tensorflow-gpu版本安裝及深度神經網路訓練與cpu版本對比
tensorflow1.0和tensorflow2.0的區別主要是1.0用的靜態圖
一般情況1.0已經足夠,但是如果要進行深度神經網路的訓練,當然還是tensorflow2.*-gpu比較快啦。
其中tensorflow有CPU和GPU兩個版本(2.0安裝方法),
CPU安裝比較簡單:
pip install tensorflow-cpu
一、檢視顯示卡
日常CPU足夠,想用GPU版本,要有NVIDIA的顯示卡,檢視顯示卡方式如下:
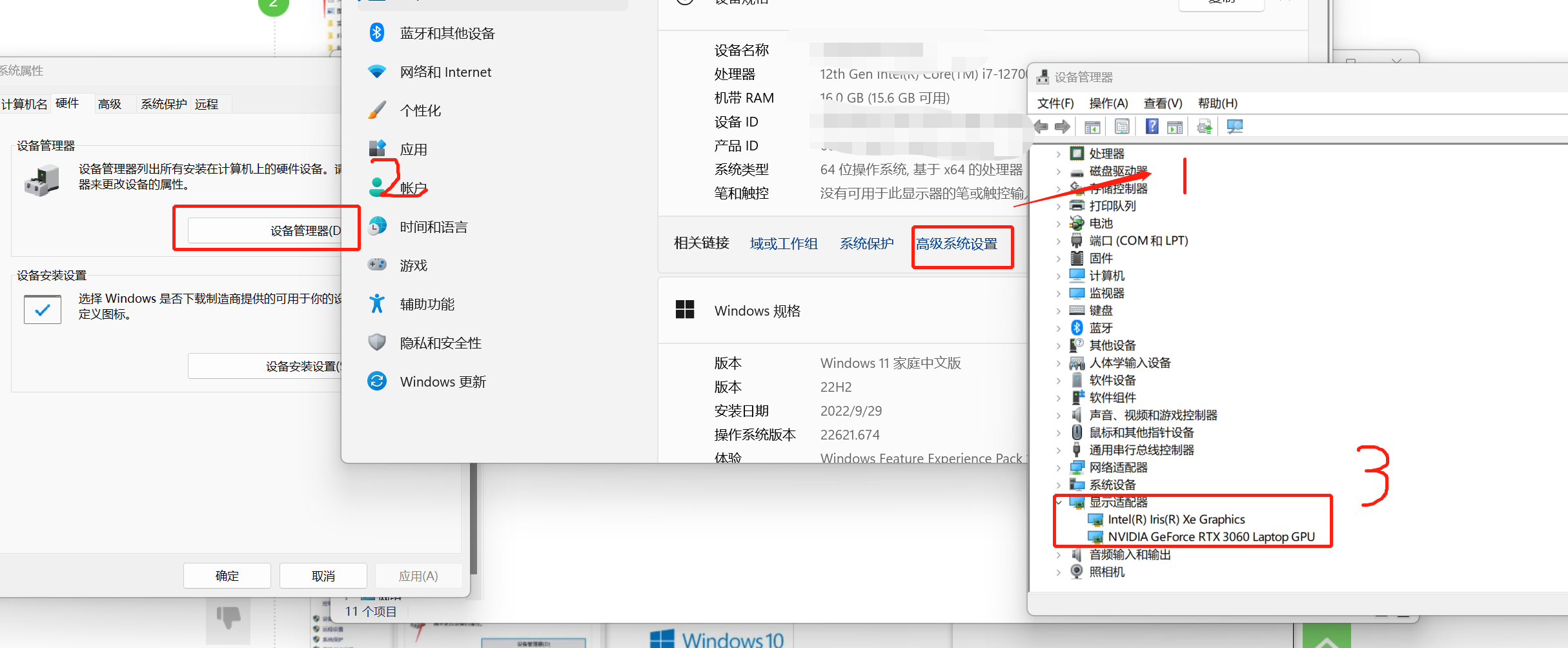
二、檢視版本對應關係
然後我們需要去下載NVIDIA驅動CUDA以及支援神經網路訓練的CUDNN模組:(重點,其中需要檢視自己NVIDIA版本 Python版本 CUDNN版本是否匹配)

下載CUDA:https://developer.nvidia.com/cuda-11.3.0-download-archive
三、安裝cudnn
CUDA安裝完畢後,需要安裝支援神經網路訓練的CUDNN模組,下載 cuDNN,下載之前需要先註冊一下 Nvidia 的賬號,下載地址為:https://developer.nvidia.com/rdp/cudnn-download
下載完成之後將其解壓,解壓之後的目錄如下:
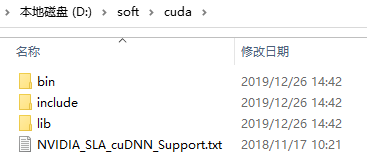
需要將以上三個檔案複製到CUDA的安裝目錄中,通過上面的安裝,我們將CUDA安裝到了C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3中。
四、安裝anaconda
安裝Anaconda:
然後最好是使用anaconda安裝tensorflow,先去安裝anaconda,詳細教學傳送門:https://blog.csdn.net/fan18317517352/article/details/123035625
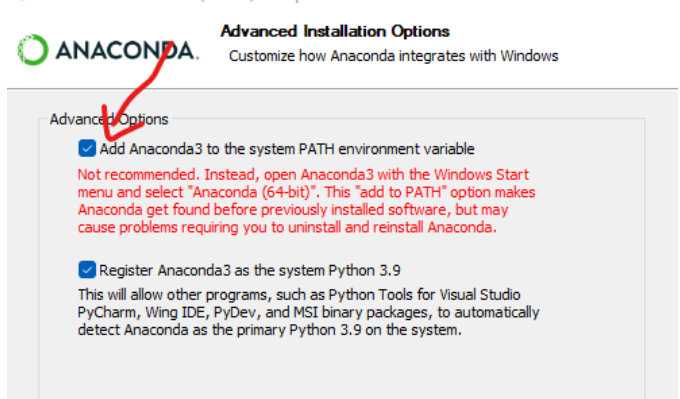
其實如果不想麻煩的設定環境變數,可以在安裝Anaconda過程中選擇JUST ME, 然後將Anaconda加入環境變數。
然後直接就可以在anaconda裡選擇tensorflow-gpu進行安裝,安裝完畢後,檢視能否支援gpu:
import os
import tensorflow as tf
print(tf.test.is_gpu_available())
gpus = tf.config.list_physical_devices('GPU')
cpus = tf.config.list_physical_devices('CPU')
print(gpus, cpus)
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
如果輸出如下,則說明可以使用GPU
(注意,真的只是可以使用,不代表可以用了,自己體會,我曾經被坑了好久):

五、測試(重點乾貨來了)
import os
# 指定使用0卡
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
如果提示缺少dll檔案,去這個網址找:https://cn.dll-files.com/cudart64_110.dll.html 缺啥找啥,看連結字尾
然後訓練模型,發現只能訓練前饋神經網路,速度還很慢,訓練深度網路時,直接記憶體不足,但原因可能是由於缺少檔案:(這個問題我查了很多資料,大部分無關痛癢,沒有對症下藥)
有說卸了GPU版本裝CPU版的,完事後還說CPU比GPU快,我也是很無語(我只想說那你何必廢勁用GPU呢,直接用CPU不就好了,
至於CPU比GPU快的問題,這個問題要看你的網路結構大小了,網路結構比較小的時候(比如簡單前饋神經網路),cpu與gpu資料傳輸過程耗時更高,這個時候只用cpu會更快。
網路結構比較龐大的時候,(比如深層折積神經網路,層數大於10層就很明顯了,CPU根本跑不動),gpu的提速就比較明顯了。
)
Process finished with exit code -1073740791 (0xC0000409)

解決辦法:Pycharm中,點選RUN-EDIT CONFIGURATIONS,輸出錯誤資訊

發現缺少檔案:

下載zlib並且解壓

dll放到cuda安裝目錄的bin裡,lib放到cuda安裝目錄的lib資料夾下,然後開始訓練,你會發現用GPU真香
CPU耗時:

GPU耗時:

切換CPU GPU 只要切換裝置就行了,我只進行了2epoch的折積訓練,可以看到GPU速度要比CPU快個4 5 倍左右,如果是前饋神經網路或者簡單的神經網路,測試驗證使用CPU是比GPU要快的,所以自己需要根據實際情況切換裝置。
需要zlib檔案的可以給我留言。