謠言檢測(PSIN)——《Divide-and-Conquer: Post-User Interaction Network for Fake News Detection on Social Med
論文資訊
論文標題:Divide-and-Conquer: Post-User Interaction Network for Fake News Detection on Social Media
論文作者:Erxue Min, Yu Rong, Yatao Bian, Tingyang Xu, Peilin Zhao, Junzhou Huang,Sophia Ananiadou
論文來源:2022,WWW
論文地址:download
論文程式碼:download
Background
挑戰:
(1) 謠言檢測涉及眾多型別的實體和關係,需要一些方法來建模異質性;
(2) 社交媒體中的話題出現了分佈變化,顯著降低了虛假新聞的效能;
(3) 現有虛假新聞資料集通常缺乏較大規模、話題多樣性和使用者的社交關係;
基於文字的謠言檢測方法存在如下兩個問題:
(1) 首先,在新聞的社會背景下的資訊是複雜的和異構的;
(2) 其次是分佈偏移問題——訓練分佈不同於測試分佈;
分佈偏移例子:如虛假新聞分類器是在 包含政治、體育、娛樂等普通主題的標記資料進行訓練的,但是在測試集上出現了出現了諸如「黑天鵝事件」的新主題。
貢獻:
-
- We construct and publicize a new fake news dataset with social context named MC-Fake2 , which contains 27,155 news events in 5 topics, and their social context composed of 5 million posts, 2 million users and induced social graph with 0.2 billion edges.
- We propose a novel Post-User Interaction Network (PSIN), which applies divide-and-conquer strategy to model the heterogeneous relations. Specifically, we integrate the post-post, user-user and post-user subgraphs with three variants of Graph Attention Networks based on their intrinsic characteristics. Additionally, we employ an additionally adversarial topic discriminator to learn topic-agnostic features for veracity classification.
- We evaluate our proposed model on the curated dataset in two settings: in-topic split and out-of-topic split. The superior results of our model in both settings reveal the effectiveness of the proposed method.
2 Related work
2.1 Fake News Datasets
- BuzzFeedNews specializes in political news published on Facebook during the 2016 U.S. Presidential Election.
- LIAR collects 12.8K short statements with manual labels from the political fact-checking website.
- FA-KES consists of 804 articles around Syrian war.
- CREDBANK contains about 1000 news events and 60 million tweets, labeled by Amazon mechanical Turk.
- Twitter15 contains 778 reported events between March 2015 to December 2015, with 1 million posts from 500k users.
- FakeNewsNet is a data repository with news content and related posts, containing political news and entertainment news which are checked by politifact and gossiocop.
- FakeHealth is collected from healthcare information review website Health News Review, it contains over 2000 news articles, 500k posts and 27k user profiles, along with user networks.
- COAID collects 1,896 news, 183,654 related user engagements, 516 social platform posts about COVID-19, and ground truth labels.
- FakeCovid is a multilingual cross-domain dataset of 5,182 fact-checked news article for COVID-19 from 92 different fact-checking websites.
- MM-COVID is a multilingual and multidimensional COVID-19 fake news data repository, containing 3,981 pieces of fake news content and 7,192 trustworthy information from 6 different languages.
2.2 Social Context-based Fake News Detection
劃分為三類:
-
- Sequential Modeling [20, 24, 30, 52]
- Explicit responding path modeling [4, 19, 26, 47]
- Implicit attention modeling
3 Problem statement
假新聞資料集定義:$\mathbf{D}=\left\{\mathbf{T}, G^{U}, G^{U P}\right\}$
News event 定義:$T_{i}=\left\{p_{1}^{i}, p_{2}^{i}, \ldots p_{M_{i}}^{i}, G_{i}^{P}, u_{1}^{i}, u_{2}^{i}, \ldots u_{N_{i}}^{i}, G_{i}^{U}, G_{i}^{U P}\right\}$
News event can be considered as a heterogeneous graph two types of nodes: post and user, and three types of edges: post-post, user-user and user-post.as shown in Figure 2:

在本文的資料集中,每一個 $T_i$ 均有一個主題標籤 $y_{i}^{C} \in\{ Politics, Entertainment, Health, Covid-19, Sryia War\}$ 和 groundtruth veracity label $y_{i}^{V} \in\{F, R\}$ (i.e. Fake, news or Real news)。
4 Methodlogy
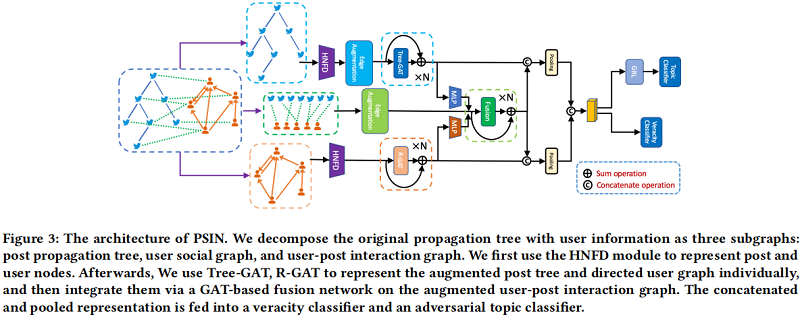
4.1 Hybrid Node Feature Encoder
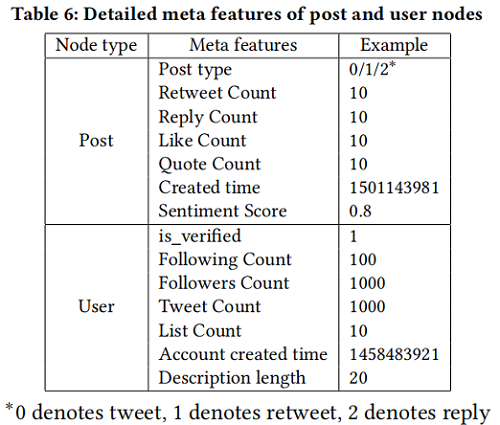
對於 event $i$ $T_{i}$,節點集合 $\left\{p_{1}^{i}, p_{2}^{i}, \ldots p_{M_{i}}^{i}, u_{1}^{i}, u_{2}^{i}, \ldots u_{N_{i}}^{i}\right\}$,每個節點擁有 textual features 和 meta features。Post 和 user 的 meta feature 如下:
4.1.1 Text Content Encoding
常用的文字編碼方式:TF-IDF、CNN、LSTM、Transformer、BERT。
本文的文字詞向量通過 CNN 獲得,設 $c_j$ 為第 $j$ 個節點提取的文字嵌入。
4.1.2 Meta feature based Gate Mechanism
文字嵌入壓縮了重要的語意資訊,然而,每個節點的重要性是不同的。直觀地說,轉發數或關注者數等元特徵(meta feature)意味著受歡迎程度和社會關注,這可用來推斷給定節點的重要性。因此,設計了一個基於元特徵的門機制來過濾文字特徵,如 Figure 4 所示。
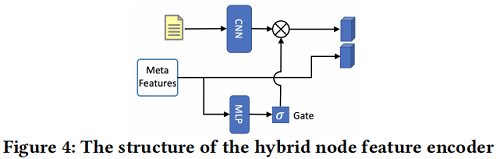
具體來說,給定第 $j$ 個節點的元特徵 $m_j$,我們計算其貢獻分數,以衡量第 $j$ 個節點的文字特徵的重要性:
$g_{j}=\sigma\left(\mathbf{W}^{m} \mathbf{m}_{j}+\mathbf{b}^{m}\right)$
其中 $\sigma$ 是一個啟用函數,它將輸入對映到 $[0,1]$ 中,$\mathbf{W}^{m}$ 和 $\mathbf{b}^{m}$ 都是可訓練的引數。最後,第 $j$ 個節點的表示如下:
$\mathbf{n}_{j}=g_{j} \mathbf{c}_{j} \oplus \mathbf{m}_{j}$
其中,$\oplus$ 是連線操作符。因此,給定輸入序列 $\left\{p_{1}, p_{2}, \ldots p_{M}, u_{1}, u_{2}, \ldots u_{N}\right\}$ 對於第 $i$ 個新聞事件,我們得到貼文特徵矩陣 $\mathbf{P}=\left\{\mathbf{h}_{1}^{P}, \mathbf{h}_{2}^{P}, \ldots, \mathbf{h}_{M}^{P}\right\}$ 和使用者特徵矩陣 $\mathbf{U}=\left\{\mathbf{h}_{1}^{U}, \mathbf{h}_{2}^{U}, \ldots \mathbf{h}_{N}^{U}\right\}$。
4.2 Post Tree Modeling
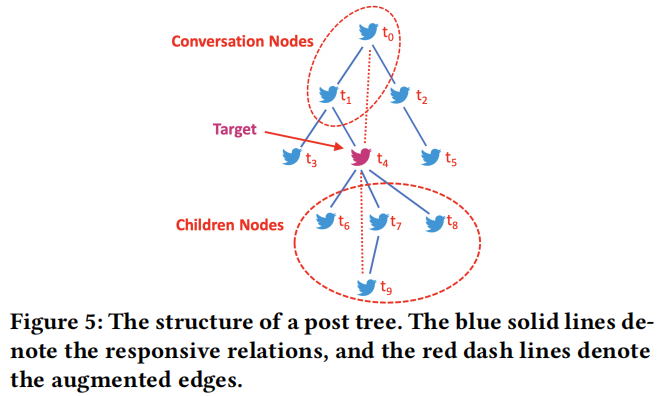
採用圖結構建模的原因:
1:貼文深層之後任然存在聯絡,尤其是對於源推文極具爭議性的時候;
2:回覆貼對於源帖的密切回覆;
本文提出的圖結構資訊建模的方法是:Tree-GAT ,包括兩個模組:-
- Edge Augmentation
- Depth-aware Graph Attention
設 $A^{P}$ 為第 $i$ 個新聞事件的傳播樹 $G^{P}$ 的鄰接矩陣,$A_{i j}^{P}=1$ 表示第 $i$ 個貼文迴應了第 $j$ 個貼文。我們計算增廣鄰接矩陣 $\widehat{A}^{P}$ 如下:
$\begin{array}{l}A_{\mathrm{BU}}^{P}=\sum\limits_{d=1}^{d_{\max }}\left(A^{P}\right)^{d}\\A_{\mathrm{TD}}^{P}=A_{B U}^{P}{ }^{\top} \\\widehat{A}^{P}=A_{B U}^{P}+A_{T D}^{P}\end{array}$
其中,$d_{max}$ 為新聞事件中傳播樹的最大深度。
Depth-aware Graph Attention
給定增強的鄰接矩陣 $\widehat{A}^{P}$ 和貼文特徵矩陣 $\mathbf{H}^{0}=\left\{\mathbf{h}_{1}^{0}, \mathbf{h}_{2}^{0}, \ldots, \mathbf{h}_{M}^{0}\right\}$,本文使用 GATv2 作為 backbone
$e_{i j}=\mathbf{a}^{\top} \operatorname{Leaky} \operatorname{ReLU}\left(\mathbf{W} \cdot\left[\mathbf{h}_{i} \| \mathbf{h}_{j}\right]\right) $
${\large \alpha_{i j}=\operatorname{Softmax}\left(e_{i j}\right)=\frac{\exp \left(e_{i j}\right)}{\sum\limits _{k \in \mathcal{N}(i)} \exp \left(e_{i k}\right)}} $
-
- $\mathbf{a} \in \mathbb{R}^{d}$ is a parameter vector
- $\mathbf{W}=\left[\mathbf{W}_{s} \| \mathbf{W}_{d}\right]$ with $\mathbf{W}_{s}$ and $\mathbf{W}_{d}$ are parameter matrices to project source nodes and target nodes
- $e_{i j}$ and $\alpha_{i j}$ are unnormalized and normalized attention
遠端節點中存在語意漂移,故對注意力進行修改:
$e_{i j}=\mathbf{a}^{\top} \operatorname{LeakyReLU}\left(\mathbf{W} \cdot\left[\mathbf{h}_{i} \| \mathbf{h}_{j}\right]+\mathbf{v}[d(i, j)]\right)$
其中,$d(i, j)=d_{i}-d_{j}+d_{\max }$ ,$d_{i}$ 為第 $i$ 個節點的深度,$d_{max}$ 為所有樹的最大深度,$\mathbf{v}[d(i, j)] \in \mathbb{R}^{d}$ 是可訓練的位置向量,使網路能夠感知節點之間的相對位置(相對時間順序和相對深度)。此外,還在更新方程中新增了殘差連線:
${\large \mathbf{h}_{i}^{\prime}=\sigma\left(\sum\limits_{j \in \mathcal{N}(i)} \alpha_{i j} \mathbf{W}_{d} \mathbf{h}_{j}\right)+\mathbf{h}_{i}} $
假設 $\mathbf{H}^{0}=\mathbf{P}$ ,經過 $K$ 層 Tree-GAT ,有 $\widehat{\mathbf{P}}=\mathbf{H}^{K}=\left\{\widehat{\mathbf{h}}_{1}^{P}, \widehat{\mathbf{h}}_{2}^{P}, \ldots, \widehat{\mathbf{h}}_{M}^{P}\right\}$ 。
$\begin{array}{l}\mathrm{A}^{\text {friend }}&=&\mathrm{A}^{U} \cdot \mathrm{A}^{U^{\top}}\\\mathrm{A}^{\text {follow }} &=&\mathrm{A}^{U}-\mathrm{A}^{\text {friend }} \\\mathrm{A}^{\text {followed }} &=&\mathrm{A}^{U^{\top}}-\mathrm{A}^{\text {friend }}\end{array}$
為了區分訊息傳遞過程中的不同邊,我們提出了 Relational Graph Attention Network(R-GAT),該方法計算節點之間的注意得分如下:
$e_{i j}=\mathbf{a}_{r(i, j)}^{\top} \operatorname{LeakyReLU}\left(\mathbf{W} \cdot\left[\mathbf{h}_{i} \| \mathbf{h}_{j}\right]\right)$
其中,
$r(i, j) \in\{0,1,2\}$ 代表三種邊的關係,$\mathbf{a}_{0}, \mathbf{a}_{1}, \mathbf{a}_{2}= a_{0}+a_{1}$ 是三個不同向量引數分別代表了 follow relations,followed relations 和 friend relations。
和 post 節點類似進行標準化和更新步驟(帶殘差)。
4.4 Post-User Interaction
使用者和貼文之間的互動也為準確性檢測提供了線索。例如,有一些異常的賬戶可能會在一個新聞事件中釋出數百條貼文。這些賬戶可以是出於某些目的而旨在傳播資訊的機器人,也可以是希望中斷傳播過程的事實核查賬戶。後傳播樹建模和使用者網路建模都不能捕獲這樣的模式。為此,我們提出了一個 user-post fusion layer 來豐富使用者節點和貼文節點的表示。
我們根據使用者的行為構建了一個使用者釋出圖。如 Figure 6 所示,我們假設給定貼文的傳播者可以表達其產生的社會效應模式,而使用者傳播的貼文描述了使用者的特徵。基於此假設,我們計算了 bipartite user-post graph 的鄰接矩陣 $\widehat{\mathrm{A}}^{U P} \in \mathbb{R}^{N \times M}$ 為:
$\widehat{\mathrm{A}}^{U P}=\mathrm{A}^{U P}\left(\sum_{d=1}^{d_{\max }}\left(\mathrm{A}^{P}\right)^{d}\right)$
其中,$\mathrm{A}^{U P} \in \mathbb{R}^{N \times M}$ 為 is-author graph $G^{UP}$ 的鄰接矩陣,$\mathrm{A}^{P}$ 是上述增強圖的鄰接矩陣。為了在 user-post graph 中使用 GNN,我們首先使用兩個投影矩陣將它們的表示投影到一個統一的空間中:
$\mathbf{H}^{P}=\mathbf{W}^{P} \widehat{\mathbf{P}}, \mathbf{H}^{U}=\mathbf{W}^{U} \widehat{\mathbf{U}}$
然後,我們將該圖視為齊次圖,得到 $\mathbf{H}= Concat \left(\mathrm{H}^{P}, \mathrm{H}^{U}\right)$。鄰接矩陣的定義為:
$\tilde{A}=\left[\begin{array}{cc}\mathrm{A}^{U P^{T}} & 0 \\0 & \mathrm{~A}^{U P}\end{array}\right]$
我們使用標準的 GATv2 來表示節點,每個層的更新規則是:
$\mathrm{H}^{\prime}=\mathrm{GATv} 2(\mathrm{H}, \widetilde{\mathrm{A}})+\mathrm{H} \text {. }$
我們在 post-user interaction layers 之後得到 $\widetilde{\mathbf{H}}=\left\{\widetilde{\mathbf{h}}_{1}^{P}, \widetilde{\mathbf{h}}_{2}^{P}, \ldots, \widetilde{\mathbf{h}}_{M}^{P}, \widetilde{\mathbf{h}}_{1}^{U}, \widetilde{\mathbf{h}}_{2}^{U}, \ldots, \widetilde{\mathbf{h}}_{N}^{U}\right\}$ 。然後我們獲得貼文和使用者的最終表示為 $\mathbf{P}^{\prime}=\left\{\mathbf{h}_{1}^{P^{\prime}}, \mathbf{h}_{2}^{P^{\prime}}, \ldots, \mathbf{h}_{M}^{P^{\prime}}\right\}$,$\mathbf{U}^{\prime}=\left\{\mathbf{h}_{1}^{U^{\prime}}, \mathbf{h}_{2}^{U^{\prime}}, \ldots, \mathbf{h}_{N}^{U^{\prime}}\right\}$,其中,$\mathbf{h}_{i}^{P^{\prime}}=\operatorname{Concat}\left(\widehat{\mathbf{h}}_{i}^{P}, \widetilde{\mathbf{h}}_{i}^{P}\right)$ 和 $\mathbf{h}_{i}^{U^{\prime }}=\operatorname{Concat}\left(\widehat{\mathbf{h}}_{i}^{U}, \widetilde{\mathbf{h}}_{i}^{U}\right) $。
4.5 Aggregation
給定貼文和使用者的表示:$\mathrm{P}^{\prime} \in \mathbb{R}^{M \times d}, \mathbf{U}^{\prime} \in \mathbb{R}^{N \times d}$,我們採用三個全域性注意層將它們分別轉換為兩個固定大小的向量。全域性注意層的表述為:
$\mathbf{r}=\sum_{k=1}^{K} \operatorname{Softmax}\left(f\left(\mathbf{h}_{k}\right)\right) \odot \mathbf{h}_{k}$
其中, $f: \mathbb{R}^{d} \rightarrow \mathbb{R}$ 是一個兩層 MLP。最後,我們得到兩個合併向量 $\mathbf{p}$,$\mathbf{u} $,並將它們連線起來,得到第 $i$ 個新聞事件的最終表示為 $\mathrm{z}=\operatorname{Concat}(\mathbf{p}, \mathbf{u})$。
4.6 Topic-agnostic Fake News Classification
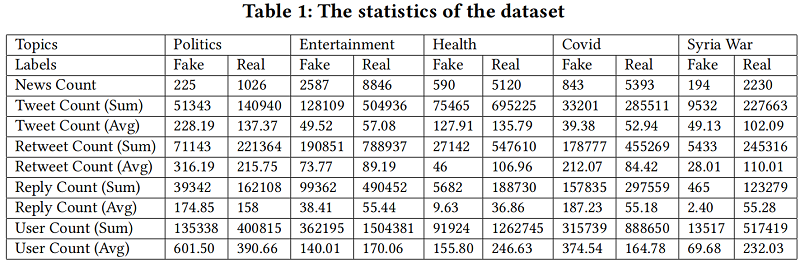
如 Table 1 所示,不同主題之間的傳播特徵差異很大,我們提出了一個輔助 adversarial module 和 a veracity classifier 來學習類判別和域不變節點表示。總體目標如下:
$\mathcal{L}\left(\mathrm{Z}, \mathrm{Y}^{V}, \mathrm{Y}^{C}\right)=\mathcal{L}_{V}\left(\mathrm{Z}, \mathrm{Y}^{V}\right)+\gamma \mathcal{L}_{C}\left(\mathrm{Z}, \mathrm{Y}^{C}\right)$
其中,$\gamma$ 是平衡引數。$\mathcal{L}_{V}$ 和 $\mathcal{L}_{C}$ 分別表示準確性分類器損失和主題分類器損失。$Z$ 是整個資料集提取的特徵矩陣,$\mathrm{Y}^{V}$ 是準確性標籤,$\mathrm{Y}^{C}$ 是主題標籤。具體介紹如下:
4.6.1 Veracity Classifier Loss
準確性分類器損失 $\mathcal{L}_{V}\left(\mathrm{Z}, \mathrm{Y}^{V}\right)$ 是為了最小化準確性分類的交叉熵損失:
$\mathcal{L}_{V}\left(\mathrm{Z}, \mathrm{Y}^{V}\right)=-\frac{1}{N_{t}} \sum_{i=1}^{N_{t}} y_{i}^{V} \log \left(f_{V}\left(\mathbf{z}_{i}\right)\right)$
其中 $f_{V}: \mathbb{R}^{d} \rightarrow \mathbb{R}$ 是一個MLP分類器,$\mathrm{z}_{i}$ 是第 $i$ 個新聞事件的特徵,$y_{i}^{V} \in\{0,1\}$ 是相應的準確性標籤,$N_{t}$ 是訓練集中的範例數。
4.6.2 Topic Classifier Loss
主題分類器損失 $\mathcal{L}_{C}\left(\mathrm{Z}, \mathrm{Y}^{C}\right)$ 要求不同主題的特徵提取過程後的表示是相似的。為了實現這一點,我們學習了一個由 $\theta_{C}$ 引數化的主題分類器 $f_{C}\left(\mathrm{Z} ; \theta_{C}\right)$ 和一個對抗性訓練方案。一方面,我們希望 $f_{V}$ 能夠將每個新聞事件分類為正確的準確性標籤。另一方面,我們希望來自不同主題的特徵相似,這樣主題分類器不能區分新聞事件的主題。在我們的論文中,我們使用梯度反轉層(GRL)來進行對抗性訓練。數學上,GRL 被定義為 $Q_{\lambda}(x)=x$,具有反轉梯度 $\frac{\partial Q_{\lambda}(x)}{\partial x}=-\lambda I$。$\theta_{C}$ 通過最小化交叉熵主題分類器的損失來進行優化:
$\mathcal{L}_{C}\left(\mathrm{Z}, \mathrm{Y}^{t}\right)=-\frac{1}{N_{t}} \sum_{i=1}^{N_{t}} y_{i}^{C} \log \left(f_{C}\left(\mathbf{z}_{i}\right)\right)$
其中,$y_{i}^{C}$ 表示第 $i$ 個新聞事件的主題標籤。對 $\mathcal{L}_{V}\left(\mathrm{Z}, \mathrm{Y}^{V}\right)$ 和 $\mathcal{L}_{C}\left(\mathrm{Z}, \mathrm{Y}^{C}\right)$ 進行聯合優化,並採用標準的反向傳播演演算法對所有引數進行優化。
5 Experiments
5.1 Baselines
- PPC_RNN+CNN [23]: A fake news detection approach combining RNN and CNN, which learns the fake news representations through the characteristics of users in the news propagation path.
- RvNN [25]: A tree-structured recursive neural network with GRU units that learn the propagation structure.
- Bi-GCN [4]: A GCN-based rumour detection model using bi-directional GCN to represent the propagation structure.
- PLAN [17]: A post-level attention model that incorporates tree structure information in the Transformer network.
- FANG [28]: A graphical fake news detection model based on the interaction between users, news, and sources. We remove the source network modeling part for fair evaluation.
- RGCN [33]: The relational graph convolutional network keeps a distinct linear projection weight for each edge type.
- HGT [13]: Heterogeneous Graph Transformer leverages nodeand edge-type dependent parameters to characterize the heterogeneous attention over each edge.
- PSIN : Our proposed Post-User Interaction Model.
- PSIN(-T): PSIN without the adversarial topic discriminator. We compare it with other baselines to demonstrate the superiority of our network architecture.
5.2 Settings
對於PPC_RNN+CNN、RvNN、Bi-GCN和PLAN,我們將post特徵與相應的使用者特徵連線起來,生成節點特徵,以適應它們的架構。
對於 RGCN 和 HGT,我們將 post 和使用者視為兩組節點,這與 PSIN 是相同的。
我們在兩種設定下評估這些方法:主題內分割和主題外分割。
在主題內分割設定中,我們將資料集分成訓練集、驗證集和測試集,比例為 6:2:2,進行了三次分割以追求穩定結果。
在主題外分割設定中,我們根據 Table 2 所示的主題分割資料集,我們將資料分割為訓練和驗證集,比例為 8:2,以構建訓練集和驗證集。
由於資料集中的標籤是不平衡的,我們採用廣泛使用的 AUC 和 F1 評分作為評價的評價度量。
我們將每個事件的貼文數限制在 2000 個,優化器選擇 Adam,學習速率從 $\left\{10^{-3}, 10^{-4}, 10^{-5}\right\}$ 中選擇。
batch_size 設定為 $32$,詞向量維度和網路 hidden size 大小設定為 $100$ ,dropout 從 $0.1$ 到 $0.9$ 之間選擇,每個部分的神經網路層數從 $\{2,3,4\}$ 中選擇, $\gamma$ 從 $\{0.01,0.1,0.5,1.0\}$ 中選擇, $\lambda$ 從 $\{0.01,0.1,1.0\}$ 中選擇。
5.3 Overall Performance
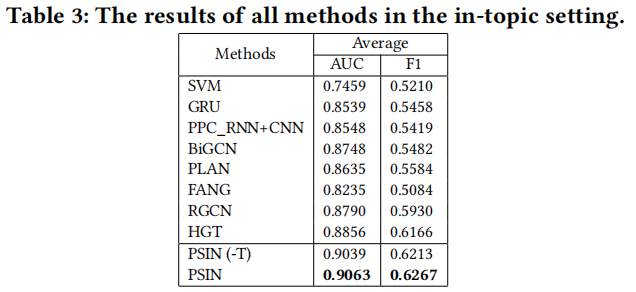
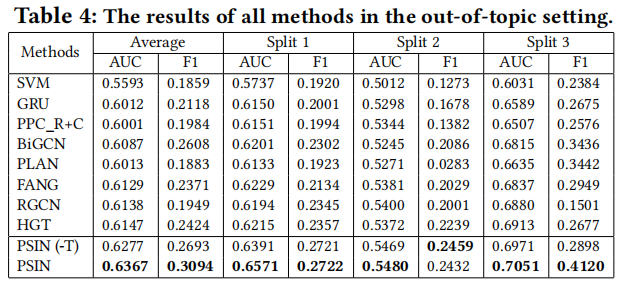
這裡 FANG 是利用了 user 和 post 互動資訊的圖模型(公平起見去掉了原網站資訊),FANG 在域內的結果次於 Bi-GCN 和 PLAN(沒有有效利用 post 內容和結構),但是在跨域分類結果相反,這代表 post-tree 方法更可能過擬合,從而削弱其對新主題事件的泛化能力。
PSIN 在這兩種設定下都優於 PSIN(-T),而且在跨域設定中差距更顯著,這表明對抗性主題分類器減輕了過擬合問題,並使模型學習泛化性更強的特徵來準確性檢測。
5.4 Ablation Study
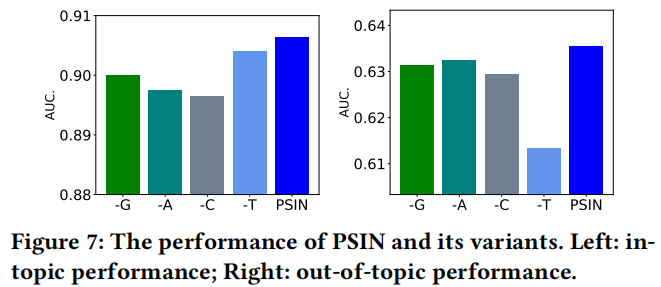
(-G) 沒有文字特徵提取器的門控機制, (-G) denotes our model with the gated mechanism for text feature extractor.(?without?)
(-A) post網路和post-user網路中都沒有邊緣增強技術的模型。
(-C) 沒有post-user互動網路。
(-T) 表示沒有對抗性的主題分類器。在跨域作用明顯
5.5 Early Detection

5.6 Visualization of Effects of the Adversarial Topic Discriminator
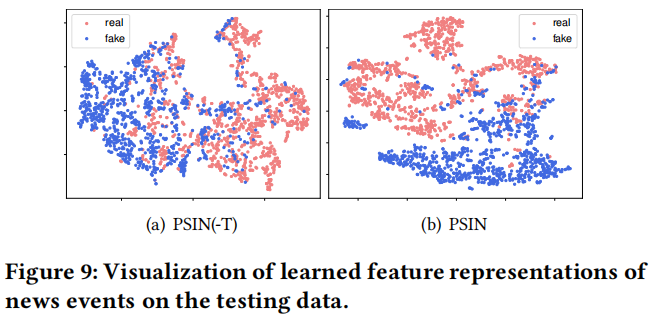
為了進一步分析對抗性主題鑑別器的有效性,我們將PSIN特徵提取器學習到的最終特徵用tSNE定性視覺化 如圖所示。
因上求緣,果上努力~~~~ 作者:關注我更新論文解讀,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/16768930.html