企業巨量資料發展面臨問題之存算分離技術思考
@
概述
背景
Hadoop一出生就是奔存算一體設計,當時設計思想就是儲存不動而計算(code也即是程式碼程式)動,負責排程Yarn會把計算任務儘量發到要處理資料所在的範例上,這也是與傳統集中式儲存最大的不同。為何當時Hadoop設計存算一體的耦合?要知道2006年伺服器頻寬只有100Mb/s~1Gb/s,但是HDD也即是磁碟吞吐量有50MB/s,這樣頻寬遠遠不夠傳輸資料,網路瓶頸尤為明顯,無奈之舉只好把計算任務發到資料所在的位置。
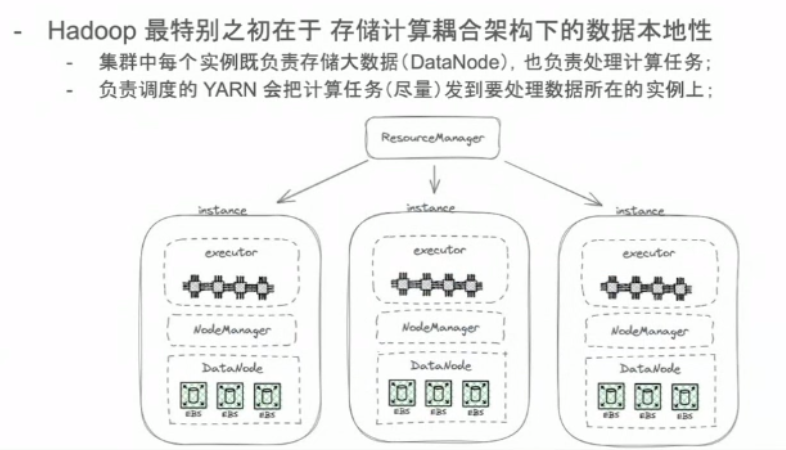
眾觀歷史常言道天下分久必合合久必分,隨著雲端計算技術的發展,資料庫也開始擁抱雲原生時代,在當前越來越強調雲原生的環境下,儲存計算分離已經是大勢所趨,「存算分離」作為一種架構思想在企業專案研發過程中逐漸為大家所熟知和使用,隨著數位化轉型帶來的企業IT架構的重塑,存算分離技術將逐漸走入歷史的舞臺。存算是指儲存和計算組成,通常所說的計算是指由CPU和記憶體組成的算力單元,儲存指的是持久化的資料存放單元。在企業生產實踐過程中沒有一成不變的架構,只有不變的以業務為核心的架構意識。
家庭寬頻自從升級到100m bps甚至更大,從來不儲存電影,要看直接下載,基本幾分鐘就好了,而這在十年前是不可想象。頻寬的速度特別是IDC機房內頻寬的速度,已經從1000mps、2000mps、10000mps,甚至100000mpbs,網路頻寬提升100倍甚至更高,網路已經不再是瓶頸,但是從磁碟吞吐效能上並沒有太大提升,僅僅提升1倍左右(100MB/S),由於硬體的變化帶來了軟體架構的變化。高效的壓縮演演算法與列式儲存也進一步減少I/O的壓力,巨量資料的瓶頸逐漸由I/O變成CPU。同時叢集規模越來越大,存算利用率不均衡,選型受限的問題越來越明顯。
為何要存算分離
隨著累積的資料量的增大,巨量資料業務量的增多,資料儲存和處理的成本越來越高,企業資料基礎設施的投資越來越大。同時,巨量資料處理元件多,不同元件使用不同的資料處理格式,比如大家熟悉的資料湖、資料倉儲使用的就是不同的格式,多樣化的資料格式導致資料儲存變得複雜,系統中應對不同的場景,往往同樣的資料需要儲存多份,不同元件之間還需要大量的資料拷貝和格式轉換,消耗大量的資源。經過十幾年巨量資料發展,隨著海量負載和巨量資料用例的出現,單一Hadoop叢集的規模變大,多個Hadoop叢集需同時支撐不同的業務。因此在儲存和計算耦合架構下,巨量資料叢集將面臨如下問題:
-
成本高:業務中對算力和儲存需求是不平衡的,增長速度也是不均衡的。擴容時同時要擴容計算和儲存,通常算力是有浪費的。
-
資源利用率低:由於多個Hadoop 叢集承接不同的工作負載,隨著支撐業務需求的波動,系統負載出現峰谷,然而存算一體的架構導致各叢集的資源完全獨立隔離不能共用(跨行業的存算一體架構下的Hadoop叢集平均資源利用率在25%以下)。高密度儲存型和算力增強型都難有用武之地;資料會傾斜,計算任務不一定能有效的排程到資料所在範例上。
-
運維困難:隨著業務複雜度的增加和新業務上線的速度加快,對伺服器資源配比的要求也會隨之增加,如果伺服器款型繁雜,維護難度就會增大,同時導致機房空間佔用多、能耗大。範例要考慮計算與儲存的均衡,機器選型受限。縮容較複雜,要對範例上的資料內容做遷移,這種情況無法做到彈性伸縮。
優勢

- 邏輯單元分開擴容:通過計算和儲存的分離部署實現計算和儲存的隔離,根據業務負載需求,對計算/儲存按需擴容。
- 巨量資料能力雲化:計算分離之後,可將其遷移到K8S或其他的雲上面,使得計算更輕量化。
- 多資料平臺整合:底層提供統一的儲存給到不同的巨量資料平臺,實現多個巨量資料平臺資料的整合,加速流程,逐步構建企業內部資料湖。
針對傳統hadoop架構中計算資源和儲存資源按某一比例強繫結,系統擴容必須按節點數目增加,導致記憶體或磁碟浪費的問題。「存算分離」不僅能節約成本,還可以讓資源根據業務需求彈性伸縮,按需分配,降低了系統部署和擴充套件成本,解決了資源利用不均衡的問題。
- 提升資源利用率:「存算一體」架構需要考慮CPU、記憶體、儲存容量/IOPS/頻寬,網路IO/頻寬,多達7個維度,任意一個維度的資源不滿足就會導致無法滿足應用訴求。而「存算分離」,按照計算和儲存兩個維度,將這7個維度拆分為兩個領域,降低選型複雜度。分別構建計算資源池和儲存資源池,提升資源利用率。擴容可實現計算和儲存的按需擴容,節約投資。
- 高可用:外接儲存陣列本身有非常好的可靠性設計,如RAID冗餘、靜默資料校驗、兩地三中心等可靠性保障,其可靠性等級高於伺服器至少兩個數量級,因此儲存應該是一個「長期」的共用儲存。伺服器的可靠性偏弱,「存算分離」後,即使伺服器故障,由於全域性共用一份資料,可實現免資料複製快速恢復業務,實現分散式資料庫整體的高可用。
- 高效能:採用「存算分離」架構後,由於全域性共用一份資料,一些不必要的消耗可以被避免,可提升資料庫整體的效能表現。例如半同步,每增加一個從節點都會導致10%的效能下降。採用「存算分離」後,不再需要半同步技術。外接儲存陣列對效能的優化更加深入,全快閃記憶體儲存,尤其是全NVME的儲存,可提供極致的效能體驗。儲存共用資源池不僅可提升資源利用率,還能利用不同應用不同時間對儲存效能峰谷要求不同的特點,將所有的IO分散到所有的磁碟,實現削峰填谷,達到最佳效能。
應用場景
儲存和計算分離目前主要應用在資料庫和訊息佇列兩個方向。
- 資料庫:以傳統主從架構資料庫系統為例,主庫接收資料變更,從庫讀取binlog,通過重放binlog以實現資料複製。在這種架構下,當主庫負載較大的時候,由於複製的是binlog,需要走完相關事務,所以主從複製就會變得很慢。當主庫資料量比較大的時候,增加從庫的速度也會變慢,同時資料庫備份也會變慢,擴容成本也隨之增加。因此企業也逐漸開始接受走計算和儲存分離的道路,讓所有的節點都共用一個儲存,其實這就是計算和儲存分離思想,現在很多的分散式NewSQL資料庫都向「計算和儲存分離」靠攏,包括PolarDB、OceanBase ,TiDB等等。
- 訊息佇列:目前主流的訊息佇列如Kafka、RocketMQ設計思想都是利用本地機器的磁碟來進行儲存訊息佇列,其實這樣是有一定的弊端的。首先本地空間的磁碟容量有限容易造成訊息堆積,導致需要追溯歷史資料時無法滿足,而只能擴容新節點,成本也比較高、運維難度較大。針對這些問題Apache Pulsar出現在人們的視野中,在Pulsar的架構中,資料計算和資料儲存是單獨的兩個結構。資料計算元件為Broker,其作用和Kafka的Broker類似,用於負載均衡,處理consumer和producer,如果業務上consumer和producer特別的多則可以單獨擴充套件這一層。資料儲存元件則為Bookie,Pulsar底層儲存使用的是成熟的Apache Bookkeeper儲存系統,因此其並沒有過多的關注底層儲存細節,可以將中心放在計算層的細節和邏輯。現在Kafka也在逐漸向這些方面靠攏,因此說「計算和儲存分離」應該是訊息佇列未來發展的主要方向。
存算分離產品
技術流派
儲存作為資料湖的底座,業界有兩個技術流派:一是基於分散式檔案,二是基於物件儲存。
- 基於分散式檔案儲存的巨量資料方案:原生 HDFS 巨量資料方案:主要適用於業務適合檔案儲存,對 Hadoop 元件相容要求高,和巨量資料計算層無縫對接,計算層程式零改造的巨量資料場景。
- 基於物件儲存的巨量資料方案:適用於業務適合物件儲存,需要在物件儲存上提供巨量資料分析能力,且可以無縫上下雲,做雲端分析或雲端資料重建。
華為
華為OceanData
- 問題:存算一體架構在故障恢復和搬遷時都要全量恢復資料,不僅降低了可靠性,也增加了運維工作量和成本,同時遷移擴容時間不可控,需要更多資源冗餘來彌補?
- 解決:華為OceanData分散式資料庫存算解決方案,在基於存算分離架構上,利用容器的技術把整個資料庫的一層做成無狀態,真正的資料通過持久化卷的方式存到儲存,磁碟故障有儲存保障,伺服器故障的時候,通過容器K8S的自動編排的技術,快速恢復資料。幾個小時的資料重構時間,縮短至分鐘級,大大提升系統效率和可靠性。
- 問題:一個幾百G資料庫down掉之後,花了3個小時和5個相關的工程師去解決,因為還有很多的操作要手工去做沒法完全形成自動化。雲原生裡有個「不可變基礎設施」的概念,無狀態解耦之後,資料都落在瞭解耦的儲存上,計算部分就可以任意的去漂移。交易型的資料庫它的資料規模雖然相對來說不是很大但要求效能和容量都具備一定的擴充套件性?
- 解決:華為OceanData方案採用了一種雲原生的架構,通過容器和企業級儲存的結合,可以做到整個計算側是無狀態的,資料庫部署在容器裡面,當資料庫算力不夠的時候,實現了算力的橫向擴充套件;磁碟不夠了,只需要把儲存資源擴充套件。
- 問題:只有可靠性、擴充套件性的問題解決後,才能夠放手去提升資源利用率。經過估算如果可靠性問題能解決那麼計算的利用率能夠從10%提升到30%左右,成本將近節省一半,尤其是在機房和耗電能夠降低大概60~70%;那為什麼之前大家沒有去做存算分離這個事情?
- 解決:很多企業也嘗試過用這種存算分離的架構,整個效能出現斷崖式的下跌,網路是很關鍵的一環。但是隨著網路技術的發展,隨著RoCE網路逐漸的成熟,可以通過無失真乙太網,NVMe協定,遠端直接存取儲存記憶體的資料,縮短整個lO路徑。在客戶場景實測發現,用NoF網路相比於FC網路,效能提升20%~30%,跟伺服器的本地盤效能持平。給客戶帶來直觀感覺就是效能沒下降,但是可靠性提升了很多。
- 問題:當我把大量資料集中到儲存上之後,如果儲存的可靠性和儲存效能達不到要求,將會成為整個系統的瓶頸?
- 解決:是的,為什麼強調是端到端支援 NVMe over Fabric,因為網路雖然用了高速無失真乙太網RoCE網路,但只是解決了通道的問題,如果前端還是用傳統SAS介面,無法解決問題。因此,儲存也要端到端支援NVMe ,以及提升儲存可靠性的亞健康主動檢測,磨損均衡和反磨損均衡等。通過磨損均衡和反磨損均衡防止盤批次故障,同時換盤的動作都是主動告知,主動監測。
- 問題:業界這些廠家在做存算分離的時候,也是要利用儲存的一些能力來去解決問題,不管是亞健康還是磨損均衡,因為本地盤上沒有亞健康檢測,也沒有磨損均衡能力,有些客戶為保證效能,用NVMe的SSD卡,但是NVMe的SSD卡,很難在伺服器上做RAID的,還有儲存層的效能隔離也很難在伺服器上實現。
- 解決:專業的人幹專業的事。整個IT架構中也一樣,磁碟資料的管理放在儲存上去做,無論從效率還是可靠性肯定是更好的。除了剛才講的IO效能、磁碟的監測外,儲存還可以做很多事情,企業級的儲存支援快照備份,容災的能力,有些開源的工具做整個資料庫的備份恢復1TB的資料需要幾個小時,效率很低。而藉助儲存的快照技術,可以大大提升效率。
資料是一個端到端的系統架構的方案,不光要考慮資料庫軟體自身,還要考慮整個叢集管理,包括一些周邊的備份容災,以及整個基礎設施的選擇。所以華為構築OceanData這樣的一個解決方案出來,把整個資料庫端到端的堆疊打通,去減少拼裝這些方案的時候遇到的這些問題。更多的是把心思放在業務上,而不是放在怎麼去搭建出一套完整的資料庫方案出來。
華為OceanStor Pacific作為國內巨量資料下一代存算分離的解決方案先行者之一,在儲存層實現了原生HDFS語意介面的存算分離方案,打破了傳統巨量資料平臺計算儲存的部署架構。同時率先在儲存上支援湖倉融合的新興資料格式,在下一代存算分離架構下,基於一份資料支援接資料湖、資料倉儲同時存取。提供以業務為中心的高彈性巨量資料計算,以資料為中心的高效能海量儲存,使用者無感知的原生HDFS和S3相容能力。OceanStor Pacific不僅算力密度在業界領先30%,而且做到一站式交付、一鍵式部署,可以有效匹配企業巨量資料快速迭代發展。
JuiceFS
JuiceFS 是一款開源分散式檔案系統,創新地將物件儲存作為底層儲存媒介,實現了儲存空間的無限擴充套件。任何存入 JuiceFS 的檔案都會按照特定規則被拆分成固定大小的資料塊儲存在物件儲存,資料塊的後設資料則儲存在 Redis、MySQL、TiKV 等資料庫中。同時 JuiceFS 的 Hadoop Java SDK 完全相容 HDFS API,提供完整的檔案系統特性,巨量資料元件可以無縫從 HDFS 遷移到 JuiceFS。
存算分離最初嘗試:
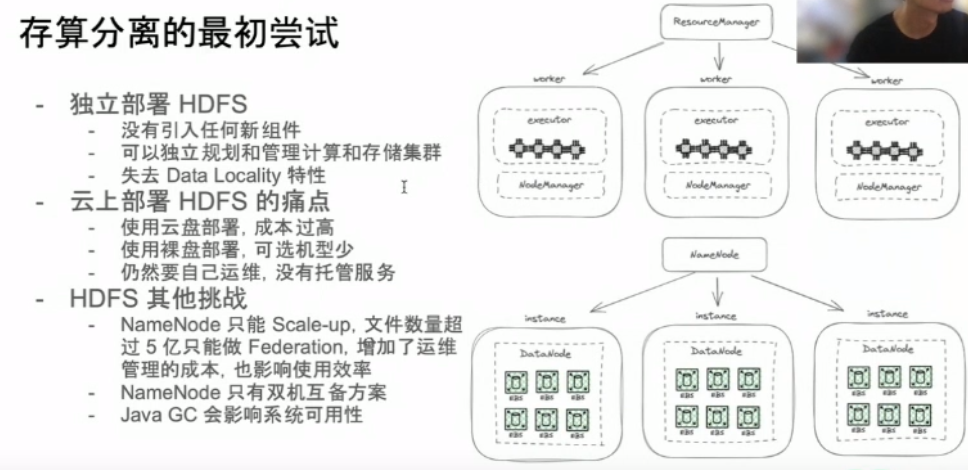
使用物件儲存替代HDFS
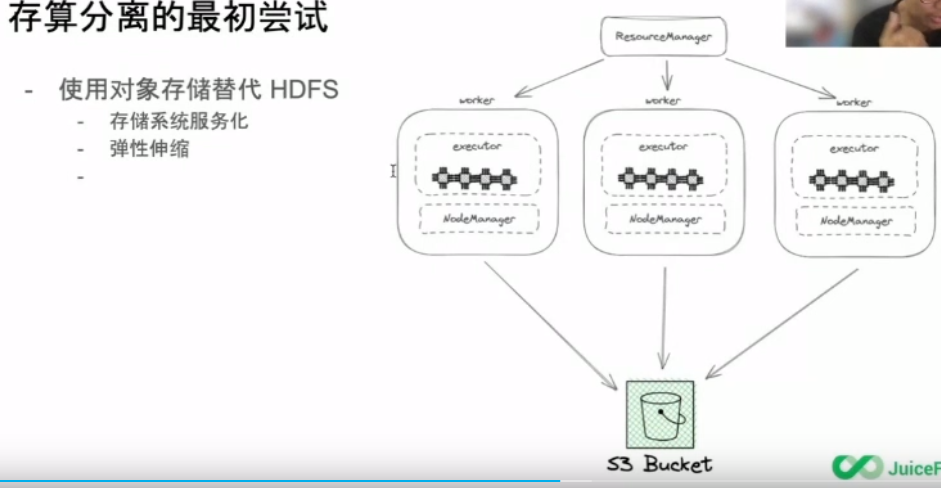
使用物件儲存替代HDFS的優勢和痛點分別如下:
-
優勢
- 儲存系統服務化
- 彈性伸縮
-
痛點
- 儲存系統API改變,相容性也改變,需要在不同元件、不同版本上逐一驗證相容性。
- 很多物件儲存是最終一致性模型,會影響計算過程穩定性和正確性。
- Listing效能弱。
- 沒有原子的rename,影響任務的穩定性和效能。
JuiceFS巨量資料存算分離方案

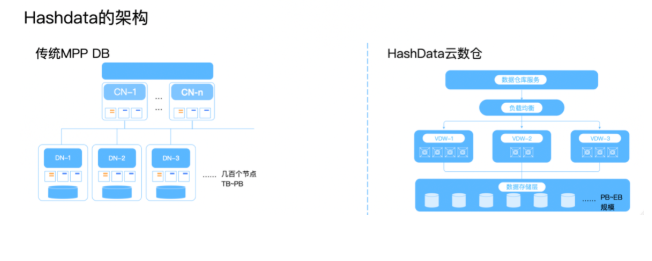
HashData
HashData為了追求極致的彈性和擴充套件性,計算叢集和持久化儲存嚴格實行物理分離:計算叢集由類似AWS EC2的虛擬機器器組成,持久化儲存則使用物件儲存。
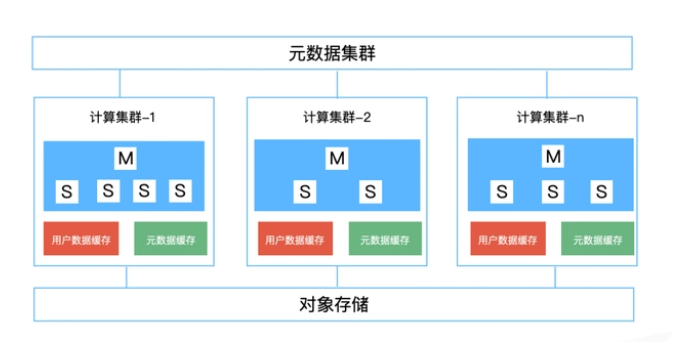
HashData利用雲端儲存作為資料持久儲存層,並與計算資源物理上分離、邏輯上整合。由於自身的高可用性和近乎無限的可延伸性,雲端儲存大大簡化了資料倉儲系統錯誤恢復、多維度擴縮容、備份恢復等流程,同時使得不同叢集間共用同一份資料、統一的資料儲存平臺成為可能。
-
相比在地化儲存,遠端存取是否會帶來效能上的下降?
- HashData通過在計算節點和物件儲存中間增加快取層,可以大幅降低存取物件儲存的頻率,緩解效能下降的問題。
- 傳統的MPP架構資料庫儲存、計算緊耦合,資料儲存在本地系統,儲存能力的擴充套件通過增加叢集節點實現,這樣就會導致計算資源的浪費,無法匹配業務的發展。
- HashData使用的是物件儲存,獨立於計算節點。利用物件儲存技術,可以提供近乎無限的擴充套件能力,避免了傳統資料平臺基於成本考慮的歸檔需求和計算成本浪費。
- 通過測試可以看到,HashData在計算節點和物件儲存之間增加快取層之後,相比MPP架構,幾乎沒有效能上的損耗,同時計算量可以提升近5倍。
-
快取層設計理念是在後設資料叢集和物件儲存叢集之間,適度增加計算資源和快取層,具體是怎麼實現的?
- HashData的快取策略採用目前比較流行的LRU演演算法,來實現熱點資料的識別和保留。LRU本質上是一個固定大小的佇列,對於需要頻繁存取的資料,會放到佇列前面;對於不經常存取的資料,會放在後面。
- 隨著佇列慢慢的增加,最終經常存取的資料會在最前面,不經常存取的資料會在最後面。
- 最終,不經常存取的資料會被剔除掉。同時,對於快取層遮蔽掉了所有遠端檔案操作。資料庫核心在存取物件儲存的時候,對遠端操作不會有任何感知。
-
快取的優化物件包括哪些?
- HashData針對高並行、小檔案等場景做了大量的優化,進一步降低系統開銷,使遠端存取的效能可以達到跟本地幾乎完全一樣。
- 針對物件儲存,HashData通過批次處理的方式對資料的查改刪進行優化,大幅提升了操作效率。
- 另外,HashData對資料的寫和讀做了很多的優化。比如企業業務場景上使用大檔案比較多,那麼我們採用分片上傳方式將大檔案傳輸到物件儲存上。對於每個上傳的檔案,HashData經過測試設定了一個最優的分片大小去做分片上傳,將檔案在物件儲存上合併。
- HashData的快取系統採用按塊快取,做到了按需下載需要的資料,避免下載整個檔案。比如使用快取系統去讀取資料,將每個塊設定8M,對於64M的檔案會被切分為8個塊,如果使用者需要的資料分佈在其中的一個塊內,那麼我們資料庫在讀取資料時只需要取其中一個塊即可,不需要把整個資料全都下載下來,這樣做到了按需下載。
-
通過網路獲取到資料是否會導致網路IO的壓力過大?
- 網路IO壓力大有兩方面。一方面是物件儲存壓力過大。另一方面是叢集本身隨著主機和業務增多會更多地去存取物件儲存,由此會帶來叢集整體和存取物件儲存的網路開銷越來越大。
- 對於物件儲存壓力過大我們通過多bucket方式來解決。將檔案分散儲存到其他的bucket上以此來分流物件儲存上的壓力。
- 對於叢集因為業務增多出現網路壓力過大,我們採用動態演演算法讓系統根據當前的壓力調整傳送請求的間隔。再者可以通過調整引數降低叢集傳送網路請求次數。
-
儲存層結構是底層採用物件儲存,上層對資源進行分片,保障全資料型別的支援、拓展能力、高可用和高持久,能否舉例詳細說明?
- 首先,因為我們通過快取層,構建了統一的儲存層,儲存層可以保證所有的計算叢集去存取快取檔案,從一定程度上解決了資源孤島的問題。
- 此外,對於大量叢集存取,HashData會根據計算叢集的規模進行分片儲存,其他節點可以也同時存取這些檔案,互相不會影響。
- 在底層的儲存方面,HashData採用物件儲存,支援多叢集同時存取一個檔案,整個架構能適配更多的雲。
- 同時,對於物件儲存,HashData做了大量的優化,包括對儲存資料的格式、多執行緒、動態調整封包大小等,這些優化都可以對存取儲存層帶來更高的效能。
-
物件儲存相比於HDFS有什麼優勢?
- HDFS預設採用三副本,整體成本更高。物件可以採用糾刪方法,可以實現更高的利用率。HDFS適合儲存大檔案,更適合Hadoop的非結構化場景。數倉中小檔案的場景很多,不適合HDFS。數倉通常將HDFS作為資料匯入的入口,而不是儲存的底座。
XSKY
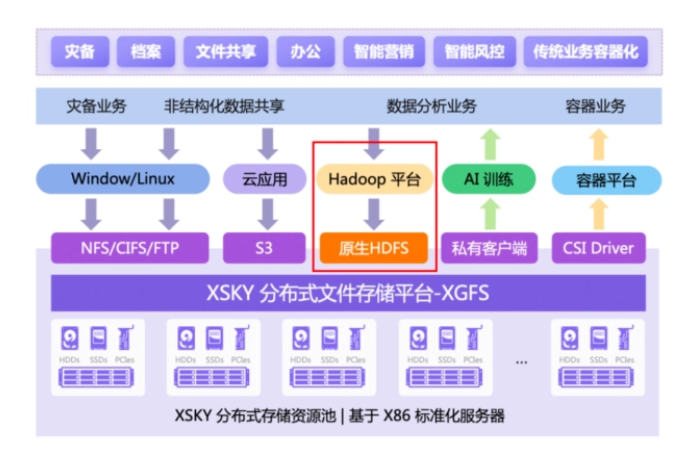
XSKY 基於分散式檔案的巨量資料方案
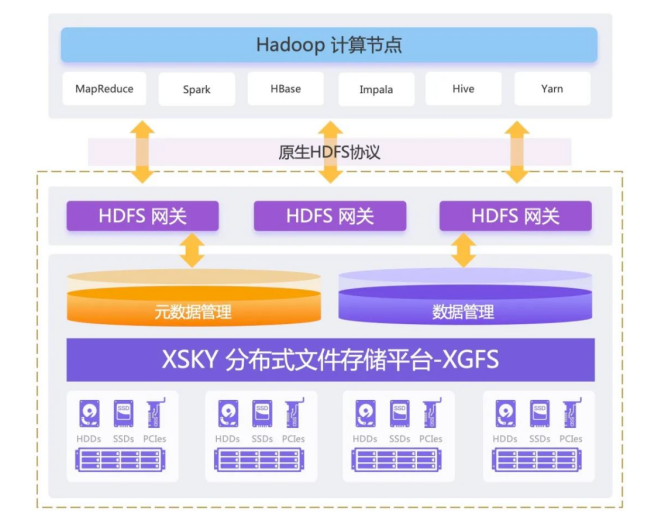
- 協定相容性--原生 HDFS 協定:
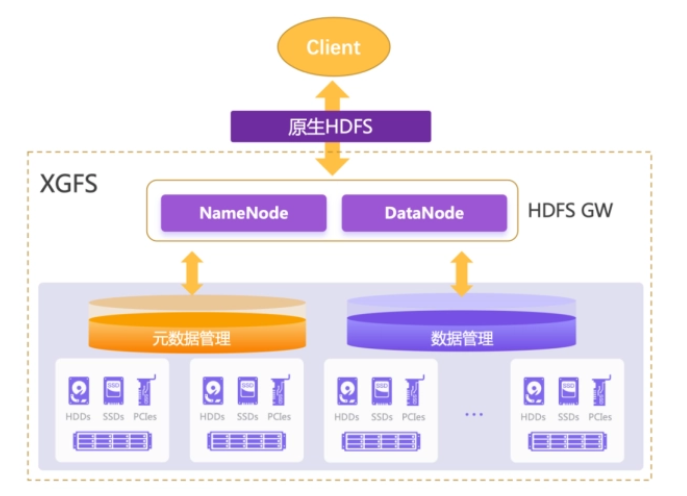
- 使用者和使用者組許可權相容性
- 多協定融合互通:支援 NFS、SMB/CIFS、POSIX、FTP、HDFS、S3、CSI
- EC 糾刪碼:實現冗餘和容錯的目的。
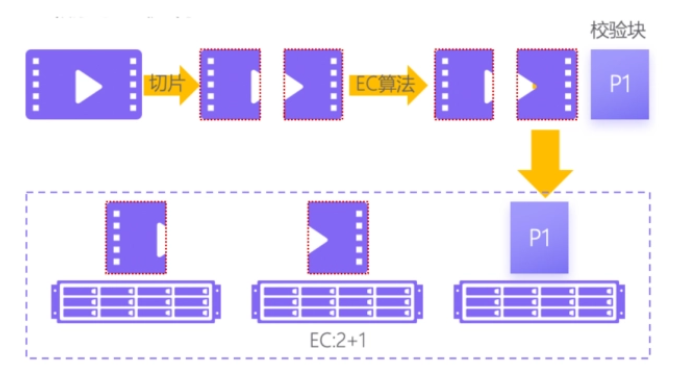
- 擴充套件性

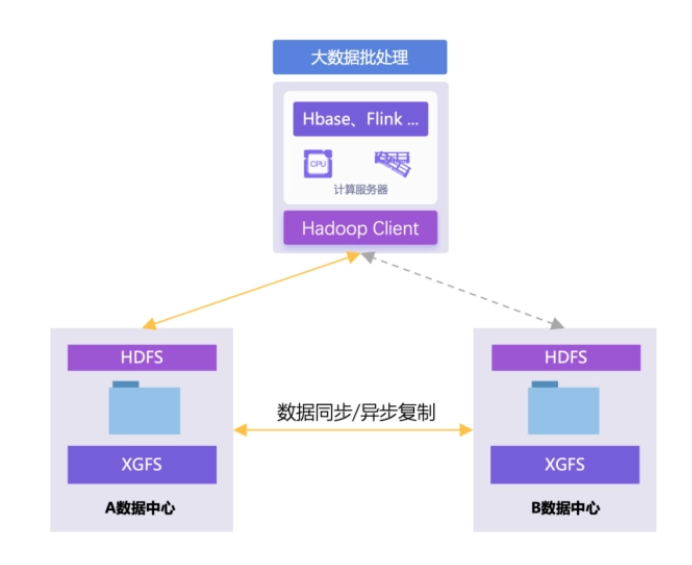
- 資料災備:同步複製和非同步複製
**本人部落格網站 **IT小神 www.itxiaoshen.com