帶你讀AI論文丨ACGAN-動漫頭像生成
摘要:ACGAN-動漫頭像生成是一個十分優秀的開源專案。
本文分享自華為雲社群《【雲駐共創】AI論文精讀會:ACGAN-動漫頭像生成》,作者:SpiderMan。
1.論文及演演算法介紹
1.1基本資訊
• 論文題目:《Conditional Image Synthesis With Auxiliary Classifier GANs》
• 出處:ICML 2017
• 作者:Augustus Odena、Christopher Olah、Jonathon Shlens
1.2研究背景
GAN(Generative Adversarial Network)是由兩個彼此對立訓練的神經網路組成。生成器G以隨機噪聲向量z作為輸入然後輸出-張影象G(z),判別器D接收訓練影象或者是來自生成器的合成影象作為輸入,輸出在可能資料來源上的條件概率分佈D(x),他需要分別出真實的資料來源或者是生成的資料來源。
使用標籤的資料集應用於生成對抗網路可以增強現有的生成模型,並形成兩種優化思路。
• cGAN使用了輔助的標籤資訊來增強原始GAN,對生成器和判別器都使用標籤資料進行訓練,從而實現模型具備產生特定條件資料的能力。
• SGAN的結構利用輔助標籤資訊(少量標籤),利用判別器或者分類器的末端重建標籤資訊。
ACGAN則是結合以上兩種思路對GAN進行優化。
1.3演演算法介紹
1.3.1 ACGAN模型結構
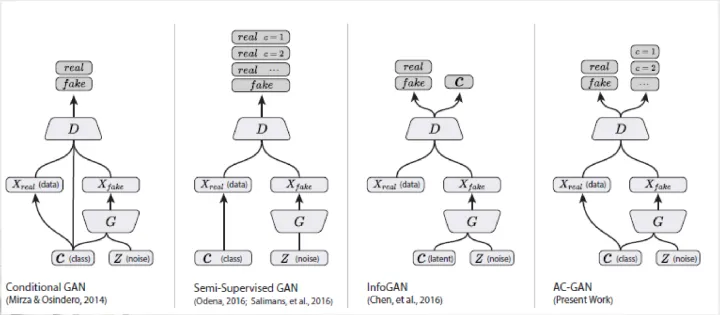
1.3.2損失函數
• Ls是面向資料真實與否的代價函數。
• Lc則是資料分類準確性的代價函數。
在優化過程中希望判別器D能否使得Ls+Lc儘可能最大,而生成器G使得Lc-Ls儘可能最大。
簡而言之是希望判別器能夠儘可能區分真實資料和生成資料並且能有效對資料進行分類,對生成器來說希望生成資料被儘可能認為是真實資料且資料都能夠被有效分類。
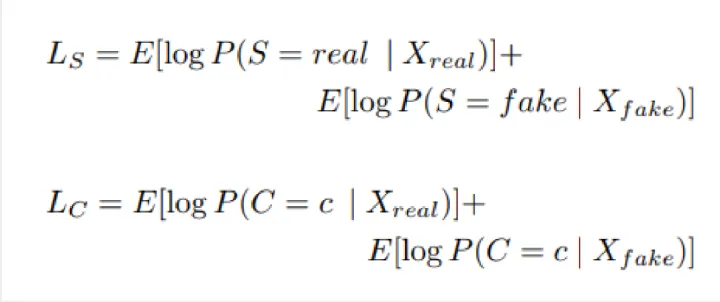
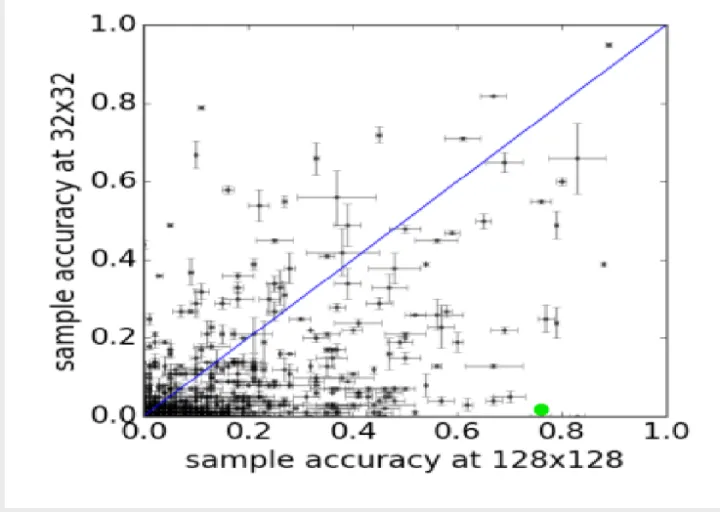
1.3.3高解析度
如何評價一個生成模型生成圖片的解析度,最簡單的方法無非就是直觀用眼睛來看,但這樣顯然無法量化一個圖片的好壞,於是作者提出使用一個分類器,若生成的圖片具有較高的分類正確率,就有理由認為生成的圖片質量比較高,也即該圖片具有較高的可分辨性,如上所述,生成高解析度的圖片,需要不是簡單的將低解析度的圖片進行線性插值來生成,因而要量化的分析生成的圖片的質量,可以從其分辨力。
從低解析度通過插值生成的高解析度圖片,其本質上沒有增加多餘資訊,只是低解析度的模糊版。結合這樣的思路,高解析度的圖片提供了更多的資訊,這些資訊結合到AC-GAN結構,每個生成圖片都有其對應的標籤,因而這個更多的資訊,可以通過分類來表明,也就是說更多的資訊,可以用於分類,也就是文中所說的分辨力。
因此,ACGAN提出Inception Accuracy,這種新的用於評判影象合成模型的標準,檢視其被分類為正確類別的比率,以此來判定生成的圖片質量。圖中,最上面給出了真實圖片和基於ACGAN生成圖片,可以明顯感覺圖片高解析度對應高可分辨性。


1.3.4影象多樣性
GAN有個最常見的問題就是模式坍塌的問題,就是模型找到一種方式,無論輸入的內容是什麼,生成的圖片都只有一種,然而這種圖片能大概率欺騙過分辨器。因而,產生的圖片具有多樣性,也是可以評估GAN模型好壞的指標。
文中採用了圖片的多尺度結構相似度來衡量圖片與圖片之間的相似度(multi-scale structural similarity,MS-SSIM),這個相似度在0和1之間取值,越大說明圖片之間越相似;提及MS-SSIM的時候,往往也要提及SSIM,來看看它們具體是怎麼計算的。

1.3.5 ACGAN分析
ACGAN分析是否通過記憶樣本合成影象。

1.3.6 ModelArts介紹
ModelArts 是面向開發者的一站式AI開發平臺,為機器學習與深度學習提供海量資料預處理及互動式智慧標註、大規模分散式訓練、自動化模型生成,及端-邊-雲模型按需部署能力,幫助使用者快速建立和部署模型,管理全週期AI工作流。下圖就是ModelArts的能力圖:
2.程式碼移植ModelArts
2.1 ModelArts簡介
ModelArts是面向AI開發者的一站式開發平臺,提供海量資料預處理及半自動化標註、大規模分散式訓練、自動化模型生成及端-邊-雲模型按需部署能力,幫助使用者快速建立和部署模型,管理全週期AI工作流。
「一站式」是指AI開發的各個環節,包括資料處理、模型訓練、模型部署都可以在ModelArts上完成。從技術上看,ModelArts底層支援各種異構計算資源,開發者可以根據需要靈活選擇使用,而不需要關心底層的技術。同時,ModelArts支援Tensorflow、PyTorch、MindSpore等主流開源的AI開發框架,也支援開發者使用自研的演演算法框架,匹配使用者的使用習慣。
ModelArts的理念就是讓AI開發變得更簡單、更方便。面向不同經驗的AI開發者,提供便捷易用的使用流程。例如:
- 面向業務開發者,不需關注模型或編碼,可使用自動學習流程快速構建AI應用;
- 面向AI初學者,不需關注模型開發,使用預置演演算法構建AI應用;
- 面向AI工程師,提供多種開發環境,多種操作流程和模式,方便開發者編碼擴充套件,快速構建模型及應用。
2.1.1 ModelArts特點
• 自動學習;
• 資料管理;
• 開發環境;
• 演演算法、訓練、模型、部署。
2.1.2 Notebook開發環境

2.2 ACGAN-動漫頭像生成
使用的資料集64*64的動漫頭像,共36740張。
資料可以存放在物件儲存服務(Object Storage Service, OBS)。

2.3 程式碼講解
2.3.1輸入
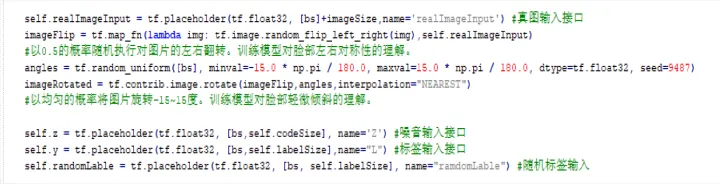
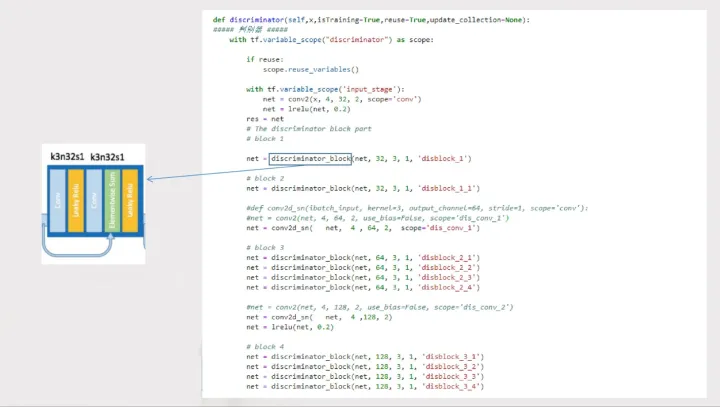
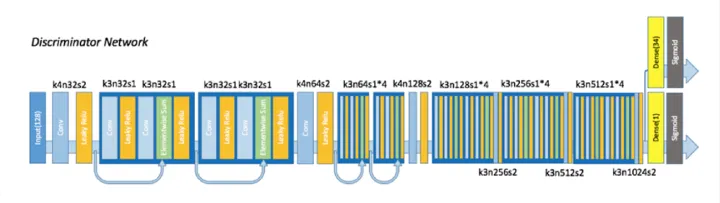
2.3.2判別器
2.3.3生成器
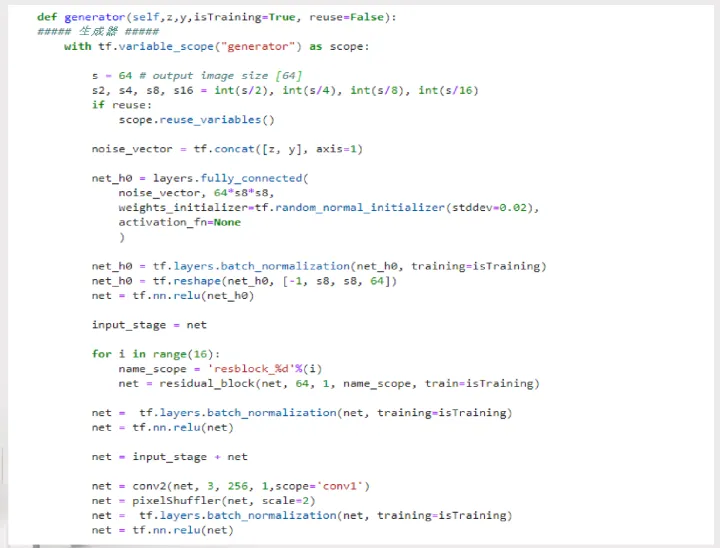
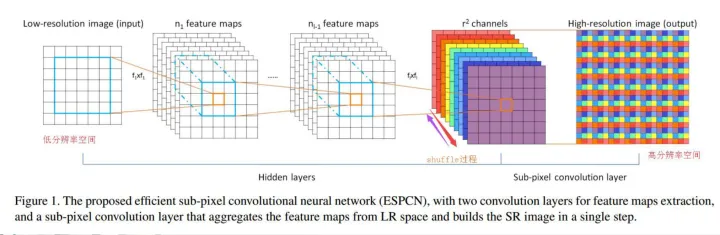
2.3.4 PixelShuffle
主要實現了這樣的功能:N*(C* r* r)*W*H——>>N*C*(H*r)*(W*r)。
2.3.5損失函數

2.3.6優化器

2.3.7訓練

2.3.8模型預測

2.4檢視效果

2.5後期優化方向

2.6參考網址/體驗網址
參考網址:
https://blog.csdn.net/forlogen/article/details/93852960
https://blog.csdn.net/qq_24477135/article/details/85758496
https://www.cnblogs.com/punkcure/p/7873566.html
https://www.zjusct.io/2019/06/16/Animation%20Avatar%20Generation/
https://blog.csdn.net/u014636245/article/details/98071626
體驗網址:
GitHub網址: https://github.com/makegirlsmoe/makegirlsmoe_web
線上體驗: https://make.girls.moe/#/
3.總結
ACGAN-動漫頭像生成是一個十分優秀的開源專案,針對已有的動漫人物頭像生成方法中生成結果的多樣性較差,且難以準確地按照使用者想法按類生成或按區域性細節生成的問題,基於含輔助分類器的對抗生成網路(ACGAN),結合互資訊理論、多尺度判別等方法,最終用於動漫人物頭像的生成。
此專案在生成影象的過程中使得生成的影象更接近於樣本集,這樣在顯得更真實的同時又不發生模式崩塌;但是如何人為定義連續標籤以控制細節,而不是通過模型自學習產生仍是值得繼續研究的問題。