雪花演演算法詳解(原理優缺點及程式碼實現)

雪花演演算法簡介
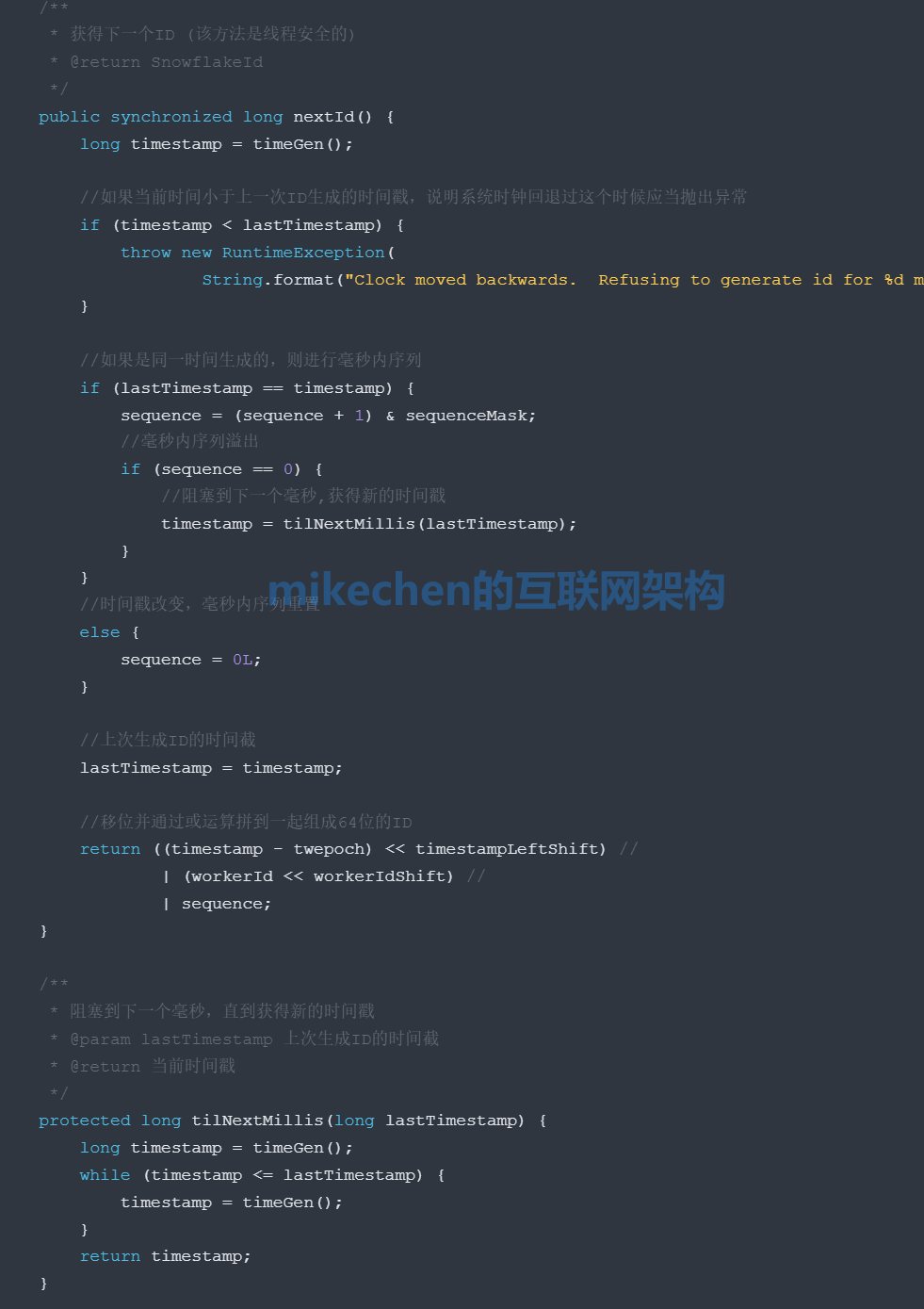
雪花演演算法,英文名為snowflake,翻譯過來就是是雪花,所以叫雪花演演算法。
在大自然雪花形成過程中,會形成不同的結構分支,所以說不存在兩片完全一樣的雪花,表示生成的id如雪花般獨一無二。

雪花演演算法,它最早是twitter內部使用的分散式環境下的唯一分散式ID生成演演算法。
雪花演演算法的優缺點
雪花演演算法,它至少有如下4個優點:
1.系統環境ID不重複
能滿足高並行分散式系統環境ID不重複,比如大家熟知的分散式場景下的資料庫表的ID生成。
2.生成效率極高
在高並行,以及分散式環境下,除了生成不重複 id,每秒可生成百萬個不重複 id,生成效率極高。
3.保證基本有序遞增
基於時間戳,可以保證基本有序遞增,很多業務場景都有這個需求。
4.不依賴第三方庫
不依賴第三方的庫,或者中介軟體,演演算法簡單,在記憶體中進行。
雪花演演算法,有一個比較大的缺點:
依賴伺服器時間,伺服器時鐘回撥時可能會生成重複 id。
雪花演演算法原理
詳細的雪花演演算法構造如下圖所示:
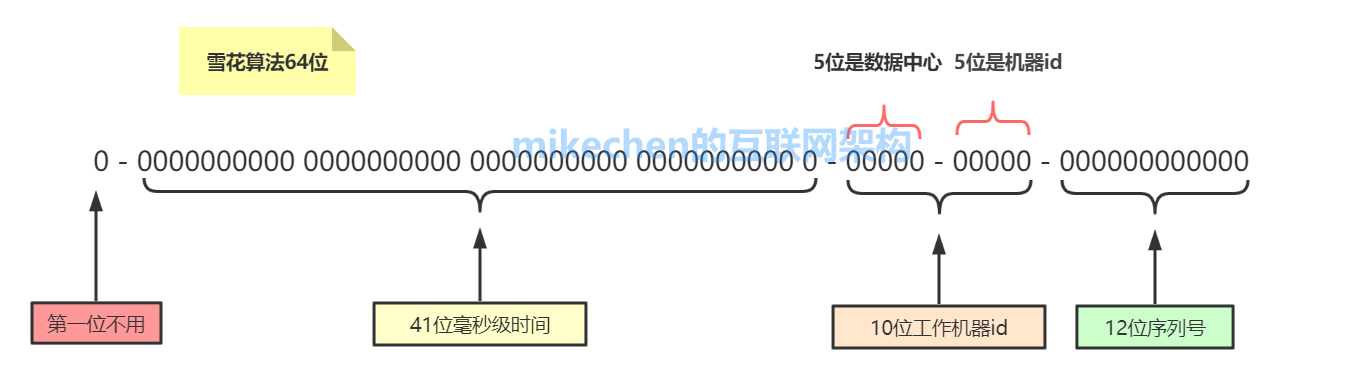
雪花演演算法的原理:就是生成一個的 64 位的 long 型別的唯一 id,主要分為如下4個部分組成:
1)1位保留 (基本不用)
1位標識:由於long基本型別在Java中是帶符號的,最高位是符號位,正數是0,負數是1,所以id一般是正數,最高位是0,所以這第一位都是0。
2)41位時間戳
接下來 41 位儲存毫秒級時間戳,41位可以表示2^41-1個毫秒的值,轉化成單位年則是:(2^41−1)/(1000∗60∗60∗24∗365)=69年 。
41位時間戳 :也就是說這個時間戳可以使用69年不重複,大概可以使用 69 年。
注意:41位時間截不是儲存當前時間的時間截,而是儲存時間截的差值「當前時間截 – 開始時間截」得到的值。
這裡的的開始時間截,一般是我們的id生成器開始使用的時間,由我們程式來指定的,一般設定好後就不要去改變了,切記!!!
因為,雪花演演算法有如下缺點:依賴伺服器時間,伺服器時鐘回撥時可能會生成重複 id。
3)10位機器
10位的資料機器位,可以部署在1024個節點,包括5位datacenterId和5位workerId,最多可以部署 2^10=1024 臺機器。
這裡的5位可以表示的最大正整數是2^5−1=31,即可以用0、1、2、3、….31這32個數位,來表示不同的datecenterId,或workerId。
4) 12bit序列號
用來記錄同毫秒內產生的不同id,12位元的計數順序號支援每個節點每毫秒(同一機器,同一時間截)產生4096個ID序號。
理論上雪花演演算法方案的QPS約為409.6w/s,這種分配方式可以保證在任何一個IDC的任何一臺機器在任意毫秒內生成的ID都是不同的。


作者簡介
陳睿|mikechen,10年+大廠架構經驗,《BAT架構技術500期》系列文章作者,專注於網際網路架構技術。
閱讀mikechen的網際網路架構更多技術文章合集
Java並行|JVM|MySQL|Spring|Redis|分散式|高並行