(資料科學學習手札144)使用管道操作符高效書寫Python程式碼
本文範例程式碼已上傳至我的
Github倉庫https://github.com/CNFeffery/DataScienceStudyNotes
1 簡介
大家好我是費老師,一些比較熟悉pandas的讀者朋友應該經常會使用query()、eval()、pipe()、assign()等pandas的常用方法(相關知識詳見我的pandas專題教學https://www.cnblogs.com/feffery/tag/pandas/),書寫可讀性很高的鏈式資料分析處理程式碼,從而更加絲滑流暢地組織程式碼邏輯。
但在原生Python中並沒有提供類似shell中的管道操作符|、R中的管道操作符%>%等語法,也沒有針對列表等陣列結構的可進行鏈式書寫的快捷方法,譬如javascript中陣列的map()、filter()、some()、every()等。
正所謂「標準庫不夠,三方庫來湊」,Python原生對鏈式寫法支援不到位沒關係,我們可以使用一些簡單方便且輕量的第三方庫來協助我們在Python程式碼中大面積實現鏈式寫法,今天的文章中費老師我就將帶大家一起學習相關的知識技巧~

2 在Python中配合pipe靈活使用鏈式寫法
我們將使用到pipe這個第三方庫,它不僅內建了很多實用的管道操作函數,還提供了將常規函數快捷轉換為管道操作函數的方法,使用pip install pipe對其進行安裝即可。
pipe的用法非常方便,類似shell中的管道操作:以你的陣列變數為起點,使用操作符|銜接pipe內建的各個常見管道操作函數,組裝起自己所需的計算步驟即可,譬如,我們篩選輸入陣列中為偶數的,再求平方,就可以寫作:
import pipe
list(
range(10) |
pipe.filter(lambda x: x % 2 == 0) |
pipe.select(lambda x: x ** 2)
)

因為pipe搭建的管道預設都是惰性運算的,直接產生的結果是生成器型別,所以上面的例子中我們最外層套上了list()來取得實際計算結果,更優雅的方式是配合pipe.Pipe(),將list()也改造為管道操作函數:
from pipe import Pipe
(
range(10) |
pipe.filter(lambda x: x % 2 == 0) |
pipe.select(lambda x: x ** 2) |
Pipe(list)
)

在上面的簡單例子中我們使用到的filter()、select()等就是pipe中常見的管道操作函數,事實上pipe中的管道操作函數相當的豐富,下面我們來展示其中一些常用的:
2.1 pipe中常用的管道操作函數
2.1.1 使用traverse()展平巢狀陣列
如果你想要將任意巢狀陣列結構展平,可以使用traverse():
(
[1, [2, 3, [4, 5]], 6, [7, 8, [9, [10, 11]]]] |
pipe.traverse |
Pipe(list)
)

2.1.2 使用dedup()進行順序去重
如果我們需要對包含若干重複值的陣列進行去重,且希望保留原始資料的順序,則可以使用dedup(),其還支援key引數,類似sorted()中的同名引數,實現自定義去重規則:
(
[-1, 0, 0, 0, 1, 2, 3] |
pipe.dedup |
Pipe(list)
)
(
[-1, 0, 0, 0, 1, 2, 3] |
# 基於每個元素的絕對值進行去重
pipe.dedup(key=abs) |
Pipe(list)
)

2.1.3 使用filter()進行值過濾
我們最開始的例子中使用過它,用法就是基於傳入的lambda函數對每個元素進行條件判斷,並保留結果為True的,與javascript中的filter()方法非常相似:
(
[1, 4, 3, 2, 5, 6, 8] |
# 保留大於5的元素
pipe.filter(lambda x: x > 5) |
Pipe(list)
)

2.1.4 使用groupby()進行分組運算
這個函數非常實用,其功能相當於管道操作版本的itertools.groupby(),可以幫助我們基於lambda函數運算結果對原始輸入陣列進行分組,通過groupby()操作後直接得到的結果是分組結果的二元組列表,每個元組的第一個元素是分組標籤,第二個元素是分到該組內的各個元素:

基於此,我們可以銜接很多其他管道操作函數,譬如銜接select()對分組結果進行自定義運算:

2.1.5 使用select()對上一步結果進行自定義遍歷運算
這個函數是pipe()中核心的管道操作函數,通過前面的若干例子也能弄明白,它的功能是基於我們自定義的函數,對上一步的運算結果進行遍歷運算。

2.1.6 使用sort()進行排序
相當於內建函數sorted()的管道操作版本,同樣支援key、reverse引數:
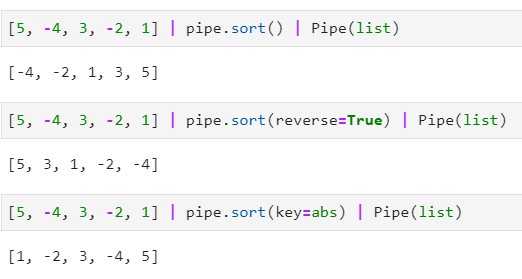
上述內容足以支撐大部分日常操作需求,你也可以在https://github.com/JulienPalard/Pipe中檢視pipe的更多功能介紹。
以上就是本文的全部內容,歡迎在評論區與我進行討論~