JuiceFS 後設資料引擎選型指南
檔案系統是我們常見的儲存形式,內部主要由資料和後設資料兩部分組成。其中資料是檔案的具體內容,通常會直接展現給使用者;而後設資料是描述資料的資料,用來記錄檔案屬性、目錄結構、資料儲存位置等。一般來說,後設資料有非常鮮明的特點,即佔用空間較小,但存取非常頻繁。
當今的分散式檔案系統中,有的(如 S3FS)會將後設資料和資料統一管理,以簡化系統設計,不過這樣的弊端是某些後設資料操作會讓使用者感受到明顯的卡頓,如 ls 大目錄,重新命名大檔案等。更多的檔案系統會選擇將這兩者分開管理,並根據後設資料的特點進行鍼對性優化。JuiceFS 採用的就是這種設計,其架構圖如下:
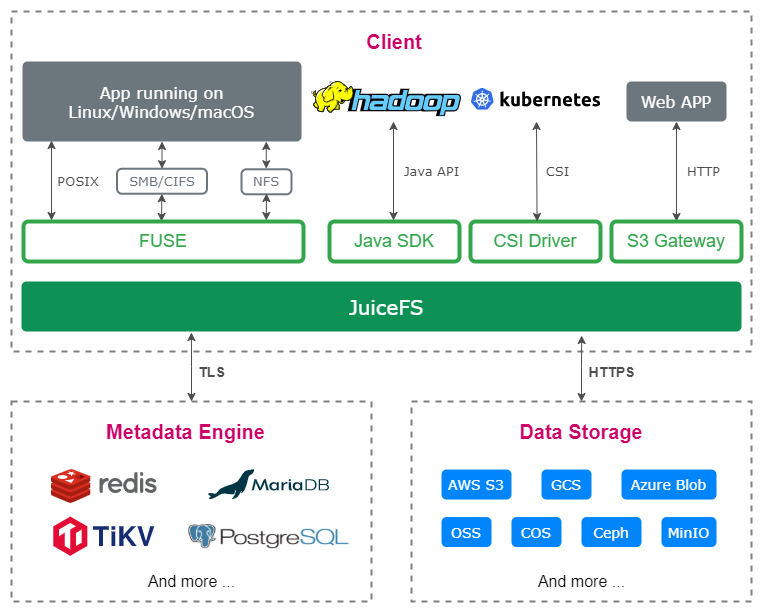
其中,後設資料引擎需要是能夠支援事務操作的資料庫,而資料引擎一般是用物件儲存。目前為止,JuiceFS 已經支援 10 種以上後設資料引擎和 30 種以上資料引擎。
使用者在使用 JuiceFS 時可以自由地選擇成熟元件來充當這兩個引擎,以應對豐富多變的企業環境和資料儲存需求。然而對於新使用者來說,當面對更多選擇時,也帶來了一個問題:在我的場景中究竟選擇哪一款資料庫作為後設資料引擎比較合適?這篇文章將從產品設計角度,為大家介紹 JuiceFS 可使用的後設資料引擎型別,以及他們的優劣勢。
01-JuiceFS 後設資料引擎型別
JuiceFS 現在支援的後設資料引擎總共有有三大類。
第一個是 Redis。Redis 是 JuiceFS 開源後最早支援的後設資料引擎。首先 Redis 速度夠快,這是後設資料引擎需要具備的重要能力之一;其次,Redis 受眾面廣,大部分使用者對 Redis 都有實踐經驗。JuiceFS 對相容 Redis 協定的資料庫也都實現了支援,比如 KeyDB、Amazon MemoryDB 等。
然而,Redis 的可靠性和擴充套件性容易受限,在一些資料安全性要求較高或規模較大的場景中表現乏善可陳,因此我們又開發支援了另外兩類引擎。
第二個是 SQL 類。如 MySQL、MariaDB、PostgreSQL 等,它們的特點是流行度較高,且通常具有不錯的可靠性與擴充套件性。另外,還支援了嵌入式資料庫 SQLite。
最後一個是 TKV(Transactional Key-Value Database)類。它們的原生介面比較簡單,因此在 JuiceFS 中的客製化性更好,相較於 SQL 類一般也能有更高的效能。目前這一類支援的有 TiKV、etcd 和嵌入式的 BadgerDB 等,對 FoundationDB 的支援也在緊鑼密鼓地開發中。
以上是根據 JuiceFS 在對接資料庫時的協定介面進行的分類。每個大類裡面有各種不同的資料庫,每種資料庫又有其自身的特點,以下根據這些特點對使用者常用的幾個選項進行比較。
後設資料引擎比較
| Redis | MySQL/PostgreSQL | TiKV | etcd | SQLite/BadgerDB | |
|---|---|---|---|---|---|
| 效能 | 高 | 低 | 中 | 低 | 中 |
| 擴充套件性 | 低 | 中 | 高 | 低 | 低 |
| 可靠性 | 低 | 高 | 高 | 高 | 中 |
| 可用性 | 中 | 高 | 高 | 高 | 低 |
| 流行度 | 高 | 高 | 中 | 高 | 中 |
如上文中提到的,Redis 的最大優勢是效能高,因為它是全記憶體的資料庫。其他幾方面它就表現平平。
從擴充套件性上說,通常單機 Redis 可以支援 1 億檔案左右,超過 1 億時,Redis 單程序的記憶體使用量會比較大,管理效能上也會有所下降。開源版 Redis 支援以叢集模式來擴充套件其可管理的資料總量,但由於叢集模式下 Redis 並不支援分散式事務,因此作為 JuiceFS 後設資料引擎時,每個 JuiceFS volume 能用的 Redis 程序還是隻有一個,單 volume 的擴充套件性相較於單機 Redis 並沒有太大提升。
從可靠性來看,Redis 預設每秒將資料刷盤,在異常時可能導致小部分資料丟失。通過將設定 appendfsync 改為 always,可以讓 Redis 在每個寫請求後都刷盤,這樣資料可靠效能提高,但是效能卻會下降。
從可用性來說,部署 Redis 哨兵監控節點和備用節點,可以在主 Redis 節點掛掉後選擇一個備份節點來重新提供服務,一定程度上提高可用性。然而,Redis 本身並不支援分散式的一致性協定,其備用節點採用的是非同步備份,所以雖然新的節點起來了,但是中間可能會有資料差,導致新起來的資料並不是那麼的完整。
MySQL 和 PostgreSQL 的整體表現比較類似。它們都是經過大量使用者多年時間驗證過的資料庫產品,可靠性和可用性都不錯,流行度也很高。只是相較於其餘後設資料引擎,它們的效能一般。
TiKV 原本是 PingCAP TiDB 的底層儲存,現在已經分離出來,成為一個獨立的 KV 資料庫元件。從我們的測試結果來看,它用來作為 JuiceFS 的後設資料引擎是一個非常出色的選擇。其本身就有不弱於 MySQL 的資料可靠性和服務可用性,而且在效能與擴充套件性上表現更好。只是在流行度上,它和 MySQL 還有差距。從我們與使用者交流來看,如果他們已經是 TiKV 或 TiDB 的使用者,那最後通常都會偏向使用 TiKV 來做 JuiceFS 的後設資料引擎。但如果他們之前對 TiKV 並不熟悉,那要再接受這樣一個新的元件就會慎重許多。
etcd 是另一個 TKV 類的資料庫。支援 etcd 的原因是因為它在容器化場景中流行度非常高,基本上 k8s 都是用 etcd 來管理它的設定。使用 etcd 作為 JuiceFS 的後設資料引擎,並不是一個特別適配的場景。一方面是它的效能一般,另一方面是它有容量限制(預設 2G,最大 8G),之後就難以擴容。但是它的可靠性和可用性都非常高,而且容器化場景中也很容易部署,因此如果使用者只需要一個規模在百萬檔案級別的檔案系統,etcd 依然是一個不錯的選擇。
最後是 SQLite 和 BadgerDB,它們分別屬於 SQL 類和 TKV 類,但使用起來體驗卻非常類似,因為它們都是單機版的嵌入式資料庫。這類資料庫的特點是效能中等,但擴充套件性和可用性都比較差,因為其資料其實就存放在本地系統中。它們的優勢在於非常易用,只需要 JuiceFS 自己的二進位制檔案,不需要任何額外元件。使用者在某些特定場景或者進行一些簡單功能測試時,可以使用這兩個資料庫。
02- 典型引擎的效能測試結果
我們做過一些典型引擎的效能測試,並將其結果記錄在這個檔案中。其中一份從原始碼介面處測試的最直接結果大致為:Redis > TiKV(3 副本)> MySQL(本地)~= etcd(3 副本),具體如下:
| Redis-Always | Redis-Everysec | TiKV | MySQL | etcd | |
|---|---|---|---|---|---|
| mkdir | 600 | 471 (0.8) | 1614 (2.7) | 2121 (3.5) | 2203 (3.7) |
| mvdir | 878 | 756 (0.9) | 1854 (2.1) | 3372 (3.8) | 3000 (3.4) |
| rmdir | 785 | 673 (0.9) | 2097 (2.7) | 3065 (3.9) | 3634 (4.6) |
| readdir_10 | 302 | 303 (1.0) | 1232 (4.1) | 1011 (3.3) | 2171 (7.2) |
| readdir_1k | 1668 | 1838 (1.1) | 6682 (4.0) | 16824 (10.1) | 17470 (10.5) |
| mknod | 584 | 498 (0.9) | 1561 (2.7) | 2117 (3.6) | 2232 (3.8) |
| create | 591 | 468 (0.8) | 1565 (2.6) | 2120 (3.6) | 2206 (3.7) |
| rename | 860 | 736 (0.9) | 1799 (2.1) | 3391 (3.9) | 2941 (3.4) |
| unlink | 709 | 580 (0.8) | 1881 (2.7) | 3052 (4.3) | 3080 (4.3) |
| lookup | 99 | 97 (1.0) | 731 (7.4) | 423 (4.3) | 1286 (13.0) |
| getattr | 91 | 89 (1.0) | 371 (4.1) | 343 (3.8) | 661 (7.3) |
| setattr | 501 | 357 (0.7) | 1358 (2.7) | 1258 (2.5) | 1480 (3.0) |
| access | 90 | 89 (1.0) | 370 (4.1) | 348 (3.9) | 646 (7.2) |
| setxattr | 404 | 270 (0.7) | 1116 (2.8) | 1152 (2.9) | 757 (1.9) |
| getxattr | 91 | 89 (1.0) | 365 (4.0) | 298 (3.3) | 655 (7.2) |
| removexattr | 219 | 95 (0.4) | 1554 (7.1) | 882 (4.0) | 1461 (6.7) |
| listxattr_1 | 88 | 88 (1.0) | 374 (4.2) | 312 (3.5) | 658 (7.5) |
| listxattr_10 | 94 | 91 (1.0) | 390 (4.1) | 397 (4.2) | 694 (7.4) |
| link | 605 | 461 (0.8) | 1627 (2.7) | 2436 (4.0) | 2237 (3.7) |
| symlink | 602 | 465 (0.8) | 1633 (2.7) | 2394 (4.0) | 2244 (3.7) |
| write | 613 | 371 (0.6) | 1905 (3.1) | 2565 (4.2) | 2350 (3.8) |
| read_1 | 0 | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) |
| read_10 | 0 | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) |
- 上表中記錄的是每一個操作的耗時,數值越小越好;括號內數位是該指標對比 Redis-always 的倍數,數值也是越小越好
- Always 和 Everysec 是 Redis 設定項 appendfsync 的可選值,分別表示每個請求都刷盤和每秒刷一次盤
- 可以看到,Redis 在使用 everysec 的時候,效能更好,但與 always 相差的並不大;這是因為測試用的 AWS 機器上的本地 SSD 盤本身 IOPS 效能就比較高
- TiKV 和 etcd 都使用了三副本,而 MySQL 是單機部署的。即使這樣,TiKV 的效能表現還是高於 MySQL,而 etcd 與 MySQL 接近。
值得一提的是,上文中的測試使用的都是預設設定,並沒有對各個後設資料引擎去做特定的調優。使用者在使用時可以根據自己的需求和實踐經驗進行設定調整,可能會有不一樣的結果。
另一份測試是通過 JuiceFS 自帶的 bench 工具跑的,其執行的是作業系統讀寫檔案的介面,具體結果如下:
| Redis-Always | Redis-Everysec | TiKV | MySQL | etcd | |
|---|---|---|---|---|---|
| Write big file | 565.07 MiB/s | 556.92 MiB/s | 553.58 MiB/s | 557.93 MiB/s | 542.93 MiB/s |
| Read big file | 664.82 MiB/s | 652.18 MiB/s | 679.07 MiB/s | 673.55 MiB/s | 672.91 MiB/s |
| Write small file | 102.30 files/s | 105.80 files/s | 95.00 files/s | 87.20 files/s | 95.75 files/s |
| Read small file | 2200.30 files/s | 1894.45 files/s | 1394.90 files/s | 1360.85 files/s | 1017.30 files/s |
| Stat file | 11607.40 files/s | 15032.90 files/s | 3283.20 files/s | 5470.05 files/s | 2827.80 files/s |
| FUSE operation | 0.41 ms/op | 0.42 ms/op | 0.45 ms/op | 0.46 ms/op | 0.42 ms/op |
| Update meta | 3.63 ms/op | 3.19 ms/op | 7.04 ms/op | 8.91 ms/op | 4.46 ms/op |
從上表可以看到,讀寫大檔案時使用不同的後設資料引擎最後效能是差不多的。這是因為此時效能瓶頸主要在物件儲存的資料讀寫上,後設資料引擎之間雖然時延有點差異,但是放到整個業務讀寫的消耗上,這點差異幾乎可以忽略不計。當然,如果物件儲存變得非常快(比如都用本地全閃部署),那麼後設資料引擎的效能差異可能又會體現出來。另外,對於一些純後設資料操作(比如 ls,建立空檔案等),不同後設資料引擎的效能差別也會表現的比較明顯。
03-引擎選型的考慮要素
根據上文介紹的各引擎特點,使用者可以根據自己的情況去選擇合適的引擎。以下簡單分享下我們在做推薦時會建議使用者考慮的幾個要素。
評估需求:比如想使用 Redis,需要先評估能否接受少量的資料丟失,短期的服務中斷等。如果是儲存一些臨時資料或者中間資料的場景,那麼用 Redis 確實是不錯的選擇,因為它效能夠好,即使有少量的資料丟失,也不會造成很大的影響。但如果是要儲存一些關鍵資料, Redis 就不適用了。另外還得評估預期資料的規模,如果在 1 億檔案左右, Redis 可以承受;如果預期會有 10 億檔案,那麼顯然單機 Redis 是難以承載的。
評估硬體:比如能否連通外網,是使用託管的雲服務,還是在自己機房內私有部署。如果是私有部署,需要評估是否有足夠的硬體資源去部署一些相關的元件。無論是用哪一種後設資料引擎,基本上都要求有高速的 SSD 盤去執行,不然會對其效能有比較大的影響。
評估運維能力,這是很多人會忽視的,但是在我們來看這應該是最關鍵的因素之一。對於儲存系統來說,穩定性往往才是其上生產後的第一重點。使用者在選擇後設資料引擎的時候,應該先想想自己對它是不是熟悉,在出現問題時,能否快速定位解決;團隊內是否有足夠的經驗或精力去把控好這個元件。通常來說,我們會建議使用者在開始時選擇一個自己熟悉的資料庫是比較合適的。如果運維人員不足,那麼選擇 JuiceFS 公有云服務也確實是個省心的選項。
最後,分享下社群在使用後設資料引擎方面的一些統計資料。
- 目前為止, Redis 的使用者依然佔了一半以上,其次是 TiKV 和 MySQL,這兩類的使用者的數量佔比在逐步增長。
- 在執行的 Redis 叢集的最大檔案數大概是在 1.5 億,而且執行情況是比較穩定的,上文提到的推薦的 1 億檔案是建議值,並不是說無法超過 1 億。
- 整體數量規模 Top3,都是使用的 TiKV 而且都超過了 10 億檔案數量。現在最大的檔案系統的檔案數量是超了 70 億檔案,總容量超過了 15 PiB,這也從側面證明了 TiKV 在作為後設資料引擎時的擴充套件能力。我們自己內部測過使用 TiKV 作為後設資料引擎儲存 100 億檔案,系統仍能穩定地執行。所以如果你的整個叢集預期的規模會非常大,那麼TiKV 確實是一個很好的選擇。
04- 元數引擎遷移
文章的最後,為大家介紹後設資料引擎遷移。 隨著使用者業務的發展,企業對後設資料引擎的需求會發生變化,當用戶發現現有的後設資料引擎不合適了,可以考慮將後設資料遷移到另一個引擎中。 我們為使用者提供了完整的遷移方法,具體可以參考這個檔案。
這個遷移方法有一定的限制,首先只能遷移到空資料庫,暫時無法將兩個檔案系統直接合在一起;其次,需要停寫,因為資料量會比較大的情況下,很難線上將後設資料完整的遷移過來。要做到這點需要加許多限制,從實測來看速度會非常慢。因此,把整個檔案系統停掉再去做遷移是最穩妥的。如果說實在需要有一定的服務提供,可以保留唯讀掛載,使用者讀資料並不會影響整個後設資料引擎遷移的動作。
雖然社群提供了全套的遷移方法,但是還是需要提醒使用者,儘量提前對資料量的增長做好規劃,儘量不做遷移或儘早遷移。當要遷移的資料規模很大時,耗時也會變長,期間出問題的概率也會變大。
如有幫助的話歡迎關注我們專案 Juicedata/JuiceFS 喲! (0ᴗ0✿)