謠言檢測(RDEA)《Rumor Detection on Social Media with Event Augmentations》
論文資訊
論文標題:Rumor Detection on Social Media with Event Augmentations
論文作者:Zhenyu He, Ce Li, Fan Zhou, Yi Yang
論文來源:2021,SIGIR
論文地址:download
論文程式碼:download
1 Introduction
現有的深度學習方法取得了巨大的成功,但是這些方法需要大量可靠的標記資料集來訓練,這是耗時和資料低效的。為此,本文提出了 RDEA ,通過事件增強在社交媒體上的謠言檢測(RDEA),該方案創新地整合了三種增強策略,通過修改回覆屬性和事件結構,提取有意義的謠言傳播模式,並學習使用者參與的內在表示。
貢獻:
-
- 涉及了三種可解釋的資料增強策略,這在謠言時間圖資料中沒有得到充分的探索;
- 在謠言資料集中使用對比自監督的方法進行預訓練;
- REDA 遠高於其他監督學習方法;
2 Methodology
總體框架如下:
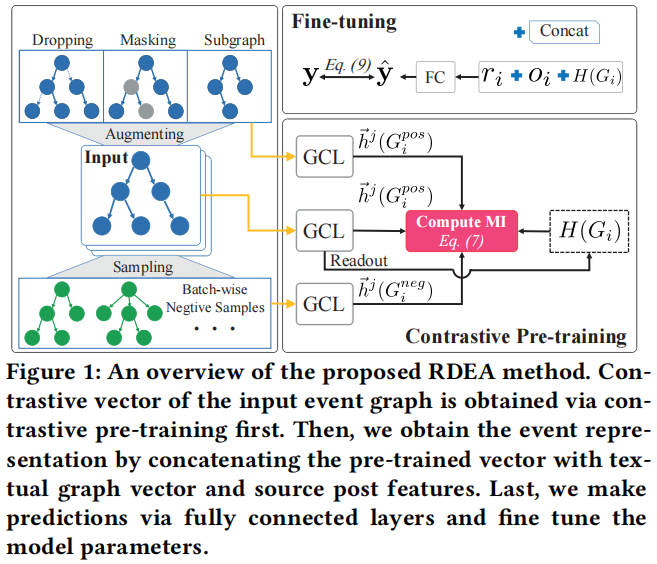
主要包括三個模組:
-
- event graph data augmentation
- contrastive pre-training
- model fne-tuning
2.1 Event Augmentation
謠言事件中存在兩種使用者:
-
- malicious users
- naive users
malicious users 故意傳播虛假資訊,nvaive users 無意中幫助了 malicious users 傳播虛假資訊,所以 mask node 是可行的。
給定除 root node 的節點特徵矩陣 $E^{-r} \in \mathbb{R}^{(|\mathcal{V}|-1) \times d}$,以及一個 mask rate $p_{m}$,mask 後的節點特徵矩陣為:
$E_{\text {mask }}^{-r}=\mathrm{M} \odot E^{-r} $
其中,$M \in\{0,1\}^{(|\mathcal{V}|-1) \times d}$ 代表著 mask matrix,隨機刪除 $ (|\mathcal{V}|-1) \times p_{m}$ 行節點特徵矩陣。
2.2 Subgraph
使用者在早期階段通常是支援真實謠言的,所以,在模型訓練時,如果過多的存取謠言事件的整個生命週期,將阻礙早期謠言檢測的準確性,所以本文采取隨機遊走生成謠言事件的子圖 $G_{i_sub}$。
2.3 Edge dropping
形式上,給定一個鄰接矩陣 $A$ 和 $N_{e}$ 條邊和丟棄率 $p_{d}$,應用 DropEdge 後的鄰接矩陣 $A_{d r o p}$,其計算方法如下:
$A_{d r o p}=A-A^{\prime}$
其中,$A^{\prime}$ 是隨機取樣 $N_{e} \times p_{d} $ 條邊的鄰接矩陣。
2.2 Contrastive Pre-training
在本節將介紹如何通過在輸入事件和增強事件之間的對比預訓練來獲得互資訊。
形式上,對於 node $j$ 和 event graph $G$,self-supervised learning 過程如下:
$\begin{array}{l}h_{j}^{(k)} &=&\operatorname{GCL}\left(h_{j}^{(k-1)}\right) \\h^{j} &=&\operatorname{CONCAT}\left(\left\{h_{j}^{(k)}\right\}_{k=1}^{K}\right)\\H(G) &=&\operatorname{READOUT}\left(\left\{h^{j}\right\}_{j=1}^{|\mathcal{V}|}\right)\end{array}$
其中,$h_{j}^{(k)}$ 是節點在第 $k$ 層的特徵向量。GCL 是 graph convolutional encoder ,$h^{j}$ 是通過將 GCL 所有層的特徵向量彙總為一個特徵向量,該特徵向量捕獲以每個節點為中心的不同尺度資訊,$H(G)$ 是應用 READOUT 函數的給定事件圖的全域性表示。本文並選擇 GIN 作為 GCL 和 mean 作為 READOUT 函數 。對比預訓練的目標是使謠言傳播圖資料集上的互資訊(MI)最大化,其計算方法為:
${\large \begin{aligned}I_{\psi}\left(h^{j}(G) ; H(G)\right):=& \mathbb{E}\left[-\operatorname{sp}\left(-T_{\psi}\left(\vec{h}^{j}\left(G_{i}^{\text {pos }}\right), H\left(G_{i}\right)\right)\right)\right] \\&-\mathbb{E}\left[\operatorname{sp}\left(T_{\psi}\left(\vec{h}^{j}\left(G_{i}^{n e g}\right), H\left(G_{i}\right)\right)\right)\right]\end{aligned}} $
其中,$I_{\psi}$ 為互資訊估計器,$T_{\psi}$ 為鑑別器(discriminator),$G_{i}$ 是輸入 event 的 graph,$G_{i}^{\text {pos }}$ 是 $G_{i}$ 的 positive sample,$G_{i}^{\text {neg }}$ 是 $G_{i}$ 的負樣本,$s p(z)=\log \left(1+e^{z}\right)$ 是 softplus function。對於正樣本,可以是 $G_{i}\left(E_{\text {mask }}^{-r}\right)$,$G_{i_{-} s u b$,$G_{i}\left(A_{d r o p}\right)$,負樣本是 一個 batch 中其他 event graph 的區域性表示。
在對 event graph 進行對比預訓練後,我們得到了 input event graph $G_{i}$ 的預訓練的向量 $H\left(G_{i}\right)$。然後,對於一個 event $C_{i}=\left[r_{i}, x_{1}^{i}, x_{2}^{i}, \cdots, x_{\left|\mathcal{V}_{i}\right|-1}^{i}, G_{i}\right]$,通過平均所有相關的回覆貼文和源貼文的原始特徵 $o_{i}=\frac{1}{n_{i}}\left(\sum_{j=1}^{\left|\mathcal{V}_{i}\right|-1} x_{j}^{i}+r_{i}\right)$,我們得到了文字圖向量 $o_{i}$。為了強調 source post,將 contrastive vector、textual graph vector 和source post features 合併為:
$\mathbf{S}_{i}=\mathbf{C O N C A T}\left(H\left(G_{i}\right), o_{i}, r_{i}\right)$
2.3 Fine tuning
預訓練使用了文字特徵,得到了預訓練的 event representation,幷包含了原始特徵和 source post 資訊,在 fine-tune 階段,使用預訓練的引數初始化引數,並使用標籤訓練模型:
將上述生成的 $s_{i}$ 通過全連線層進行分類:
$\hat{\mathbf{y}}_{i}=\operatorname{softmax}\left(F C\left(\mathbf{S}_{i}\right)\right)$
最後採用交叉熵損失:
$\mathcal{L}(Y, \hat{Y})=\sum_{i=1}^{|C|} \mathbf{y}_{i} \log \hat{\mathbf{y}}_{i}+\lambda\|\Theta\|_{2}^{2}$
其中,$\|\Theta\|_{2}^{2}$ 代表 $L_{2}$ 正則化,$\Theta$ 代表模型引數,$\lambda$ 是 trade-off 係數。
3 Experiments
-
- DTC [3]: A rumor detection approach applying decision tree that utilizes tweet features to obtain information credibility.
- SVM-TS [10]: A linear SVM-based time-series model that leverages handcrafted features to make predictions.
- RvNN [11]: A recursive tree-structured model with GRU units that learn rumor representations via the tree structure.
- PPC_RNN+CNN [8]: A rumor detection model combining RNN and CNN for early-stage rumor detection, which learns the rumor representations by modeling user and source tweets.
- Bi-GCN [2]: using directed GCN, which learns the rumor representations through Bi-directional propagation structure.
3.2 Performance Comparison

3.3 Ablation study
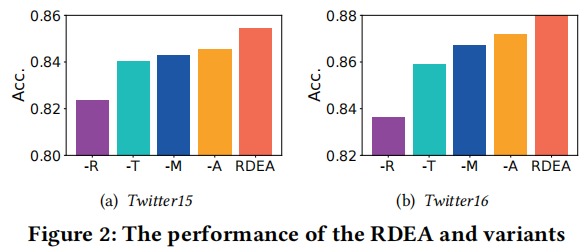
-R represent our model without root feature enhancement
-T represent our model without textual graph
-A represent our model without event augmentation
-M represent our model without mutual information
3.4 Limited labeled data
Figure 3 顯示了當標籤分數變化時的效能:
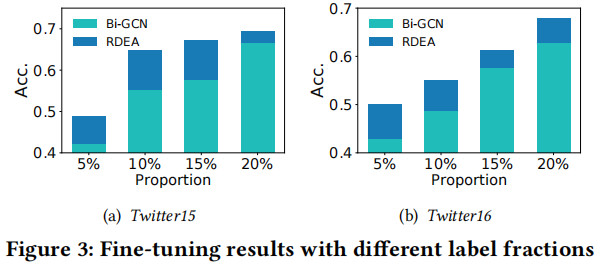
我們觀察到,RDEA 對這兩個資料集都比 Bi-GCN 更具有標籤敏感性。此外,標籤越少,改進幅度越大,說明RDEA的魯棒性和資料有效性。
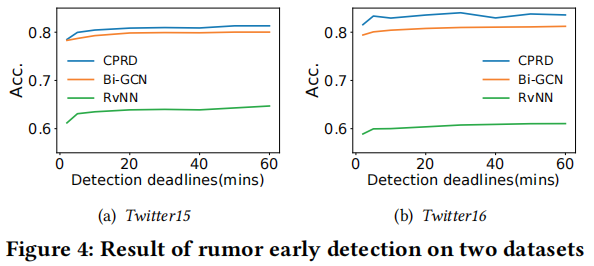
3.5 Early Rumor Detection
因上求緣,果上努力~~~~ 作者:關注我更新論文解讀,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/16776829.html