爬蟲的基本原理
一、爬蟲的基本原理
網路爬蟲的價值其實就是資料的價值,在網際網路社會中,資料是無價之寶,一切皆為資料,誰擁有了大量有用的資料,誰就擁有了決策的主動權。
爬蟲聚合站點
https://qbt4.mobduos.com/promote/pc/?code=339115928&utm=339115928
http://www.hrdatayun.com
https://tophub.today/c/tech
https://www.vlogxz.com/
1.0 爬蟲定義
簡單來講,爬蟲就是一個探測機器,它的基本操作就是模擬人的行為去各個網站溜達,點點按鈕,查查資料,或者把看到的資訊揹回來。就像一隻蟲子在一幢樓裡不知疲倦地爬來爬去。
1.1 爬蟲薪資

1.2 爬蟲前景
每個職業都是有一個橫向和縱向的發展,也就是所謂的廣度和深度的意思。第一、如果專研得夠深,你的爬蟲功能很強大,效能很高,擴充套件性很好等等,那麼還是很有前途的。第二、爬蟲作為資料的來源,後面還有很多方向可以發展,比如可以往巨量資料分析、資料展示、機器學習等方面發展,前途不可限量,現在作為巨量資料時代,你佔據在資料的的入口,還怕找不到發展方向嗎?

1.3 爬蟲創業
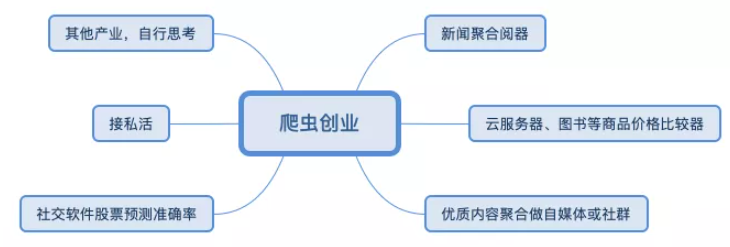
案列:
1.1.1 獲取網頁
爬蟲首先要做的工作就是獲取網頁,這裡就是獲取網頁的原始碼。原始碼裡包含了網頁的部分有用資訊,所以只要把原始碼獲取下來,就可以從中提取想要的資訊了。
- 使用socket下載一個頁面
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@author:chenshifeng
@file:00.py
@time:2022/10/14
"""
import socket
# 不需要安裝
# 存取網站
url = 'www.baidu.com'
# 埠
port = 80
def blocking():
sock = socket.socket() # 建立物件
sock.connect((url, port)) # 連線網站 ,發出一個HTTP請求
request_url = 'GET / HTTP/1.0\r\nHost: www.baidu.com\r\n\r\n'
sock.send(request_url.encode()) # 根據請求頭來傳送請求資訊
response = b'' # 建立一個二進位制物件用來儲存我們得到的資料
chunk = sock.recv(1024) # 每次獲得的資料不超過1024位元組
while chunk: # 迴圈接收資料,因為一次接收不完整
response += chunk
chunk = sock.recv(1024)
header, html = response.split(b'\r\n\r\n', 1)
f = open('index.html', 'wb')
f.write(html)
f.close()
if __name__ == '__main__':
blocking()
1.1.2 提取資訊
獲取網頁原始碼後,接下來就是分析網頁原始碼,從中提取我們想要的資料。首先,最通用的方法便是採用正規表示式提取,這是一個萬能的方法,但是在構造正規表示式時比較複雜且容易出錯。
另外,由於網頁的結構有一定的規則,所以還有一些根據網頁節點屬性、CSS 選擇器或 XPath 來提取網頁資訊的庫,如 Beautiful Soup、pyquery、lxml 等。使用這些庫,我們可以高效快速地從中提取網頁資訊,如節點的屬性、文字值等。
提取資訊是爬蟲非常重要的部分,它可以使雜亂的資料變得條理清晰,以便我們後續處理和分析資料。
1.1.3 儲存資料
提取資訊後,我們一般會將提取到的資料儲存到某處以便後續使用。這裡儲存形式有多種多樣,如可以簡單儲存為 TXT 文字或 JSON 文字,也可以儲存到資料庫,如 MySQL 和 MongoDB 等,也可儲存至遠端伺服器,如藉助 SFTP 進行操作等。
1.1.4 自動化程式
說到自動化程式,意思是說爬蟲可以代替人來完成這些操作。首先,我們手工當然可以提取這些資訊,但是當量特別大或者想快速獲取大量資料的話,肯定還是要藉助程式。爬蟲就是代替我們來完成這份爬取工作的自動化程式,它可以在抓取過程中進行各種例外處理、錯誤重試等操作,確保爬取持續高效地執行。
二、HTTP基本原理
2.1.1 URI 和 URL
這裡我們先了解一下 URI 和 URL,URI 的全稱為 Uniform Resource Identifier,即統一資源標誌符,URL 的全稱為 Universal Resource Locator,即統一資源定位符。
什麼是URL?
Uniform Resource Locator或者簡稱URL— 顧名思義 — 就是對於某種web資源的參照,並且包含了如何獲取該資源的方式。 最常見到的場景就是指一個網站的地址,也就是你在瀏覽器位址列見到的那個東西。

一個URL由如下幾個部分構成:
https://img.vm.laomishuo.com/image/2019/10/F9A91867-194B-4F18-90CF-65CE2A8BFDDA.jpeg
- 協定: 通常是https或者http。表示通過何種方式獲取該資源。你可能還見過其他協定型別,比如ftp或者file,協定後面跟著://
- 主機名: 可以是一個已經在DNS伺服器註冊過的域名 —— 或者是一個IP地址 —— 域名就表示背後的IP地址。一組主要由數位組成的用於標識接入網路的裝置的字串。
主機名後面可以指定埠,埠是可選的,如果不指定則使用預設埠,埠和主機名之間通過冒號隔開。 - 資源路徑: 用於表示資源在主機上的檔案系統路徑。
可以在這之後通過問號連線可選的查詢引數,如果有多個查詢引數,通過&符連線
最後一項,如果需要的話可以新增#作為需要跳轉的頁面上的矛點名稱。
一個URL的組成部分可以參考下面的圖示:

什麼是URI?
接下來我們來了解一下究竟什麼是URI。與URL相似的部分是,Uniform Resource Identifier同樣定義了資源的標識。但不同點在於URI通常不會包含獲取資源的方式。
ISBN作為書目的資源定義就是一種URI,但不是URL。它清楚地為每一種出版的書目定義了唯一的數位編號,但沒有包含任何如何獲取這種資源的方法。
URI代表著統一資源識別符號(UniformResourceIdentifier),用於標識某一網際網路資源名稱。 該種標識允許使用者對任何包括本地和網際網路的資源通過特定的協定進行互動操作。比如上面URL中的F9A91867-194B-4F18-90CF-65CE2A8BFDDA.jpeg。
URL 和 URI 的區別:
(1)URL:Uniform Resource Locator統一資源定位符;
(2)URI: Uniform Resource Identifier統一資源識別符號;
因此我們可以這樣總結:URI是URL的超集,URL是URI的子集。每一個URL都必定也是一個URI。
其實一直有個誤解,很多人以為URI是URL的子集,其實應該反過來。URL是URI的子集才對。簡單解釋下。
假設"小白"(URI)是一種資源,而"在迪麗亦巴的懷裡"表明了一個位置。如果你想要找到(locate)小白,那麼你可以到"在迪麗亦巴懷裡"找到小白,而"在迪麗亦巴懷裡的/小白"才是我們常說的URL。而"在迪麗亦巴懷裡的/小白"(URL)顯然是"小白"(URI)的子集,畢竟,"小白"還可能是"在牛亦菲懷裡的/小白"(其他URL)。
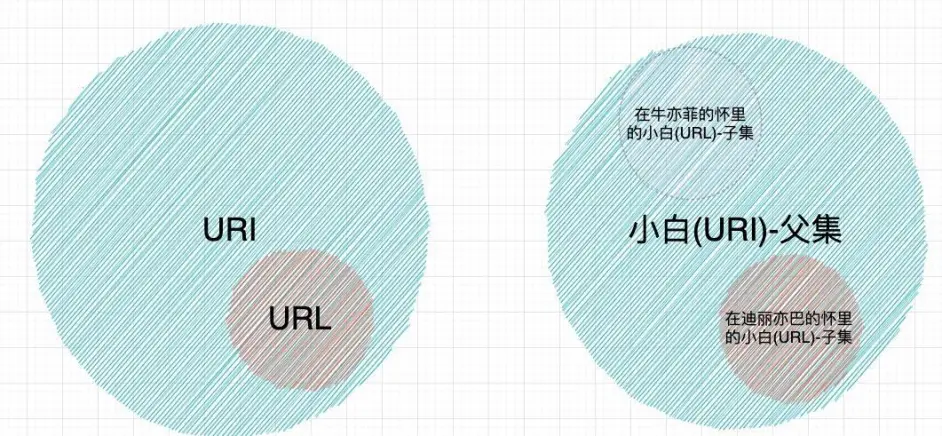
所以實際上URL就是一種特定的URI,這種URI還含有如何獲取資源的資訊。如果一定需要一句話來總結本文的主要內容,那麼RFC3986中的這句定義一定是最合適的:
The term 「Uniform Resource Locator」 (URL) refers to the subset of URIs that, in addition to identifying a resource, provide a means of locating the resource by describing its primary access mechanism.
2.1.2 超文字
其英文名稱叫作 hypertext,我們在瀏覽器裡看到的網頁就是超文字解析而成的,其網頁原始碼是一系列 HTML 程式碼,裡面包含了一系列標籤,比如 img 顯示圖片,p 指定顯示段落等。瀏覽器解析這些標籤後,便形成了我們平常看到的網頁,而網頁的原始碼 HTML 就可以稱作超文字。
2.1.3 HTTP 和 HTTPS
在百度的首頁 https://www.baidu.com/ 中,URL 的開頭會有 http 或 https,這個就是存取資源需要的協定型別,有時我們還會看到 ftp、sftp、smb 開頭的 URL,那麼這裡的 ftp、sftp、smb 都是指的協定型別。在爬蟲中,我們抓取的頁面通常就是 http 或 https 協定的,我們在這裡首先來了解一下這兩個協定的含義。
- HTTP 的全稱是 Hyper Text Transfer Protocol,中文名叫做超文字傳輸協定
- HTTPS 的全稱是 Hyper Text Transfer Protocol over Secure Socket Layer,是以安全為目標的 HTTP 通道,簡單講是 HTTP 的安全版,即 HTTP 下加入 SSL 層,簡稱為 HTTPS。
參考:https://baike.baidu.com/item/HTTPS/285356?fr=aladdin
2.1.4 HTTP 請求過程
我們在瀏覽器中輸入一個 URL,回車之後便會在瀏覽器中觀察到頁面內容。實際上,這個過程是瀏覽器向網站所在的伺服器傳送了一個請求,網站伺服器接收到這個請求後進行處理和解析,然後返回對應的響應,接著傳回給瀏覽器。響應裡包含了頁面的原始碼等內容,瀏覽器再對其進行解析,便將網頁呈現了出來,模型如圖 所示。

2.1.5 請求
請求,由使用者端向伺服器端發出,可以分為 4 部分內容:請求方法(Request Method)、請求的網址(Request URL)、請求頭(Request Headers)、請求體(Request Body)。
面板組成
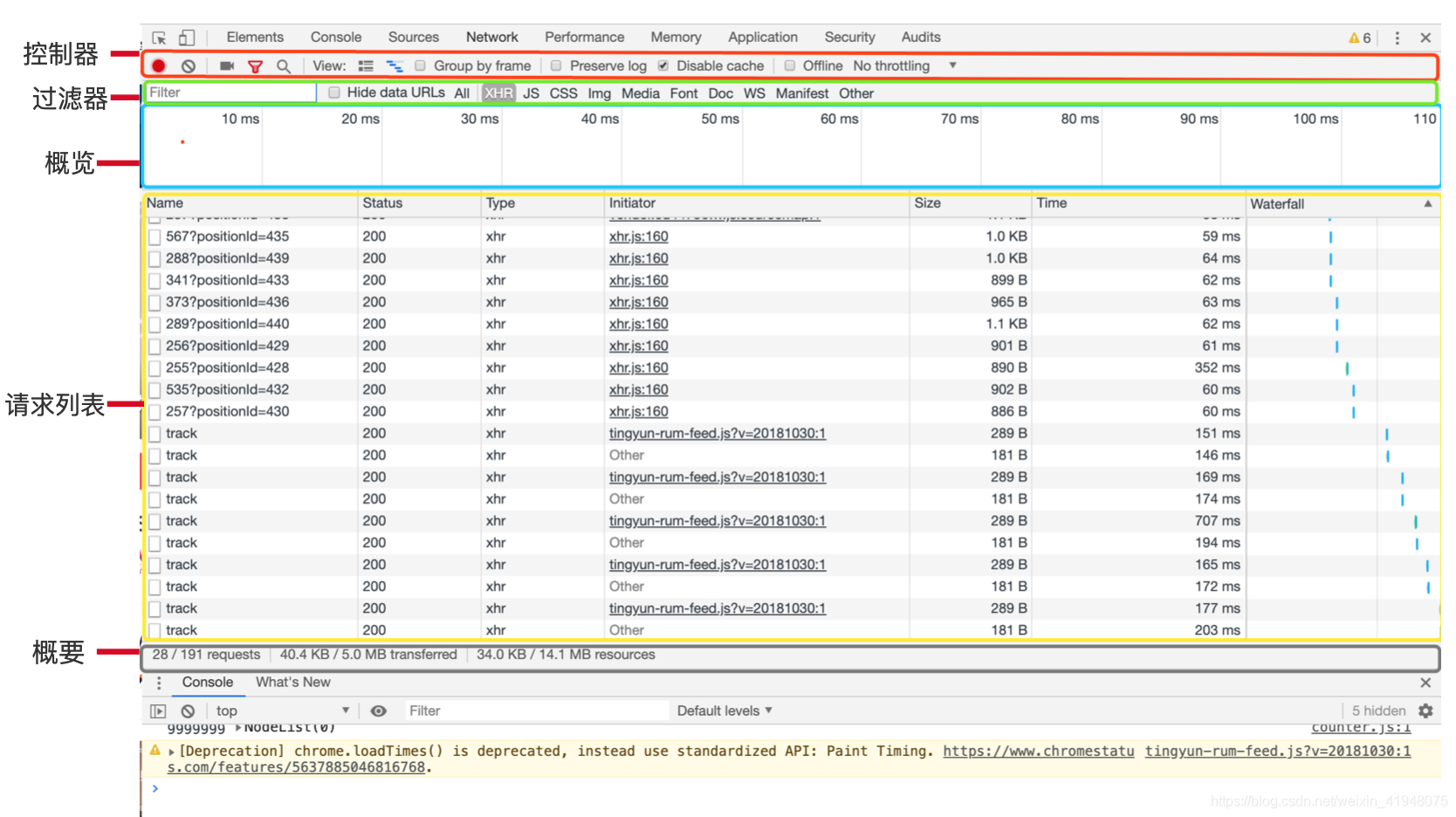
-
請求方法
表 1-1 其他請求方法
方 法 描 述 GET 請求頁面,並返回頁面內容 HEAD 類似於 GET 請求,只不過返回的響應中沒有具體的內容,用於獲取報頭 POST 大多用於提交表單或上傳檔案,資料包含在請求體中 PUT 從使用者端向伺服器傳送的資料取代指定檔案中的內容 DELETE 請求伺服器刪除指定的頁面 CONNECT 把伺服器當作跳板,讓伺服器代替使用者端存取其他網頁 OPTIONS 允許使用者端檢視伺服器的效能 TRACE 回顯伺服器收到的請求,主要用於測試或診斷
本表參考:http://www.runoob.com/http/http-methods.html。
-
請求的網址
請求的網址,即統一資源定位符 URL,它可以唯一確定我們想請求的資源。
-
請求頭
參考:https://byvoid.com/zhs/blog/http-keep-alive-header/
- Accept
- Accept-Language
- Accept-Encoding
- Host 主機
- Cookie 對談資訊 身份
- Referer 記錄來源
- User-Agent 瀏覽器得指紋資訊
- Content-Type 型別
-
請求體
請求體一般承載的內容是 POST 請求中的表單資料,而對於 GET 請求,請求體則為空。
2.1.6 響應
響應,由伺服器端返回給使用者端,可以分為三部分:響應狀態碼(Response Status Code)、響應頭(Response Headers)和響應體(Response Body)。
- 響應狀態碼
響應狀態碼錶示伺服器的響應狀態,如 200 代表伺服器正常響應,404 代表頁面未找到,500 代表伺服器內部發生錯誤。在爬蟲中,我們可以根據狀態碼來判斷伺服器響應狀態,如狀態碼為 200,則證明成功返回資料,再進行進一步的處理,否則直接忽略。表 2-3 列出了常見的錯誤程式碼及錯誤原因。
1.1常見的錯誤程式碼及錯誤原因
| 狀態碼 | 說 明 | 詳 情 |
|---|---|---|
| 100 | 繼續 | 請求者應當繼續提出請求。伺服器已收到請求的一部分,正在等待其餘部分 |
| 101 | 切換協定 | 請求者已要求伺服器切換協定,伺服器已確認並準備切換 |
| 200 | 成功 | 伺服器已成功處理了請求 |
| 201 | 已建立 | 請求成功並且伺服器建立了新的資源 |
| 202 | 已接受 | 伺服器已接受請求,但尚未處理 |
| 203 | 非授權資訊 | 伺服器已成功處理了請求,但返回的資訊可能來自另一個源 |
| 204 | 無內容 | 伺服器成功處理了請求,但沒有返回任何內容 |
| 205 | 重置內容 | 伺服器成功處理了請求,內容被重置 |
| 206 | 部分內容 | 伺服器成功處理了部分請求 |
| 300 | 多種選擇 | 針對請求,伺服器可執行多種操作 |
| 301 | 永久移動 | 請求的網頁已永久移動到新位置,即永久重定向 |
| 302 | 臨時移動 | 請求的網頁暫時跳轉到其他頁面,即暫時重定向 |
| 303 | 檢視其他位置 | 如果原來的請求是 POST,重定向目標檔案應該通過 GET 提取 |
| 304 | 未修改 | 此次請求返回的網頁未修改,繼續使用上次的資源 |
| 305 | 使用代理 | 請求者應該使用代理存取該網頁 |
| 307 | 臨時重定向 | 請求的資源臨時從其他位置響應 |
| 400 | 錯誤請求 | 伺服器無法解析該請求 |
| 401 | 未授權 | 請求沒有進行身份驗證或驗證未通過 |
| 403 | 禁止存取 | 伺服器拒絕此請求 |
| 404 | 未找到 | 伺服器找不到請求的網頁 |
| 405 | 方法禁用 | 伺服器禁用了請求中指定的方法 |
| 406 | 不接受 | 無法使用請求的內容響應請求的網頁 |
| 407 | 需要代理授權 | 請求者需要使用代理授權 |
| 408 | 請求超時 | 伺服器請求超時 |
| 409 | 衝突 | 伺服器在完成請求時發生衝突 |
| 410 | 已刪除 | 請求的資源已永久刪除 |
| 411 | 需要有效長度 | 伺服器不接受不含有效內容長度檔頭欄位的請求 |
| 412 | 未滿足前提條件 | 伺服器未滿足請求者在請求中設定的其中一個前提條件 |
| 413 | 請求實體過大 | 請求實體過大,超出伺服器的處理能力 |
| 414 | 請求 URI 過長 | 請求網址過長,伺服器無法處理 |
| 415 | 不支援型別 | 請求格式不被請求頁面支援 |
| 416 | 請求範圍不符 | 頁面無法提供請求的範圍 |
| 417 | 未滿足期望值 | 伺服器未滿足期望請求檔頭欄位的要求 |
| 500 | 伺服器內部錯誤 | 伺服器遇到錯誤,無法完成請求 |
| 501 | 未實現 | 伺服器不具備完成請求的功能 |
| 502 | 錯誤閘道器 | 伺服器作為閘道器或代理,從上游伺服器收到無效響應 |
| 503 | 服務不可用 | 伺服器目前無法使用 |
| 504 | 閘道器超時 | 伺服器作為閘道器或代理,但是沒有及時從上游伺服器收到請求 |
| 505 | HTTP 版本不支援 | 伺服器不支援請求中所用的 HTTP 協定版本 |
- 響應頭
響應頭包含了伺服器對請求的應答資訊,如 Content-Type、Server、Set-Cookie 等。下面簡要說明一些常用的頭資訊。
- Date:標識響應產生的時間。
- Last-Modified:指定資源的最後修改時間。
- Content-Encoding:指定響應內容的編碼。
- Server:包含伺服器的資訊,比如名稱、版本號等。
- Content-Type:檔案型別,指定返回的資料型別是什麼,如 text/html 代表返回 HTML 檔案,application/x-javascript 則代表返回 JavaScript 檔案,image/jpeg 則代表返回圖片。
- Set-Cookie:設定 Cookies。響應頭中的 Set-Cookie 告訴瀏覽器需要將此內容放在 Cookies 中,下次請求攜帶 Cookies 請求。
- Expires:指定響應的過期時間,可以使代理伺服器或瀏覽器將載入的內容更新到快取中。如果再次存取時,就可以直接從快取中載入,降低伺服器負載,縮短載入時間。
- 響應體
最重要的當屬響應體的內容了。響應的正文資料都在響應體中,比如請求網頁時,它的響應體就是網頁的 HTML 程式碼;請求一張圖片時,它的響應體就是圖片的二進位制資料。我們做爬蟲請求網頁後,要解析的內容就是響應體,如圖 2-8 所示。
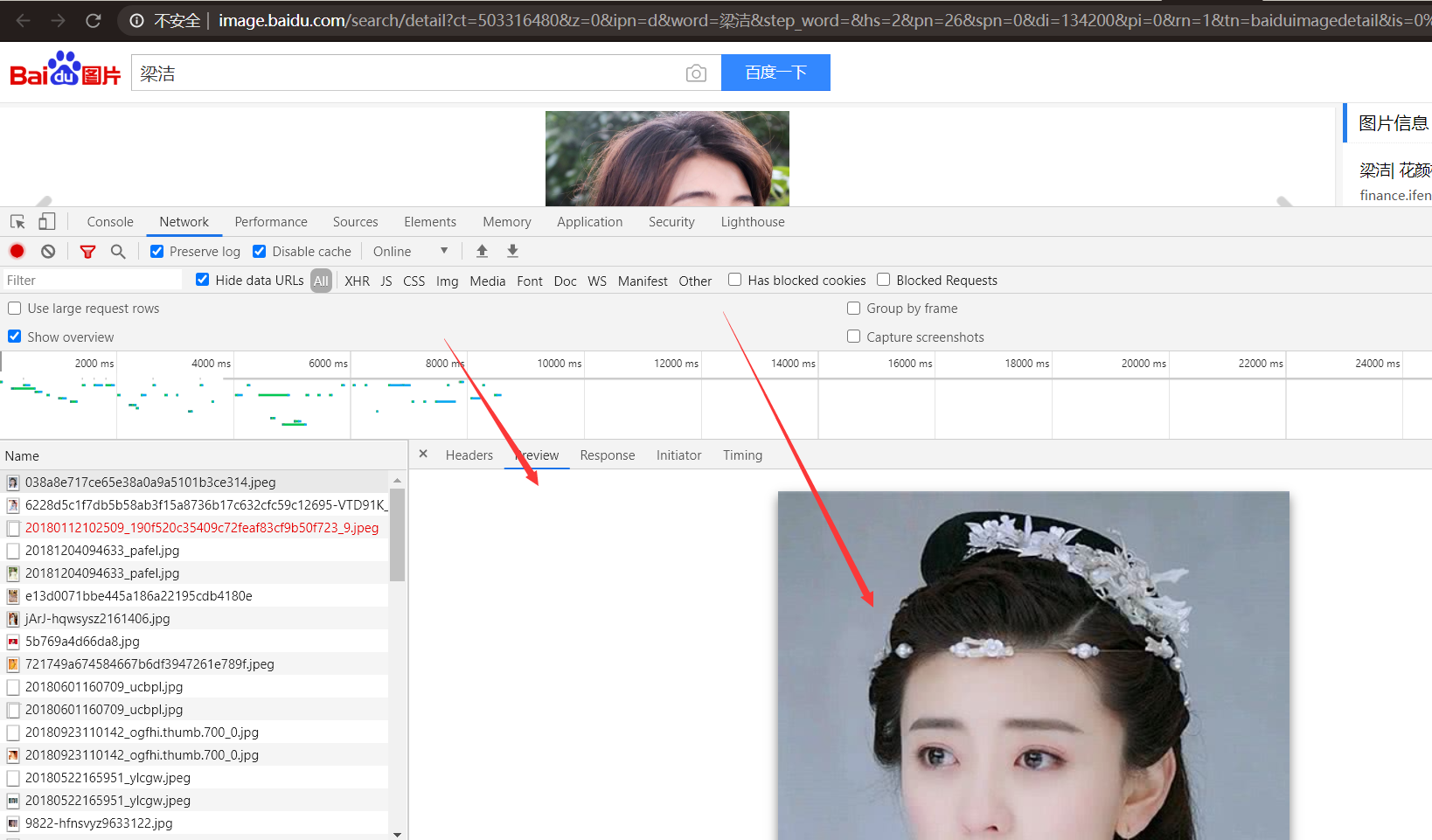
在瀏覽器開發者工具中點選 Preview,就可以看到網頁的原始碼,也就是響應體的內容,它是解析的目標。
在做爬蟲時,我們主要通過響應體得到網頁的原始碼、JSON 資料等,然後從中做相應內容的提取。
三、web網頁基礎
3.1 網頁的組成
網頁可以分為三大部分 —— HTML、CSS 和 JavaScript。如果把網頁比作一個人的話,HTML 相當於骨架,JavaScript 相當於肌肉,CSS 相當於面板,三者結合起來才能形成一個完善的網頁。下面我們分別來介紹一下這三部分的功能。
3.1.1 html
HTML 是用來描述網頁的一種語言。
- HTML 指的是超檔案標示語言 (Hyper Text Markup Language)
- HTML 不是一種程式語言,而是一種標示語言 (markup language)
- 標示語言是一套標記標籤 (markup tag)
- HTML 使用標記標籤來描述網頁
HTML 標籤
- HTML 標記標籤通常被稱為 HTML 標籤 (HTML tag)。
- HTML 標籤是由尖括號包圍的關鍵詞,比如
- HTML 標籤通常是成對出現的,比如 和
- 標籤對中的第一個標籤是開始標籤,第二個標籤是結束標籤
- 開始和結束標籤也被稱為開放標籤和閉合標籤
HTML 檔案 = 網頁
- HTML 檔案描述網頁
- HTML 檔案包含 HTML 標籤和純文字
- HTML 檔案也被稱為網頁
Web 瀏覽器的作用是讀取 HTML 檔案,並以網頁的形式顯示出它們。瀏覽器不會顯示 HTML 標籤,而是使用標籤來解釋頁面的內容:
<html>
<body>
<h1>我的第一個標題</h1>
<p>我的第一個段落。</p>
</body>
</html>
3.1.2 css
什麼是 CSS?
- CSS 指層疊樣式表 (Cascading Style Sheets)
- 樣式定義如何顯示 HTML 元素
- 樣式通常儲存在樣式表中
- 把樣式新增到 HTML 4.0 中,是為了解決內容與表現分離的問題
- 外部樣式表可以極大提高工作效率
- 外部樣式表通常儲存在 CSS 檔案中
- 多個樣式定義可層疊為一個
body {
background-color:#d0e4fe;
}
h1 {
color:orange;
text-align:center;
}
p {
font-family:"Times New Roman";
font-size:20px;
}
3.1.3 JavaScript
JavaScript 是屬於 HTML 和 Web 的程式語言。
程式設計令計算機完成您需要它們做的工作。
JavaScript 是 web 開發人員必須學習的 3 門語言中的一門:
- HTML 定義了網頁的內容
- CSS 描述了網頁的佈局
- JavaScript 控制了網頁的行為
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<!-- 編寫css檔案 需要使用 style -->
<style>
h1{
color: red;
text-align: center;
}
</style>
<body>
<!-- 編寫文字 需要使用 h5 標籤 -->
<h1 id="text">大家好,我是塵世風</h1>
<p>
</p>
<div>
<img src="https://t9.baidu.com/it/u=2219788502,4244472931&fm=218&app=137&size=f242,150&n=0&f=JPEG&fmt=auto?s=F9231F703F227A15696CD9CD0300A0B3&sec=1658595600&t=4967a0d0d262421dd9926f00a598186e">
請求報文格式

通訊端物件伺服器端方法

綜合案例---使用socket下載圖片
url = 'https://img1.baidu.com/it/u=3028486691,1206269421&fm=253&fmt=auto&app=138&f=JPEG?w=499&h=323'
import socket # socket模組是python自帶的內建模組,不需要我們去下載
# 建立通訊端使用者端
client = socket.socket()
# 存取網站
url = 'img1.baidu.com'
# 埠
port = 80
# 連線,通過(ip,埠)來進行連線
client.connect((url,port))
resq = "GET /it/u=3028486691,1206269421&fm=253&fmt=auto&app=138&f=JPEG?w=499&h=323 HTTP/1.0\r\nHost: img1.baidu.com\r\n\r\n"
# 根據請求頭來傳送請求資訊
client.send(resq.encode())
# 建立一個二進位制物件用來儲存我們得到的資料
result = b''
data = client.recv(1024)
# 迴圈接收響應資料 新增到bytes型別
while data:
result+=data
data = client.recv(1024)
import re
# re.S 匹配包括換行在內的所有字元 ,去掉響應頭
images = re.findall(b'\r\n\r\n(.*)',result, re.S)
# 開啟一個檔案,將我們讀取到的資料存入進去,即下載到本地我們獲取到的圖片
with open("可愛的小姐姐.jpg","wb") as f:
f.write(images[0])
六、httpx模組
httpx是Python新一代的網路請求庫,它包含以下特點
- 基於Python3的功能齊全的http請求模組
- 既能傳送同步請求,也能傳送非同步請求
- 支援HTTP/1.1和HTTP/2
- 能夠直接向WSGI應用程式或者ASGI應用程式傳送請求
環境安裝
pip install httpx
測試
headers = {'user-agent': 'my-app/1.0.0'}
params = {'key1': 'value1', 'key2': 'value2'}
url = 'https://httpbin.org/get'
r = httpx.get(url, headers=headers, params=params)
爬蟲請求案例
# encoding: utf-8
"""
@author:chenshifeng
@file: 爬蟲案例.py
@time:2022/10/14
"""
import httpx
import os
class S_wm(object):
def __init__(self):
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
def get_url_list(self):
url_list = ['https://img1.baidu.com/it/u=1875739781,4152007440&fm=253&fmt=auto&app=120&f=JPEG?w=1024&h=576',
'https://img1.baidu.com/it/u=3980896846,3728494487&fm=253&fmt=auto&app=138&f=JPEG?w=333&h=499',
'https://img1.baidu.com/it/u=467548803,2897629727&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=500',
]
return url_list
def save_image(self,filename,img):
with open(filename, 'wb') as f:
f.write(img.content)
print('圖片提取成功')
def run(self):
url_list = self.get_url_list()
for index,u in enumerate(url_list):
file_name = './image/{}.jpg'.format(index)
data = httpx.request('get', u, headers=self.headers)
self.save_image(file_name,data)
if __name__ == '__main__':
url = 'https://www.vmgirls.com/13344.html'
s = S_wm()
if os.path.exists("./image") is False:
os.mkdir('./image')
s.run()