[Raft共識演演算法] Dragonboat Log Replication 程式碼走讀
Dragonboat Log Replication 程式碼走讀
Dragonboat 是一個開源的高效能Go實現的Raft共識協定實現. 具有良好的效能和久經社群檢驗的魯棒性, 機遇巧合, 接觸到. 因此決定結合Raft博士論文走讀其原始碼. 今天帶來Raft中三大核心之一的紀錄檔複製Log Replication的程式碼走讀.
Dragonboat Log Replication程式碼實現結構

Dragonboat中的網路介面呼叫主要在node.go檔案中實現, 作者提供了對網路介面的抽象, 可以自由實現底層的網路互動方法. 本次討論僅涉及對這些網路介面的代用邏輯, 也就是工作流的講解, 不涉及網路協定底層實現的邏輯討論. 作者在protobuf中定義了msg.Tpye, 並通過路由函數將不同Type的msg路由到不同的Handler函數進行處理.
msg Type 及其路由處理常式解讀
先介紹根據msg.Type 進行路由的路由函數
路由函數 initializeHandlerMap
func (r *raft) Handle(m pb.Message) {
if !r.onMessageTermNotMatched(m) {
r.doubleCheckTermMatched(m.Term)
r.handle(r, m)
} ...
}
func (r *raft) initializeHandlerMap() {
// candidate
...
// follower
r.handlers[follower][pb.Propose] = r.handleFollowerPropose
r.handlers[follower][pb.Replicate] = r.handleFollowerReplicate
r.handlers[follower][pb.Heartbeat] = r.handleFollowerHeartbeat
r.handlers[follower][pb.ReadIndex] = r.handleFollowerReadIndex
r.handlers[follower][pb.LeaderTransfer] = r.handleFollowerLeaderTransfer
r.handlers[follower][pb.ReadIndexResp] = r.handleFollowerReadIndexResp
r.handlers[follower][pb.InstallSnapshot] = r.handleFollowerInstallSnapshot
r.handlers[follower][pb.Election] = r.handleNodeElection
r.handlers[follower][pb.RequestVote] = r.handleNodeRequestVote
r.handlers[follower][pb.TimeoutNow] = r.handleFollowerTimeoutNow
r.handlers[follower][pb.ConfigChangeEvent] = r.handleNodeConfigChange
r.handlers[follower][pb.LocalTick] = r.handleLocalTick
r.handlers[follower][pb.SnapshotReceived] = r.handleRestoreRemote
// leader
r.handlers[leader][pb.LeaderHeartbeat] = r.handleLeaderHeartbeat
r.handlers[leader][pb.CheckQuorum] = r.handleLeaderCheckQuorum
r.handlers[leader][pb.Propose] = r.handleLeaderPropose
r.handlers[leader][pb.ReadIndex] = r.handleLeaderReadIndex
r.handlers[leader][pb.ReplicateResp] = lw(r, r.handleLeaderReplicateResp)
r.handlers[leader][pb.HeartbeatResp] = lw(r, r.handleLeaderHeartbeatResp)
r.handlers[leader][pb.SnapshotStatus] = lw(r, r.handleLeaderSnapshotStatus)
r.handlers[leader][pb.Unreachable] = lw(r, r.handleLeaderUnreachable)
r.handlers[leader][pb.LeaderTransfer] = r.handleLeaderTransfer
r.handlers[leader][pb.Election] = r.handleNodeElection
r.handlers[leader][pb.RequestVote] = r.handleNodeRequestVote
r.handlers[leader][pb.ConfigChangeEvent] = r.handleNodeConfigChange
r.handlers[leader][pb.LocalTick] = r.handleLocalTick
r.handlers[leader][pb.SnapshotReceived] = r.handleRestoreRemote
r.handlers[leader][pb.RateLimit] = r.handleLeaderRateLimit
// observer
...
// witness
...
}
重點需要關注的函數是 r.handlers[follower][pb.Propose] = r.handleFollowerPropose, r.handlers[follower][pb.Replicate] = r.handleFollowerReplicate, r.handlers[leader][pb.Propose] = r.handleLeaderPropose, r.handlers[leader][pb.ReplicateResp] = lw(r, r.handleLeaderReplicateResp)這四個函數. 分別對應Follower處理Proposal訊息和Replicate訊息; 以及Leader處理ProposalS和ReplicateResp訊息. 接下來分別閱讀上述四個函數. 以及上述四個函數後續的呼叫棧. 最終在本地呼叫棧結束於send函數. send函數十分簡單僅僅將msgs新增到r.msgs領域中. 之後將有node掃描raft的msgs領域和logs領域中的快取訊息, 並行起網路互動.
send
func (r *raft) send(m pb.Message) {
m.From = r.nodeID
m = r.finalizeMessageTerm(m)
r.msgs = append(r.msgs, m)
}
更新msg的任期以及原節點id資訊, 後新增到raft的msgs領域.
handleFollowerPropose
func (r *raft) handleFollowerPropose(m pb.Message) {
if r.leaderID == NoLeader {
plog.Warningf("%s dropped proposal, no leader", r.describe())
r.reportDroppedProposal(m)
return
}
m.To = r.leaderID
// the message might be queued by the transport layer, this violates the
// requirement of the entryQueue.get() func. copy the m.Entries to its
// own space.
m.Entries = newEntrySlice(m.Entries)
r.send(m)
}
Follower接到使用者端的proposal(提議) 後需要將提議轉發給主節點, 因此更新完msg.To 目的節點資訊後立刻轉發. 呼叫send函數.
handleLeaderPropose 及其後續函數
func (r *raft) handleLeaderPropose(m pb.Message) {
r.mustBeLeader()
if r.leaderTransfering() {
plog.Warningf("%s dropped proposal, leader transferring", r.describe())
r.reportDroppedProposal(m)
return
}
for i, e := range m.Entries {
if e.Type == pb.ConfigChangeEntry {
if r.hasPendingConfigChange() {
plog.Warningf("%s dropped config change, pending change", r.describe())
r.reportDroppedConfigChange(m.Entries[i])
m.Entries[i] = pb.Entry{Type: pb.ApplicationEntry}
}
r.setPendingConfigChange()
}
}
r.appendEntries(m.Entries)
r.broadcastReplicateMessage()
}
前18行程式碼都不是我們關注的重點: 大體進行一下在確認主節點完畢之後, 判斷當前叢集狀態, 以及設定變更的操作. 最後兩行的帶嗎引起我的的注意. 他們分別是 r.appendEntries(m.Entries)和 r.broadcastReplicateMessage().
func (r *raft) appendEntries(entries []pb.Entry) {
lastIndex := r.log.lastIndex()
for i := range entries {
entries[i].Term = r.term
entries[i].Index = lastIndex + 1 + uint64(i)
}
r.log.append(entries)
r.remotes[r.nodeID].tryUpdate(r.log.lastIndex())
if r.isSingleNodeQuorum() {
r.tryCommit()
}
}
在appendEntries中更新每個entry的term和Index資訊. 並將這些entries新增到r.log中.
func (r *raft) broadcastReplicateMessage() {
r.mustBeLeader()
for nid := range r.observers {
if nid == r.nodeID {
plog.Panicf("%s observer is broadcasting Replicate msg", r.describe())
}
}
for _, nid := range r.nodes() {
if nid != r.nodeID {
r.sendReplicateMessage(nid)
}
}
}
在broadcastReplicateMessage方法中, 檢查完leader之後, 呼叫r.sendReplicateMessage(nid)來實現訊息的傳送.
func (r *raft) sendReplicateMessage(to uint64) {
var rp *remote
if v, ok := r.remotes[to]; ok {
rp = v
} else if v, ok := r.observers[to]; ok {
rp = v
} else {
rp, ok = r.witnesses[to]
if !ok {
plog.Panicf("%s failed to get the remote instance", r.describe())
}
}
if rp.isPaused() {
return
}
m, err := r.makeReplicateMessage(to, rp.next, maxEntrySize)
if err != nil {
// log not available due to compaction, send snapshot
if !rp.isActive() {
plog.Warningf("%s, %s is not active, sending snapshot is skipped",
r.describe(), NodeID(to))
return
}
index := r.makeInstallSnapshotMessage(to, &m)
plog.Infof("%s is sending snapshot (%d) to %s, r.Next %d, r.Match %d, %v",
r.describe(), index, NodeID(to), rp.next, rp.match, err)
rp.becomeSnapshot(index)
} else if len(m.Entries) > 0 {
lastIndex := m.Entries[len(m.Entries)-1].Index
rp.progress(lastIndex)
}
r.send(m)
}
該訊息傳送函數進行了一系列狀態檢查和判斷之後, 最後一行語句點明主旨. 還是呼叫本段開始所述的send方法.
handleFollowerReplicate
func (r *raft) handleFollowerReplicate(m pb.Message) {
r.leaderIsAvailable()
r.setLeaderID(m.From)
r.handleReplicateMessage(m)
}
前兩行判斷leader的資訊. 最後一行呼叫r.handleReplicateMessage(m)方法處理Replicate資訊.
在處理Replicate msg的過程中, 根據comitted資訊的不同將有兩種邏輯, 分別對應紀錄檔的複製和紀錄檔的提交.
func (r *raft) handleReplicateMessage(m pb.Message) {
resp := pb.Message{
To: m.From,
Type: pb.ReplicateResp,
}
if m.LogIndex < r.log.committed {
resp.LogIndex = r.log.committed
r.send(resp)
return
}
if r.log.matchTerm(m.LogIndex, m.LogTerm) {
r.log.tryAppend(m.LogIndex, m.Entries)
lastIdx := m.LogIndex + uint64(len(m.Entries))
r.log.commitTo(min(lastIdx, m.Commit))
resp.LogIndex = lastIdx
} else {
plog.Debugf("%s rejected Replicate index %d term %d from %s",
r.describe(), m.LogIndex, m.Term, NodeID(m.From))
resp.Reject = true
resp.LogIndex = m.LogIndex
resp.Hint = r.log.lastIndex()
if r.events != nil {
info := server.ReplicationInfo{
ClusterID: r.clusterID,
NodeID: r.nodeID,
Index: m.LogIndex,
Term: m.LogTerm,
From: m.From,
}
r.events.ReplicationRejected(info)
}
}
r.send(resp)
}
func (l *entryLog) tryAppend(index uint64, ents []pb.Entry) bool {
conflictIndex := l.getConflictIndex(ents)
if conflictIndex != 0 {
if conflictIndex <= l.committed {
plog.Panicf("entry %d conflicts with committed entry, committed %d",
conflictIndex, l.committed)
}
l.append(ents[conflictIndex-index-1:])
return true
}
return false
}
func (l *entryLog) getConflictIndex(entries []pb.Entry) uint64 {
for _, e := range entries {
if !l.matchTerm(e.Index, e.Term) {
return e.Index
}
}
return 0
}
func (l *entryLog) commitTo(index uint64) {
if index <= l.committed {
return
}
if index > l.lastIndex() {
plog.Panicf("invalid commitTo index %d, lastIndex() %d",
index, l.lastIndex())
}
l.committed = index
}
func (l *entryLog) lastIndex() uint64 {
index, ok := l.inmem.getLastIndex()
if ok {
return index
}
_, index = l.logdb.GetRange()
return index
}
前五行構造了replicaresp資料結構的同時, 對當前的committedIndex和m.LogIndex進行對比, 顯然拒絕了比當前已提交的Index更小的訊息. 之後在11--15行的程式碼中, 進行了term任期校驗後, 新增msg到r.log中, 更新其committed的index值. 一切結束之後使用前述的send方法返回Resp.
handleLeaderReplicateResp
func (r *raft) handleLeaderReplicateResp(m pb.Message, rp *remote) {
r.mustBeLeader()
rp.setActive()
if !m.Reject {
paused := rp.isPaused()
if rp.tryUpdate(m.LogIndex) {
rp.respondedTo()
if r.tryCommit() {
r.broadcastReplicateMessage()
} else if paused {
r.sendReplicateMessage(m.From)
}
// according to the leadership transfer protocol listed on the p29 of the
// raft thesis
if r.leaderTransfering() && m.From == r.leaderTransferTarget &&
r.log.lastIndex() == rp.match {
r.sendTimeoutNowMessage(r.leaderTransferTarget)
}
}
} else {
// the replication flow control code is derived from etcd raft, it resets
// nextIndex to match + 1. it is thus even more conservative than the raft
// thesis's approach of nextIndex = nextIndex - 1 mentioned on the p21 of
// the thesis.
if rp.decreaseTo(m.LogIndex, m.Hint) {
r.enterRetryState(rp)
r.sendReplicateMessage(m.From)
}
}
}
不考慮失敗的其他情況, 重點關注5--19行的程式碼, 不難發現, r.tryCommit() 和``r.broadcastReplicateMessage()`是值得重點注意的. 其中第一個函數負責狀態判斷, 第二個函數負責訊息的廣播.
func (r *raft) tryCommit() bool {
r.mustBeLeader()
if r.numVotingMembers() != len(r.matched) {
r.resetMatchValueArray()
}
idx := 0
for _, v := range r.remotes {
r.matched[idx] = v.match
idx++
}
for _, v := range r.witnesses {
r.matched[idx] = v.match
idx++
}
r.sortMatchValues()
q := r.matched[r.numVotingMembers()-r.quorum()]
// see p8 raft paper
// "Raft never commits log entries from previous terms by counting replicas.
// Only log entries from the leader’s current term are committed by counting
// replicas"
return r.log.tryCommit(q, r.term)
}
判斷完leader身份之後進行?? 此處存疑. 之後到entryLog進行commit操作. 對於leader來說已經完成了紀錄檔提交的過程了, 但是client還需要對leader的本次Replicate資訊進行反饋.
func (l *entryLog) tryCommit(index uint64, term uint64) bool {
if index <= l.committed {
return false
}
lterm, err := l.term(index)
if err == ErrCompacted {
lterm = 0
} else if err != nil {
panic(err)
}
if index > l.committed && lterm == term {
l.commitTo(index)
return true
}
return false
}
具體的commit邏輯還是在entrylog的方法中實現的.
func (r *raft) broadcastReplicateMessage() {
r.mustBeLeader()
for nid := range r.observers {
if nid == r.nodeID {
plog.Panicf("%s observer is broadcasting Replicate msg", r.describe())
}
}
for _, nid := range r.nodes() {
if nid != r.nodeID {
plog.Errorf("[Aibot] %s is sending replicate message to %s", r.describe(), NodeID(nid))
r.sendReplicateMessage(nid)
}
}
}
判斷完狀態最後一行進行訊息的傳送
func (r *raft) sendReplicateMessage(to uint64) {
var rp *remote
if v, ok := r.remotes[to]; ok {
rp = v
} else if v, ok := r.observers[to]; ok {
rp = v
} else {
rp, ok = r.witnesses[to]
if !ok {
plog.Panicf("%s failed to get the remote instance", r.describe())
}
}
if rp.isPaused() {
return
}
m, err := r.makeReplicateMessage(to, rp.next, maxEntrySize)
if err != nil {
// log not available due to compaction, send snapshot
if !rp.isActive() {
plog.Warningf("%s, %s is not active, sending snapshot is skipped",
r.describe(), NodeID(to))
return
}
index := r.makeInstallSnapshotMessage(to, &m)
plog.Infof("%s is sending snapshot (%d) to %s, r.Next %d, r.Match %d, %v",
r.describe(), index, NodeID(to), rp.next, rp.match, err)
rp.becomeSnapshot(index)
} else if len(m.Entries) > 0 {
lastIndex := m.Entries[len(m.Entries)-1].Index
rp.progress(lastIndex)
}
r.send(m)
}
從第16行開始構造一個replicate Message開始, 這裡的pregress方法提供對遠端狀態的管理.
func (r *raft) makeReplicateMessage(to uint64,
next uint64, maxSize uint64) (pb.Message, error) {
term, err := r.log.term(next - 1)
if err != nil {
return pb.Message{}, err
}
entries, err := r.log.entries(next, maxSize)
if err != nil {
return pb.Message{}, err
}
if len(entries) > 0 {
lastIndex := entries[len(entries)-1].Index
expected := next - 1 + uint64(len(entries))
if lastIndex != expected {
plog.Panicf("%s expected last index in Replicate %d, got %d",
r.describe(), expected, lastIndex)
}
}
// Don't send actual log entry to witness as they won't replicate real message,
// unless there is a config change.
if _, ok := r.witnesses[to]; ok {
entries = makeMetadataEntries(entries)
}
return pb.Message{
To: to,
Type: pb.Replicate,
LogIndex: next - 1,
LogTerm: term,
Entries: entries,
Commit: r.log.committed,
}, nil
}
構建Replicate, msg. 之後傳送給follower.
func (r *remote) progress(lastIndex uint64) {
if r.state == remoteReplicate {
r.next = lastIndex + 1
} else if r.state == remoteRetry {
r.retryToWait()
} else {
panic("unexpected remote state")
}
}
node的互動邏輯
主程序中有一個while True迴圈進行實時變更的處理.
func (e *engine) stepWorkerMain(workerID uint64) {
nodes := make(map[uint64]*node)
ticker := time.NewTicker(nodeReloadInterval)
defer ticker.Stop()
cci := uint64(0)
stopC := e.nodeStopper.ShouldStop()
updates := make([]pb.Update, 0)
for {
select {
case <-stopC:
e.offloadNodeMap(nodes)
return
case <-ticker.C:
nodes, cci = e.loadStepNodes(workerID, cci, nodes)
e.processSteps(workerID, make(map[uint64]struct{}), nodes, updates, stopC)
case <-e.stepCCIReady.waitCh(workerID):
nodes, cci = e.loadStepNodes(workerID, cci, nodes)
case <-e.stepWorkReady.waitCh(workerID):
if cci == 0 || len(nodes) == 0 {
nodes, cci = e.loadStepNodes(workerID, cci, nodes)
}
active := e.stepWorkReady.getReadyMap(workerID)
e.processSteps(workerID, active, nodes, updates, stopC)
}
}
}
在這個迴圈中的第23行e.processSteps(workerID, active, nodes, updates, stopC)監控事件的狀態並進行處理
func (e *engine) processSteps(workerID uint64,
active map[uint64]struct{},
nodes map[uint64]*node, nodeUpdates []pb.Update, stopC chan struct{}) {
if len(nodes) == 0 {
return
}
if len(active) == 0 {
for cid := range nodes {
active[cid] = struct{}{}
}
}
nodeUpdates = nodeUpdates[:0]
for cid := range active {
node, ok := nodes[cid]
if !ok || node.stopped() {
continue
}
if ud, hasUpdate := node.stepNode(); hasUpdate {
nodeUpdates = append(nodeUpdates, ud)
}
}
e.applySnapshotAndUpdate(nodeUpdates, nodes, true)
// see raft thesis section 10.2.1 on details why we send Replicate message
// before those entries are persisted to disk
for _, ud := range nodeUpdates {
node := nodes[ud.ClusterID]
node.sendReplicateMessages(ud)
node.processReadyToRead(ud)
node.processDroppedEntries(ud)
node.processDroppedReadIndexes(ud)
}
if err := e.logdb.SaveRaftState(nodeUpdates, workerID); err != nil {
panic(err)
}
if err := e.onSnapshotSaved(nodeUpdates, nodes); err != nil {
panic(err)
}
e.applySnapshotAndUpdate(nodeUpdates, nodes, false)
for _, ud := range nodeUpdates {
node := nodes[ud.ClusterID]
if err := node.processRaftUpdate(ud); err != nil {
panic(err)
}
e.processMoreCommittedEntries(ud)
node.commitRaftUpdate(ud)
}
if lazyFreeCycle > 0 {
resetNodeUpdate(nodeUpdates)
}
}
在這個方法中第18行stepNode方法負責進行Node本地事務的處理包括本地使用者端以及其他節點傳送到本機的訊息. 第41行負責進行網路互動processRaftUpdate
func (n *node) processRaftUpdate(ud pb.Update) error {
if err := n.logReader.Append(ud.EntriesToSave); err != nil {
return err
}
n.sendMessages(ud.Messages)
if err := n.removeLog(); err != nil {
return err
}
if err := n.runSyncTask(); err != nil {
return err
}
if n.saveSnapshotRequired(ud.LastApplied) {
n.pushTakeSnapshotRequest(rsm.SSRequest{})
}
return nil
}
第5行 n.sendMessages(ud.Messages)方法
func (n *node) sendMessages(msgs []pb.Message) {
for _, msg := range msgs {
if !isFreeOrderMessage(msg) {
msg.ClusterId = n.clusterID
n.sendRaftMessage(msg)
}
}
}
第5行n.sendRaftMessage(msg)由上層函數指定方法
func (nh *NodeHost) sendMessage(msg pb.Message) {
if nh.isPartitioned() {
return
}
if msg.Type != pb.InstallSnapshot {
nh.transport.Send(msg)
} else {
witness := msg.Snapshot.Witness
plog.Debugf("%s is sending snapshot to %s, witness %t, index %d, size %d",
dn(msg.ClusterId, msg.From), dn(msg.ClusterId, msg.To),
witness, msg.Snapshot.Index, msg.Snapshot.FileSize)
if n, ok := nh.getCluster(msg.ClusterId); ok {
if witness || !n.OnDiskStateMachine() {
nh.transport.SendSnapshot(msg)
} else {
n.pushStreamSnapshotRequest(msg.ClusterId, msg.To)
}
}
nh.events.sys.Publish(server.SystemEvent{
Type: server.SendSnapshotStarted,
ClusterID: msg.ClusterId,
NodeID: msg.To,
From: msg.From,
})
}
}s
第6行nh.transport.Send(msg)
// Send asynchronously sends raft messages to their target nodes.
//
// The generic async send Go pattern used in Send() is found in CockroachDB's
// codebase.
func (t *Transport) Send(req pb.Message) bool {
v, _ := t.send(req)
if !v {
t.metrics.messageSendFailure(1)
}
return v
}
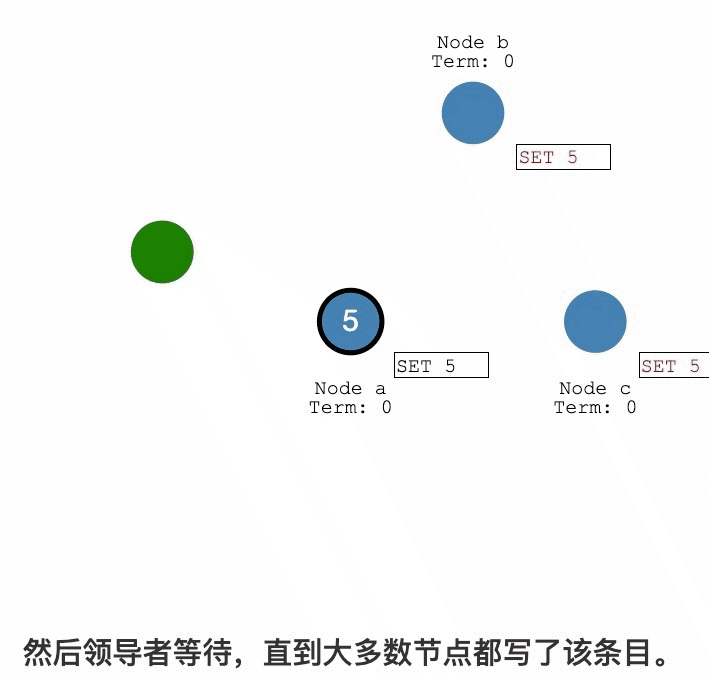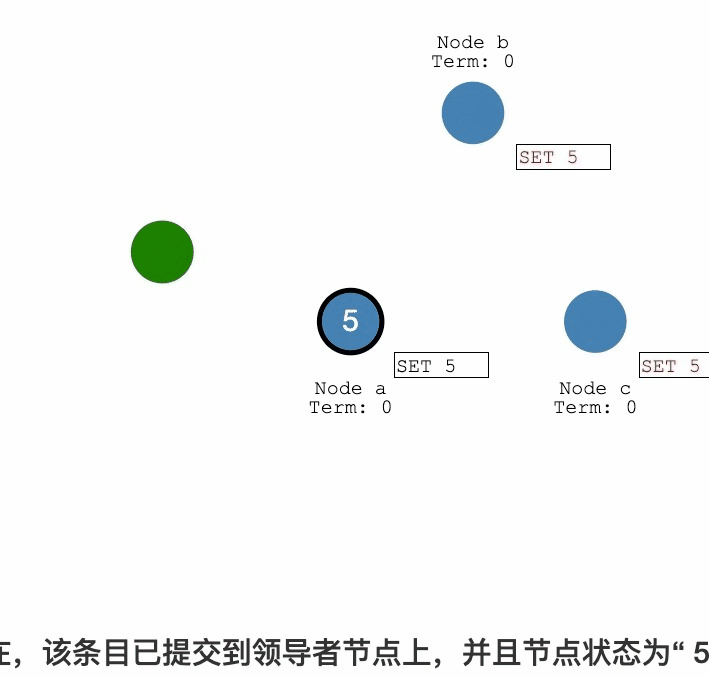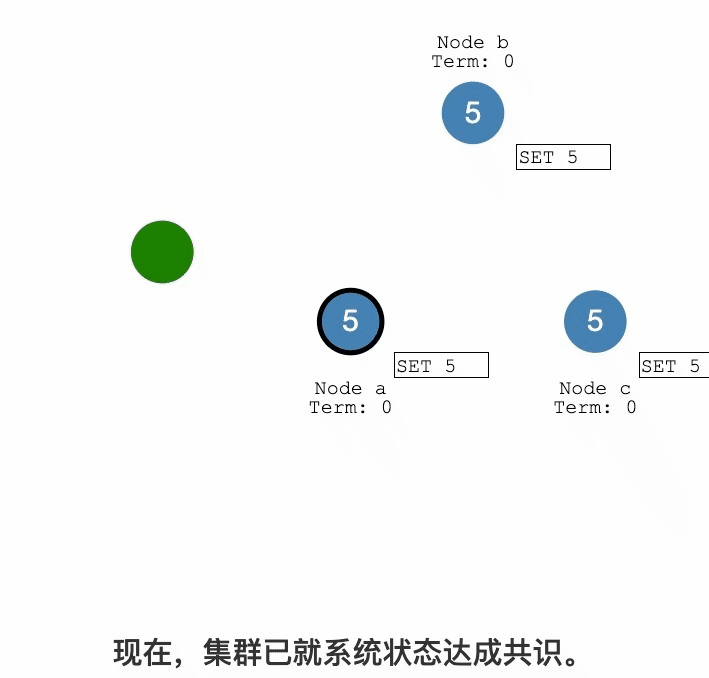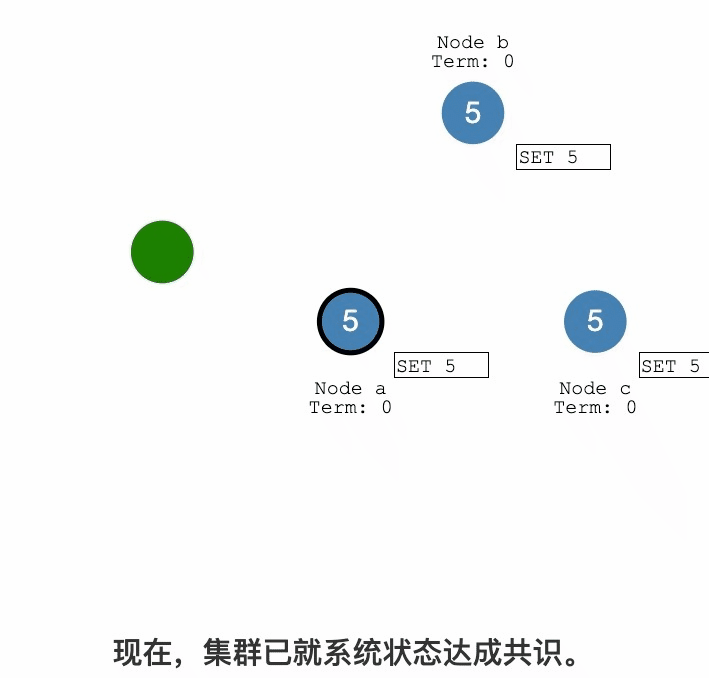
Raft紀錄檔複製過程詳解
紀錄檔複製
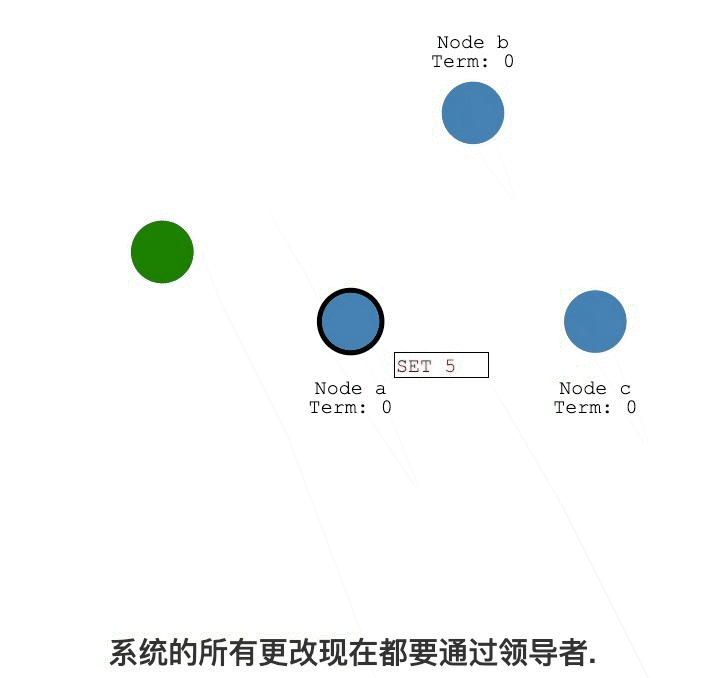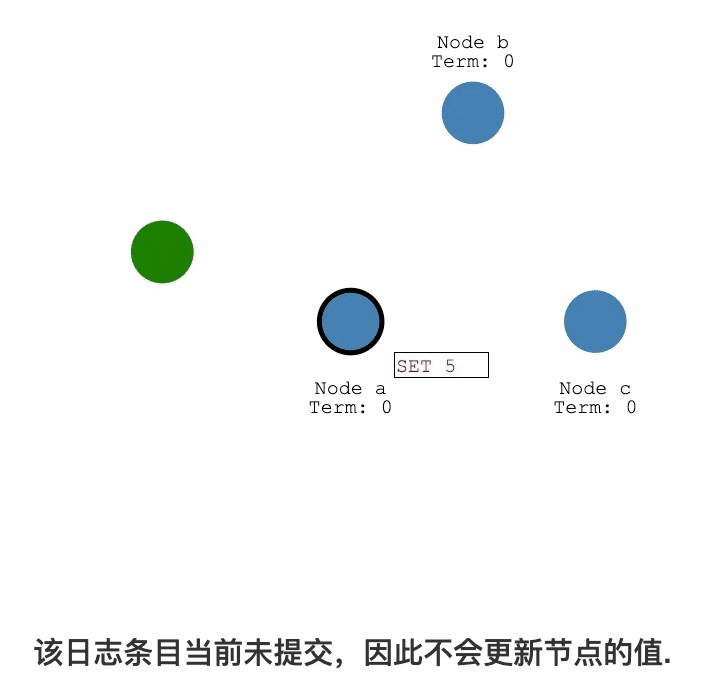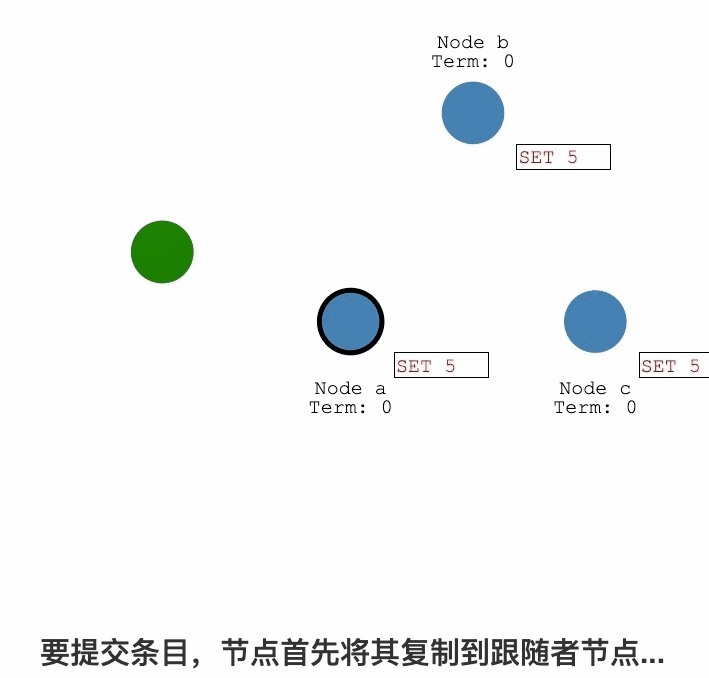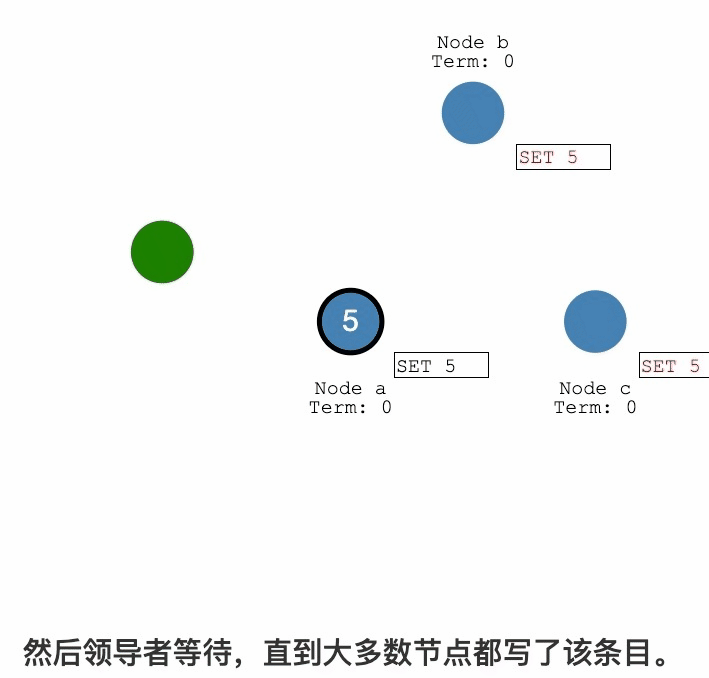
紀錄檔提交