假如我是核酸系統架構師,我會...
成都核酸檢測系統「崩潰」事件,將東軟推至風口浪尖,同時也在技術圈內引發了廣泛的討論。
開發一個不崩潰的核酸系統到底難不難 ?

這篇文章,勇哥想象自己是核酸系統架構師,談談自己對核酸系統的理解。
1 明確系統邊界
作為架構師,首先需要明確系統邊界。
核酸檢測核心流程:
- 醫護人員開啟核酸系統的手機端應用,錄入試管編碼 ;
- 醫護人員掃描居民的健康碼;
- 醫護人員採集咽拭子標本 ;
- 檢測結束之後,醫護人員將檢測標本送至檢測中心;
- 檢測中心將檢測結果提交到核酸系統,然後核酸系統會將核酸結果同步到健康碼系統。
成都核酸系統崩潰時,流程阻塞在步驟一和二。
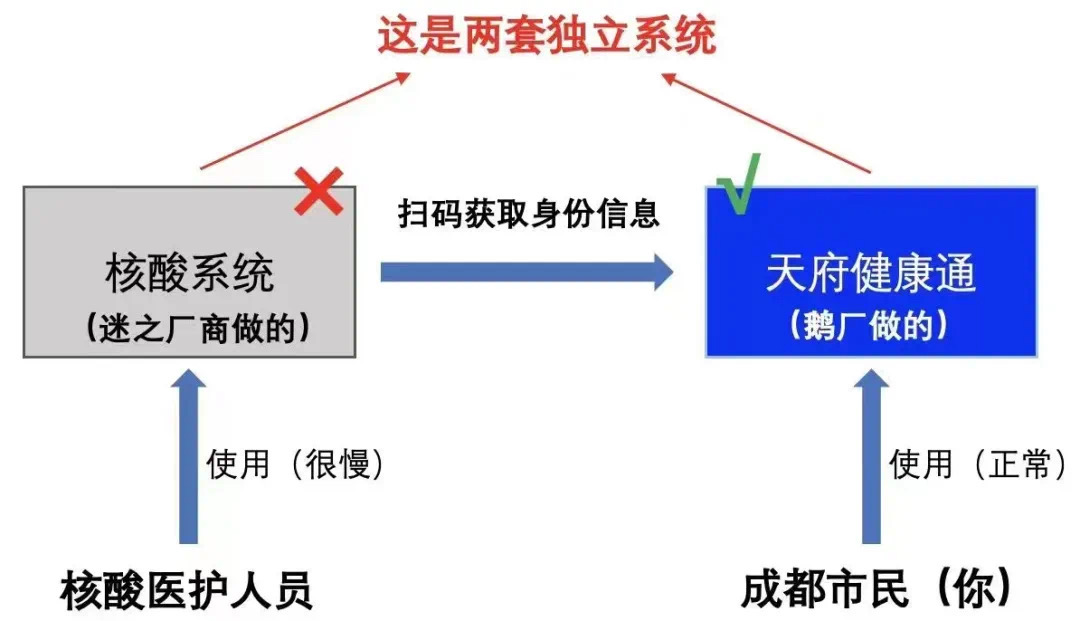
本文裡我們提到的核酸系統,也就是指醫護人員使用的系統。而核酸檢測系統會將檢測結果同步到健康碼系統 , 健康碼系統面向的是大眾居民 , 是高頻場景。
對於成都市居民來講,與他們關係最為密切的就是兩套系統。
- 核酸系統:核酸醫護人員使用 , 東軟負責開發和維護;
- 天府健康通:廣大市民使用,騰訊研發和維護。
2 崩潰疑雲
核酸系統軟體是屬於政府購買 (TO G),市民使用 (TO C) 。
核酸系統是一個多方共同作業的系統,它不僅直接和政府有關係,還涉及到多個廠商,一個系統工程背後,除了系統整合商之外,包括多個分包商。比如西安的一碼通,曾集結了電信、東軟、美林和安恆等公司。
正因為這套系統涉及面之廣,當成都核酸系統崩潰時,我們需要冷靜下來,縷清條理。
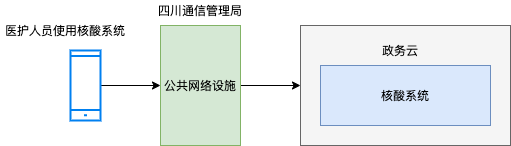
我們先從基礎設施層的維度來分析,很多網際網路公司會將自己的服務部署在阿里雲或者騰訊雲,部署方便,也可以動態擴容。
那麼核酸系統部署在哪裡呢? 假如核酸系統是以 SAAS 形態部署(東軟自建機房,或者東軟採用阿里雲/騰訊雲服務),那麼成都核酸崩潰事件,東軟必然脫不了干係 。但東軟隨後硬氣的發了公告:
系統上線後,發現有響應延遲、卡頓等現象,東軟集團第一時間組織專家組和堅守現場的公司技術人員,與成都市相關部門一起,排查事故原因,強化安全防護,保證系統執行。據技術專家研判,目前出現的系統響應延遲、卡頓等現象與核酸檢測系統軟體無關。9月3日零點左右,在進行網路調整之後,系統執行平穩順暢,效率得到極大提升,當日共完成1200萬樣本採集量。
假如核酸系統沒有問題,會不會是網路問題呢?

成都核酸系統奔潰時,醫護人員以為是訊號問題,紛紛舉起手中的手機,捕捉訊號,而排隊的市民卻可以刷抖音,頭條。
9月3日下午4點32分,四川省通訊管理局發文稱,「全市通訊網路執行平穩,各核酸檢測點行動網路覆蓋良好,沒有出現網路擁塞和故障。」
我們基本可以做出判斷:成都核酸系統部署在政務雲,也就是政府部門提供基礎設施 ,應用開發商將軟體部署在政務雲機房裡 。
核算系統崩潰的可能原因:
-
政務雲機房問題
網路問題(負載均衡,頻寬,防火牆), 或者機房伺服器出現故障;
-
核酸系統軟體問題
核酸檢測軟體確實承載能力有限,軟體崩潰了。
3 應用層設計
核酸系統是屬於高並行應用嗎? 這裡我們做個估算:
- 人口估演演算法:
據統計成都市人口2千萬多人,假設集中在6小時內做核酸,平均每小時支援的並行人數是3531666。每秒支援的並行約為1000。基於檢測人員的集中度不均衡的因素,假設高峰期是平均並行的2-3倍。則每秒並行「核酸登記」2000-3000左右。
- 檢測點估演演算法:
今年5月份,上海抗疫期間一共有 15000 + 核酸檢測點 ,我們假設成都有和上海一樣多的核酸檢測點。市民在排隊核酸檢測時,核酸醫護人員掃居民健康碼的時間間隔在10秒到15秒之間,每個核酸檢測點並行兩排檢測通道,那麼每秒並行「核酸登記」也是在 2000-3000 左右。
通過兩種估算方法,我們發現:核酸系統的請求並行度並不高。
雖然並行度不高,但每天的業務資料條數量級較高 ,按照東軟的公告,每天可以完成1200萬核酸樣本採集。
假設核酸檢測記錄一天1000萬條資料,一週就有7000萬條,1個月就能達到3億條資料。那麼勢必要使用分庫分表。

- 醫護人員掃市民的健康碼 ,核酸登記的請求傳送到 api 閘道器 , api 閘道器將請求轉發到核酸系統;
- 快取儲存檢測點,檢測批次等基礎資訊,核酸系統通過快取判斷業務請求是否合法,若合法,則組裝真正的入庫的資料;
- 核酸系統呼叫分庫分表中介軟體將資料插入到資料庫 。
看起來,核酸系統的架構設計還是比較簡單清晰的,核心點在於用分庫分表硬擋高流量存取。
但現在這種模式就完美了嗎 ?
我們舉湖北鄂通碼舉例,核酸登記後,健康碼在 10~20 分鐘狀態會修改成綠色並標識成:核酸已檢測,也就是核酸已檢測的狀態會非同步同步到健康碼服務。
我們不由得想到了訊息佇列 MQ ,MQ 最大的優勢在於:非同步和解耦,MQ 模式還有一個優點:當流量激增時,訊息佇列還可以起到消峰的作用。
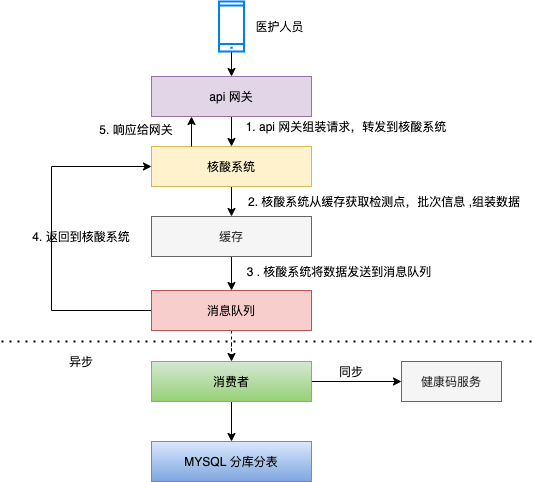
MQ 方案裡,核心流程如下:
- 醫護人員掃市民的健康碼 ,核酸登記的請求傳送到 api 閘道器 ,api 閘道器將請求轉發到核酸系統;
- 快取儲存檢測點,檢測批次等基礎資訊,核酸系統通過快取判斷業務請求是否合法,若合法,則組裝真正的入庫的資料;
- 核酸系統將檢測記錄傳送到訊息佇列,返回給前端響應成功;
- 消費者接收訊息後呼叫分庫分表中介軟體將資料插入到資料庫 ;
- 消費者接收訊息後同步狀態到健康碼服務。
在架構設計中,並不是引入了元件就完事了,更需要考慮如何精準的使用元件。
比如,使用訊息佇列 kafka ,如何保證不丟訊息,如何保證高可用。使用了分庫分表中介軟體,是不是需要考慮資料異構,以及冷熱分離等。
4 監控平臺
我們經常講:研發人員有兩隻眼睛,一隻是監控平臺,另一隻是紀錄檔平臺。
在對效能和高可用講究的場景裡,監控平臺的重要性再怎麼強調也不過分。

▍一、基礎運維監控
基礎運維監控負責監控伺服器的 CPU、網路、磁碟、負載、網路流量、TCP 連線等指標,並且通過設定報警閾值實時通知指定負責人。
我們在基礎設施層這一節裡提到:
核酸系統崩潰時,成都政務雲不能提供暢通的核酸檢測服務 , 可能原因之一是政務雲機房問題。
當政務雲機房出現問題時,基礎運維監控可以幫助運維人員更快的發現問題,並制定解決策略。
▍二、應用系統監控
應用系統監控是研發人員接觸最多的一種監控型別,系統出現瓶頸的時候,應用系統監控會有最直觀的體現。
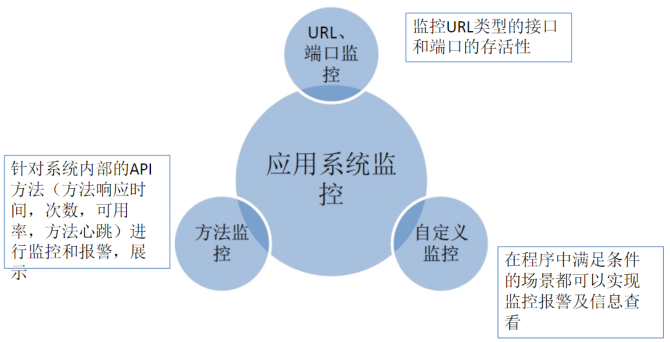
筆者一般會關注效能監控,方法可用性監控,方法呼叫次數監控,JVM 監控這四大類。
- 效能監控
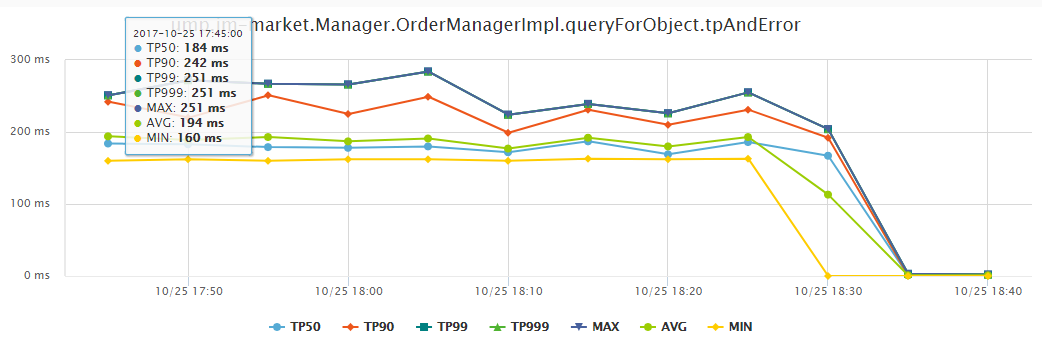
效能監控不同時間段效能分佈,實時統計 TP99、TP999 、AVG 、MAX 等維度指標,這也是效能調優的重點關注物件。
-
方法呼叫次數監控
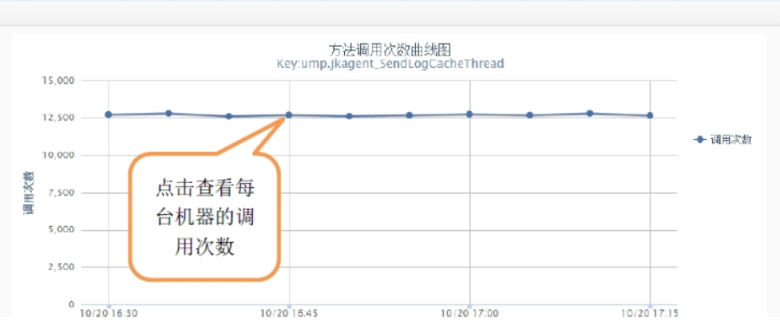
方法呼叫次數監控可以按照機器,時間段分析介面或者方法的呼叫次數,當大流量來襲時,可以清晰的看到請求的波動。
- 方法可用性監控

方法可用性監控是指:當介面被呼叫或者方法被執行,可能返回異常或者方法執行拋異常,分析該方法是否呼叫正常,當系統出現嚴重問題時,方法可用率是一個重要的參考指標。
- JVM 監控

JVM 監控是 JAVA 工程師特別關注的監控型別,我們會重點關注:堆記憶體,GC 頻率 ,執行緒數等等。
▍三、業務監控
業務監控功能是從業務角度出發,各個應用系統需要從業務層面進行哪些監控,以及提供怎樣的業務層面的監控功能支援業務相關的應用系統。
具體就是對業務資料,業務功能進行監控,實時收集業務流程的資料,並根據設定的策略對業務流程中不符合預期的部分進行預警和報警,並對收集到業務監控資料進行集中統一的儲存和各種方式進行展示。
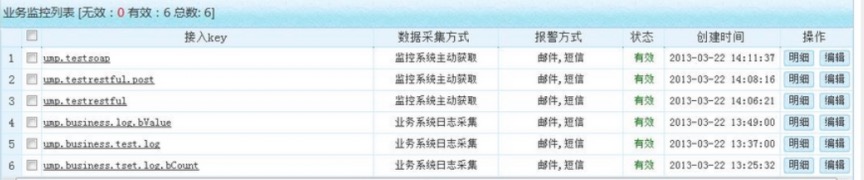
比如訂單系統中有一個定時結算的服務,每兩分鐘執行一次。我們可以在定時任務 JOB 中新增埋點,並設定業務監控,假如十分鐘該定時任務沒有執行,則傳送郵件,簡訊給相關負責人。
5 多方共同作業
很多同學都指責東軟失職:「核酸系統在倉促上線之後,到底有沒有進行完備的效能測試 」。
確實,效能測試非常重要 ,通過壓測可以知道系統的極限值是多大,當系統承受不住存取時,就會暴露出瓶頸,如伺服器 CPU、資料庫、記憶體、響應速度等,從而促使研發團隊進行再優化。
這裡我們先按捺指責的衝動,核酸系統是一個多方共同作業的系統,它不僅直接和政府有關係,還涉及到多個廠商,一個系統工程背後,除了系統整合商之外,包括多個分包商。
《核酸檢測系統崩潰,東軟該不該背鍋?》這篇文章提到:
原則上,監督管理部門要把所有廠商叫在一塊協同作戰。但沒有頂層統籌的強壓之下,廠商之間的溝通和協調很難達成。大多數情況之下的壓測,各個廠商有點「各自為政」的意思。一般,軟體廠商會自己測試自己,鮮少幾家聯合起來測驗。「不同廠商坐在一起的時候,大家都覺得自己沒有問題,都會覺得是別人的問題。理由也會一致,我們的系統在別的地方跑過,沒出岔子"。甚至應對這一局面,各家的心思都極為微妙。「每個廠家在系統上的投入都是一筆不菲的開支,在應急狀態之下,如果上面領導沒表態,也沒明確是公益性質還是有償的付出,廠家相應選擇也是謹慎的。」 因此大多數情況之下的壓測,各個廠商有點「各自為政」的意思。一般,軟體廠商會自己測試自己,鮮少幾家聯合起來壓測。
這篇文章的一個觀點,「這是技術層面之外,一個城市應急預案的管理能力問題。」 我深以為然。
6 總結
假如我是核酸系統的架構師。。。。
-
我會使用訊息佇列 + 分庫分表來最大程度提升系統的吞吐量。
-
我會在使用訊息佇列中介軟體的時候,重點關注如何不丟失訊息,訊息系統如何做到高可用。
-
我會使用分庫分表中介軟體時,重點關注冷熱分離,如何將資料異構到資料倉儲。
-
我會在政務雲部署監控系統,提供基礎運維監控,應用系統監控,業務監控的能力,當系統出現問題時,團隊可以以最快的速度發現問題,並解決問題。
可是,核酸系統是一個多方共同作業的系統,我們不僅需要和政府溝通,也需要和眾多三方廠商共同作業。
也許,當我提出需要更多伺服器預算時,政府部門的預算並不充足,或者就算充足了,走流程也要一個月的時間;
也許,當我提出需要部署監控系統,公司會以人力不足為由或者政務雲硬體資源不足,否定我的方案;
也許,當我聯調時發現三方介面速度慢,排查起來(溝通成本)需要 2-3 天時,我也不得不沉浸在瑣事中;
直到最後,當系統崩潰時,我也只能嘆息到:「尊重技術,尊重專業」。
如果我的文章對你有所幫助,還請幫忙點贊、在看、轉發一下,你的支援會激勵我輸出更高質量的文章,非常感謝!
