SQL抽象語法樹及改寫場景應用
1 背景
我們平時會寫各種各樣或簡單或複雜的sql語句,提交後就會得到我們想要的結果集。比如sql語句,」select * from t_user where user_id > 10;」,意在從表t_user中篩選出user_id大於10的所有記錄。你有沒有想過從一條sql到一個結果集,這中間經歷了多少坎坷呢?
2 SQL引擎
從MySQL、Oracle、TiDB、CK,到Hive、HBase、Spark,從關係型資料庫到巨量資料計算引擎,他們大都可以藉助SQL引擎,實現「接受一條sql語句然後返回查詢結果」的功能。
他們核心的執行邏輯都是一樣的,大致可以通過下面的流程來概括:

中間藍色部分則代表了SQL引擎的基本工作流程,其中的詞法分析和語法分析,則可以引申出「抽象語法樹」的概念。
3 抽象語法樹
3.1 概念
高階語言的解析過程都依賴於解析樹(Parse Tree),抽象語法樹(AST,Abstract Syntax Tree)是忽略了一些解析樹包含的一些語法資訊,剝離掉一些不重要的細節,它是原始碼語法結構的一種抽象表示。以樹狀的形式表現程式語言的結構,樹的每個節點ASTNode都表示原始碼中的一個結構;AST在不同語言中都有各自的實現。
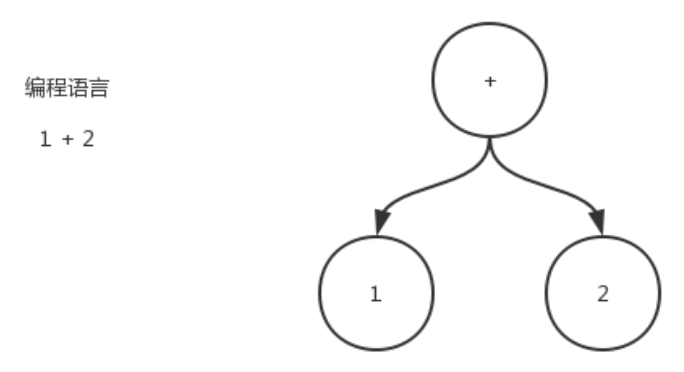
解析的實現過程這裡不去深入剖析,重點在於當SQL提交給SQL引擎後,首先會經過詞法分析進行「分詞」操作,然後利用語法解析器進行語法分析並形成AST。
下圖對應的SQL則是「select username,ismale from userInfo where age>20 and level>5 and 1=1」;

這棵抽象語法樹其實就簡單的可以理解為邏輯執行計劃了,它會經過查詢優化器利用一些規則進行邏輯計劃的優化,得到一棵優化後的邏輯計劃樹,我們所熟知的「謂詞下推」、「剪枝」等操作其實就是在這個過程中實現的。得到邏輯計劃後,會進一步轉換成能夠真正進行執行的物理計劃,例如怎麼掃描資料,怎麼聚合各個節點的資料等。最後就是按照物理計劃來一步一步的執行了。
3.2 ANTLR4
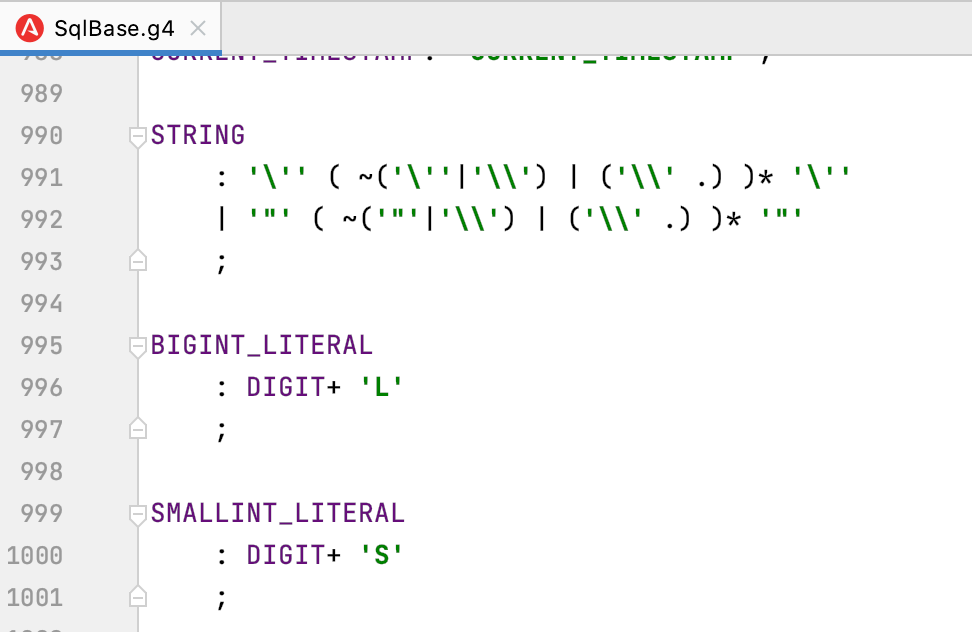
解析(詞法和語法)這一步,很多SQL引擎採用的是ANTLR4工具實現的。ANTLR4採用的是構建G4檔案,裡面通過正規表示式、特定語法結構,來描述目標語法,進而在使用時,依賴語法字典一樣的結構,將SQL進行拆解、封裝,進而提取需要的內容。下圖是一個描述SQL結構的G4檔案。
3.3 範例
3.2.1 SQL解析
在java中的實現一次SQL解析,獲取AST並從中提取出表名。
首先引入依賴:
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-runtime</artifactId>
<version>4.7</version>
</dependency>
在IDEA中安裝ANTLR4外掛;
範例1,解析SQL表名。
使用外掛將描述MySQL語法的G4檔案,轉換為java類(G4檔案忽略)。
類的結構如下:

其中SqlBase是G4檔名轉換而來,SqlBaseLexer的作用是詞法解析,SqlBaseParser是語法解析,由它生成AST物件。HelloVisitor和HelloListener:進行抽象語法樹的遍歷,一般都會提供這兩種模式,Visitor存取者模式和Listener監聽器模式。如果想自己定義遍歷的邏輯,可以繼承這兩個介面,實現對應的方法。

讀取表名過程,是重寫SqlBaseBaseVisitor的幾個關鍵方法,其中TableIdentifierContext是表定義的內容;
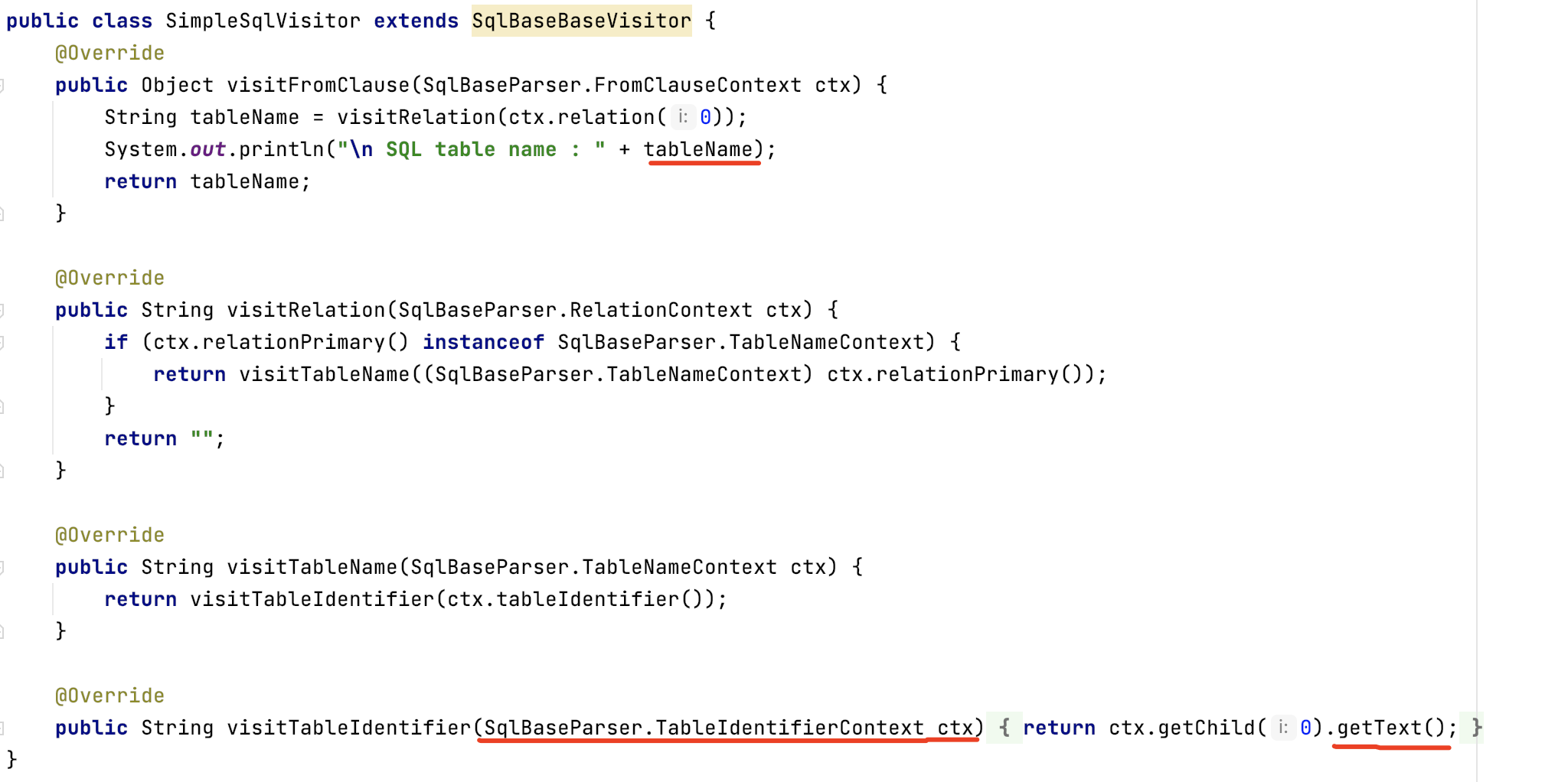
SqlBaseParser下還有SQL其他「詞語」的定義,對應的就是G4檔案中的各類描述。比如TableIdentifierContext對應的是G4中TableIdentifier的描述。
3.2.2 字串解析
上面的SQL解析過程比較複雜,以一個簡單字串的解析為例,瞭解一下ANTLR4的邏輯。
1)定義一個字串的語法:Hello.g4

2)使用IDEA外掛,將G4檔案解析為java類

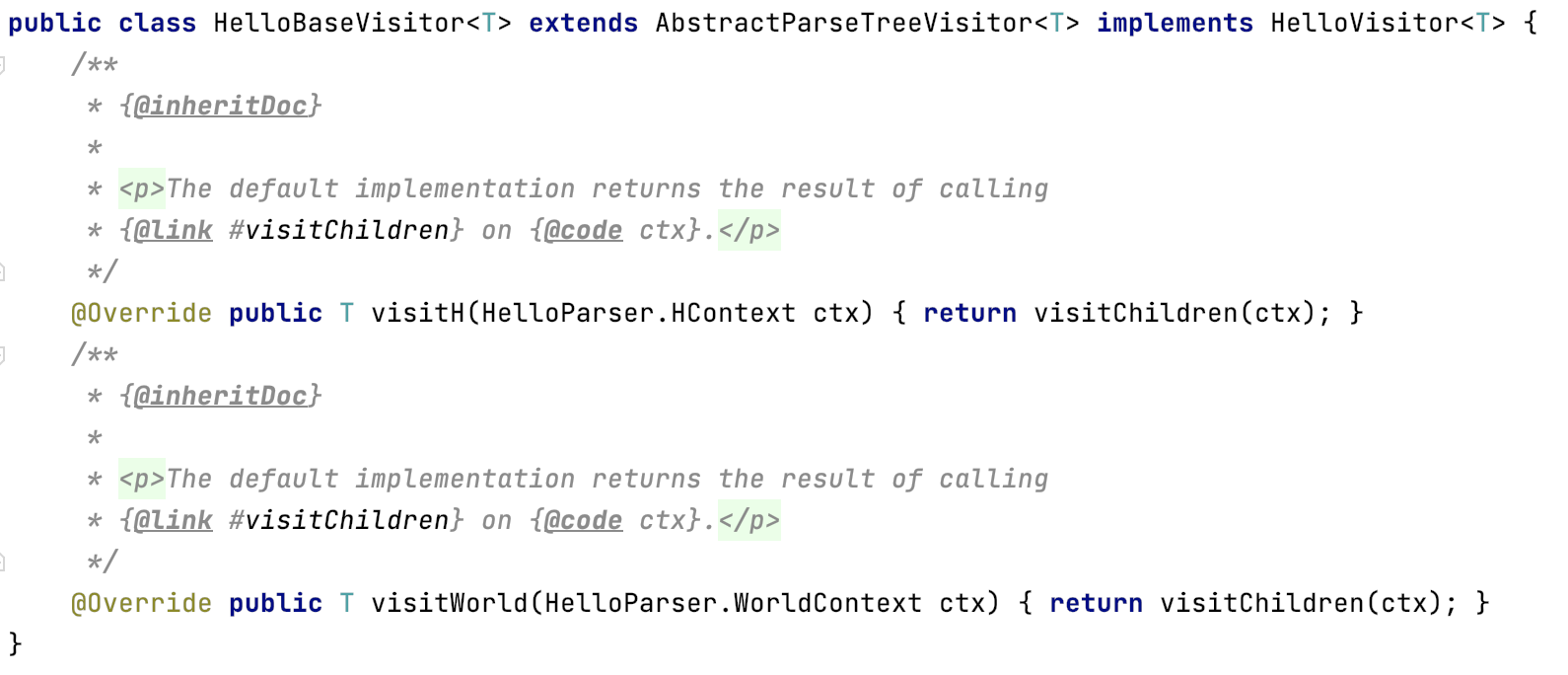
3)語法解析類HelloParser,內容就是我們定義的h和world兩個語法規則,裡面詳細跳脫了G4檔案的內容。

4)HelloBaseVisitor是採用存取者模式,開放出來的介面,需要自行實現,可以獲取xxxParser中的規則資訊。
5)編寫測試類,使用解析器,識別字串「hi abc」:

6)偵錯後發現命中規則h,解析為Hi和abc兩部分。

7)如果是SQL的解析,則會一層層的獲取到SQL中的各類關鍵key。
4 SqlParser
利用ANTLR4進行語法解析,是比較底層的實現,因為Antlr4的結果,只是簡單的文法解析,如果要進行更加深入的處理,就需要對Antlr4的結果進行更進一步的處理,以更符合我們的使用習慣。
利用ANTLR4去生成並解析AST的過程,相當於我們在寫rpc框架前,先去實現一個netty。因此在工業生產中,會直接採用已有工具來實現解析。
Java生態中較為流行的SQL Parser有以下幾種(此處摘自網路):
- fdb-sql-parser 是FoundationDB在被Apple收購前開源的SQL Parser,目前已無人維護。
- jsqlparser 是基於JavaCC的開源SQL Parser,是General SQL Parser的Java實現版本。
- Apache calcite 是一款開源的動態資料管理框架,它具備SQL解析、SQL校驗、查詢優化、SQL生成以及資料連線查詢等功能,常用於為巨量資料工具提供SQL能力,例如Hive、Flink等。calcite對標準SQL支援良好,但是對傳統的關係型資料方言支援度較差。
- alibaba druid 是阿里巴巴開源的一款JDBC資料庫連線池,但其為監控而生的理念讓其天然具有了SQL Parser的能力。其自帶的Wall Filer、StatFiler等都是基於SQL Parser解析的AST。並且支援多種資料庫方言。
Apache Sharding Sphere(原噹噹Sharding-JDBC,在1.5.x版本後自行實現)、Mycat都是國內目前大量使用的開源資料庫中介軟體,這兩者都使用了alibaba druid的SQL Parser模組,並且Mycat還開源了他們在選型時的對比分析Mycat路由新解析器選型分析與結果.
4.1 應用場景
當我們拿到AST後,可以做什麼?
- 語法稽核:根據內建規則,對SQL進行稽核、合法性判斷。
- 查詢優化:根據where條件、聚合條件、多表Join關係,給出索引優化建議。
- 改寫SQL:對AST的節點進行增減。
- 生成SQL特徵:參考JIRA的慢SQL工單中,生成的指紋(不一定是AST方式,但AST可以實現)。
4.2 改寫SQL
提到改寫SQL,可能第一個思路就是在SQL中新增預留位置,再進行替換;再或者利用正則匹配關鍵字,這種方式侷限性比較大,而且從安全形度不可取。
基於AST改寫SQL,是用SQL字串生成AST,再對AST的節點進行調整;通過遍歷Tree,拿到目標節點,增加或修改節點的子節點,再將AST轉換為SQL字串,完成改寫。這是在滿足SQL語法的前提下實現的安全改寫。
以Druid的SQL Parser模組為例,利用其中的SQLUtils類,實現SQL改寫。
4.2.1 新增改寫

1)原始SQL

2)實際執行SQL

4.2.2 查詢改寫
前面省略了Tree的遍歷過程,需要識別諸如join、sub-query等語法

1)簡單join查詢
- 原始SQL

- 實際執行SQL

2)join查詢+隱式where條件
- 原始SQL
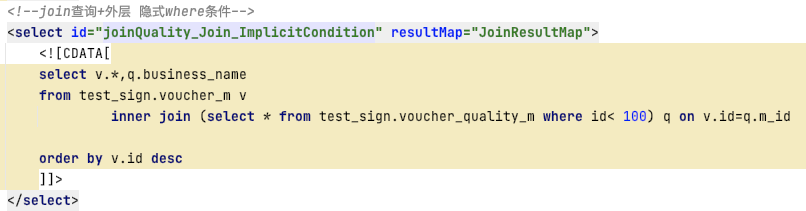
- 實際執行SQL
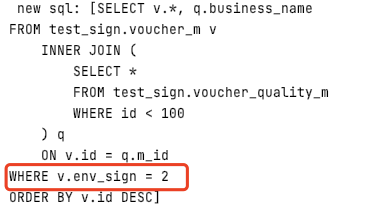
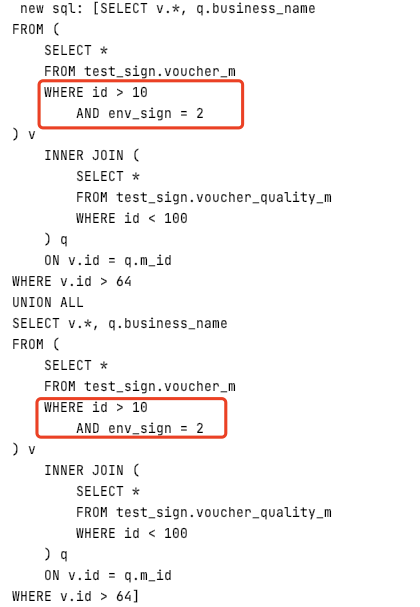
3)union查詢+join查詢+子查詢+顯示where條件
- 原始SQL
(unionQuality_Union_Join_SubQuery_ExplicitCondition)

- 實際執行SQL
5 總結
本文是基於環境隔離的技術預研過程產生的,其中改寫SQL的實現,是資料庫在資料隔離上的一種嘗試。
可以讓開發人員無感知的情況下,以外掛形式,在SQL提交到MySQL前實現動態改寫,只需要在資料表上增加欄位、標識環境差異,後續CRUD的SQL都會自動增加標識欄位(flag=’預發’、flag=’生產’),所操作的資料只能是當前應用所在環境的資料。
作者:耿宏宇