kafka詳解(二)--kafka為什麼快
前言
Kafka 有多快呢?我們可以使用 OpenMessaging Benchmark Framework 測試框架方便地對 RocketMQ、Pulsar、Kafka、RabbitMQ 等訊息系統進行對比測試,因為暫時沒有測試條件(後續補上),我直接用這篇文章的測試結果(Benchmarking Kafka vs. Pulsar vs. RabbitMQ: Which is Fastest?),可以看到,在某種條件下,Kafka 寫入速度比 RabbitMQ 快 15 倍,比 Pulsar 快 2 倍,在最高吞吐量下仍保持低延遲。

那麼,為什麼 Kafka 可以那麼快呢?這裡我先簡單總結,後面會展開分析。
- 從磁碟中順序讀寫 event。
- 通過批次處理減少大量小 I/O。
- 從檔案到 socket 之間資料零拷貝。
- 基於分割區的橫向擴充套件。
ps:[本系列](部落格後臺 - 部落格園 (cnblogs.com))部落格將持續更新。
順序讀寫磁碟
Kafka 嚴重依賴檔案系統來讀寫 event。我們不禁會問,磁碟不是很慢嗎?Kafka 真的能提供很好的效能嗎?
事實上,磁碟比人們預期的要慢得多,也快得多,這取決於它們的使用方式。在這篇文章中(ACM Queue article)可以發現,在某些情況下,順序磁碟存取可能比隨機記憶體存取更快。這要得益於現代作業系統對磁碟讀寫進行的大量的優化,包括 read-ahead 和 write-behind 技術,當我們順序讀取磁碟時,更多時候存取的不是磁碟,而是記憶體--pagecache。
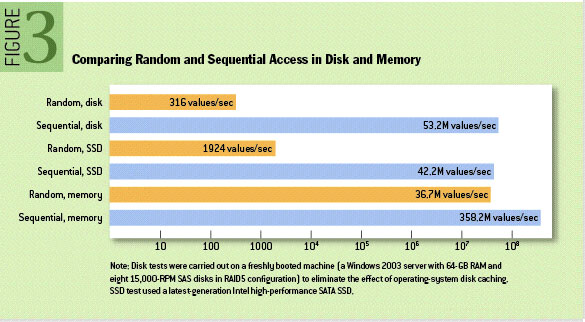
因此,只要順序存取檔案系統,磁碟也可以很快。Kafka 的 event 組織方式以及應用場景,天然地支援了順序讀寫,並且 Kafka 也為此做了許多努力,例如批次處理、追加寫入等。
此外,相比主動將 event 維護在記憶體,採用檔案系統還有以下好處:
-
可以快取更多的資料。在 JVM 中,維護物件的記憶體開銷將是實際資料大小的兩倍甚至更糟,隨著堆內資料的增加,gc 將愈發頻繁。而使用檔案系統可以在 pagecache 中快取更多更緊湊的資料,而不需要考慮 gc 問題。
-
重啟後恢復更快。由於資料快取在 pagecache,程序重啟,這部分快取仍然可以保持 warn 的狀態,如果在程序記憶體中維護這些資料的話,每次啟動都需要重建(對於 10GB 快取可能需要 10 分鐘)。
-
資料不會丟失。如果資料維護在記憶體中,需要考慮定期將資料持久化到磁碟,一致性和效能的權衡將是一個比較麻煩的問題,即便如此,我們也不能保證資料不會丟失,例如 redis 可能損失幾秒的資料,甚至更多。在理論上,Kafka 就不會出現資料丟失的情況。
-
大大簡化了程式碼。用於維護快取和檔案系統之間一致性的所有邏輯現在都在作業系統中,而作業系統往往更高效、更正確。
通過批次處理減少小I/O
小 I/O 操作發生在使用者端和伺服器端之間的資料傳輸以及伺服器端自身的持久化操作。
為了避免小 I/O 操作,Kafka 是以批的形式來操作 event,而不是一次傳送一條訊息。producer 會嘗試在記憶體中積累資料,並在單個請求中傳送更大的批,當然,這種方式是犧牲少量額外延遲以獲得更好的吞吐量,我們可以設定累積數量和等待時間來平衡。同理,consumer 讀取資料時也會嘗試一次讀取更多。
批次處理可以產生較大順序磁碟操作和連續記憶體塊,不過也產生了較大的網路封包,相應地,Kafaka 會將訊息壓縮後傳送,當訊息寫入紀錄檔時仍然是壓縮形式,僅由使用者解壓縮。
資料零拷貝
另一個問題是過多的位元組複製。//zzs001
一般情況下,資料從檔案傳輸到 socket 的資料路徑為:磁碟 -》核心的 pagecache -》使用者空間緩衝區 -》核心的 socket 緩衝區 -》NIC 緩衝區。
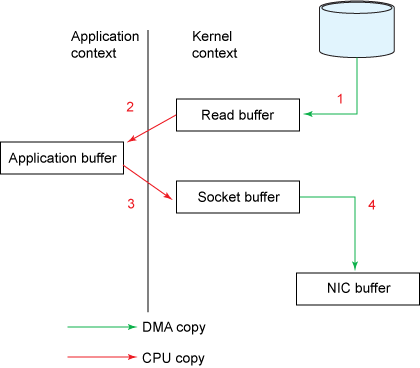
顯然,這是非常低效的,有四個副本和兩個系統呼叫。Kafka 使用 sendfile,允許作業系統將資料從 pagecache 直接傳送到網路,即磁碟 -》核心的 pagecache-》NIC 緩衝區。從而避免這種重複複製和系統呼叫。更多關於 sendfile 的內容可以參考Efficient data transfer through zero copy。
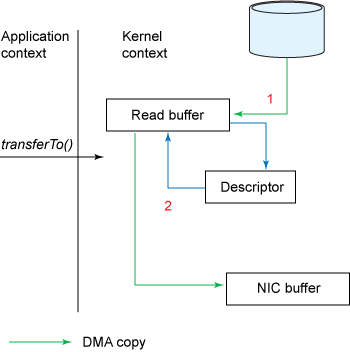
需要注意的是,由於 TLS/SSL 庫是工作在使用者空間的,所以,當啟用了 SSL,sendfile 將不能使用。
基於分割區的橫向擴充套件
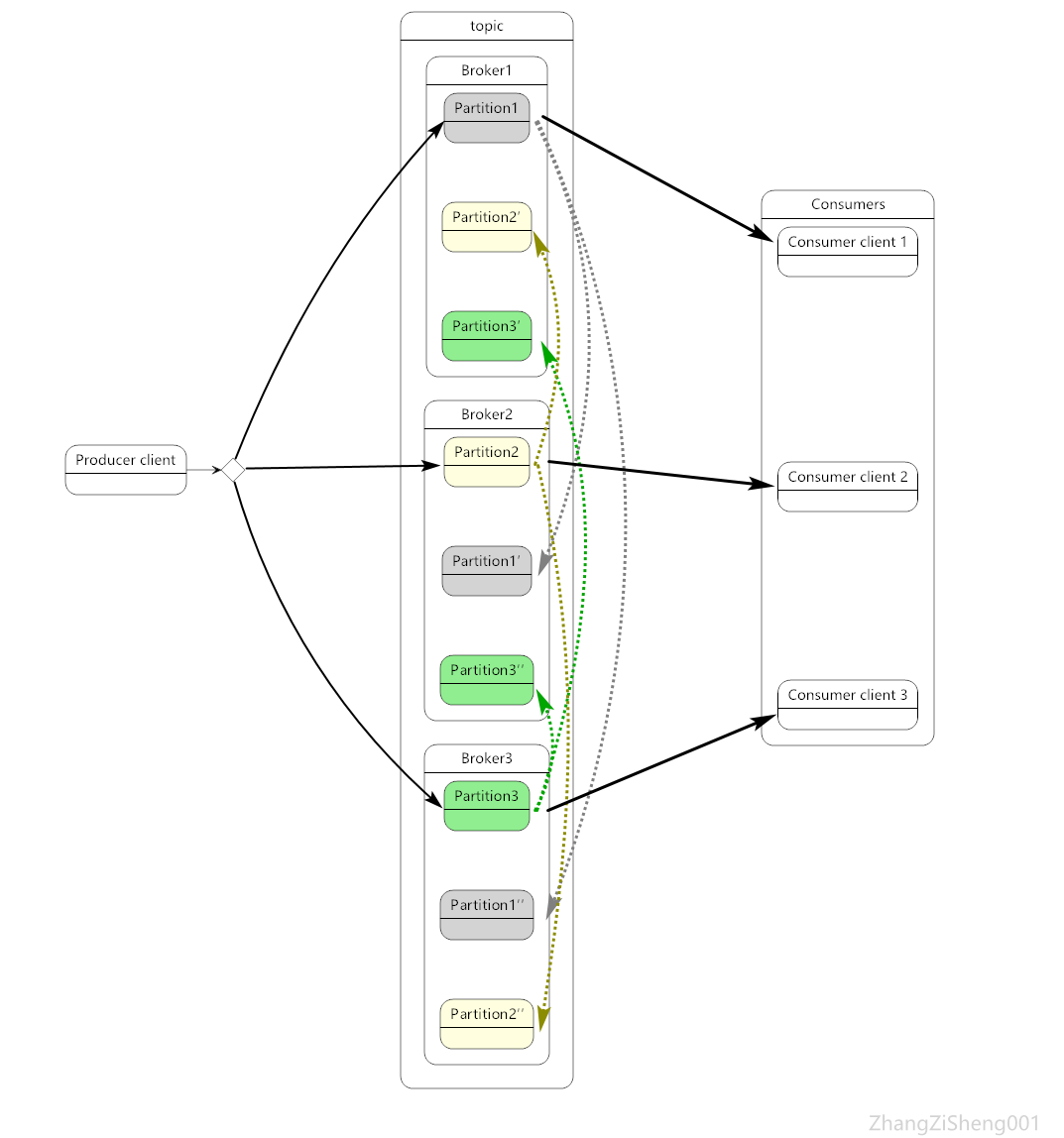
關於這一點,在上一篇部落格中其實已經提到過。首先,一個 topic 會劃分成一個或多個 partition,這些 partition 一般分佈在不同的 broker 範例。producer 釋出的 event 會根據某種策略分配到不同的 partition,這樣做的好處是,consumer 可以同時從多臺 broker 讀取 event,從而大大提高吞吐量。另外,為了高可用,同一個 partition 還會有多個副本,它們分佈在不同的 broker 範例,和很多傳統的訊息系統不同,Kafka 的副本是可讀的,即 consumer 不僅可以從主 partition 讀取 event,也可以從副本讀取。//zzs001
結語
以上內容是最近學習 Kafka 的一些思考和總結(主要參考官方檔案),如有錯誤,歡迎指正。
任何的事物,都可以被更簡單、更連貫、更系統地瞭解。希望我的文章能夠幫到你。
最後,感謝閱讀。
參考資料
Benchmarking Kafka vs. Pulsar vs. RabbitMQ: Which is Fastest?
The OpenMessaging Benchmark Framework
The Pathologies of Big Data - ACM Queue
Efficient data transfer through zero copy - IBM Developer
本文為原創文章,轉載請附上原文出處連結:https://www.cnblogs.com/ZhangZiSheng001/p/16788561.html