追求效能極致:使用者端快取帶來的革命
Redis系列1:深刻理解高效能Redis的本質
Redis系列2:資料持久化提高可用性
Redis系列3:高可用之主從架構
Redis系列4:高可用之Sentinel(哨兵模式)
Redis系列5:深入分析Cluster 叢集模式
追求效能極致:Redis6.0的多執行緒模型
背景
前面一篇我們說到,2020年5月份,Redis官方推出了令人矚目的 Redis 6.0,提出很多新特性,包括了使用者端快取 (Client side caching)、ACL、Threaded I/O 和 Redis Cluster Proxy 等諸多新特性。如下:
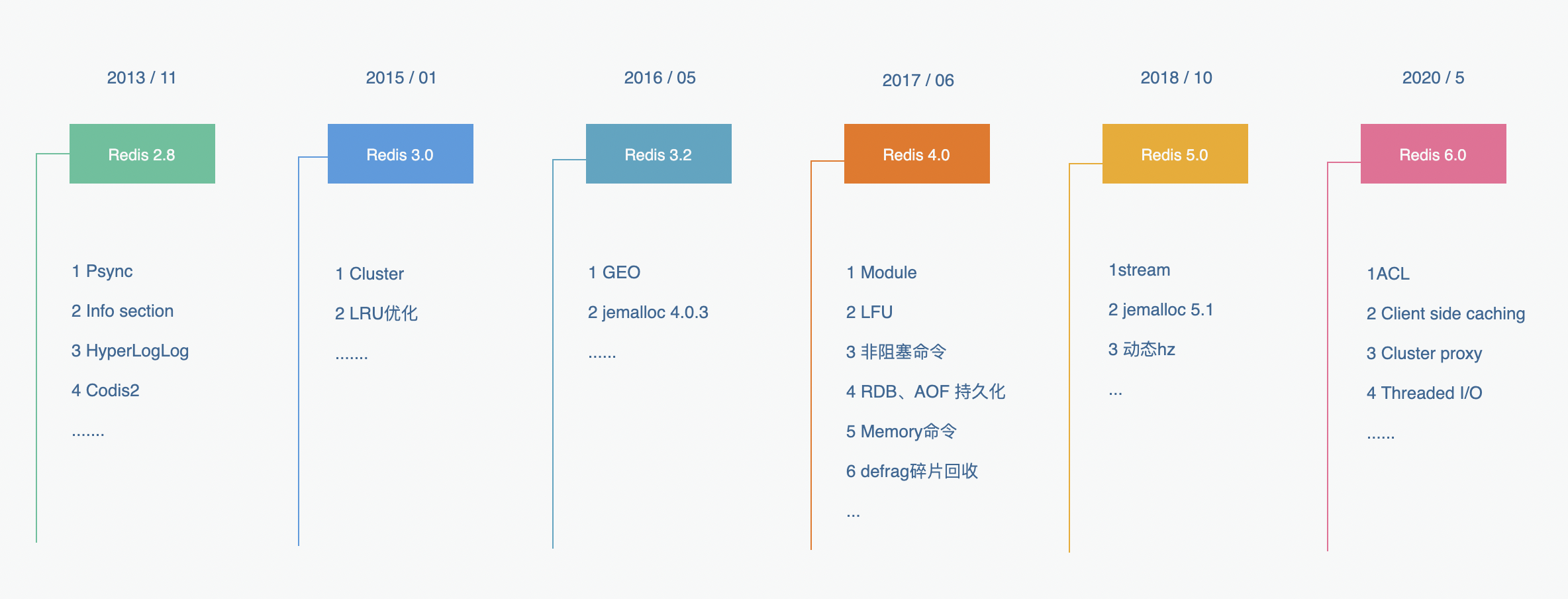
我們也專門對 Redis 6.0的 Threaded I/O(多執行緒網路I/O 模式)做了很詳細的說明,有興趣的翻到前面一篇。
這一篇咱們就來聊下這個Client side caching(使用者端快取),看看Redis為什麼需要使用者端快取、是基於什麼原理實現的,以及具體應該怎麼使用。
1 為什麼需要使用者端快取
1.1 快取服務的目的
回顧一下我們 在第一篇 《深刻理解高效能Redis的本質》中說過的,Redis的讀寫操作都是在記憶體中實現了,相對其他的持久化儲存(如MySQL、File等,資料持久化在磁碟上),效能會高很多。因為我們在運算元據的時候,需要通過 IO 操作先將資料讀取到記憶體裡,增加工作成本。

上面那張圖來源於網路,可以看看他的金字塔模型,越往上執行效率越高,價格也就越貴。下面給出每一層的執行耗時對比:
- 暫存器:0.3 ns
- L1快取記憶體:0.9 ns
- L2快取記憶體:2.8 ns
- L3快取記憶體:12.9 ns
- 主記憶體:120 ns
- 本地二級儲存(SSD):50~150 us
- 遠端二級儲存:30 ms
我們舉個L1和SSD的直觀對比,如果L1耗時1s的話,SSD中差不多要15~45小時,所以記憶體層面的存取效率遠遠比磁碟層面的存取效率高很多。
總之,快取的目的是基於對持久化在磁碟的資料(比如MySQL資料、檔案資料等)的高效存取,為了提升效率而實現的。《Redis in Action》中也提到, Redis 能夠提升普通關係型資料庫的 10 ~ 100 倍的效能。
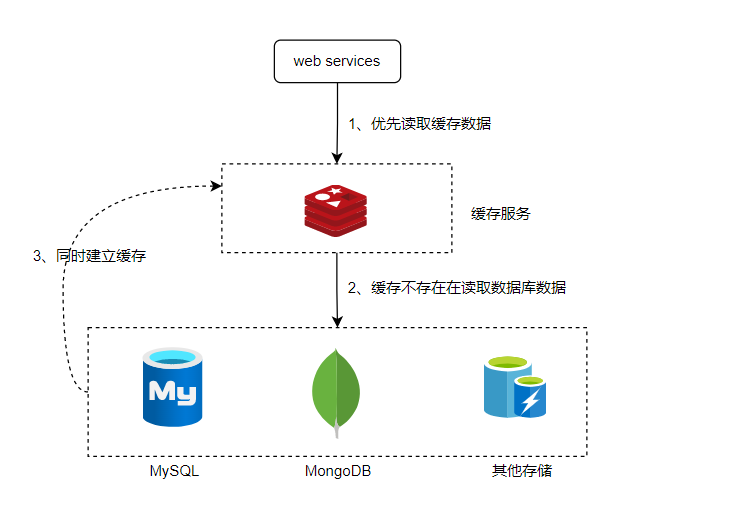
資料存取過程如下圖,Redis 儲存了熱點資料,當天我們請求一個資料時,先去存取快取層,如果不存在再去存取資料庫,這樣可以解決大部分高效讀取資料的業務場景,效能是快取最重要的價值之一。
1.2 存在的問題
雖然我們使用Redis提升了資料的存取效率,但是依然存在一些問題。基於分散式存取的快取服務是一個獨立的服務存在,一般情況下存取它需要經過這幾個步驟:
- 連線快取服務(一般不會跟計算服務在一個範例上)
- 查詢並讀取資料(I/O操作)
- 網路傳輸
- 資料序列化反序列化
這些操作一樣的是對效能有影響的,隨著網際網路的發展,流量不斷的膨脹,很容易達到 Redis 的效能上限。
所以,我們經常會使用程序快取(本地快取),來輔助處理,將一些高頻讀低頻寫的資料暫存在本地,讀取資料的時候,先檢查本地快取是否存在,不存在再存取遠端快取服務的資料,進一步提高存取效率。
如果Redis也不存在,就只能去 資料庫 中查詢,查到的資料再設定到 Redis 和 本地快取中,這樣後續的請求就不用再走到資料庫中了。

一般我們會使用Memcachced、Guava Cache 等來做第一級別快取(本地快取),使用Redis作為第二級快取(快取服務),本地記憶體避免了 連線、查詢、網路傳輸、序列化等操作,效能比快取服務快很多,這種模式大大減少資料延遲。
2 使用者端快取實現原理
Redis自己實現了一個使用者端快取,用以協助伺服器端Redis的操作,叫做tracking。
我們可以通過命令來設定它:
CLIENT TRACKING ON|OFF [REDIRECT client-id] [PREFIX prefix] [BCAST] [OPTIN] [OPTOUT] [NOLOOP]
使用者端快取最核心的問題就是當Redis中的快取變更或者失效了之後,如果能夠及時有效的通知到使用者端快取,來保證資料的一致性。
Redis 6.0 實現 Tracking 功能,這個功能提供了兩種方案來實現資料的一致性保證:
- RESP2 協定版本的轉發模式
- RESP3 協定版本的普通模式和廣播模式
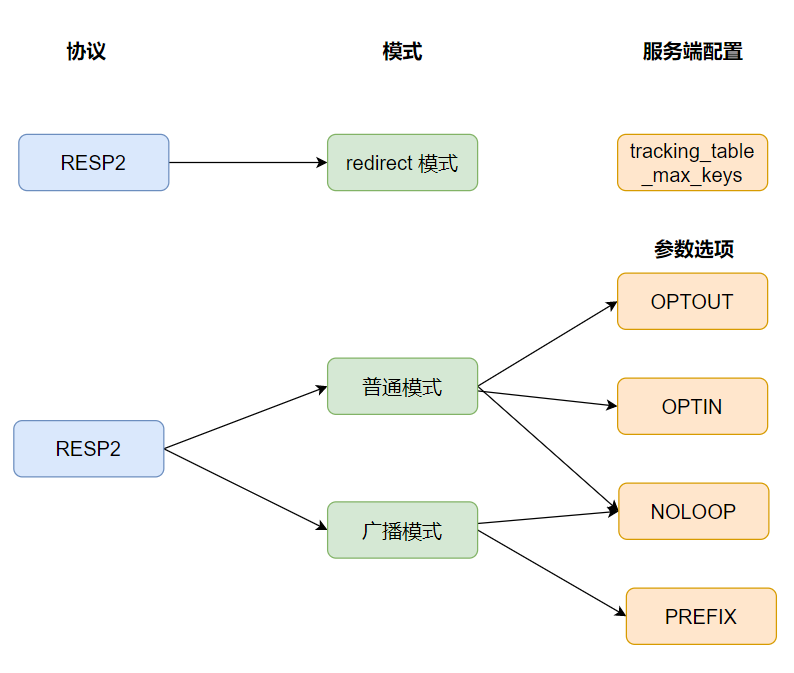
接下來我們一個個來分析。
2.1 普通模式
Redis使用 TrackingTable 來儲存普通模式的使用者端資料,它的資料型別是基數樹 ( radix tree)。
radix tree是針對稀疏的長整型資料查詢的多叉搜尋樹,能快速且節省空間的完對映,想深入瞭解的可以看這篇介紹。
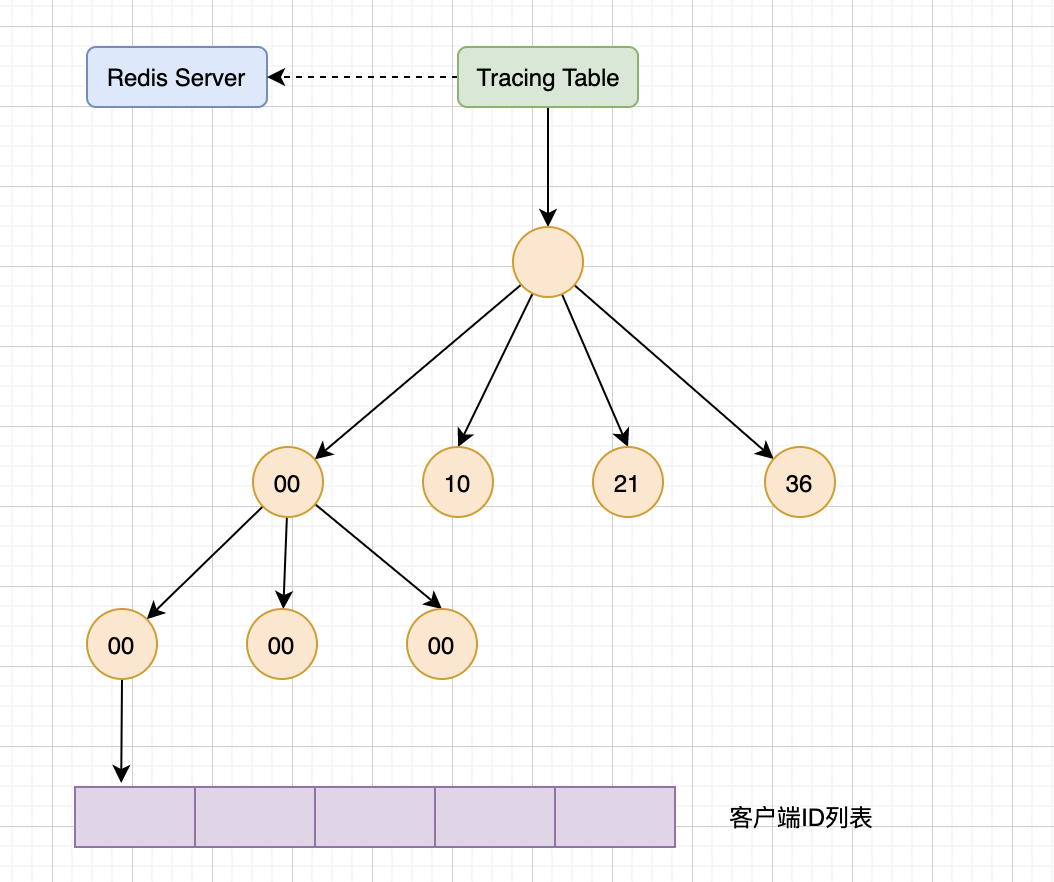
如圖中,使用者端ID列表與Redis儲存鍵的指標具有對映關係。而Redis鍵物件的指標對應的就是記憶體地址,資料結構是Long。
當開啟了track 功能之後,操作具有以下特性:
- 當Redis獲取一個鍵值資訊時,radix tree 會呼叫 enableTracking 方法記錄 key 和 clientId 的對映關係,記錄到 TrackingTable 中。
- 當Redis刪除或者修改一個鍵值資訊時
- radix tree 根據key呼叫 trackingInvalidateKey 方法查詢對應的 Clinet ID
- 呼叫 sendTrackingMessage 方法把失效的鍵值資訊(invalidate 訊息) 傳送給這些 Clinet ID。
- 傳送完成之後從TrackingTable中刪除對映關係。
- Client關閉 track 功能後,遇到大量刪除操的時候,一般是懶刪除,只將 CLIENT_TRACKING 標誌位刪除。
- 預設 track 模式是不開啟,需要通過命令開啟,參考如下:
CLIENT TRACKING ON|OFF
+OK
GET test
$7
archite
2.2 廣播模式(BCAST)

廣播模式與普通模式類似,也是採用對映關係來對照,但實現過程還是有區別的:
- 儲存的內容不一樣:如圖,採用Prefix Table 來儲存使用者端資料,儲存的是 字首字串指標 和 使用者端資料(使用者端ID列表 + 需通知的key值列表) 的對映關係。
- 刪除鍵值的時機不一樣:
- radix tree 根據key呼叫 trackingInvalidateKey 方法查詢PrefixTable。
- 判斷是否為空,不為空則 呼叫 trackingRememberKeyToBroadcast 對鍵列表進行進行遍歷,找到符合字首匹配規則的,並記錄位置。
- 在事件處理周期函數 beforeSleep 中 呼叫 trackingBroadcastInvalidationMessages 函數來傳送訊息。
- 傳送完成之後從 PrefixTable 中刪除對映關係。
2.3 轉發模式
RESP 3 協定 是 Redis 6.0 新啟用的協定,使用普通模式或者廣播模式需要依賴這種協定,這樣對於RESP 2 協定的使用者端來說就會有問題。所以衍生除了另一種模式:重定向(redirect)。
- RESP 2 無法直接 PUSH 失效訊息,所以不能直接獲取到失效資料(Redis Client 2)。
- 支援 RESP 3 協定的使用者端(Redis Clinet 1) 告訴 Server 將失效訊息通過 Pus/Sub 通知給 RESP 2 使用者端。
- 而Redis Client 2 (RESP 2 )是通過訂閱命令 SUBSCRIBE,專門訂閱用於傳送失效訊息的頻道 redis:invalidate。
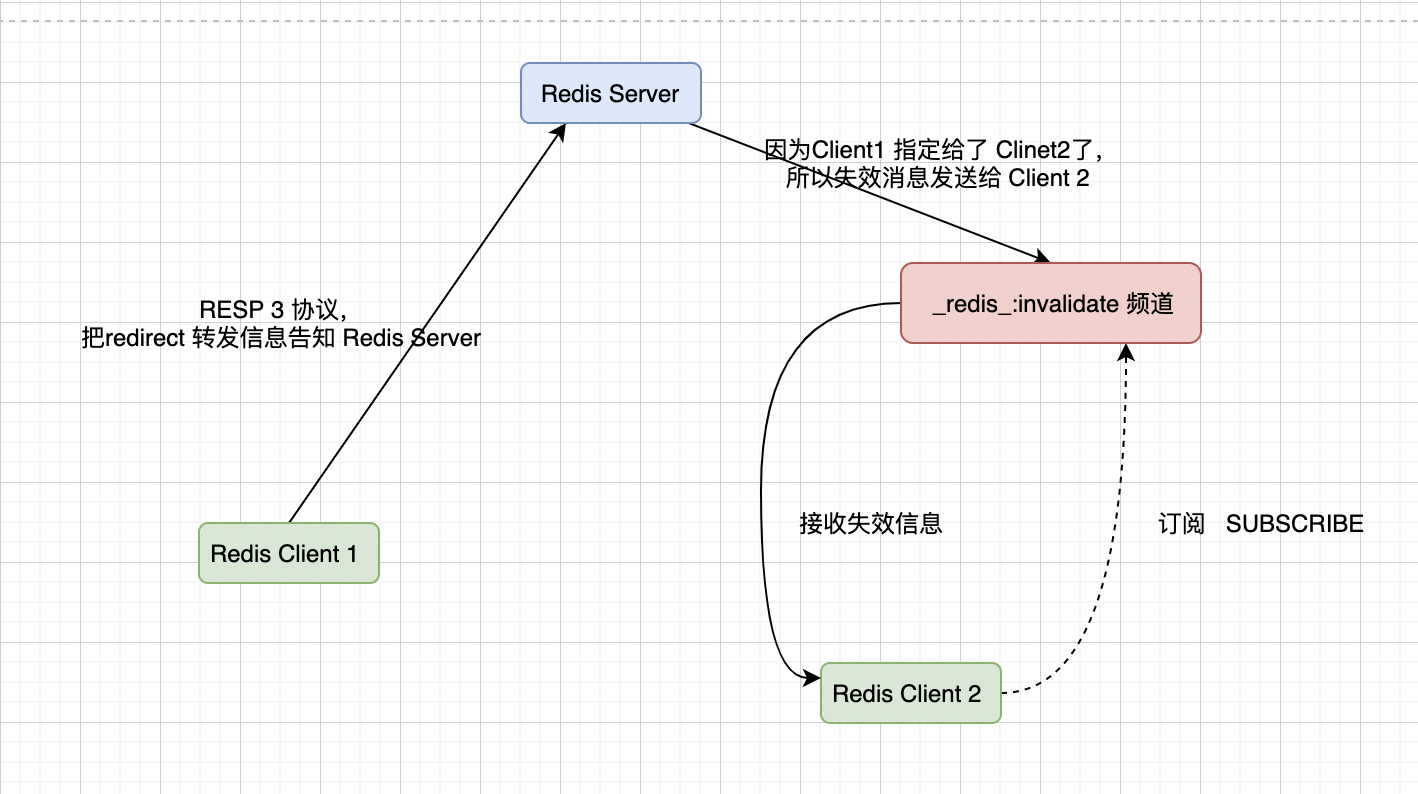
如下所示:
# Redis Client 2 (支援RESP 2)執行訂閱
client id : 888
subscribe _redis_:invalidate
# Redis Client 1(支援RESP 3),轉發給 2
client tracking on bcast redirect 888
3 總結
3.1 預設模式(普通模式)
- 伺服器端記錄使用者端操作過的 key,key 對應的值發生變化時,會傳送 Invalidation Messages 給Redis 使用者端。
- 伺服器端記錄key資訊會消耗一些記憶體,但是傳送失效訊息的範圍,限制在儲存的key範圍內,計算和網路傳輸變的輕量。
- 優點是節省 CPU 以及流量頻寬,但是會佔用一些記憶體。
3.2 廣播模式
- 伺服器端不記錄 key,而是訂閱 key 的特定字首,當匹配字首的 key 的值改變時,傳送 Invalidation Messages 給 Redis使用者端。
- 優點是伺服器端的記憶體消耗少,但是會損耗更多的 CPU 去做字首匹配的計算。
3.3 轉發模式
- 為了相容 resp2 協定的一種過渡模式
- 優點是佔用記憶體少,CPU佔用多
使用者端的快取
使用者端快取,需要業務側自己實現,Redis 伺服器端只負責通知你key 的變動(刪除、新增)。
