字串匹配之Sunday演演算法
2022-10-04 06:00:47
簡介
Sunday演演算法是一種字串匹配演演算法,相比於KMP演演算法,它比較簡單易學。
在有些時候,比如字串很長的時候,它是比KMP要高效的。
核心思想
-
從前往後匹配,匹配失敗時關注主串中參與匹配的最末位字元的下一位。
-
該字元沒有在模式串中出現,則直接跳過,且模式串移動位數 = 模式串長度 + 1。
-
否則,移動位數 = 模式串長度 - 該字元在模式串最右出現出現的位置。
這三步說明了具體的執行,感覺很抽象。但綜合起來就是:
- 匹配時從前向後匹配。
- 匹配失敗時,重新對齊模式串與主串。
所以現在的問題是,這個重新對齊是怎麼對齊呢?
舉個栗子
- 設主串為 eurusdoveyesido
- 設模式為 esid
- 正常匹配,在第2位發現不匹配,於是看主串中參與匹配的最末位字元的下一位,也就是s。s也在模式串出現過,那麼對齊

- 對齊後,繼續正常匹配,發現第1位就不同,匹配失敗。同樣,看v,發現v沒在模式串出現過,那麼模式串就與v後面的e對齊
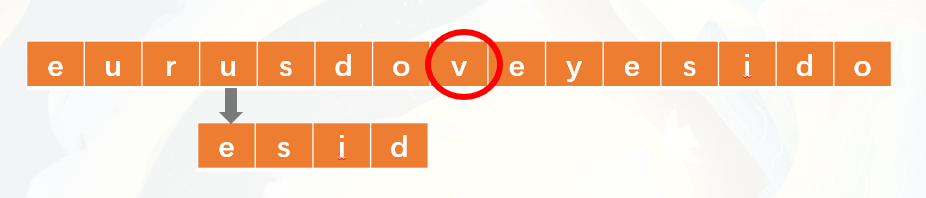
- 同樣,匹配失敗。對齊i
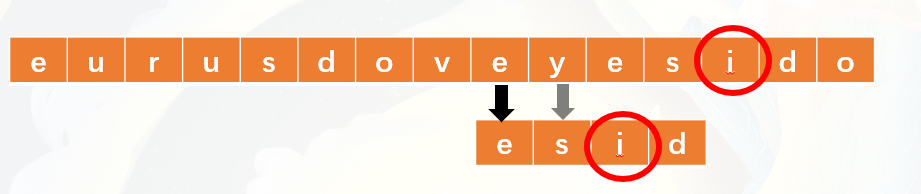
- 終於,匹配成功!

程式碼實現
_next陣列
是的,Sunday演演算法也有next陣列需要預處理。
next陣列儲存的是:模式串不同字元最右邊的下標。
所以,對於上面例子的模式串 esid
- \(next[d] = 3\)
- \(next[i] = 2\)
- \(next[s] = 1\)
- \(next[e] = 0\)
而對於英文字元,它們都在ASCII裡,總計256個,所以我們開一個256大小的陣列
int _next[256];
void getnext(char pattern[])
{
int len = strlen(pattern);
int i;
for(i = 0;i < 256; i ++)//初始化為 -1
{
_next[i] = -1;
}
int cnt = 0;
for(i = len - 1;i >= 0;i --)
{
if(_next[i] == -1)
{
_next[(int)pattern[i]] = i;
cnt ++;
if(cnt == 256)//256滿了就退出
{
break;
}
}
}
}
這樣的預處理,正是以空間換取時間
匹配過程
匹配的程式碼按思想寫就好,值得一提的是:
因為模式串中沒有出現的字元的next值為-1,所以正好,當要對齊的時候,模式串多向後移動了一位(減 負 1 -> 加 1)。
int SundaySearch(char pattern[],char dest[])
{
getnext(pattern);
int i, j, k;
int lenp = strlen(pattern),lend = strlen(dest);
for(i = 0;i < lend;)
{
j = i;
for(k = 0;k < lenp && j < lend; k ++)//匹配的過程
{
if(dest[j] == pattern[k])
{
j ++;
}else
{
break;
}
}
if(k == lenp)//匹配成功,返回首字元下標
{
return i;
}else
{
if(i + lenp < lend)//注意越界
{
i += lenp - _next[(int)dest[i + lenp]];
}
else
{
return -1;
}
}
}
return -1;
}
本文來自部落格園,作者:江水為竭,轉載請註明原文連結:https://www.cnblogs.com/Az1r/p/16751593.html