微服務12:系統服務熔斷、限流
微服務1:微服務及其演進史
微服務2:微服務全景架構
微服務3:微服務拆分策略
微服務4:服務註冊與發現
微服務5:服務註冊與發現(實踐篇)
微服務6:通訊之閘道器
微服務7:通訊之RPC
微服務8:通訊之RPC實踐篇(附原始碼)
微服務9:服務治理來保證高可用
1 為什麼熔斷限流
分散式系統環境下,服務間類似依賴非常常見,一個業務呼叫通常依賴多個基礎服務。
如下圖,對於同步呼叫,當庫存服務不可用時,商品服務請求執行緒被阻塞,當有大批次請求呼叫庫存服務時,最終可能導致整個商品服務資源耗盡,
無法繼續對外提供服務。並且這種不可用可能沿請求呼叫鏈向上傳遞,這種現象被稱為雪崩效應。

1.2 雪崩效應常見場景
- 硬體故障:如伺服器宕機,機房斷電,光纖甚至專線被破壞等。
- 流量激增:如異常流量,線上活動導致的流量激增,重試導致流量放大等。
- 快取穿透:快取服務重啟,導致大量快取同時失效時。重建快取或者大量的請求無法命中快取,會直接投向資料庫,導致服務和資料層壓力驟增甚至雪崩。
- 程式漏洞:如程式邏輯(如死迴圈)導致記憶體漏失,或者死鎖操作導致互相等待,或者JVM長時間FullGC等。
- 同步等待:服務間採用同步呼叫模式,同步等待造成的資源耗盡。
1.3 雪崩效應應對策略
針對上述的常見場景,需要給出不同的策略來應對,主要有如下幾個方面,參考如下:
- 硬體故障:分服甚至分機房容災、異地多活等。
- 流量激增:服務動態擴縮容,流量控制(熔斷,限流,超時重試)等。
- 快取穿透:快取預載入、非同步載入,設定不定的過期時間等。詳細參考這篇《一次快取雪崩的災難覆盤》
- 程式的健壯性:修復程式漏洞、避免記憶體漏失、及時釋放資源 等等。
- 同步等待:資源隔離、MQ解耦、不可用服務呼叫快速失敗(超時能力)等。
綜合上述的內容可知,如果一個服務不能對自己依賴以及產生的故障進行隔離,那麼它自己本身就會處在雪崩風險中。要想構建穩定健壯的分散式系統,我們的服務應當具有自我保護能力和容錯的能力。
避免造成更大的故障設定服務雪崩。而這種自我保護的模式就是熔斷、限流、異常驅逐等能力。
2 常見的限流的演演算法
2.1 計數限流演演算法
計數演演算法是指再一定的時間間隔裡,記錄請求次數,當時間間隔到期之後,就把計數清零,重新計算。如果請求次數超過統計週期內額定的最大次數時,直接拒絕存取,簡單粗暴。
計數器的值要是存在記憶體中就算單機限流演演算法,類似 Atomic 等原子類。如果存放在類似Redis的第三方快取服務服務中就是分散式限流了,類似 Redis incr、Redis decr。
如下圖所示:

可能存在的問題是:請求分佈的不均衡,比如在時間週期1分鐘的第1秒,就把100次請求用完了,那麼最後59秒都是空白的。也可能直到最後1秒才有大批次的流量
湧入,造成系統的不穩定。
2.2 固定視窗限流演演算法(取樣時間窗)

固定視窗計數演演算法的步驟是:
- 將時間劃分為固定的時間視窗,比如1s。
- 在視窗時間段內,每來一個請求,對計數器加1。
- 當計數器達到設定限制後(比如上圖,限制了5s),該視窗時間內的之後的請求都被直接拒絕了。
- 時間窗結束後,計數器重置,重新開始計數。
2.3 滑動視窗限流(記錄每個請求到達的時間點)
滑動視窗限流解決固定視窗臨界值的問題,可以保證在任意時間視窗內都不會超過閾值。
相對於固定視窗,滑動視窗除了需要引入計數器之外還需要記錄時間視窗內每個請求到達的時間點,因此對記憶體的佔用會比較多。

上圖中每個時間視窗限流8個req,滑動視窗計數演演算法的步驟如下:
- 將一個時間視窗劃分為細粒度的區間,每個區間設定一個計數器,每incr一個請求則將計數+1。
- 因為一個時間視窗是由多個時間區間組成,每走完一個區間時間後,則拋棄最老的一個區間,納入新區間。如上圖拋棄區間1,納入新區間3
- 視窗由t1 過渡為 視窗t2。
- 若當前視窗的區間計數器總和超過額定的限制數量8,別區間2使用了5,則區間3最多隻能使用剩下3個,後續請求都被丟棄。
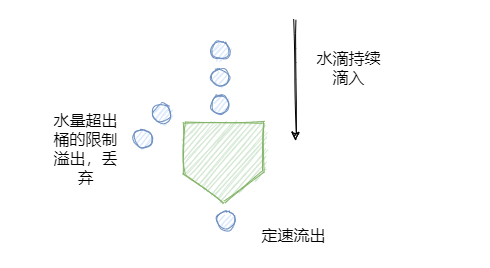
2.4 漏桶演演算法(漏斗池演演算法)
類似沙漏思維,大家都用過,沙子是勻速流出得。對於漏桶來說,由於它的出水口的速度是恆定的,也就是消化處理請求的速度是恆定的,所以它可以保證元件以恆定的速率來處理請求,
這對一些對處理速度或者資源有嚴格要求的系統是非常實用的。原理如下:
- req到來則放入桶中
- 桶內請求量滿了,則拒絕後續的請求
- 服務定速地從桶內拿出請求並處理
寬進嚴出是它最大的特點,無論請求多少,請求的速率有多大,都按照固定的速率流出(定速輸出),而服務也只能按照固定速率處理,有點像固定延時的訊息佇列。
如果有處理不過來的請求,那就按照佇列進行排隊,避免巨大輸出把服務搞掛掉,佇列滿了就refuse。
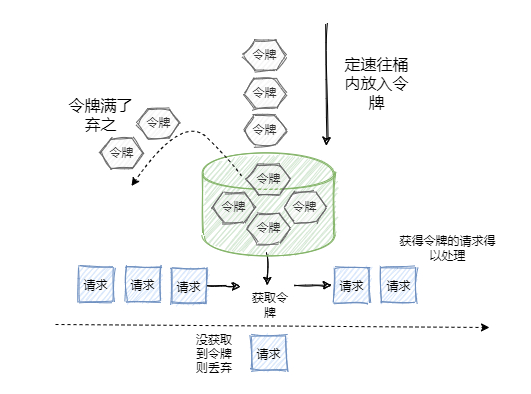
2.5 令牌桶演演算法(定速流入)
令牌桶和漏桶的原理類似,只不過漏桶是定速流出,令牌桶是定速流入(即往桶裡塞入令牌),每個請求進來,分配一個令牌,只有拿到了令牌才能進入伺服器處理,拿不到令牌的就被拒絕了。
因為令牌桶的大小也是有限制的,所以一旦令牌桶滿,後續生成的令牌就會被丟棄,拿不到令牌的服務請求就被拒絕了,達到限流的目的。執行原理如下:
- 定速將令牌放如令牌桶
- 當桶裡面的令牌數量超過桶的額度,直接丟棄
- 當req進來,令牌桶會分配一個令牌給請求,如果令牌桶空了,則請求會被直接拒絕
相對於漏洞的定速流程那種的勻速消費模式,令牌桶可以將積壓的令牌一下子花掉,所以在應對流量洪峰的時候,他的表現比露銅演演算法更優異。
2.6 應用場景
Google Guava 提供的限流工具類 RateLimiter,是基於令牌桶實現的,並且擴充套件了演演算法,支援預熱功能。
阿里開源的限流框架Sentinel 中的勻速排隊限流策略,就採用了漏桶演演算法。
3 主流熔斷限流技術介紹
3.1 Sentinel熔斷降級
3.1.1 介紹
Sentinel 被稱為高可用流量管理框架,分散式系統流量衛兵。假如對一個介面QPS(每秒請求數)最大限制為10000,在QPS超過10000之後的請求我們就要限制其存取,並給出友好的提示。
不限制QPS無限的次數就會造成伺服器超量存取而宕機。在服務呼叫的過程中,如果呼叫鏈路中的某個資源出現了不穩定,比如錯誤數增加,請求平響升高,則大概率會導致請求堆積,進而誘發整個鏈路的雪崩,解決辦法就是熔斷、限流、降級。熔斷限流就是當檢測到呼叫鏈路中某個服務出現不穩定時,對服務的呼叫進行限制,讓請求快速失敗,避免影響到其它的資源而導致級聯故障。
3.1.2 功能特性
Sentinel是分散式系統的流量防衛兵,他有如下優秀特質:
3.2 Spring Cloud 的Hystrix
Hystrix是一個用於處理分散式系統的延遲和容錯的開源庫,在分散式系統裡,許多依賴不可避免的會呼叫失敗,比如超時、異常等,Hystrix能夠保證在一個依賴出問題的情況下,不會導致整體服務失敗,避免級聯故障,以提高分散式系統的彈性。「斷路器」本身是一種開關裝置,當某個服務單元發生故障之後,通過斷路器的故障監控(類似熔斷保險絲),向呼叫方返回一個符合預期的、可處理的備選響應(FallBack),而不是長時間的等待或者丟擲呼叫方無法處理的異常,這樣就保證了服務呼叫方的執行緒不會被長時間、不必要地佔用,從而避免了故障在分散式系統中的蔓延,乃至雪崩。
3.2.1 使用方式
- 構建HystrixCommand,執行命令,execute()、queue()、observe()、toObservable()
- 新增 @WafHystrixFallback 註解
- 判斷熔斷器是否開啟;判斷執行緒池/佇列/號誌是否已滿;執行HystrixObservableCommand.construct()或HystrixCommand.run() 失敗或者超時,走Fallback備用邏輯。
4 總結
- 熔斷限流的目的是避免超出預期的呼叫、或者你自身服務的故障 造成服務響應延遲,請求堆積,甚至服務雪崩。而雪崩會隨著呼叫鏈向上傳遞,可能導致整個服務鏈的崩潰。
- 常見的限流演演算法有:計數限流、固定視窗限流、滑動視窗限流、漏桶演演算法、令牌同演演算法等。
- 主流的熔斷限流技術有 Hystrix 、Rate Limiter、Seninel 等
