我說HashMap初始容量是16,面試官讓我回去等通知
眾所周知HashMap是工作和麵試中最常遇到的資料型別,但很多人對HashMap的知識止步於會用的程度,對它的底層實現原理一知半解,瞭解過很多HashMap的知識點,卻都是散亂不成體系,今天一燈帶你一塊深入淺出的剖析HashMap底層實現原理。
看下面這些面試題,你能完整的答對幾道?
1. HashMap底層資料結構?
JDK1.7採用的是陣列+連結串列,陣列可以通過下標存取,實現快速查詢,連結串列用來解決雜湊衝突。
連結串列的查詢時間複雜度是O(n),效能較差,所以JDK1.8做了優化,引入了紅黑樹,查詢時間複雜度是O(logn)。
JDK1.8採用的是陣列+連結串列+紅黑樹的結構,當連結串列長度大於等於8,並且陣列長度大於等於64時,連結串列才需要轉換成成紅黑樹。

2. HashMap的初始容量是多少?
如果面試的時候,你回答是16,面試官肯定讓你回去等通知。
JDK1.7的時候初始容量確實是16,但是JDK1.8的時候初始化HashMap的時候並沒有指定容量大小,而是在第一次執行put資料,才初始化容量。
// 負載因子大小
final float loadFactor;
// 預設負載因子大小
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 初始化方法
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
執行new HashMap()方法初始化的時候,只指定了負載因子的大小。
3. HashMap的put方法流程?
- 計算key的雜湊值
- 判斷陣列是否為空,如果為空,就執行擴容,初始化資料大小。
- 如果陣列不為空,根據雜湊值找到陣列所在下標
- 判斷下標元素是否為null,如果為null就建立新元素
- 如果下標元素不為null,就判斷是否是紅黑樹型別,如果是,則執行紅黑樹的新增邏輯
- 如果不是紅黑樹,說明是連結串列,就追加到連結串列末尾
- 如果判斷連結串列長度是否大於等於8,陣列長度是否大於等於64,如果不是就執行擴容邏輯
- 如果是,則需要把連結串列轉換成紅黑樹
- 最後判斷新增元素後,判斷元素個數是否大於閾值(16*0.75=12),如果是則執行擴容邏輯,結束。

原始碼如下:
// put方法入口
public V put(K key, V value) {
// 計算雜湊值
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 判斷陣列是否為空,為空的話,則進行擴容初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 計算陣列下標位置,判斷下標位置元素是否為null
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 陣列中已經存在元素(處理雜湊衝突)
else {
Node<K,V> e; K k;
// 判斷元素值是否一樣,如果一樣則替換舊值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 判斷元素型別是否是紅黑樹
else if (p instanceof TreeNode)
// 執行紅黑樹新增邏輯
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 不是紅黑樹型別則說明是連結串列
else {
// 遍歷連結串列
for (int binCount = 0; ; ++binCount) {
// 到達連結串列的尾部
if ((e = p.next) == null) {
// 在尾部插入新結點
p.next = newNode(hash, key, value, null);
// 連結串列結點數量達到閾值(預設為 8 ),執行 treeifyBin 方法
// 這個方法會根據 HashMap 陣列來決定是否轉換為紅黑樹。
// 只有當陣列長度大於或者等於 64 的情況下,才會執行轉換紅黑樹操作,以減少搜尋時間。否則,就是隻是對陣列擴容。
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 判斷連結串列中結點的key值與插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出迴圈
break;
// 用於遍歷桶中的連結串列,與前面的e = p.next組合,可以遍歷連結串列
p = e;
}
}
// 表示在陣列中找到key值、雜湊值與插入元素相等的結點
if (e != null) {
// 記錄e的value
V oldValue = e.value;
// onlyIfAbsent為false或者舊值為null
if (!onlyIfAbsent || oldValue == null)
//用新值替換舊值
e.value = value;
// 存取後回撥
afterNodeAccess(e);
// 返回舊值
return oldValue;
}
}
// 記錄修改次數
++modCount;
// 元素個數大於閾值則擴容
if (++size > threshold)
resize();
// 插入後回撥
afterNodeInsertion(evict);
return null;
}
4. HashMap容量大小為什麼要設定成2的倍數?
int index = hash(key) & (n-1);
為了更快的計算key所在的陣列下標位置。
當陣列長度(n)是2的倍數的時候,就可以直接通過邏輯與運算(&)計算下標位置,比取模速度更快。
5. HashMap為什麼是執行緒不安全?
原因就是HashMap的所有修改方法都沒有加鎖,導致在多執行緒情況下,無法保證資料一致性和安全性。
比如:一個執行緒刪除了一個key,由於沒有加鎖,其他執行緒無法及時感知到,還繼續能查到這個key,無法保證資料的一致性。
比如:一個執行緒新增完一個元素,由於沒有加鎖,其他執行緒無法及時感知到,另一個執行緒正在擴容,擴容後就把上一個執行緒新增的元素弄丟了,無法保證資料的安全性。
6. 解決雜湊衝突方法有哪些?
常見有鏈地址法、線性探測法、再雜湊法等。
-
鏈地址法
就是把發生雜湊衝突的值組成一個連結串列,HashMap就是採用的這種。
-
線性探測法
發生雜湊衝突後,就繼續向下遍歷,直到找到空閒的位置,ThreadLocal就是採用的這種,以後再詳細講。
-
再雜湊法
使用一種雜湊演演算法發生了衝突,就換一種雜湊演演算法,直到不衝突為止(就是這麼聰明)。
7. JDK1.8擴容流程有什麼優化?
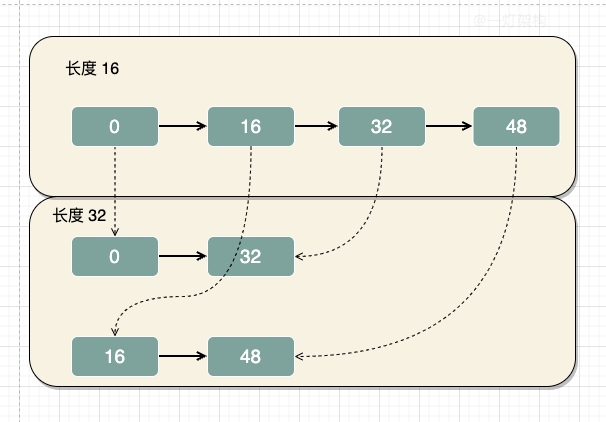
在JDK1.7擴容的時候,會遍歷原陣列,重新雜湊,對新陣列長度邏輯與,計算出資料下標,然後放到新陣列中,比較麻煩耗時。
在JDK1.8擴容的時候,會遍歷原陣列,然後統計出兩組資料,一組是新陣列的下標位置不變,另一組是新陣列的下標位置等於原陣列的下標位置加上原陣列的長度。
比如:陣列長度由16擴容到32,雜湊值是0和32的元素,在新舊陣列中下標位置不變,都是下標為0的位置。而雜湊值是16和48的元素,在新陣列的位置=原陣列的下標+原陣列的長度,也就是下標為16的位置。