分散式之計算高效能
@
一、計算高效能的概念
- 概念
- 計算高效能指的是系統中的介面高效能;如圖:
- 計算高效能指的是系統中的介面高效能;如圖:
二、PPC方案 [懶載入]
- 概念
-
PPC方案也稱為程序建立連線方案;如圖:
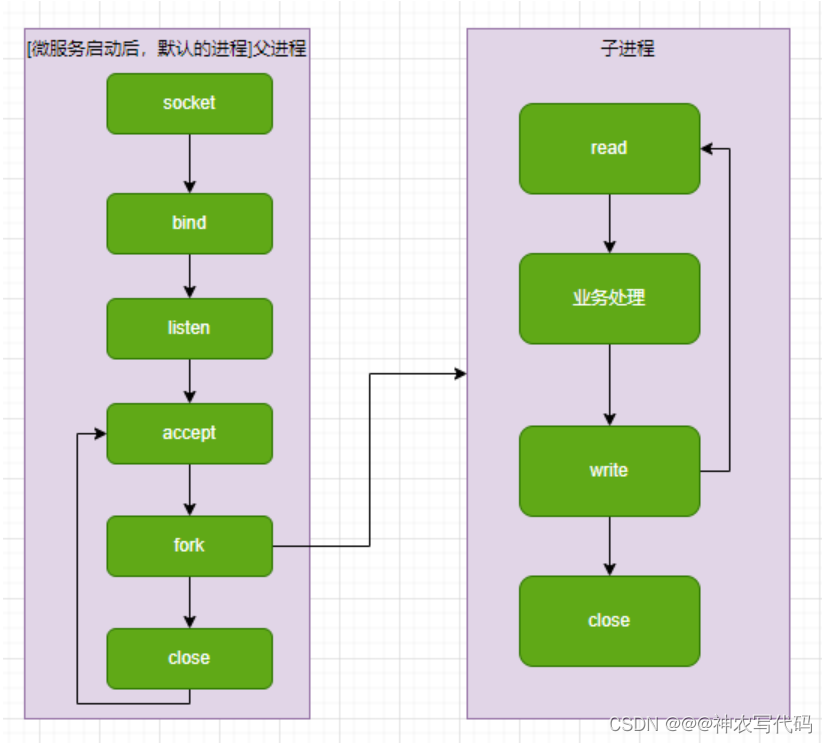
- 以查詢商品為場景
- 當用戶端發起請求到伺服器端,父程序接收使用者端發過來的請求,再將請求轉給子程序進行處理業務邏輯[讀資料,寫資料],處理完成後再返回使用者端。
- 子程序工作流程
1、 建立子程序
2、使用子程序處理業務處理[資料查詢,資料寫入]
3、 關閉子程序
- 以查詢商品為場景
-
- 缺陷
- 太消耗時間,效能低。 [比如使用者端發來100個請求,建立子程序需要時間,子程序CPU切換需要消耗時間]
三、prefork方案 [預先載入程序方案]
- 概念
-
prefork方案稱之為預先載入程序方案,如圖:
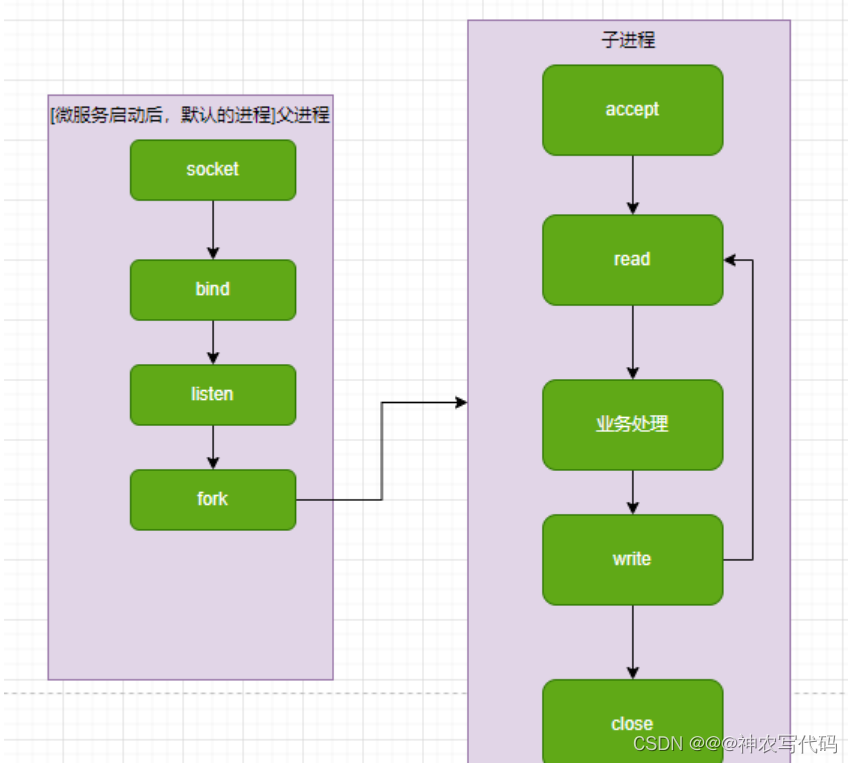
當用戶端發來到伺服器端,父程序接收到請求,再將請求轉給預先載入好的子程序,進行業務處理[資料的讀取,資料的新增]。
-
- 缺陷
- 子程序CPU切換,太消耗時間的問題不能解決。
- 預先建立子程序,太消耗記憶體資源。
- 建立子程序是有限的。
四、TPC方案
- 概念
-
TCP方案稱為程序與執行緒的方案;如圖:

當用戶端傳送請求到伺服器端,伺服器端系統[主程序]接收到請求並建立一個子執行緒來處理業務邏輯[資料讀取,資料新增]。
-
- 缺陷
- 建立子執行緒與執行緒CPU切換,消耗時間[效能低]
- 存在資源競爭的問題[方案:lock 互斥鎖]
- 子執行緒與子程序的區別
- 子執行緒是共用主程序的資源。
- 子程序不共用主程序,複製主程序的資源。
五、prethread方案
- 概念
-
prethread方案可以稱為預先載入執行緒的方案;如圖:

當用戶端傳送請求到伺服器端,伺服器端系統[主程序]接收到請求轉給預先建立好的子執行緒來處理業務邏輯[資料讀取,資料新增]。
-
- 缺點
- 預先建立子執行緒,消耗記憶體資源。
六、執行緒池方案
- 概念
-
執行緒池是將預先建立好的執行緒放線上程池中;如圖:
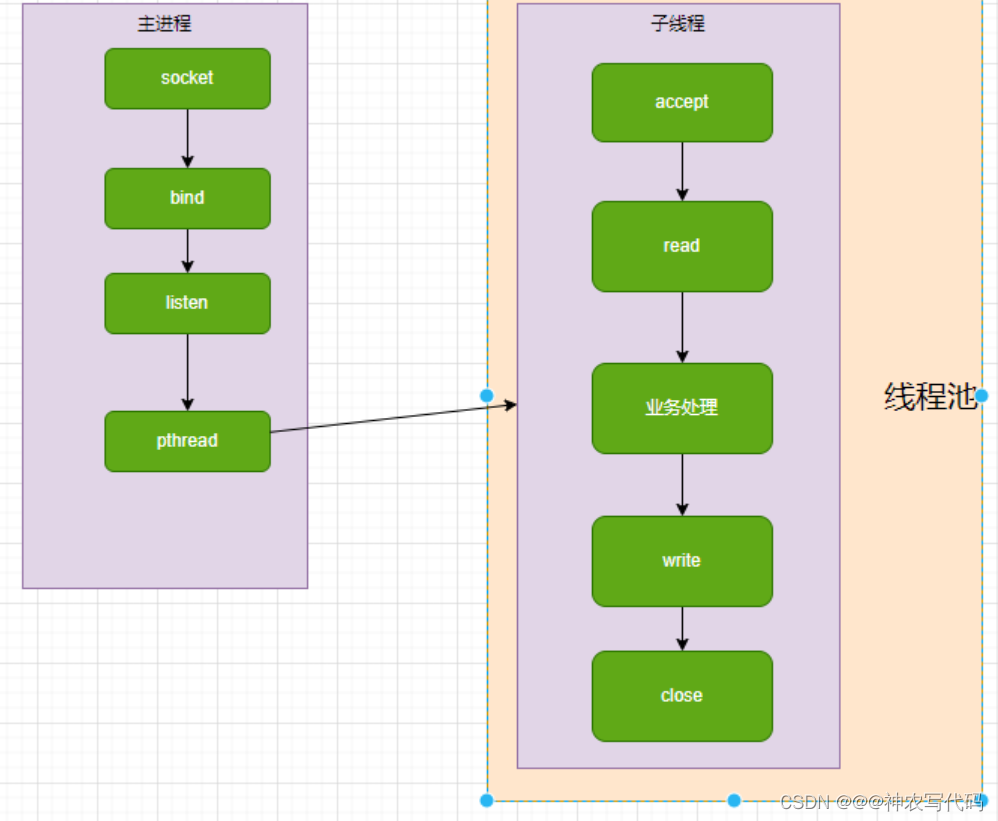
當用戶端傳送請求到伺服器端,伺服器端系統[主程序]接收到請求到執行緒池中取一個執行緒來處理業務邏輯 [資料讀取,資料新增]。
-
- 場景
- 如果當前的業務處理不耗時,可以使用:程序+多執行緒+執行緒的方案
- 當前主程序與子執行緒之間的關係
- 假如當用戶端發起10個請求,主程序會開啟10個子執行緒,當第一個子執行緒在讀取資料時,其他的9個執行緒處於等待的狀態,直到第一個子執行緒讀取資料成功後,主程序將資料返回到使用者端,在處理其他的9個子執行緒,其他的9個子執行緒和第一個執行緒的處理方式是一樣的,一個一個的返回後在處理其他的子執行緒。
- 缺陷
- 如果業務處理非常耗時,效能下降很快。
七、執行緒池--輪詢方案
-
概念
- 當用戶端傳送請求到伺服器端,伺服器端系統[主程序]接收到請求,主執行緒使用for迴圈輪詢的方式迴圈執行緒池中的子執行緒,看哪個子執行緒是空閒的狀態就給哪個請求,並一個一個的返回給使用者端;如圖:

- 當用戶端傳送請求到伺服器端,伺服器端系統[主程序]接收到請求,主執行緒使用for迴圈輪詢的方式迴圈執行緒池中的子執行緒,看哪個子執行緒是空閒的狀態就給哪個請求,並一個一個的返回給使用者端;如圖:
-
缺陷
- 如果並行量大,執行緒數量大,導致輪詢時間過長,消耗CPU的資源,效能下降。
八、多路複用-Reactor [推薦]
-
概念
- 多路複用就是複用一個程序處理請求;如圖:
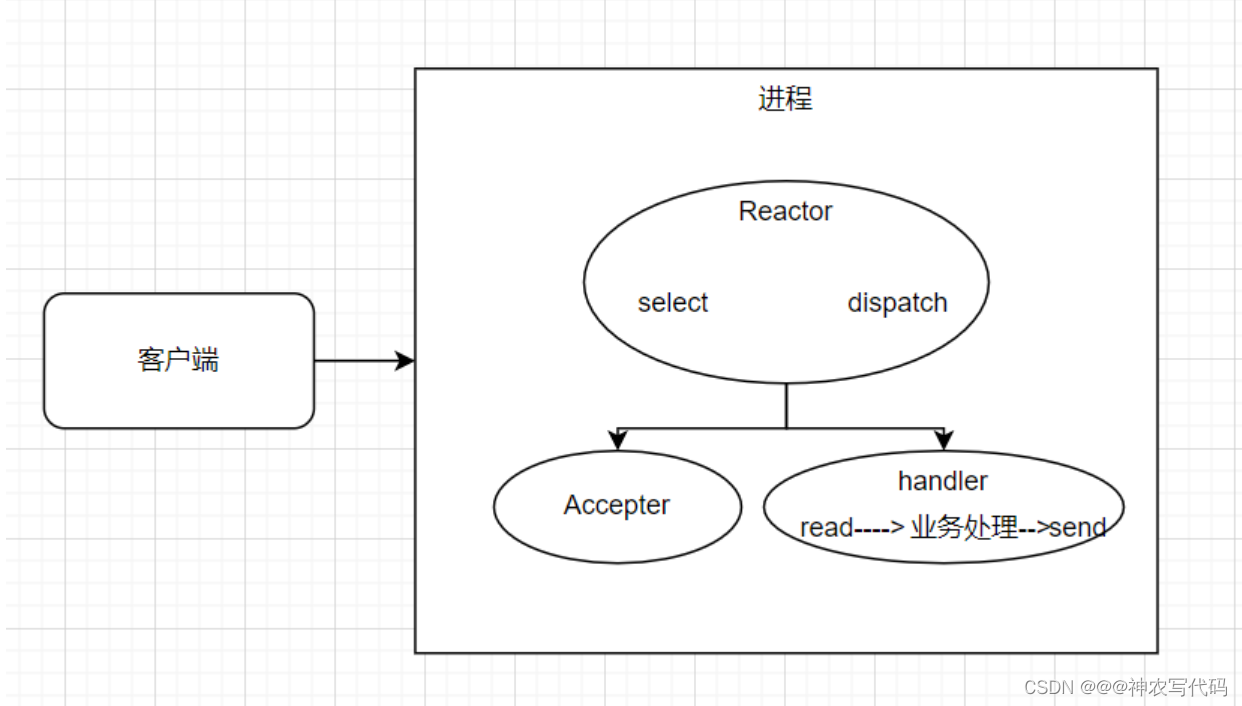
- 多路複用就是複用一個程序處理請求;如圖:
-
核心思想
- 排程,依靠事件處理
當系統[微服務]啟動之後,Reactor框架中的select監聽使用者端的請求,當用戶端發起查詢商品請求後,Reactor框架中的select會判斷是建立連線還是進行業務處理,如果第一次進來收到是連線請求,Reactor回將該請求給dispach,dispach轉給Accept,Accept並創立連線,同時並建立Handler類處理業務邏輯;當用戶端第二次發起請求,Reactor框架中的select發現已經建立連線,Reactor回將該請求給dispach,dispach直接轉給Handler類處理業務邏輯。
- 排程,依靠事件處理
-
優點
- 節約執行緒資源。
- 解決for迴圈消耗CPU資源的問題。[redis就是使用的這種方案]
-
缺陷
- 如果當前請求業務處理耗時,其他的請求需要進行等待[阻塞],會出現效能瓶頸。
九、多路複用-Reactor-多執行緒[推薦]
- 概念
-
多路複用+多執行緒其實就是一個主程序加多個執行緒的處理方案;如圖:
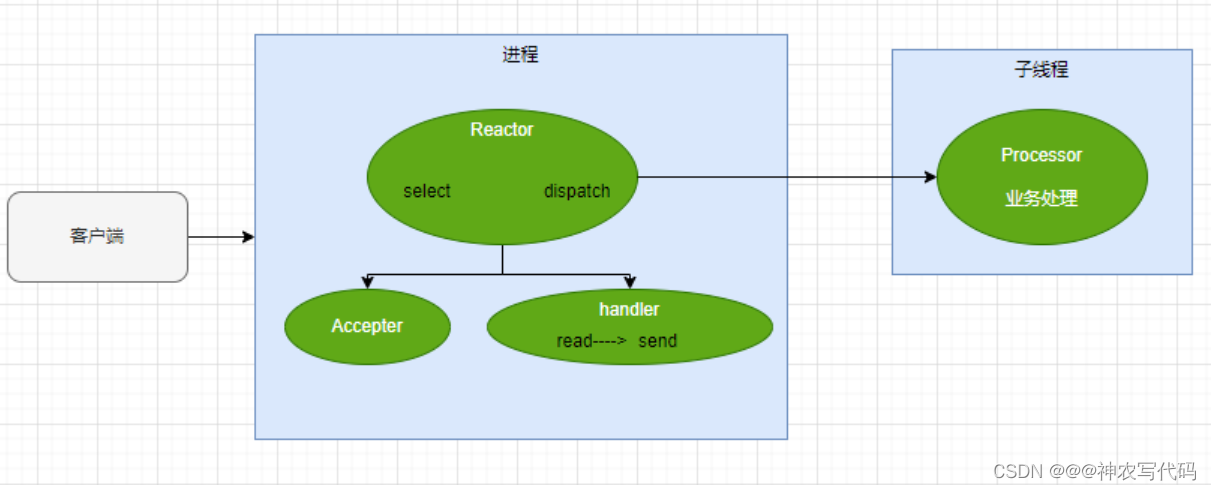
當系統[微服務]啟動之後,Reactor框架中的select監聽使用者端的請求,當用戶端發起查詢商品請求後,Reactor框架中的select會判斷是建立連線還是進行業務處理,如果第一次進來收到是連線請求,Reactor回將該請求給dispach,dispach轉給Accept,Accept並創立連線,同時並建立Handler類根據事件型別在主程序裡面開啟一個新的執行緒處理業務邏輯;當用戶端發起查詢訂單請求後,Reactor框架中的select會判斷是建立連線還是進行業務處理,如果第一次進來收到是連線請求,Reactor回將該請求給dispach,dispach轉給Accept,Accept並創立連線,同時並建立Handler類根據事件型別在主程序裡面開啟一個新的執行緒處理業務邏輯;
誰先完成業務處理,誰就先返回給使用者端。
-
- 場景
- 資料量大的場景
- 資料量小的場景
- 缺陷
- 瞬時高並行時,因為要建立更多的連線和事件,造成效能下降。
十、多路複用-多Reactor-多執行緒[推薦]
-
當用戶端發起請求,主程序Reactor框架的select監聽使用者端的請求,Reactor會將該請求給dispach,dispach轉給Accept,Accept並創立連線後,再將請求交給子程序,子程序會建立一個執行緒處理業務邏輯;[主程序與子程序相互隔離,主程序負責建立連線,子程序建立執行緒,執行緒負責處理業務邏輯。python與go語言符合這種方案,既可以多程序又可以多執行緒;C#與java是單程序多執行緒方案;nginx也是用的多程序的方案] 如圖:

-
缺陷
- 執行緒之間的切換耗時
- 執行緒建立太多,太消耗記憶體資源
十一、Proactor--非同步IO [推薦]
-
概念
- 當用戶端傳送請求到伺服器端的使用者程序,首先通過Proactor initiator初始化,將請求註冊給核心程序中asynchroncus operation processor,同時建立Handler事件處理類,建立成功後註冊到asynchroncus operation
processor,再將請求建立一個Proactor;核心程序接收註冊的請求後,然後執行IO操作【到資料庫查詢資料等業務邏輯】,處理成後通知processor,進行回撥返回使用者端。如圖:

- 當用戶端傳送請求到伺服器端的使用者程序,首先通過Proactor initiator初始化,將請求註冊給核心程序中asynchroncus operation processor,同時建立Handler事件處理類,建立成功後註冊到asynchroncus operation
-
實現場景
- windows IOCP
- Linux epoll(藉助Reactor)
十二、叢集方案
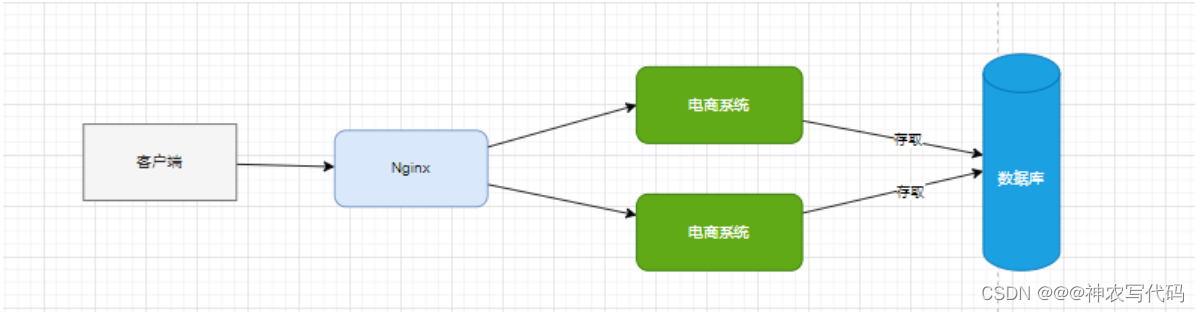
1 使用Nginx部署系統叢集,如圖:
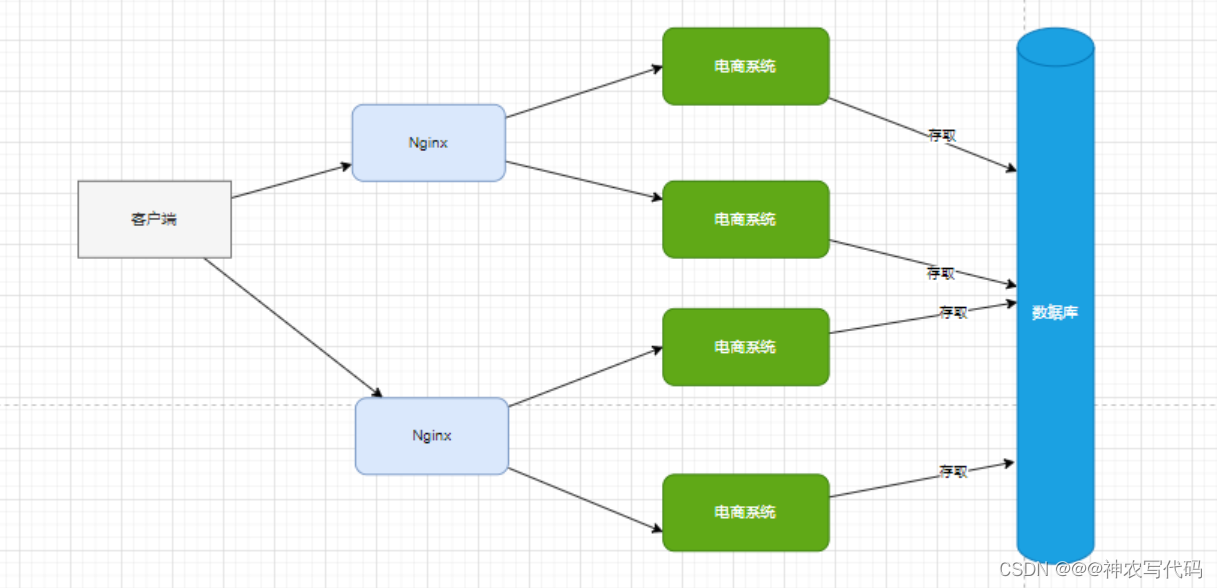
2 使用nginx叢集部署系統叢集,如圖:
3 使用F5部署nginx叢集,如圖:
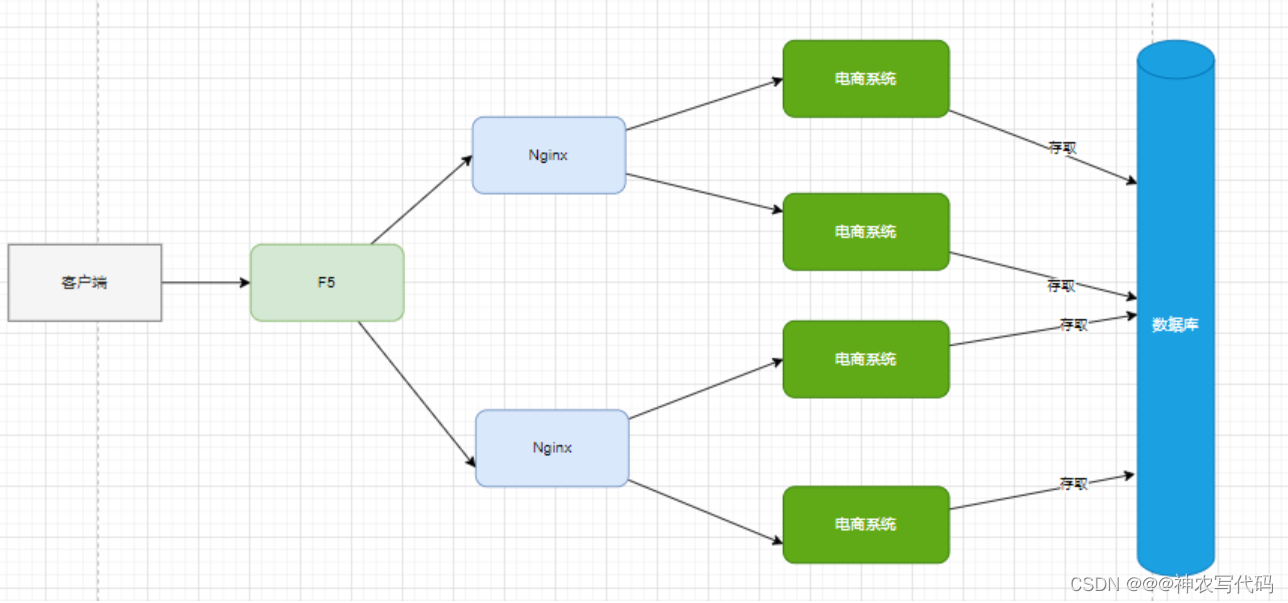
F5處理並行能力差不多在100萬左右。
-
缺陷
- F5裝置太貴,小型公司一般不會去用,大型公司會用。
4 使用DNS伺服器部署F5叢集,如圖:
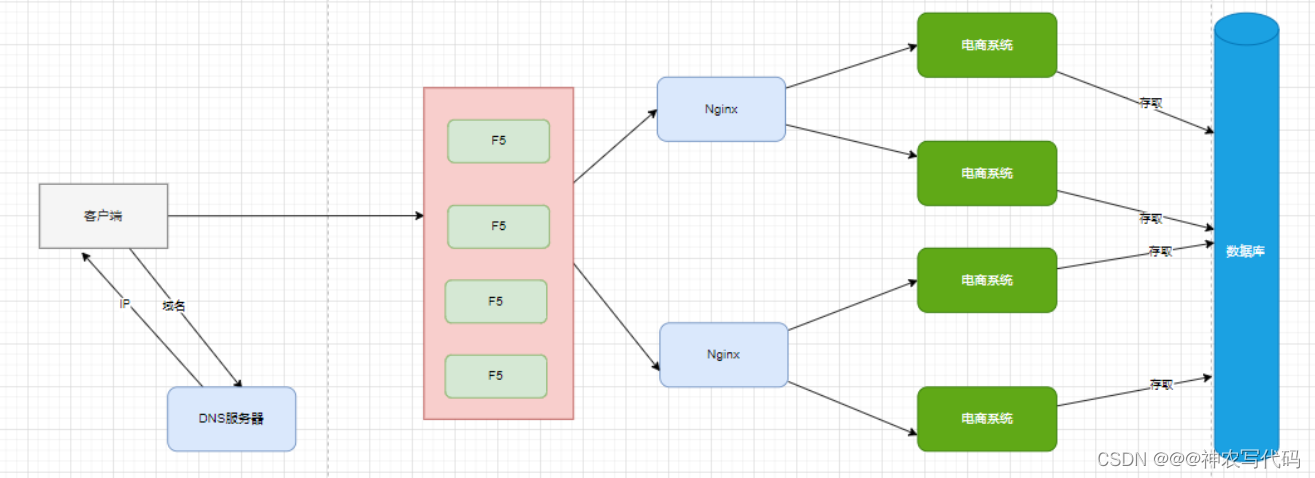
- F5裝置太貴,小型公司一般不會去用,大型公司會用。
-
當用戶端發起請求到dns伺服器,使用負載均衡演演算法獲取到相應的IP地址,再根據地址到相應的F5裝置,F5再用負載均衡演演算法到相應的nginx伺服器,nginx再用負載均衡演演算法到相應的服務處理業務邏輯。
-
缺陷
- F5這種裝置太過於貴重,最起碼兩臺F5裝置起,一臺正常使用,另一臺裝置當做備機使用。
十三、總結
- 方案場景選擇
- 如果資料量小,選擇單Reactor。例如:Redis [8]
- 如果資料量有大,有小,選擇Reactor多執行緒方案。例如:NET,java[9]
- 如果資料量有大,有小,並有瞬間並行,選擇多程序方案。例如:Netty,Dotnetty [10]
- 如果資料量有大,有小,並有瞬間並行,而且資源消耗大,選擇非同步IO。例如:IOCP,epoll ,nginx,Dotnetty [11]
- 以某商城分散式系統為例,看哪些模組使用F5裝置
- 商品模組[獨立的服務(系統)]:可用可不用,分情況來定,[範例隔離]。
- 訂單模組[獨立的服務(系統)]:
- 支付模組[獨立的服務(系統)]:
- 前提
- 資料存取量 決定叢集數量
- 資料大小 決定選擇通訊模型
- 存取的資料量大 [12中的第四個方案]以上的三個模組可根據存取的資料量來定
- 存取的資料量小 [12中的第二個方案]以上的三個模組可根據存取的資料量來定
- 前提
-
- 使用者模組[獨立的服務(系統)]: [12中的第二個方案]