CVPR2022 Oral OGM-GE閱讀筆記
標題:Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR 2022 Oral)
論文:https://arxiv.org/abs/2203.15332
領域:多模態學習
解決本質問題
在某些多模態模型的訓練過程中,效能更好的模態(主導模態)會對其他模態的優化產生抑制作用,因此導致的模態間訓練的不平衡現象,單一模態存在欠優化。
方法
文章主要從不同模態的梯度傳播上入手,根據模態間的效果差異自適應地調變梯度,並結合高斯噪聲的泛化性增強能力,提出了具有較強適用性的OGM-GE優化方法。
優點
- 隨插即用,很通用直觀的工作
- 實驗詳實,各項實驗指標表明該方法的靈活有效性,應用在不同的encoder、fusion method以及優化器中都有一定提升,並且相比其他調節策略提升優勢顯著
缺點
- 模態間的融合方式不僅只有論文中所詳細闡述的concat方式,融合的階段也不一定要在各自模態的encoder提完特徵後,在某些任務中,不同模態的地位是不相同的,分清主次模態也是一個方法,因此本文的做法有一定侷限性。
- 本文動態調節梯度中的動態係數\(k_t\)的設定方法是比較handmade的,模態差異率\(\rho_t^u\)的定義符合intuition但也缺乏一定的數學解釋證明,僅僅只是實驗表明比較work。
- 為了彌補因為動態減少強勢模態梯度所造成的泛化性減小問題而再引入高斯噪聲(GN)的方式感覺不夠elegant,既然這樣為啥不直接增強弱勢模態梯度,加強隨機梯度噪聲,甚至不需要新增GN?
進一步思考
如果是我,我該如何解決這個問題?這也是我一直以來在試著培養的科研思維,當然,idea is cheap,以下思路都尚待實驗證明~
method1:gradient decent
如上述缺點中提到的,既然可以減少強勢模態梯度,同時增加GN,相反的,也可以嘗試增強弱勢模態梯度,加強隨機梯度噪聲,甚至不需要新增GN。
method2:multi task learning
為啥會想到這個,因為我覺得思想差不多!只不過多模態是multiple in,而多工是multiple out。
首先多工學習可以通過不同子任務的互相約束,可以使網路減少歸納偏置、幫助收斂、提取共性特徵來取得更好的效能,但是loss權重人為設定相當困難,為什麼不讓網路自己學習?
一種可行的方式
參考論文:Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics (CVPR 2018)

本文通過建立貝葉斯模型,基於同方差不確定性建立了多工的聯合loss如下

對於更多工的模型,根據任務型別也很容易拓展,網路將自動學習權重~
本任務中的應用流程

通過多工加強整體任務效能,相對應的提升弱勢模態優化效果。
method3:knowledge distill
由於強弱模態之間,存在學習和優化上的差異,可以類比老師和學生,一個學的好,一個學的不好,因此考慮知識蒸餾~
KD整體架構如下:
參考論文:Distilling the Knowledge in a Neural Network

一種可行的方式
參考論文:There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge (CVPR 2021)
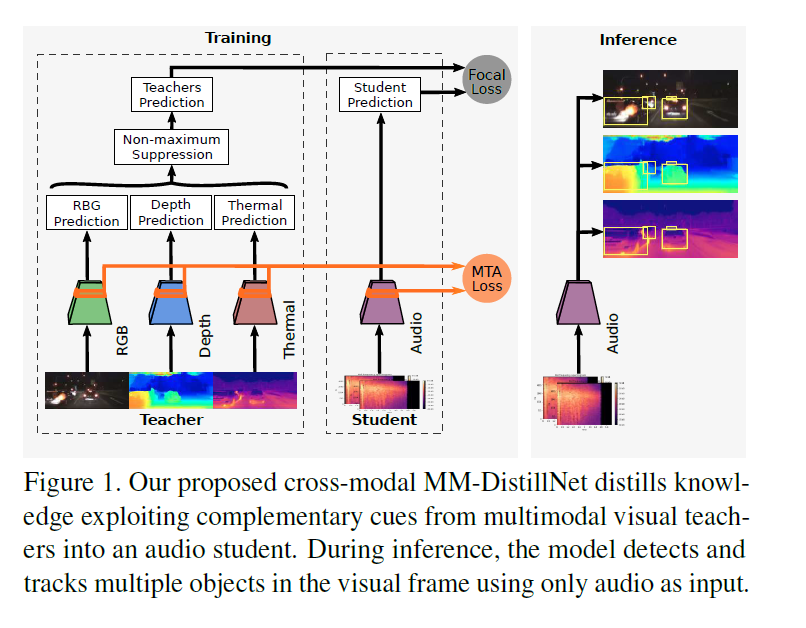
讓teacher net(含有RGB、Depth、Themal多個模態)訓練student net(Audio)然後讓student net單獨實現定位,MTA損失來對齊學生的中間表示與教師的中間表示。
本任務中的應用流程
- gt教強模態train一個teacher net
- 強模態教弱模態, 使用強模態的輸出概率值而不是onehot向量對弱模態進行訓練,train student net
- 一般知識蒸餾的做法是單獨用student去預測的,但這裡可以進行模態fusion實現共同預測。
解決的問題本質都是模態不均衡,但思路不同,這個方法側重於使弱模態從本質上變強。
該方法可能存在的問題:模態差異性太大,無法對齊導致效果不好。。。
method4:self-supervised learning
原先的動態係數\(k_t\)只對encoder部分進行動態調節,來使得弱勢模態優化得到提升,這種方法是有點後天培養的意思,那麼為啥不能直接就讓encoder先天就比較厲害呢?這樣我不怎麼需要優化就perform well了~於是就想到了利用自監督,自監督是目前比較火的方向,通過在上游任務中先進行預訓練然後應用到下游任務中往往效果比較好。
一種可行的方式
參考論文::Unsupervised learning of visual representations by solving jigsaw puzzles(ECCV 2016)

為了恢復原始的小塊,Noroozi等人提出了一個稱為上下文無關網路(CFN)的神經網路,如下圖所示。在這裡,各個小塊通過相同的共用權值的siamese折積層傳遞。然後,將這些特徵組合在一個全連線的層中。在輸出中,模型必須預測在64個可能的排列類別中使用了哪個排列,如果我們知道排列的方式,我們就能解決這個難題。
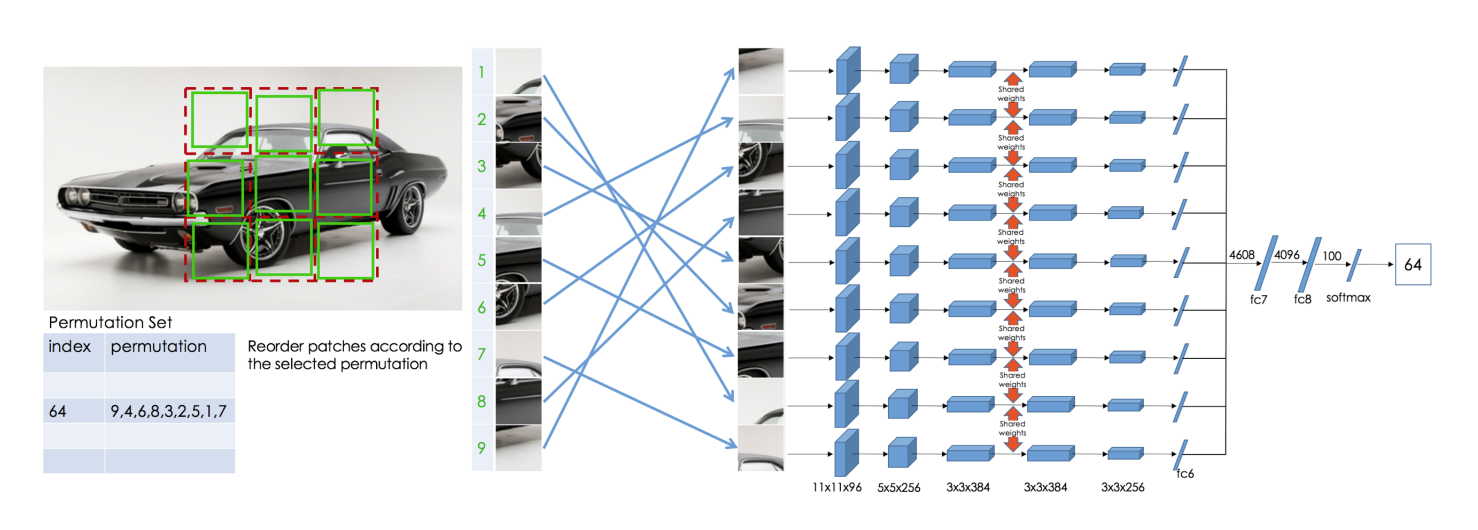
為了解決拼圖問題,模型需要學習識別零件是如何在一個物體中組裝的,物體不同部分的相對位置和物體的形狀。因此,這些表示對於下游的分類和檢測任務是有用的。
本任務中的應用流程
- 自監督預訓練好各自模態的encoderA和encoderB
- 按OGM-GE實驗進行的架構進行Fine-tune
method5:bilnearl pooling
OGM-GE架構中存在的另一個問題是concat的方式模態之間融合還不夠充分,哪怕實驗中所展示的其他fusion方式也是比較的簡單的,算是一階融合,這樣就導致互相之間不同模態特徵之間融合太少,學習不夠充分,也可能間接導致弱勢模態學的不夠好,因此可以改變融合策略考慮用二階融合,比如二階雙線性池化
由於二階雙線性池化存在維度過高,計算量過大的問題,後續的很多work都對它進行降維處理,比較的典型的就是表徵能力較強的MFB方法,由於本人對於vqa領域瞭解不深,故不在此展開。
