Dapr 長程測試和混沌測試
介紹
這是Dapr的特色專案,具體參見: https://github.com/dapr/test-infra/issues/11 ,在全天候執行的應用程式中保持Dapr可靠性至關重要。在部署真正的應用程式之前,可以通過在受控的混沌環境中構建,部署和操作此類應用程式來實現這種信心。
測試應用程式
所測試應用程式將模擬在社群網路中釋出的訊息,以便通過情緒分析進行評分。不採用外部依賴來更好地控制環境。可以刪除某些元件,並實現相同的結果。另一方面,這個測試設計是有意地執行Dapr的所有構建塊。
此應用程式中的所有元件使用相同的儲存庫和相同的程式語言實現,以便快速開發。由於此應用程式也使用 Actor 功能,因此可以用 .Net 或 Java 編寫。鑑於當前的專案維護者更熟悉 C#,因此使用帶有 C# 的 .Net SDK來實現這個專案。
儲存庫應與現有儲存庫分開。建議建立一個名為「長程測試」的新儲存庫。
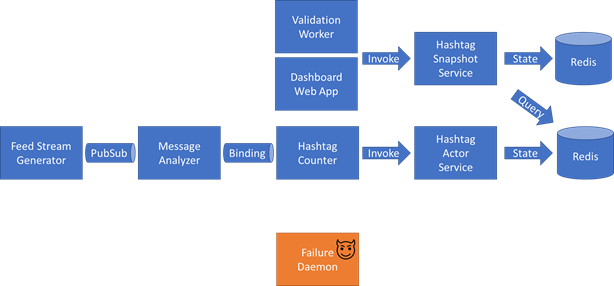
Feed 流發生器
生成人工社群網路訊息貼文,例如:「Dapr很棒。#DaprRocks #Kubernetes「。將在預定義的模板中自動生成這些訊息「 is . <Hashtag 1> <Hashtag 2>」 名詞和形容詞的列表是預定義的,並且是隨機選擇的。與主題標籤列表相同。
該訊息使用 UUID 生成器獲取隨機生成的訊息 Id 和相關 Id,並使用 Dapr 的 PubSub API 以下列格式釋出:
{
"correlationId": "<UUID>",
"messageId": "<UUID>",
"message": "<message>",
"creationDate": "<creationDate>"
}訊息分析器
該元件通過Dapr 的PubSub功能訂閱主題,查詢形容詞與情緒型別(正面,中性,負面)的對映,並使用識別的型別(或未知,如果找不到)並將該內容附加到訊息中。最後,通過 Dapr 的輸出繫結API 釋出新的標記有效負載。
標記的有效負載採用以下格式:
{
"correlationId": "<UUID>",
"messageId": "<UUID>",
"message": "<message>",
"sentiment": "<sentiment type>",
"creationDate": "<creationDate>"
}Hashtag 計數器
此元件將通過 Dapr 的輸入繫結呼叫接收訊息。從郵件中提取主題標籤。對於每個hashtag標識的# 標籤,它都會進行一個Actor方法呼叫:標識為「HashtagActor」的執行元件範例中的方法increment(sentiment)。
Hashtag Actor 服務
此元件對於在 Dapr 中練習「Actor 」功能非常有用。它註冊主題HashtagActor 程式型別,其中hashtag是識別符號。這個Actor 有一個方法increment(String sentiment), 其目標是保持每個主題標籤 - 情緒組合的計數器。在狀態鍵中傳遞的情緒和狀態值是前一個值(如果未找到,則為零),增量為 1。
Hashtag 快照服務
此元件將執行 Dapr 的狀態 API(而不是在Actor 的上下文中)。它每分鐘喚醒一次,並從 Redis 狀態儲存中檢索所有Key - 不使用 Dapr 的狀態 API,因為 Dapr 不提供 API 來從另一個 Dapr 應用程式的狀態儲存中查詢一系列狀態。預計只有幾十個Key,因為此元件中預定義了主題標籤列表。
現在,為所有狀態生成鍵值對,並通過 Dapr 的狀態儲存 API 儲存。此服務還提供了一個 API,用於通過 GET 方法檢索所有金鑰。
驗證Worker
此元件將對應用程式的結果執行執行狀況檢查。鑑於最終的一致性和人為注入的故障,驗證必須是模糊的。Worker應執行以下驗證:
- 每5分鐘喚醒一次。
- 通過在Hashtag 快照服務上呼叫 API 來獲取所有鍵值對。
- Sleep 2分鐘。
- 通過在Hashtag 快照服務上呼叫 API 來獲取所有鍵值對。
- 計算已更改的計數器數的比率。
- 以 JSON 格式向標準輸出指標:
{ "longhaul-counters-changeratio": "<ratio>"}
儀表板網路應用
這是一個簡單的網頁,它將呼叫Hashtag 快照服務進行 API ,顯示所有鍵值對。這對於手動驗證非常有用。(可選)此元件還可以通過 Dapr 的中介軟體驗證 OAuth 功能。
失敗守護行程
最後但並非最不重要的一點是,在給定固定設定的情況下,此服務將觸發故障。本檔案稍後將介紹故障型別和特定的故障設定。
平臺、紀錄檔和指標
長程測試應用將使用 AKS 群集進行部署,該群集在 3 個可用區中的每個節點上至少有 1 個節點。由於目標是測試復原能力而不是效能,並且流量是人為生成的,因此便宜的硬體型別應該足夠了,例如標準DS2 v2(2個vcpus,7 GiB記憶體)。
紀錄檔和指標將轉發到 Azure 監視器,並且可以通過 JSON 作為結構化資料進行查詢。
故障型別
為了模擬混亂的環境,將注入一些人為的故障。可以通過將服務從 3 縮小到 0,然後從 0 擴充套件到 3 來實現重新啟動。當需要單個 POD(例如,placement服務)時,重新縮放應改為從1/到 1。
應用容器崩潰
若要模擬的應用崩潰(程序退出),任何容器都將在一段時間內重新啟動此係統。值得注意的是,Dapr的Sidecar 預計將繼續執行。預計容器將正常重新啟動,Dapr的Sidecar將在沒有手動干預的情況下恢復與應用程式的通訊。
Pod 崩潰
要模擬給定 POD 不正常的情況,系統中的服務 POD 將在一段時間內重新啟動。這是部分故障,這意味著在 Kubernetes 恢復新 POD 時,服務應繼續執行。預計 Kubernetes 會將服務再次恢復到正常狀態,而來自其他服務的 Dapr sidecar 將能夠與恢復的服務中的所有 POD 進行通訊。
服務崩潰
此故障通過重新啟動服務的所有 POD 來模擬服務的完全中斷。這將導致驗證工作程式可能會識別完全中斷。預計 Kubernetes 會將服務再次恢復到正常狀態,而來自其他服務的 Dapr sidecar 將能夠與恢復的服務中的所有 POD 進行通訊。
狀態儲存中斷
狀態儲存可能由於任何原因而關閉。為了模擬這一點,Redis 的所有 POD 都將每隔一段時間重新啟動一次。
狀態儲存速度緩慢
狀態儲存的效能可能會因鄰居應用的繁忙或其他外部因素而降低。這是通過在內部以 X tps 對 Redis 執行 Y 秒的寫入操作來模擬的。預計資料處理會有些緩慢,但在突發結束後恢復。
主題中斷
主題可能因任何原因而關閉。這將通過每隔一段時間重新啟動 Kafka 的所有 POD 來模擬。
主題緩慢
由於並置了另一個主題並接收到流量峰值,因此主題的吞吐量可能會降低。緩慢也可能是由其他外部因素引起的。為了模擬這一點,建立了一個隨機主題ios,副本設定為3(保證所有節點都有資料的副本),並且流量以X tps保持,持續時間為Y秒,間隔一次。預計資料處理會有些緩慢,但在突發結束後恢復。
Dapr 的sidecar 注入器奔潰
使用以下步驟模擬此故障後,資料處理應繼續,並且所有 POD 都應具有 Dapr sidecar。
- 將服務從 3 擴充套件到 0。
- 等待服務為 0。
- 重新啟動達普爾的邊車噴油器。
- 將服務從 0 擴充套件到 3。
Dapr的placement服務崩潰
這是通過每隔一段時間重新啟動placement服務來模擬的。
Dapr的Sentry服務崩潰
這是通過每隔一段時間重新啟動sentry服務來模擬的。
Actor 範例化 洪峰
某些應用程式可能會在很短的時間內建立許多Actor。這種突發將通過建立隨機型別的actor並以X tps的固定速率啟用它來模擬,以達到一定間隔的持續 D。頻繁的Actor型別必須與應用中使用的actor 型別不同,但也應由 Hashtag Actor 服務註冊,以確保服務獲得流量負載。預計資料處理會有些緩慢,但在洪峰結束後恢復。
失敗設定
失敗守護程式將設定為每隔一小時執行以下模式 (即,活動 1 小時,空閒 1 小時)。
- Feed 流生成器的容器每 2 分鐘崩潰一次。
- 訊息分析器的容器每 3 分鐘崩潰一次。
- Hashtag計數器的容器每 4 分鐘崩潰一次。
- Hashtag Actor 服務的容器每 5 分鐘崩潰一次。
- Hashtag計數器的POD每9分鐘崩潰一次。
- Hashtag Actor服務的 POD 每 10 分鐘崩潰一次。
- 訊息分析器的服務每 7 分鐘崩潰一次。
- 狀態儲存每 25 分鐘中斷一次。
- 狀態儲存速度為每 29 分鐘 1 分鐘(tps 將在實現期間定義)。
- 每 21 分鐘中斷一次主題。
- 每 23 分鐘有 1 分鐘的主題緩慢。
- Dapr的Sidecar 注入器與Hashtag 快照服務每13分鐘崩潰一次。
- Dapr的placement每5分鐘崩潰一次。
- Dapr的sentry服務每7分鐘就會崩潰一次。
- Actor 的範例化每 10 分鐘突發 1 分鐘(tps 將在實現期間定義)。
如果上述所有故障在現實世界中都不能一起證明是可行的,那麼 Failure Daemon 可以隨機選擇上述故障設定的子集(例如 5),並僅在給定執行中執行這些設定。
測試驗證
測試驗證通過 Azure 監視器中觸發 sev3 的監視器上的警報進行。將設定以下監視器,並應始終保持正常:
資料處理
對於兩個連續的資料點,驗證工作人員的更改比率指標永遠不應為零。此指標由驗證工作程式發出。
訊息分析器延遲
訊息分析器必須釋出自訊息建立以來延遲的指標。任何訊息都不應早於 2 分鐘。此指標由訊息分析器發出。
Hashtag計數器延遲
Hashtag計數器必須釋出自訊息建立以來延遲的指標。任何訊息都不應早於 4 分鐘。此指標由 Hashtag計數器發出。
過時快照
即使 Hashtag 快照服務正在執行,最後一個快照也可能太舊。Hashtag 快照服務應在自上次成功執行以來延遲時釋出指標。延遲不應超過 5 分鐘。此指標可由 Hashtag 快照服務發出。
服務執行狀況
可以使用其他告警檢測到完全中斷。要檢測部分故障,任何服務都不能在超過 50 分鐘內具有少於 3 個正常執行的 POD。此衡量指標可由失敗守護程式發出。
一般錯誤計數峰值
錯誤計數峰值時發出警報。確切的值將在實施過程中確定。
無錯誤
錯誤計數不應大於零超過 70 分鐘(即,進入正常小時 10 分鐘)。
歡迎大家掃描下面二維條碼成為我的客戶,扶你上雲
