不允許還有Java程式設計師不瞭解BlockingQueue阻塞佇列的實現原理
我們平時開發中好像很少使用到BlockingQueue(阻塞佇列),比如我們想要儲存一組資料的時候會使用ArrayList,想要儲存鍵值對資料會使用HashMap,在什麼場景下需要用到BlockingQueue呢?
1. BlockingQueue的應用場景
當我們處理完一批資料之後,需要把這批資料發給下游方法接著處理,但是下游方法的處理速率不受控制,可能時快時慢。如果下游方法的處理速率較慢,會拖慢當前方法的處理速率,這時候該怎麼辦呢?
你可能想到使用執行緒池,是個辦法,不過需要建立很多執行緒,還要考慮下游方法支不支援並行,如果是CPU密集任務,可能多執行緒比單執行緒處理速度更慢,因為需要頻繁上下文切換。
這時候就可以考慮使用BlockingQueue,BlockingQueue最典型的應用場景就是上面這種生產者-消費者模型。生產者往佇列中放資料,消費者從佇列中取資料,中間使用BlockingQueue做緩衝佇列,也就解決了生產者和消費者速率不同步的問題。

你可能聯想到了訊息佇列(MessageQueue),訊息佇列相當於分散式阻塞佇列,而BlockingQueue相當於本地阻塞佇列,只作用於本機器。對應的是分散式快取(比如:Redis、Memcache)和本地快取(比如:Guava、Caffeine)。
另外很多框架中都有BlockingQueue的影子,比如執行緒池中就用到BlockingQueue做任務的緩衝。訊息佇列中發訊息、拉取訊息的方法也都借鑑了BlockingQueue,使用起來很相似。
今天就一塊深入剖析一下Queue的底層原始碼。
2. BlockingQueue的用法
BlockingQueue的用法非常簡單,就是放資料和取資料。
/**
* @apiNote BlockingQueue範例
* @author 一燈架構
*/
public class Demo {
public static void main(String[] args) throws InterruptedException {
// 1. 建立佇列,設定容量是10
BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(10);
// 2. 往佇列中放資料
queue.put(1);
// 3. 從佇列中取資料
Integer result = queue.take();
}
}
為了滿足不同的使用場景,BlockingQueue設計了很多的放資料和取資料的方法。
| 操作 | 丟擲異常 | 返回特定值 | 阻塞 | 阻塞一段時間 |
|---|---|---|---|---|
| 放資料 | add |
offer |
put |
offer(e, time, unit) |
| 取資料 | remove |
poll |
take |
poll(time, unit) |
| 取資料(不刪除) | element() |
peek() |
不支援 | 不支援 |
這幾組方法的不同之處就是:
- 當佇列滿了,再往佇列中放資料,add方法拋異常,offer方法返回false,put方法會一直阻塞(直到有其他執行緒從佇列中取走資料),offer方法阻塞指定時間然後返回false。
- 當佇列是空,再從佇列中取資料,remove方法拋異常,poll方法返回null,take方法會一直阻塞(直到有其他執行緒往佇列中放資料),poll方法阻塞指定時間然後返回null。
- 當佇列是空,再去佇列中檢視資料(並不刪除資料),element方法拋異常,peek方法返回null。
工作中使用最多的就是offer、poll阻塞指定時間的方法。
3. BlockingQueue實現類
BlockingQueue常見的有下面5個實現類,主要是應用場景不同。
-
ArrayBlockingQueue
基於陣列實現的阻塞佇列,建立佇列時需指定容量大小,是有界佇列。
-
LinkedBlockingQueue
基於連結串列實現的阻塞佇列,預設是無界佇列,建立可以指定容量大小
-
SynchronousQueue
一種沒有緩衝的阻塞佇列,生產出的資料需要立刻被消費
-
PriorityBlockingQueue
實現了優先順序的阻塞佇列,基於資料顯示,是無界佇列
-
DelayQueue
實現了延遲功能的阻塞佇列,基於PriorityQueue實現的,是無界佇列
4. BlockingQueue原始碼解析
BlockingQueue的5種子類實現方式大同小異,這次就以最常用的ArrayBlockingQueue做原始碼解析。
4.1 ArrayBlockingQueue類屬性
先看一下ArrayBlockingQueue類裡面有哪些屬性:
// 用來存放資料的陣列
final Object[] items;
// 下次取資料的陣列下標位置
int takeIndex;
// 下次放資料的陣列下標位置
int putIndex;
// 當前已有元素的個數
int count;
// 獨佔鎖,用來保證存取資料安全
final ReentrantLock lock;
// 取資料的條件
private final Condition notEmpty;
// 放資料的條件
private final Condition notFull;
ArrayBlockingQueue中4組存取資料的方法實現也是大同小異,本次以put和take方法進行解析。
4.2 put方法原始碼解析
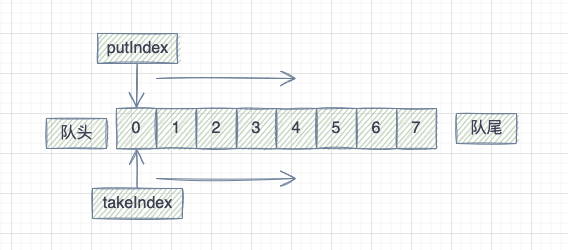
無論是放資料還是取資料都是從隊頭開始,逐漸往隊尾移動。
// 放資料,如果佇列已滿,就一直阻塞,直到有其他執行緒從佇列中取走資料
public void put(E e) throws InterruptedException {
// 校驗元素不能為空
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 加鎖,加可中斷的鎖
lock.lockInterruptibly();
try {
// 如果佇列已滿,就一直阻塞,直到被喚醒
while (count == items.length)
notFull.await();
// 如果佇列未滿,就往佇列新增元素
enqueue(e);
} finally {
// 結束後,別忘了釋放鎖
lock.unlock();
}
}
// 實際往佇列新增資料的方法
private void enqueue(E x) {
// 獲取陣列
final Object[] items = this.items;
// putIndex 表示本次插入的位置
items[putIndex] = x;
// ++putIndex 計算下次插入的位置
// 如果本次插入的位置,正好是隊尾,下次插入就從 0 開始
if (++putIndex == items.length)
putIndex = 0;
// 元素數量加一
count++;
// 喚醒因為佇列空等待的執行緒
notEmpty.signal();
}
原始碼中有個有意思的設計,新增元素的時候如果已經到了隊尾,下次就從隊頭開始新增,相當於做成了一個迴圈佇列。
像下面這樣:

4.3 take方法原始碼
// 取資料,如果佇列為空,就一直阻塞,直到有其他執行緒往佇列中放資料
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
// 加鎖,加可中斷的鎖
lock.lockInterruptibly();
try {
// 如果佇列為空,就一直阻塞,直到被喚醒
while (count == 0)
notEmpty.await();
// 如果佇列不為空,就從佇列取資料
return dequeue();
} finally {
// 結束後,別忘了釋放鎖
lock.unlock();
}
}
// 實際從佇列取資料的方法
private E dequeue() {
// 獲取陣列
final Object[] items = this.items;
// takeIndex 表示本次取資料的位置,是上一次取資料時計算好的
E x = (E) items[takeIndex];
// 取完之後,就把佇列該位置的元素刪除
items[takeIndex] = null;
// ++takeIndex 計算下次取資料的位置
// 如果本次取資料的位置,正好是隊尾,下次就從 0 開始取資料
if (++takeIndex == items.length)
takeIndex = 0;
// 元素數量減一
count--;
if (itrs != null)
itrs.elementDequeued();
// 喚醒被佇列滿所阻塞的執行緒
notFull.signal();
return x;
}
4.4 總結
- ArrayBlockingQueue基於陣列實現的阻塞佇列,建立佇列時需指定容量大小,是有界佇列。
- ArrayBlockingQueue底層採用迴圈佇列的形式,保證陣列位置可以重複使用。
- ArrayBlockingQueue存取都採用ReentrantLock加鎖,保證執行緒安全,在多執行緒環境下也可以放心使用。
- 使用ArrayBlockingQueue的時候,預估好佇列長度,保證生產者和消費者速率相匹配。
我是「一燈架構」,如果本文對你有幫助,歡迎各位小夥伴點贊、評論和關注,感謝各位老鐵,我們下期見
