git clone開啟雲上AI開發
摘要:相比於傳統的軟體開發,AI開發存在以下4個痛點:演演算法繁多;訓練時間長;算力需求大;模型需手動管理,我們可以使用雲上AI開發的方式來緩解以上4個痛點。
本文分享自華為雲社群《git clone開啟雲上AI開發》,作者:ModelArts開發者。
已釋出地址:https://developer.huaweicloud.com/develop/aigallery/article/detail?id=17052711-f3f5-4b53-bdbc-5d5c7cdc64fa
一、為什麼需要雲上AI開發?
相比於傳統的軟體開發,AI開發存在以下4個痛點:
1)演演算法繁多;
2)訓練時間長;
3)算力需求大;
4)模型需手動管理
我們可以使用雲上AI開發的方式來緩解以上4個痛點,雲上AI開發的優勢:
- 任意地點接入,線上開發;
- 雲上環境預置多種主流深度學習框架,開「箱「即用;
- 雲端充足算力、TB級資料儲存,支援重型訓練任務;
- 雲端平臺具備訓練任務版本化管理,AI開發更可靠、可高效;
二、雲上AI開發主要步驟
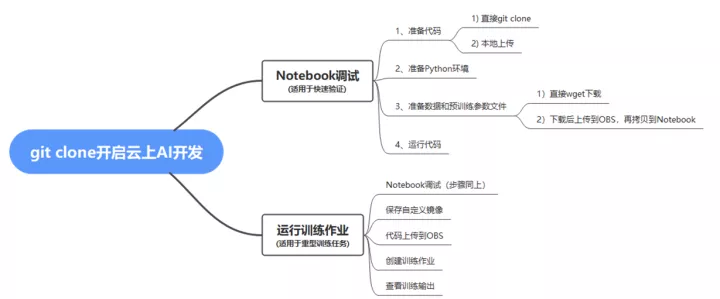
三、具體操作步驟
步驟一 Notebook偵錯
1.準備Python環境
進入ModelArts控制管理臺,點選【開發環境】–> 【Notebook】,進入notebook列表頁面,點選頁面左上角「建立」按鈕,新建一個notebook,填寫引數,下圖所示:


點選「立即建立」,確認產品規格後,點選提交,完成Notebook的建立。
返回Notebook列表頁面,等待新建立Notebook狀態變為「執行中」後,點選名稱進入Notebook。
進入Notebook頁面後,開啟terminal,如下圖所示:

輸入如下命令,檢視已安裝Python環境資訊
conda info -e
點此連結GitHub - IDEA-Research/DINO,下面將以此開源演演算法為例,演示如何在華為雲Notebook上快速執行,演演算法詳細介紹請參考 README.md 。
1)在terminal裡繼續輸入如下命令,克隆倉庫
git clone https://github.com/IDEACVR/DINO cd DINO
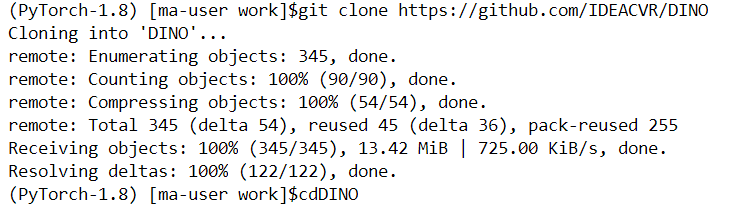
如上圖所示,表示已完成程式碼克隆,點選左側工作列頂部重新整理按鈕,即可檢視程式碼。
2)檢視Pytorch版本
pip list | grep torch
3)安裝其他需要的包
pip install -r requirements.txt
4)編譯CUDA運算元
cd models/dino/ops python setup.py build install # unit test (should see all checking is True) python test.py cd ../../.. # 回到程式碼主目錄

2.準備資料和預訓練引數檔案
1)進入控制檯,將遊標移動至左邊欄,彈出選單中選擇「服務列表」->「儲存」->「物件儲存服務OBS」,如下圖所示:
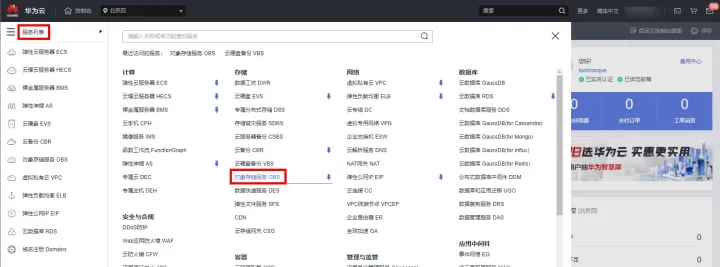
點選「建立桶」按鈕進入建立介面。

開始建立。設定引數如下:
① 複製桶設定:不選
② 區域:華北-北京四
③ 桶名稱:自定義,將在後續步驟使用
④ 資料冗餘儲存策略:單AZ儲存
⑤ 預設儲存類別:標準儲存
⑥ 桶策略:私有
⑦ 預設加密:關閉
⑧ 歸檔資料直讀:關閉
單擊「立即建立」>「確定」,完成桶建立。
點選建立的「桶名稱」->「物件」->「新建資料夾」,建立一個資料夾,用於存放後續資料集。

2)下載COCO 2017資料集子集。該資料集包括train(5000張),val(5000張)及標註檔案。進入下載詳情頁面,下載方式選擇物件儲存服務(OBS),目標區域選擇華北-北京四,目標路徑選擇1中在OBS中建立的路徑,用於資料集儲存,如下圖所示:
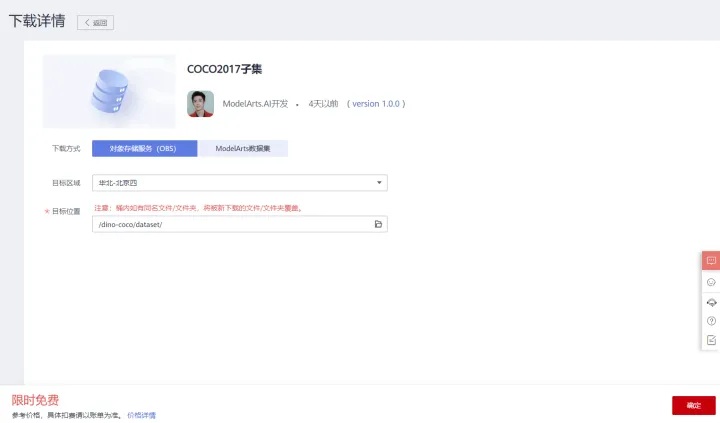
點選「確認」,跳轉至我的下載頁面,可以檢視資料集下載詳情,等待資料集下載完成,如下圖所示:
返回Notebook頁面,新建一個ipynb檔案,編寫匯入資料集指令碼,執行程式碼,執行完畢後,點選工作列上方「重新整理」按鈕,即可檢視匯入dataset,如下圖所示:
import moxing as mox mox.file.copy_parallel({obs_path},{notebook_path})
說明:
{obs_path}為OBS儲存資料集的位置
{notebook_path}為資料集在notebook中的儲存路徑
3)下載DINO 模型 checkpoint 「checkpoint0011_4scale.pth」,下載完成後,返回Notebook頁面,在DINO頁面,建立資料夾ckpts,用於存放下載的checkpoint。

進入資料夾,點選工作列上方」上傳「按鈕,選擇下載完成的checkpoint 路徑,檔案大小超過100MB,需選擇OBS中轉,等待資料上傳完畢,如下圖所示:
3.執行程式碼
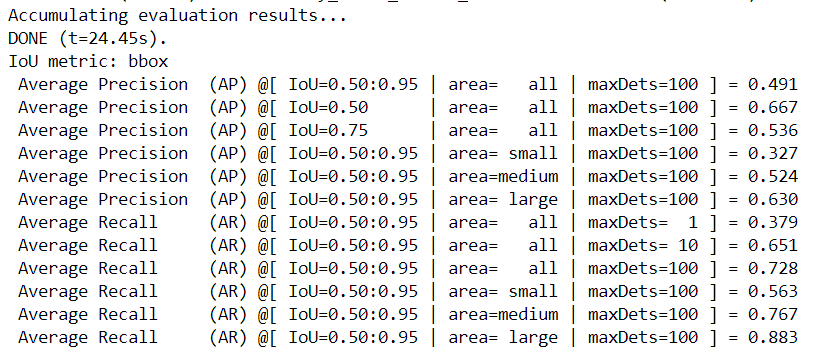
1)執行下面的命令,評估預訓練模型,你可以期待得到最終的AP大約49.0。
bash scripts/DINO_eval.sh /path/to/your/COCODIR /path/to/your/checkpoint
說明:
/path/to/your/COCODIR 為Notebook資料集的儲存路徑
/path/to/your/checkpoint 為Notebookcheckpoint儲存路徑
如下圖所示:

整個過程約等待13分鐘左右,執行結果如下:
2)推理及視覺化
開啟DINO目錄下的inference_and_visualization.ipynb,選擇Kernel Pytorch-1.8,如下圖所示:
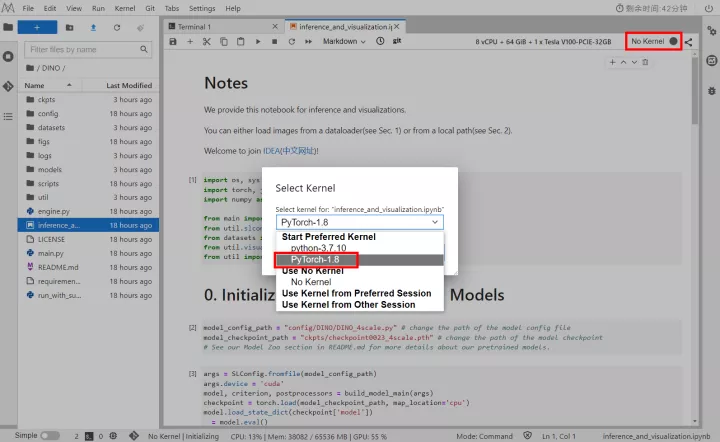
修改程式碼:
... model_checkpoint_path = "ckpts/checkpoint0011_4scale.pth" # 修改checkpoint路徑 ... args.coco_path = "../dataset" # 修改coco資料集路徑
執行程式碼檢視推理結果。
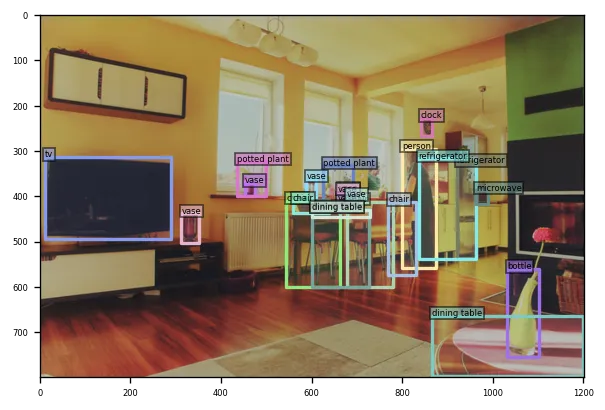
步驟二 執行訓練作業
1.儲存映象
1)返回ModelArts管理控制檯,在左側選單欄中選擇**「開發環境 > Notebook」**,進入新版Notebook管理頁面。在Notebook列表中,點選名稱進入建立的Notebook詳情頁
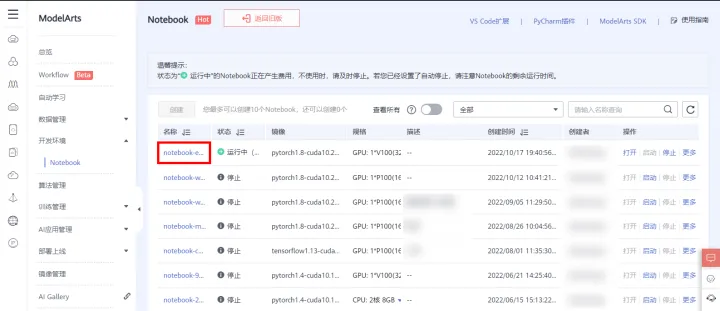
2)點選右側「更多」,選擇「儲存映象」

3)在儲存映象對話方塊中,設定組織、映象名稱、映象版本和描述資訊。單擊「確認」儲存映象。
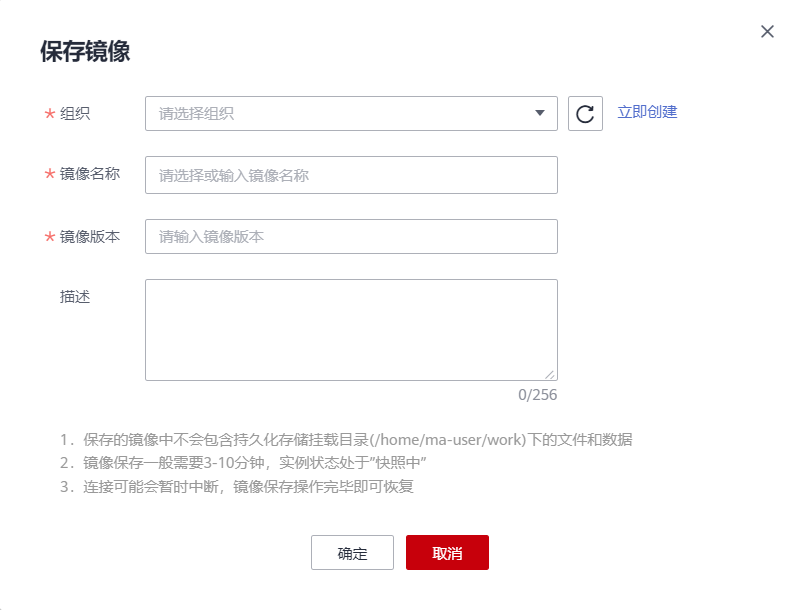
在「組織」下拉框中選擇一個組織。如果沒有組織,可以單擊右側的「立即建立」,建立一個組織。建立組織的詳細操作請參見建立組織。
同一個組織內的使用者可以共用使用該組織內的所有映象。
4)映象會以快照的形式儲存,儲存過程約5分鐘,請耐心等待。此時不可再操作範例(對於開啟的JupyterLab介面和本地IDE 仍可操作)。
5)映象儲存成功後,範例狀態變為**「執行中」**,使用者可在「映象管理」頁面檢視到該映象詳情。
6)單擊映象的名稱,進入映象詳情頁,可以檢視映象版本/ID,狀態,資源型別,映象大小,SWR地址等。
7)還可在左側選單欄中選擇**「映象管理」**,檢視映象列表及詳情,如下圖所示:

2.上傳訓練程式碼
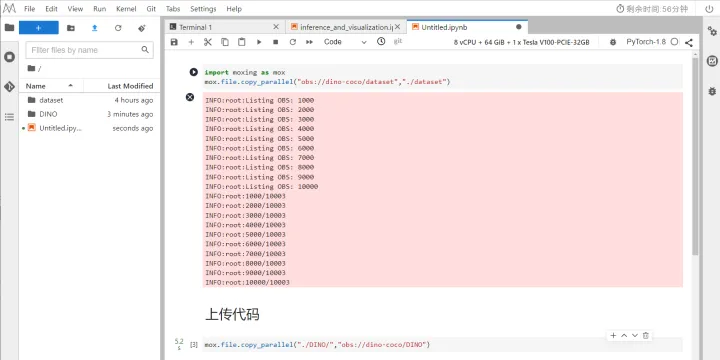
返回Notebook頁面,在新建的ipynb中輸入以下程式碼,完成程式碼上傳至OBS桶中
mox.file.copy_parallel("./DINO/","obs://dino-coco/DINO")
如下圖所示:
3.建立訓練作業
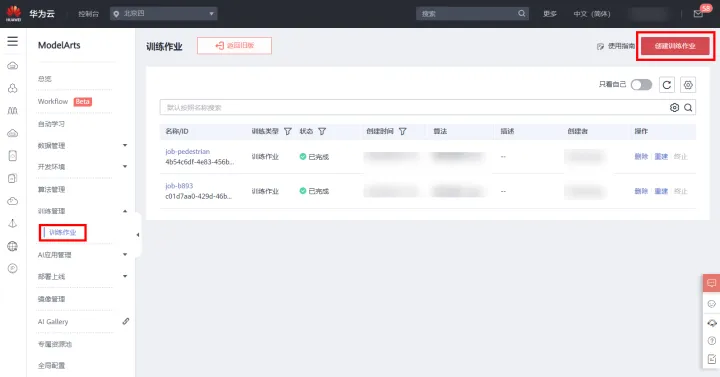
1)在左側選單欄中選擇**「訓練管理 > 訓練作業」**,點選右上角「建立訓練作業」,如下圖所示:
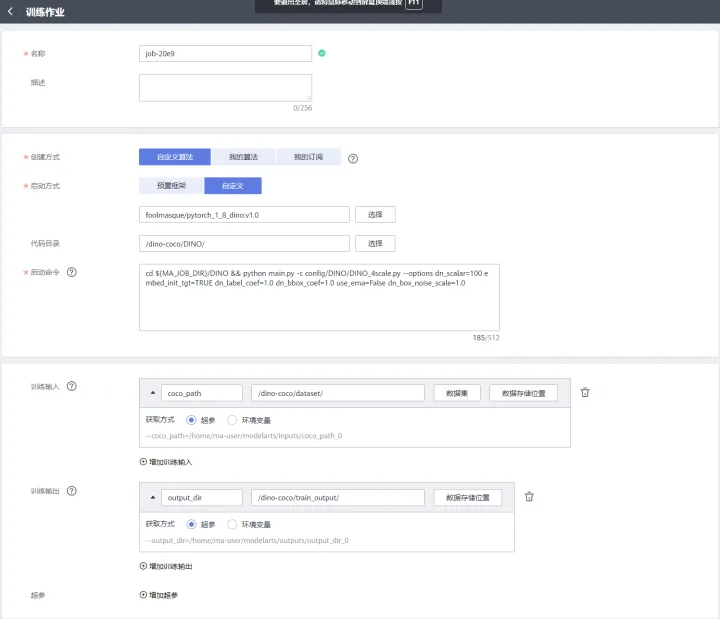
2)引數設定
建立方式:自定義演演算法
啟動方式:自定義,選擇已儲存映象
啟動命令:
cd ${MA_JOB_DIR}/DINO && python main.py -c config/DINO/DINO_4scale.py --options dn_scalar=100 embed_init_tgt=TRUE dn_label_coef=1.0 dn_bbox_coef=1.0 use_ema=False dn_box_noise_scale=1.0
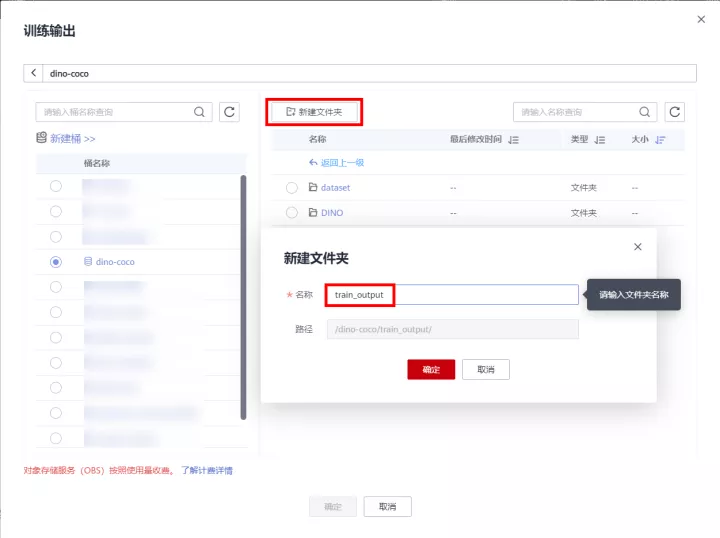
訓練輸入:選擇OBS桶內上傳程式碼路徑
訓練輸出:選擇建立的OBS桶,點選新建資料夾,建立一個資料夾,用於存放訓練輸出,如下圖所示:
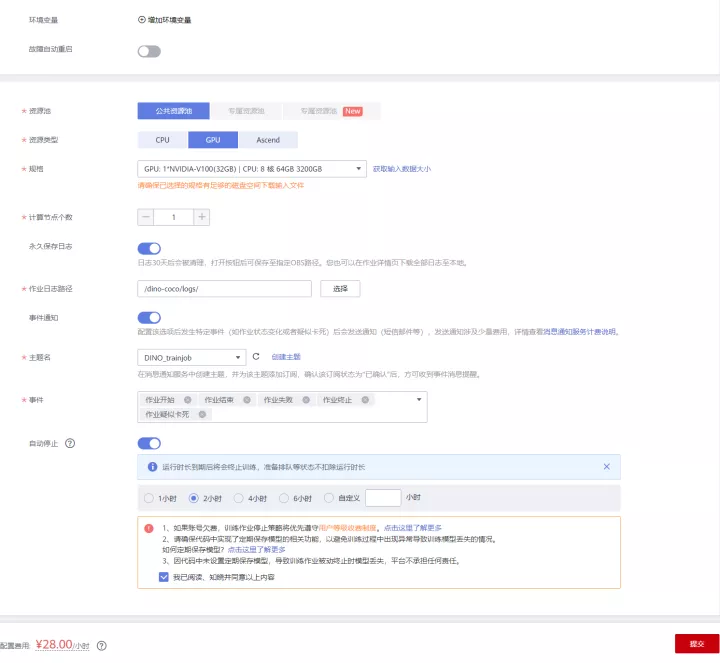
資源池:公幹資源池
資源型別:GPU
規格: GPU: 1*NVIDIA-V100(32GB) | CPU: 8 核 64GB 3200GB
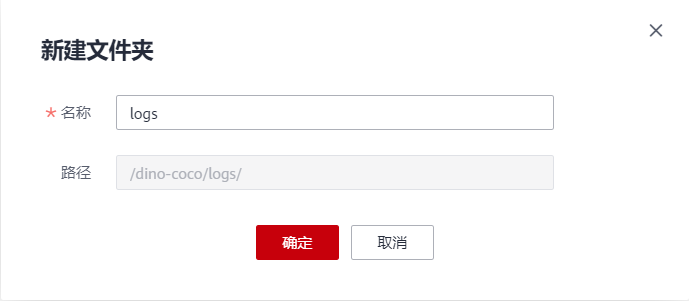
永久儲存紀錄檔:開啟,選擇OBS桶,新建資料夾,用於存放訓練紀錄檔,如下圖所示:
事件通知:開啟,可監控訓練作業的事件的狀態,可簡訊通知。
主題名:如不存在點選右側「建立主題」。主題是訊息釋出或使用者端訂閱通知的特定事件型別。它作為傳送訊息和訂閱通知的通道,為釋出者和訂閱者提供一個可以相互交流的通道。
事件:全部勾選
自動停止:可開啟(訓練時長大於1小時)
如下圖所示:
3)引數設定完成之後,點選提交,確認訓練資訊,點選「確認」

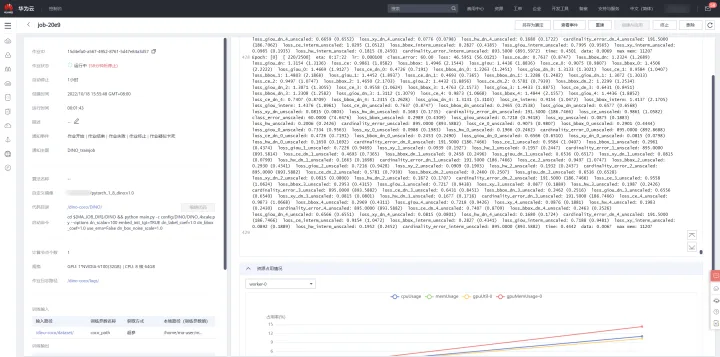
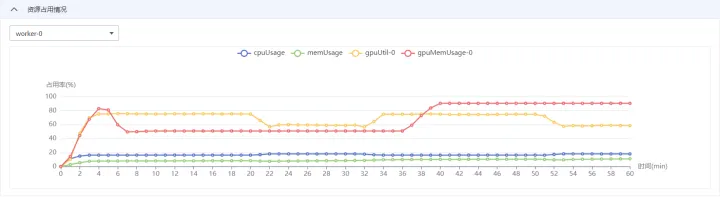
跳轉至訓練作業列表,等待建立的訓練作業,可點選訓練作業名稱,檢視詳細資訊,系統紀錄檔,及資源佔用情況,如下圖所示:
4)在訓練任務跑完之後,可在「程式碼目錄」處線上編輯程式碼,儲存之後,可再次進行訓練模型,如下圖所示:

4.訓練輸出
訓練完成之後,可在設定的OBS訓練輸出路徑檢視訓練結果


10月27日19:00-20:30直播講解《git clone開啟雲上AI開發》,預約報名:https://bbs.huaweicloud.com/live/cloud_live/202210271900.html