巨量資料關鍵技術:自然語言處理入門篇
分詞與詞向量
自然語言處理簡介
自然語言處理概況
什麼是自然語言處理?
自然語言處理( Natural Language Processing, NLP)是電腦科學領域與人工智慧領域中的一個重要方向。它研究能實現人與計算機之間用自然語言進行有效通訊的各種理論和方法。自然語言處理是一門融語言學、電腦科學、數學於一體的科學。
自然語言處理主要應用於機器翻譯、輿情監測、自動摘要、觀點提取、文字分類、問題回答、文字語意對比、語音識別、中文OCR等方面。
(1) 計算機將自然語言作為輸入或輸出:
- 輸入對應的是自然語言理解;
- 輸出對應的是自然語言生成;
(2) 關於NLP的多種觀點:
- A、人類語言處理的計算模型:
- ——程式內部按人類行為方式操作
- B、 人類交流的計算模型:
- ——程式像人類一樣互動
- C、有效處理文字和語音的計算系統
(3) NLP的應用:
A、機器翻譯(Machine Translation)…….
B、MIT翻譯系統(MIT Translation System)……
C、文字摘要(Text Summarization)……
D、對話系統(Dialogue Systems)……
E、其他應用(Other NLP Applications):
——語法檢查(Grammar Checking)
——情緒分類(Sentiment Classification)
——ETS作文評分(ETS Essay Scoring)
自然語言處理相關問題
為什麼自然語言處理比較難?
(1) 歧義
「At last, a computer that understands you like your mother」
對於這句話的理解:
A、 它理解你就像你的母親理解你一樣;
B、 它理解你喜歡你的母親;
C、 它理解你就像理解你的母親一樣
D、 我們來看看Google的翻譯:終於有了一臺像媽媽一樣懂你的電腦(看上去Google的理解更像選項A)。
A到C這三種理解好還是不好呢?
(2) 不同層次的歧義
A、 聲音層次的歧義——語音識別:
——「 ... a computer that understands you like your mother」
——「 ... a computer that understands you lie cured mother」
B、語意(意義)層次的歧義:
Two definitions of 「mother」:
——a woman who has given birth to a child
——a stringy slimy substance consisting of yeast cells and bacteria; is added to cider or wine to produce vinegar
C、話語(多語)層次的歧義、句法層次的歧義:
NLP的知識瓶頸
我們需要:
——有關語言的知識;
——有關世界的知識;
可能的解決方案:
——符號方法 or 象徵手法:將所有需要的資訊在計算機裡編碼;
——統計方法:從語言樣本中推斷語言特性;
(1)例子研究:限定詞位置
任務:在文字中自動地放置限定詞
樣本:Scientists in United States have found way of turning lazy monkeys into workaholics using gene therapy. Usually monkeys work hard only when they know reward is coming, but animals given this treatment did their best all time. Researchers at National Institute of Mental Health near Washington DC, led by Dr Barry Richmond, have now developed genetic treatment which changes their work ethic markedly. 」Monkeys under influence of treatment don’t procrastinate,」 Dr Richmond says. Treatment consists of anti-sense DNA - mirror image of piece of one of our genes - and basically prevents that gene from working. But for rest of us, day when such treatments fall into hands of our bosses may be one we would prefer to put off.
(2)相關語法規則
a) 限定詞位置很大程度上由以下幾項決定:
i. 名詞型別-可數,不可數;
ii. 照應-特指,類指;
iii. 資訊價值-已有,新知
iv. 數詞-單數,複數
b) 然而,許多例外和特殊情況也扮演著一定的角色,如:
i. 定冠詞用在報紙名稱的前面,但是零冠詞用在雜誌和期刊名稱前面
(3) 符號方法方案
a) 我們需要哪些類別的知識:
i. 語言知識:
-靜態知識:數詞,可數性,…
-上下文相關知識:共指關係
ii. 世界知識:
- 參照的唯一性(美國現任總統),名詞的型別(報紙與雜誌),名詞之間的情境關聯性(足球比賽的得分),......
iii. 這些資訊很難人工編碼!
(4)統計方法方案
a) 樸素方法:
i. 收集和你的領域相關的大量的文字
ii. 對於其中的每個名詞,計算它和特定的限定詞一起出現的概率
iii. 對於一個新名詞,依據訓練語料庫中最高似然估計選擇一個限定詞
b) 實現:
i. 語料:訓練——華爾街日報(WSJ)前21節語料,測試——第23節
ii. 預測準確率:71.5%
c) 結論:
i. 結果並不是很好,但是對於這樣簡單的方法結果還是令人吃驚
ii. 這個語料庫中的很大一部分名詞總是和同樣的限定詞一起出現,如:
-「the FBI」,「the defendant」, ...
(5)作為分類問題的限定詞位置
a) 預測:
b) 代表性的問題:
i. 複數?(是,否)
ii. 第一次在文字中出現?
iii. 名詞(詞彙集的成員)
c) 圖表例子略
d) 目標:學習分類函數以預測未知例子
(6)分類方法
a) 學習X->Y的對映函數
b) 假設已存在一些分佈D(X,Y)
c) 嘗試建立分佈D(X,Y)和D(X|Y)的模型
(7)分類之外
a) 許多NLP應用領域可以被看作是從一個複雜的集合到另一個集合的對映:
i. 句法分析: 串到樹
ii. 機器翻譯: 串到串
iii. 自然語言生成:資料詞條到串
b) 注意,分類框架並不適合這些情況!
自然語言處理:單詞計數
語料庫及其性質
(1) 什麼是語料庫(Corpora)
i. 一個語料庫就是一份自然發生的語言文字的載體,以機器可讀形式儲存;
(2) 單詞計數(Word Counts)
i. 在文字中最常見的單詞是哪些?
ii. 在文字中有多少個單詞?
iii. 在大規模語料庫中單詞分佈的特點是什麼?
(3) 我們以馬克吐溫的《湯姆索耶歷險記》為例:
單詞(word) 頻率(Freq) 用法(Use)
the 3332 determiner (article)
and 2972 conjunction
a 1775 determiner
to 1725 preposition, inf. marker
of 1440 preposition
was 1161 auxiliary verb
it 1027 pronoun
in 906 preposition
that 877 complementizer
Tom 678 proper name
虛詞佔了大多數
(4) 這個例句裡有多少個單詞:
They picnicked by the pool, then lay back on the grass and looked at the stars.
i. 「型」(Type) ——語料庫中不同單詞的數目,詞典容量
ii. 「例」(Token) — 語料中總的單詞數目
iii. 注:以上定義參考自《自然語言處理綜論》
iv. 湯姆索耶歷險記(Tom Sawyer)中有:
1. 詞型— 8, 018
2. 詞例— 71, 370
3. 平均頻率— 9(注:詞例/詞型)
(5) 詞頻的頻率:

什麼是LDA主題模型
介紹
- 關於LDA有兩種含義,一種是線性判別分析(Linear Discriminant Analysis),一種是概率主題模型:隱含狄利克雷分佈(Latent Dirichlet Allocation,簡稱LDA),我們講後者。
- 按照wiki上的介紹,LDA由Blei, David M.、Ng, Andrew Y.、Jordan於2003年提出,是一種在PLSA基礎上改進的主題模型,它可以將檔案集中每篇檔案的主題以概率分佈的形式給出,從而通過分析一些檔案抽取出它們的主題(分佈)出來後,便可以根據主題(分佈)進行主題聚類或文字分類。同時,它是一種典型的詞袋模型,即一篇檔案是由一組詞構成,詞與詞之間沒有先後順序的關係。
- 研表究明,漢字的序順並不定一能影閱響讀。比如當你看完這句話後,才發這現裡的字,全是都亂的。
- 此外,一篇檔案可以包含多個主題,檔案中每一個詞都由其中的一個主題生成。
人類是怎麼生成檔案的呢?LDA的這三位作者在原始論文中給了一個簡單的例子。比如假設事先給定了這幾個主題:Arts、Budgets、Children、Education,然後通過學習訓練,獲取每個主題Topic對應的詞語。如下圖所示:
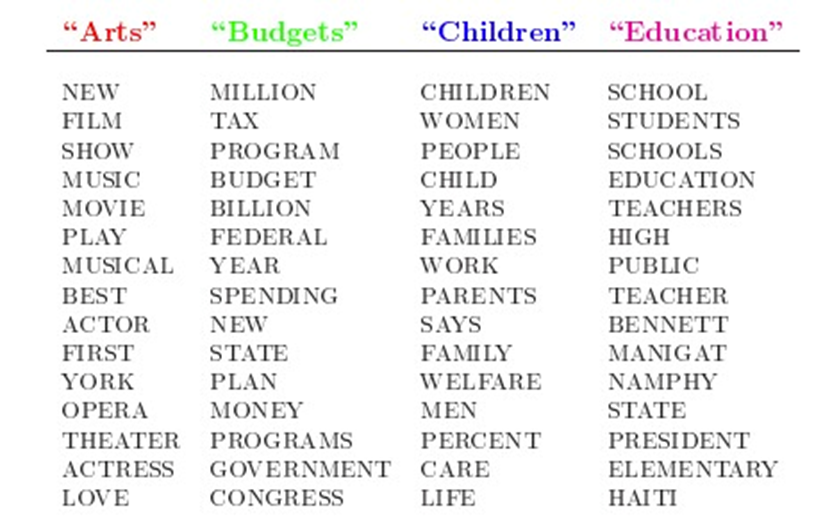
原創作者:孤飛-部落格園
原文連結:https://www.cnblogs.com/ranxi169/p/16804615.html