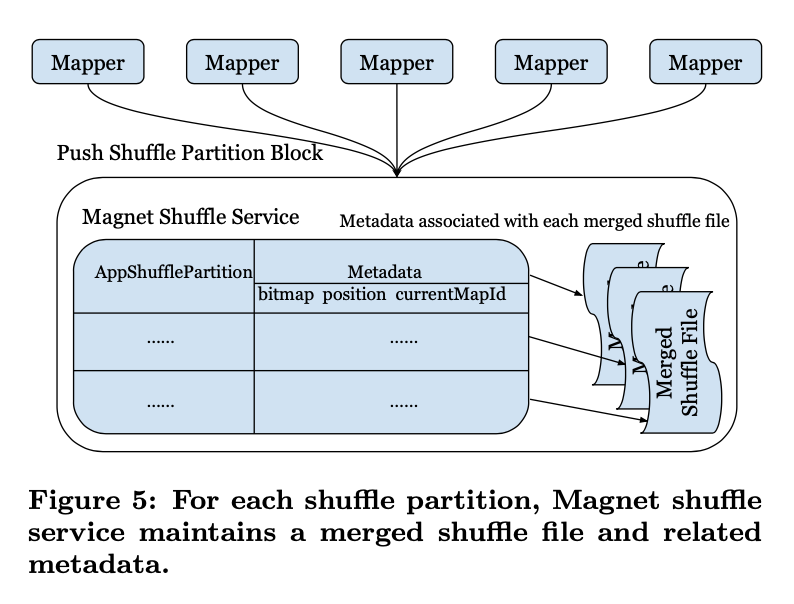
這樣首先可以根據傳送來的shuffle blocks的後設資料判斷資料是否已經merge過了,避免重複儲存。通過currentMapId來避免多個mapper端資料同時往一個檔案merge的問題,而position offset 則可以用作在merge 失敗的時候可以依舊保持檔案能讀到最近一次成功的位置。下一次重寫的時候會依舊從position offset進行覆蓋寫入。通過這幾個後設資料管理,就可以很優雅的處理在檔案merge過程中的寫重複,寫衝突和寫失敗的問題。
Best effort
在Magent的設計中,push/merge的失敗,並不會影響整個任務的流程,可以fallback到讀取mapper端未merge的資料。
- 如果map task 在寫入本地shuffle資料完成之前失敗了,那麼map端task會進行重跑
- 如果map端push/merge失敗,那麼這部分資料就會直接從mapper端讀取
- 如果reduce fetch merge block失敗,那麼也會fallback到從mapper端讀取
我理解要實現這樣的目的,原始資料就需要被保留,所以可以看到在架構圖中Magent Shuffle Service實際上會和executor一起部署(還支援其他的部署形式)。在executor端作為external shuffle service的角色存在,mapper端的資料產出完之後就由原生的shuffle service 節點託管了。所以他可以在以上2、3兩種失敗場景下提供fallback的讀取能力。
同時資料是否Merge完的資訊是在Spark Driver中通過MapStatus和 MergeStatus兩個結構來進行維護的,下游讀取資料時就是由driver來進行是否fallback的邏輯。
從整體上看Push/Merge 的操作可以理解為完全由Magent Shuffle Service節點託管的資料搬遷合併的動作(將各個mapper處的資料搬遷合併成redcuer端的資料),通過資料寫兩次的行為使得mapper端寫資料和合並解耦,並且在fault tolerance的設計中也利用了寫兩次這個行為所帶來的備份的好處。
同時我們需要關注到雖然通過這個操作,將mapper端的隨機讀取轉化成了順序讀取,但是在shuffle service時merge時,其實還是random write,這在資料重組的過程中是必然的。但是由於os cache 和 disk buffer的存在,會使得random write的吞吐比random read的吞吐大很多。
Flexible Deployment Strategy
Magnet支援兩種模式的部署
- on-perm 表示和Spark計算叢集一起部署,作為external shuffle service的方式存在。
- cloud-based 表示以存算分離的模式部署,這樣就是以Remote shuffle service的方式部署。
在on-perm的叢集中,Spark driver可以很好的利用data locality的特性,在push/merge節點結束後,可以將reduce task儘可能排程到資料所在的節點上,可以直接讀取本地資料,效率更高,減少了網路的傳輸也不容易失敗。
Handling Stragglers and Data Skews
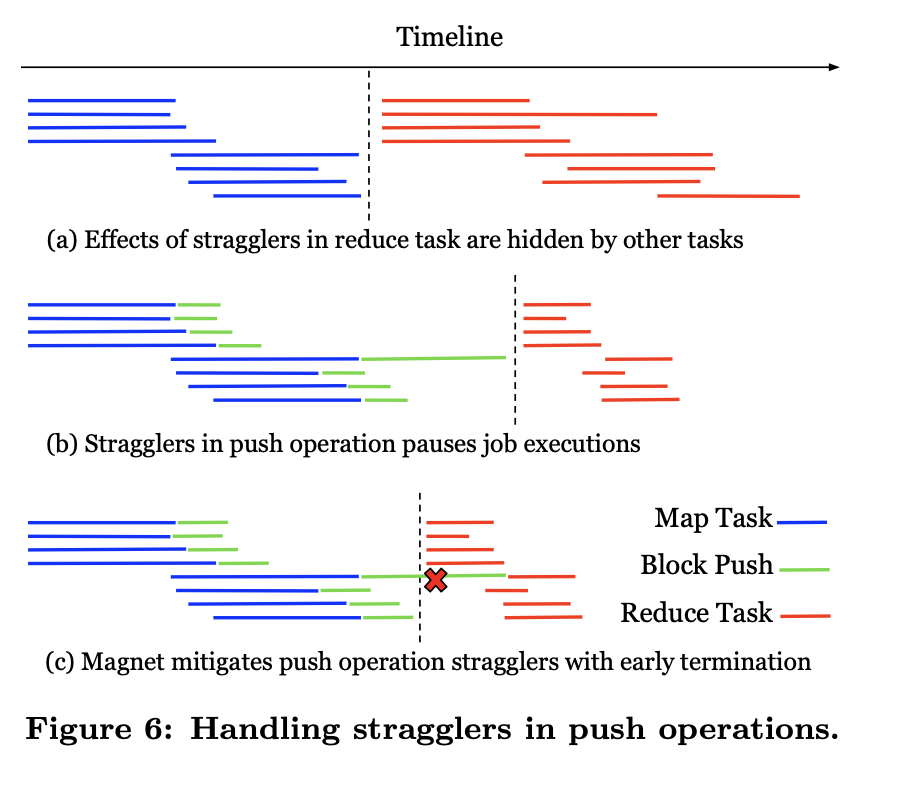
因為Spark計算引擎是BSP模型,所以在map端階段全部完成之前reduce端不會開始計算,因此在Push/Megre階段,為了防止部分Push/Merge較慢影響下游reduce task開始執行。Magnet支援了最大的超時機制,利用上面提到的fallback行為,在超時之後就標記該map端的分割區為unmerged,這樣就跳過了這部分慢節點,直接開始reduce階段。
而針對資料傾斜場景,為了避免reduce端合併的檔案過大,這時Magent的解法是和Spark的Adaptive execution 相結合,根據執行時採集到的每個block的大小,當block 大於某個閾值時,就在合併chunk的階段跳過這種block,還是通過fallback行為直接讀取原來mapper端較大的資料塊
Parallelizing Data Transfer and Task Execution
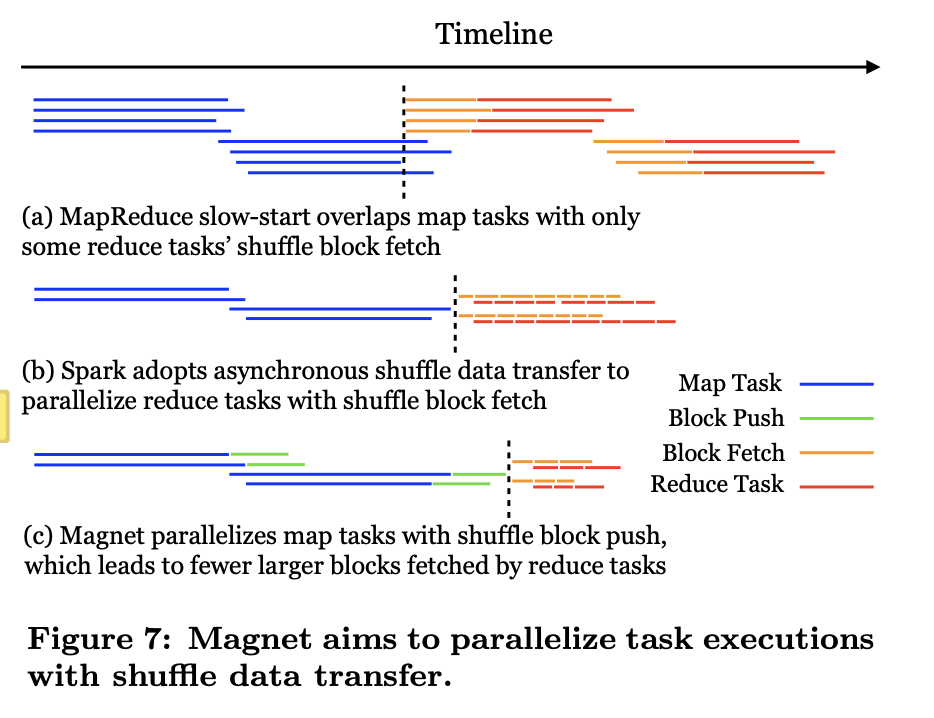
在Hadoop的Map-Reduce模型中,通過 "Slow start" 技術可以在Map task都完成之前,部分Reduce task可以先開始進行資料預拉,實現了比較有限的並行化
而在Spark中,通過資料拉取和資料處理的執行緒解耦,這兩者有點類似於一組生產者和消費者。
而在Magnet中也採用了類似的技術,在mapper端Push task 和 mapper task解耦,但是這裡不太理解這個mapper端解耦的收益,因為本身就是在mapper task結束之後才開始進行push task,也就不存在計算執行緒和io執行緒並行的說法。可以理解的是可以通過這個方式和mapper task的框架執行緒解耦。
然後在reduce端,為了最大化並行讀取的能力,不會將reduce端的資料只合併成一個檔案,而是切成多個MB大小的slice,然後reduce task可以發起並行讀取的請求最大化的提高吞吐。
小結
從上面可以看出Magent的幾個設計宗旨
- 儘可能的避免給shuffle service 增大負載
- 所有的排序的動作只會發生在mapper端或者reducer端,所以排序佔用的資源是executor節點的
- merge時不會有資料buffer的動作,資料buffer在executor端完成,在Shuffle Service側只要直接進行資料appen。
- 盡力而為,資料備份讀取提供更好的容錯特性。並很好的利用了這兩份資料做了更多的設計
- 儘管如今普遍都是存算分離的架構,但是在Magent的設計中data locality的特性還是佔據的很重要的位置
How to evaluate
很多系統設計最後對於系統的測試設計其實也很有看點。在論文裡提到了Magent採用了模擬和生產叢集兩個模式來最終衡量新的Shuffle Service的效果。
Magnet 開發了一個分散式的壓測框架,主要可以模擬以下幾個維度
- 模擬shuffle service叢集所會建立的總的連線數
- 每個block塊的大小
- 總的shuffle的資料量
並且可以模擬fetch和push的請求
- fetch請求會從一個Shuffle serice節點將block傳送到多個使用者端
- push請求會從多個使用者端將資料傳送到一個shuffle service節點
那衡量的指標有哪些
- 在不同的block大小下, Magnet完成Push Merge和Reduce fetch的時間已經Spark 原生Shuffle Service完成fetch的時間比較
- Disk IO 衡量在fetch 和 push的場景下,不同的block大小對於磁碟吞吐能力的影響
- Shuffle Service的資源開銷 主要是測試單機的shuffle service,這裡看到一個比較驚奇的資料,在測試的過程中的資源消耗為0.5c 300M,開銷的確很小。
其他的指標資料就不一一列舉了,可以檢視原文相關章節獲取
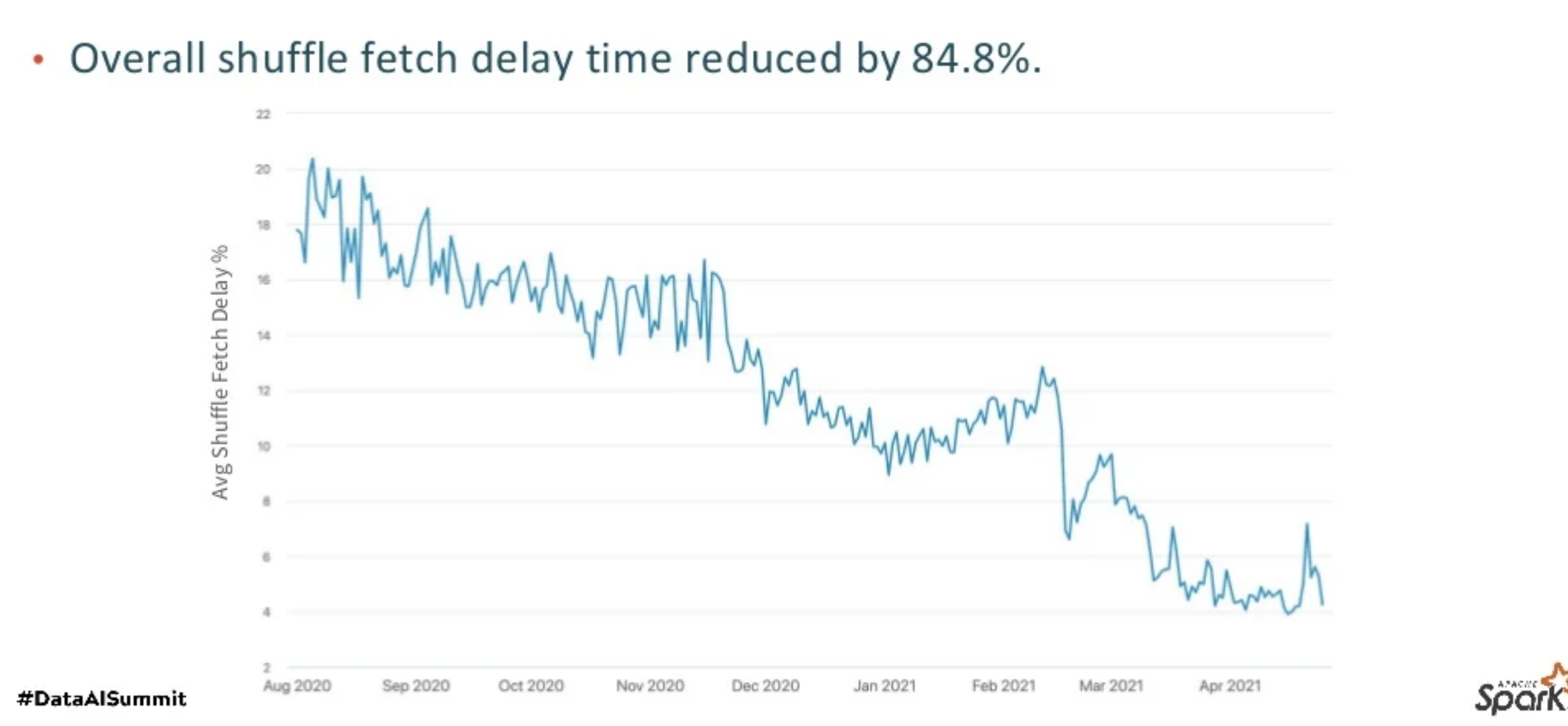
最後上線後的優化效果
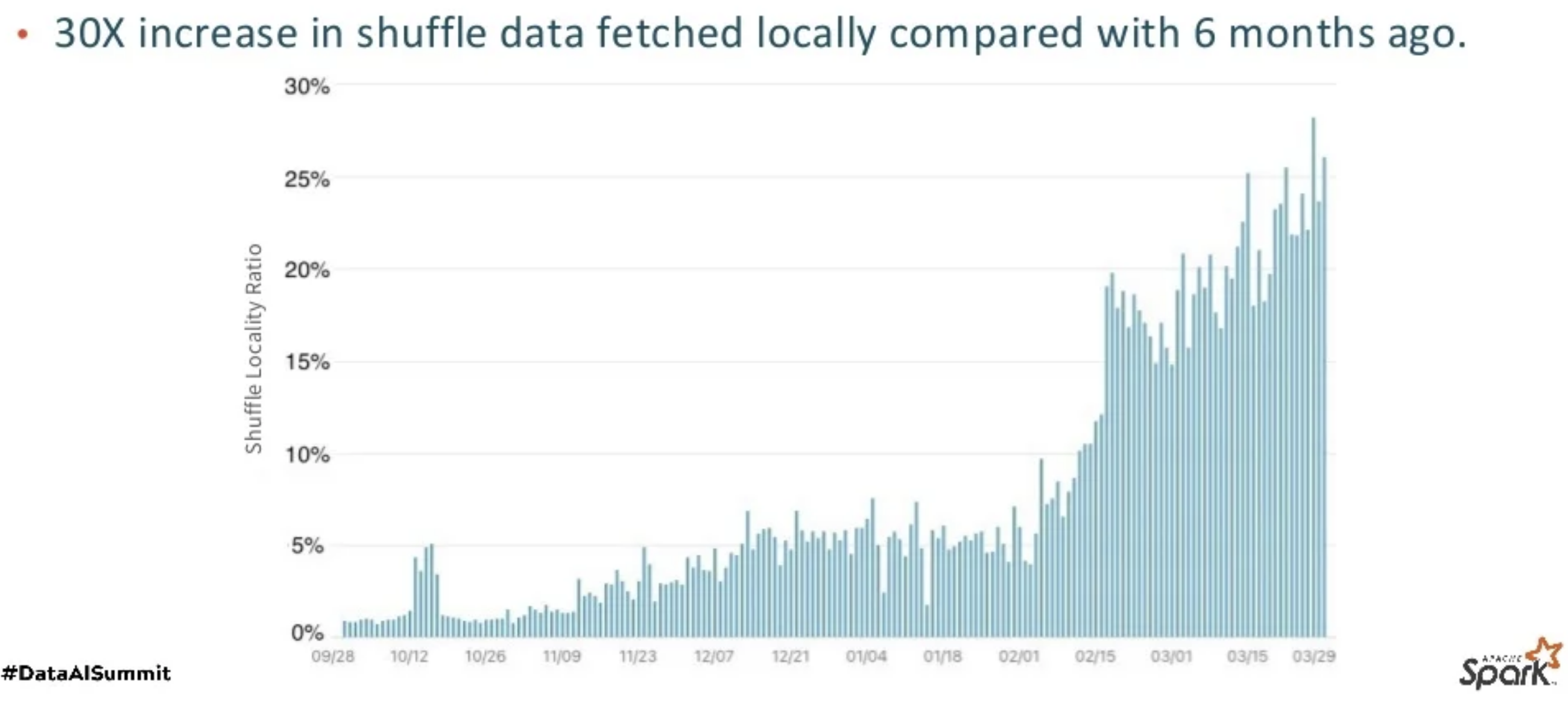
Figure 1: Shuffle locality ratio increase over past 6 months
參考
https://mp.weixin.qq.com/s/8Fhn24vbZdt6zmCZRvhdOg Magent shuffle 解讀
https://zhuanlan.zhihu.com/p/397391514 Magnet shuffle解讀
https://zhuanlan.zhihu.com/p/67061627 spark shuffle 發展
https://mp.weixin.qq.com/s/2yT4QGIc7XTI62RhpYEGjw
https://mp.weixin.qq.com/s/2yT4QGIc7XTI62RhpYEGjw
https://www.databricks.com/session_na21/magnet-shuffle-service-push-based-shuffle-at-linkedin
https://issues.apache.org/jira/browse/SPARK-30602
https://www.linkedin.com/pulse/bringing-next-gen-shuffle-architecture-data-linkedin-scale-min-shen
本文來自部落格園,作者:Aitozi,轉載請註明原文連結:https://www.cnblogs.com/Aitozi/p/16813183.html