python-繪圖與視覺化
python 有許多視覺化工具,但本書只介紹Matplotlib。Matplotlib是一種2D的繪相簿,它可以支援硬拷貝和跨系統的互動,它可以在python指令碼,IPython的互動環境下、Web應用程式中使用。該專案是由John Hunter 於2002年啟動,其目的是為python構建MATLAB式的繪圖介面。如果結合使用一種GUI工具包(如IPython),Matplotlib還具有諸如縮放和平移等互動功能。它不僅支援各種作業系統上許多不同的GUI後端,而且還能將圖片匯出為各種常見的向量(vector)和光柵(raster)圖:PDF、SVG、JPG、PNG、BMP、GIF等。
1.Matplotlib 程式包
所謂「一圖勝千言」,我們很多時候需要通過視覺化的方式檢視、分析資料,雖然pandas中也有一些繪圖操作,但是相比較而言,Matplotlib在繪圖顯示效果方面更加絢麗。Pyplot為Matplotlib提供了一個方便的介面,我們可以通過pyplot對matplotlib進行操作,多數情況下pyplot的命令與MATLAB有些相似。
匯入Matplotlib包進行簡單的操作(此處需要安裝pip install matplotlib):
import matplotlib.pyplot as plt #首先定義兩個函數(正弦&餘弦) import numpy as np X = np.linspace(-np.pi,np.pi,256,endpoint=True) #-Π to +Π的256個值 C,S = np.cos(X),np.sin(X) plt.plot(X,C) plt.plot(X,S) #在ipython 的互動環境中需要這句才能顯示出來 plt.show()
2.繪圖命令的基本架構及其屬性設定
上面的例子我們可以看出,幾乎所有的屬性和繪圖的框架我們都選用預設設定。現在我們來看Pyplot 繪圖的基本框架是什麼,用過photoshop的人都知道,作圖時先要定義一個畫布,此處的畫布就是Figure,然後把其他素材「畫」到該Figure上。
(1)在Figure 上建立子plot,並設定屬性,
具體簡析和程式碼如下:
import numpy as np import matplotlib.pyplot as plt x = np.linspace(0,10,1000) #X軸資料 y1 = np.sin(x) #Y軸資料 y2 = np.cos(x**2) #Y軸資料 plt.figure(figsize=(8,4)) plt.plot(x,y1,label="$sin(x)$",color="red",linewidth=2) plt.plot(x,y2,"b--",label="$cos(x^2)$") #指定曲線的顏色和線形,如「b--」表示藍色虛線(b:藍色,-:虛線) plt.xlabel("Time(s)") plt.ylabel("Volt") plt.title("PyPlot First Example") #書上寫的是:plt.figure(figsize(8,4)) #注意:會報錯 name 'figsize' is not defined #這裡figsize是一個引數,並不是一個函數,給引數賦值中間需要加一個等號,寫為:plt.figure(figsize=(8,4)) #使用關鍵字引數可以指定所繪製的曲線的各種屬性: #label:給曲線指定一個標籤名稱,此標籤將在圖示中顯示。如果標籤字串的前後有字元「$」,則Matplotlib 會使用其內嵌的LaTex引擎將其顯示為數學公式 #color:指定曲線的顏色。顏色可以用如下方法表示 #英文單詞 #以「#」字元開頭的3個16進位制數,如「#ff0000」表示紅色。以0~1的RGB表示,如(1.0,0.0,0.0)也表示紅色 #linewidth:指定曲線的寬度,可以不是整數,也可以使用縮寫形式的引數名lw plt.ylim(-1.5,1.5) plt.legend() plt.show()
(2)在Figure上建立多個子plot
如果需要同時繪製多幅圖表的話,可以給Figure傳遞一個整數引數指定圖表的序號,如果所指定序號的繪圖物件已經存在的話,將不建立新的物件,而只是讓它成為當前繪圖物件,具體分析和程式碼如下:
import numpy as np import matplotlib.pyplot as plt fig1 =plt.figure(2) plt.subplot(211) #subplot(211)把繪圖區域等分為2行*1列共兩個區域 #然後在區域1(上區域)中建立一個軸物件 plt.subplot(212)#在區域2(下區域)建立一個軸物件 plt.show()

#我們還可通過命令再次拆分這些塊(相當於Word中拆分單元格的操作) f1 = plt.figure(5) plt.subplot(221) plt.subplot(222) plt.subplot(212) plt.subplots_adjust(left = 0.08,right = 0.95,wspace = 0.25,hspace = 0.45) #subplots_adjust的操作是類似網頁csv格式化中的邊距處理,左邊距離多少? #右邊邊距多少?這個取決於你需要繪製的大小和各個模組之間的間距。 plt.show()

(3)通過Axes設定當前物件plot的屬性
以上我們操作的是在Figure上繪製圖案,但是當我們繪製的圖案過多,又需要選取不同的小模組進行格式化設定時,Axes物件就能很好的解決這個問題。具體簡析和程式碼如下:
import numpy as np import matplotlib.pyplot as plt fig,axes = plt.subplots(nrows=2,ncols=2) #定一個2*2的plot plt.show()

#現在我們需要通過命令來操作每個plot(subplot),設定他們的title並刪除橫縱座標值 fig,axes =plt.subplots(nrows=2,ncols=2) axes[0,0].set(title="Upper Left") axes[0,1].set(title="Upper Right") axes[1,0].set(title="Lower Left") axes[1,1].set(title="Lower Right")
另外,實際來說,plot操作的底層操作就是Axes物件的操作,只不過如果我們不使用Axes而用plot操作時,它預設的是plot.subplot(111),也就是說plot其實是Axes的特例
(4)儲存Figure物件
最後一項操作就是儲存,我們繪製的目的是用在其他研究中,或者希望可以把研究結果儲存下來,此時需要的操作是save。具體簡析和程式碼如下:
import numpy as np import matplotlib.pyplot as plt plt.savefig("save_test.png",dpi=520) #預設畫素是dpi是80 #此處只是用了savefig屬性對Figure進行儲存
另外,除了上述的基本操作之外,Matplotlib還有其他的繪圖優勢,此處只是簡單介紹了它在繪圖時需要注意的事項。
3.Seaborn 模組介紹
前面我們簡單介紹了Matplotlib庫的繪圖功能和屬性設定,對於常規性的繪圖,使用pandas的API屬性研究較為透徹,幾乎沒有不能解決的問題。但是有的時候Matplotlib還是有它的不足之處,Matplotlib 自動化程度非常高,但是,掌握如何設定系統以便獲得一個吸引人的圖是相當困難的事。為了控制Matplotlib圖表的外觀,Seaborn 模組自帶許多客製化的主題和高階的介面。
3.1 未加Seaborn 模組的效果
具體簡析和程式碼如下:
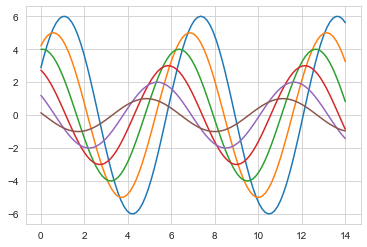
#有關於seaborn介紹 import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt np.random.seed(sum(map(ord,"aesthetics"))) #首先定義一個函數用來畫正弦函數,可幫助瞭解可以控制的不同風格引數 def sinplot(flip=1): x=np.linspace(0,14,100) for i in range(1,7): plt.plot(x,np.sin(x+i*.5)*(7-i)*flip) sinplot() plt.show()

#有關於seaborn介紹 import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt np.random.seed(sum(map(ord,"aesthetics"))) def sinplot(flip=1): x = np.linspace(0,14,100) for i in range(1,7): plt.plot(x,np.sin(x + i * .5) * (7-i) * flip) #轉換成Seaborn 模組,只需要引入seaborn模組 import seaborn as sns #不同之處在此 sinplot() plt.show()
使用seaborn的優點有:1.seaborn預設淺灰色背景與白色格線的靈感來源於Matplotlib,卻比matplotlib的顏色更加柔和;2.seaborn把繪圖風格引數與資料引數分開設定。seaborn有兩組函數對風格進行控制:axes_style()/set_style()函數和plotting_context()/set_context()函數。axes_style()函數和plotting_context()函數返回引數字典,set_style()函數和set_context()函數設定Matplotlib。
(1)使用set_style()函數
具體通過cording檢視效果:
import seaborn as sns sns.set_style("ticks") sns.set_style("whitegrid") sinplot() plt.show() #seaborn 有5種預定義的主題: #darkgrid (灰色背景+白網格) #whitegrid(白色背景+黑網格) #dark (僅灰色背景) #white (僅白色背景) #ticks (座標軸帶刻度) #預設的主題是darkgrid,修改主題可以使用set_style()函數
(2)使用set_context()函數
具體通過coding檢視效果:
import seaborn as sns sns.set_context("paper") sinplot() plt.show() #上下文(context)可以設定輸出圖片的大小尺寸(scale) #seaborn中預定義的上下文有4種:paper、notebook、talk和poster。 預設使用notebook上下文

(3)使用Seaborn「耍酷」
然而seaborn 不僅能夠用來更改背景顏色,或者改變畫布大小,還有其他很多方面的用途,比如下面這個例子:
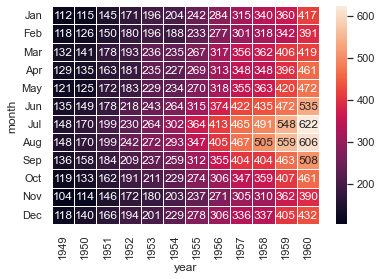
import seaborn as sns sns.set() #通過載入sns自帶資料庫中的資料(具體資料可以不關心) flights_long = sns.load_dataset("flights") flights = flights_long.pivot("month","year","passengers") #使用每個單元格中的資料值繪製一個熱圖heatmap sns.heatmap(flights,annot=True,fmt="d",linewidths=.5) plt.show()
4.描述性統計圖形概覽
描述性統計是藉助圖表或者總結性的數值來描述資料的統計手段。資料探勘工作的資料分析階段,我們可藉助描述性統計來描述或總結資料的基本情況,一來可以梳理自己的思維,二來可以更好地向他人展示資料分析結果。數值分析的過程中,我們往往要計算出資料的統計特徵,用來做科學計算的Numpy和SciPy工具可以滿足我們的需求。Matplotlib工具可用來繪製圖,滿足圖分析的需求。
4.1製作資料
資料是自己製作的,主要包括個人身高、體重及一年的借閱圖書量(之所以自己製作資料是因為不是每份真實的資料都可以進行接下來的分析,比如有些資料就不能繪製餅圖,另一個角度也說明,此處舉例的資料其實沒有實際意義,只是為了分析而舉例,但是不代表在具體的應用中這些分析不能發揮作用)。
另外,以下的資料顯示都是在Seaborn庫的作用下體現的效果。
#案例分析(結合圖書情報學,比如借書量) from numpy import array from numpy.random import normal def getData(): heights = [] weights = [] books = [] N =10000 for i in range(N): while True: #身高服從均值為172,標準差為6的正態分佈 height = normal(172,6) if 0<height:break while True: #體重由身高作為自變數的線性迴歸模型產生,誤差服從標準正態分佈 weight = (height-80)*0.7 + normal(0,1) if 0 < weight:break while True: #借閱量服從均值為20,標準差為5的正態分佈 number = normal(20,5) if 0<= number and number<=50: book = "E"if number <10 else("D"if number<15 else ("C"if number<20 else("B"if number<25 else "A"))) break heights.append(height) weights.append(weight) books.append(book) return array(heights),array(weights),array(books) heights,weights,books =getData()
4.2 頻數分析
(1)定性分析
柱狀圖和餅形圖是對定性資料進行頻數分析的常用工具,使用前需將每一類的頻數計算出來。
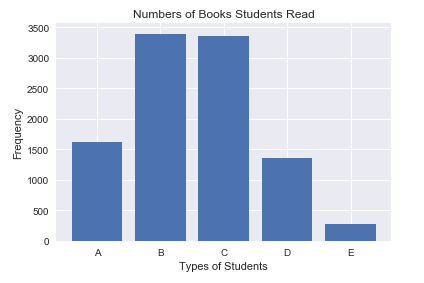
①柱狀圖。柱狀圖是以柱的高度來指代某種型別的頻數,使用Matplotlib對圖書借閱量這一定性變數繪製柱狀圖的程式碼如下:
from matplotlib import pyplot #繪製柱狀圖 def drawBar(books): xticks=["A","B","C","D","E"] bookGroup ={ } #對每一類借閱量進行頻數統計 for book in books: bookGroup[book] = bookGroup.get(book,0) + 1 #建立柱狀圖 #第一個引數為柱的橫座標 #第二個引數為柱的高度 #引數align為柱的對齊方式,以第一個引數為參考標準 pyplot.bar(range(5),[bookGroup.get(xtick,0) for xtick in xticks],align="center") #設定柱的文字說明 #第一個引數為文字說明的橫座標 #第二個引數為文字說明的內容 pyplot.xticks(range(5),xticks) #設定橫座標的文字說明 pyplot.xlabel("Types of Students") #設定縱座標的文字說明 pyplot.ylabel("Frequency") #設定標題 pyplot.title("Numbers of Books Students Read") #繪圖 pyplot.show() drawBar(books)
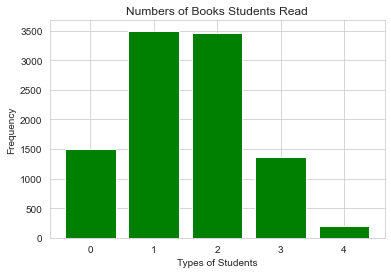
import matplotlib.pyplot as plt num_list = [1506,3500,3467,1366,200] pyplot.xlabel("Types of Students") pyplot.ylabel("Frequency") pyplot.title("Numbers of Books Students Read") plt.bar(range(len(num_list)), num_list,color="green") import seaborn as sns sns.set_style("whitegrid") plt.show()
②餅形圖。餅形圖是以扇形的面積來指代某種型別的頻率,使用Matplotlib對圖書借閱量這一定性變數繪製餅形圖的程式碼如下:
import numpy as np import matplotlib.mlab as mlab import matplotlib.pyplot as plt labels=['A','B','C','D','E'] X=[257,145,32,134,252] fig = plt.figure() plt.pie(X,labels=labels,autopct='%1.1f%%') #畫餅圖(資料,資料對應的標籤,百分數保留兩位小數點) plt.title("Numbers of Books Student Read") plt.show()
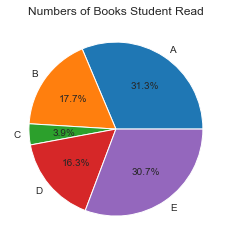
(2)定量分析
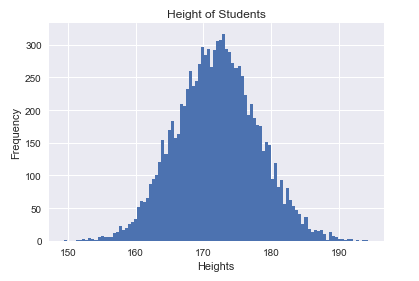
直方圖類似於柱狀圖,是用柱的高度來指代頻數,不同的是其將定量資料劃分為若干連續的區間,在這些連續的區間上繪製柱。
①直方圖。使用Matplotlib對身高這一定量變數繪製直方圖的程式碼如下:
#繪製直方圖 def drawHist(heights): #建立直方圖 #第一個引數為待繪製的定量資料,不同於定性資料,這裡並沒有實現進行頻數統計 #第二個引數為劃分的區間個數 pyplot.hist(heights,100) pyplot.xlabel('Heights') pyplot.ylabel('Frequency') pyplot.title('Height of Students') pyplot.show() drawHist(heights)
累積曲線:使用Matplotlib對身高這一定量變數繪製累積曲線的程式碼如下:
#繪製累積曲線 def drawCumulativaHist(heights): #建立累積曲線 #第一個引數為待繪製的定量資料 #第二個引數為劃分的區間個數 #normal引數為是否無量綱化 #histtype引數為‘step’,繪製階梯狀的曲線 #cumulative引數為是否累積 pyplot.hist(heights,20,normed=True,histtype='step',cumulative=True) pyplot.xlabel('Heights') pyplot.ylabel('Frequency') pyplot.title('Heights of Students') pyplot.show() drawCumulativaHist(heights)

(3)關係分析
散點圖。在散點圖中,分別以自變數和因變數作為橫座標。當自變數與因變數線性相關時,散點圖中的點近似分佈在一條直線上。我們以身高作為自變數,體重作為因變數,討論身高對體重的影響。使用Matplotlib繪製散點圖的程式碼如下:
#繪製散點圖 def drawScatter(heights,weights): #建立散點圖 #第一個引數為點的橫座標 #第二個引數為點的縱座標 pyplot.scatter(heights,weights) pyplot.xlabel('Heights') pyplot.ylabel('Weight') pyplot.title('Heights & Weight of Students') pyplot.show() drawScatter(heights,weights)
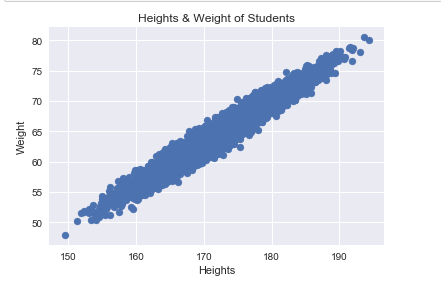
(4)探索分析
箱型圖。在不明確資料分析的目標時,我們對資料進行一些探索性的分析,可以知道資料的中心位置、發散程度及偏差程度。使用Matplotlib繪製關於身高的箱型圖程式碼如下:
#繪製箱型圖 def drawBox(heights): #建立箱型圖 #第一個引數為待繪製的定量資料 #第二個引數為資料的文字說明 pyplot.boxplot([heights],labels=['Heights']) pyplot.title('Heights of Students') pyplot.show() drawBox(heights)

注:
① 上四分位數與下四分位數的差叫四分位差,它是衡量資料發散程度的指標之一
② 上界線和下界線是距離中位數1.5倍四分位差的線,高於上界線或者低於下界線的資料為異常值
描述性統計是容易操作、直觀簡潔的資料分析手段。但是由於簡單,對於多元變數的關係難以描述。現實生活中,自變數通常是多元的:決定體重的不僅有身高,還有飲食習慣、肥胖基因等因素。通過一些高階的資料處理手段,我們可以對多元變數進行處理,例如,特徵工程中,可以使用互資訊方法來選擇多個對因變數有較強相關性的自變數作為特徵,還可以使用主成分分析法來消除一些冗餘的自變數來降低運算複雜度。
參考書目:《資料館員的python簡明手冊》