目錄
一、對快取中介軟體的訴求
1.1 我們為什麼需要快取中介軟體
我們一直使用關係型資料庫作為我們幾乎是唯一的資料儲存方案。關係型資料庫在對複雜結構的資料的組織上、永續性和一致性控制上有巨大的優勢。但磁碟資料庫無論如何進行查詢優化,速度上終究無法和記憶體讀寫相提並論。而隨著客戶資料量越來越大、並行量越來越高、客戶場景越來越複雜,我們對資料存取效率的要求也在提高。此時,引入快取中介軟體成了我們一定要考慮的事情。
在2022年,一聽到快取中介軟體,我們首先想到的依然是redis。但我們團隊長期以來並沒有充分地利用起redis提高系統效能,依然大量依賴於關係型資料庫處理資料的儲存和讀寫。為提高系統整體效能,嘗試引入新的快取中介軟體解決我們的問題。
1.2 快取的分類
我將快取解決方案劃分為兩大類別:弱勢快取和強勢快取。
1.1.1 弱勢快取
第一類,是以Redis為首的弱勢快取。這類快取強調的是極高的讀效能和寫效能,一般作為高並行場景下,高速的應用服務和較低速的磁碟資料庫之間的快取。
弱勢快取為提高讀寫效率,捨棄了強一致性,追求最終一致性,資料結構簡單,因此,基於弱勢快取設計的應用系統,通常以磁碟關係型資料庫的資料為準,快取中更傾向於儲存一些相對靜態穩定的基礎資料,用於輔助關係型資料庫。對於資料的更新模式,也更偏向於追加,而不是大並行下的頻繁更新,應用系統不會完全信任快取中的資料。這種效率優先,對資料準確性要求不高的方向與如今的網際網路行業(尤其是toC領域)的需求十分契合。
1.1.2 強勢快取
而對於業務資料模型較複雜,對資料實時性和準確性要求較高的金融行業、企服行業,更需要的是一個強一致性的資料儲存,在引入快取之前,關係型資料庫承擔了這一角色。
業務特性導致我們幾乎無法接受為了讀寫效率犧牲資料準確性。複雜業務場景下,我們需要一個強一致性和高實時性的、對資料結構有更強的表達能力的,能描述部分邏輯表達的記憶體資料庫。能滿足這些要求的產品,我稱其為強勢快取。因為這些特性可以讓記憶體資料庫作為我們資料的基準,而讓關係型資料庫作為一個持久化的備份,進一步降低磁碟的存取率,提高記憶體的存在感,讓一個完整業務流程中的資料流轉可以在記憶體中可靠地完成。
二、什麼是Apache Geode
Apache Geode正是滿足我給出的強勢快取定義的一款記憶體資料庫產品。它是商業記憶體資料網格Geofirm的開源版本,已經在金融支付領域和12306等大型訂購網站中經受住了考驗。
2.1 Apache Geode的架構
2.1.1 通訊拓撲
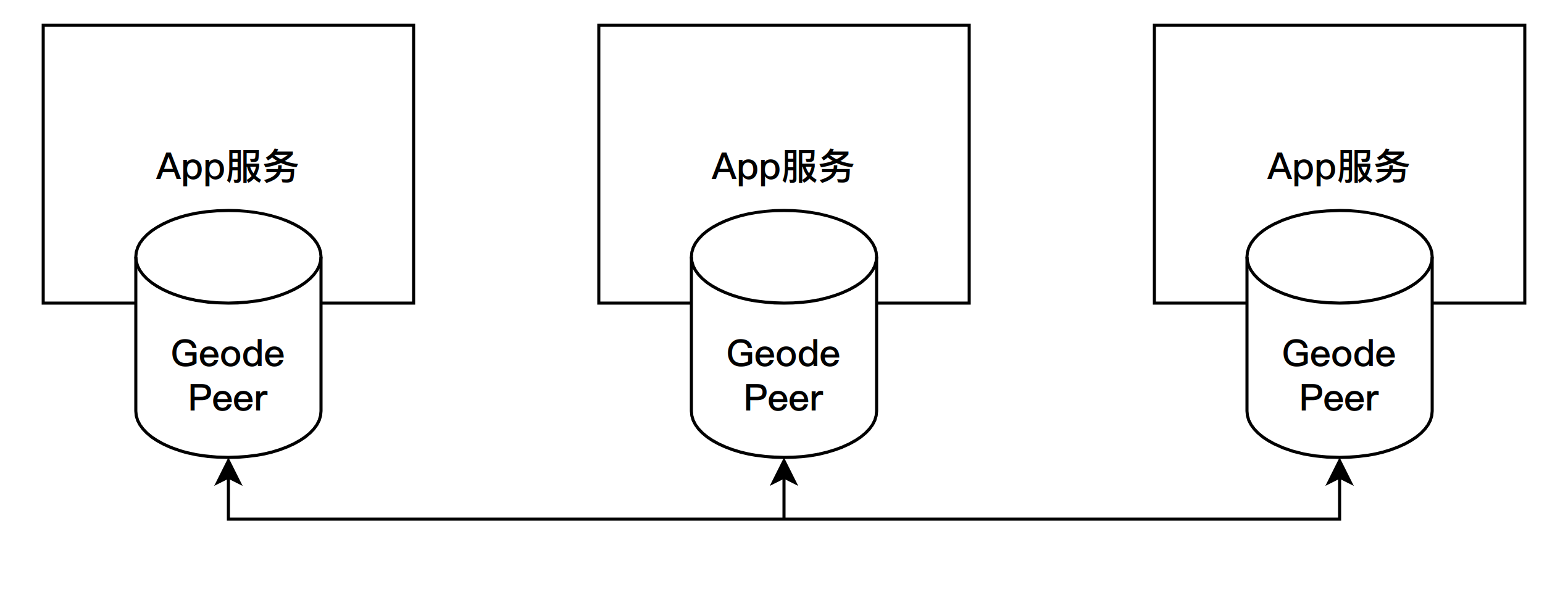
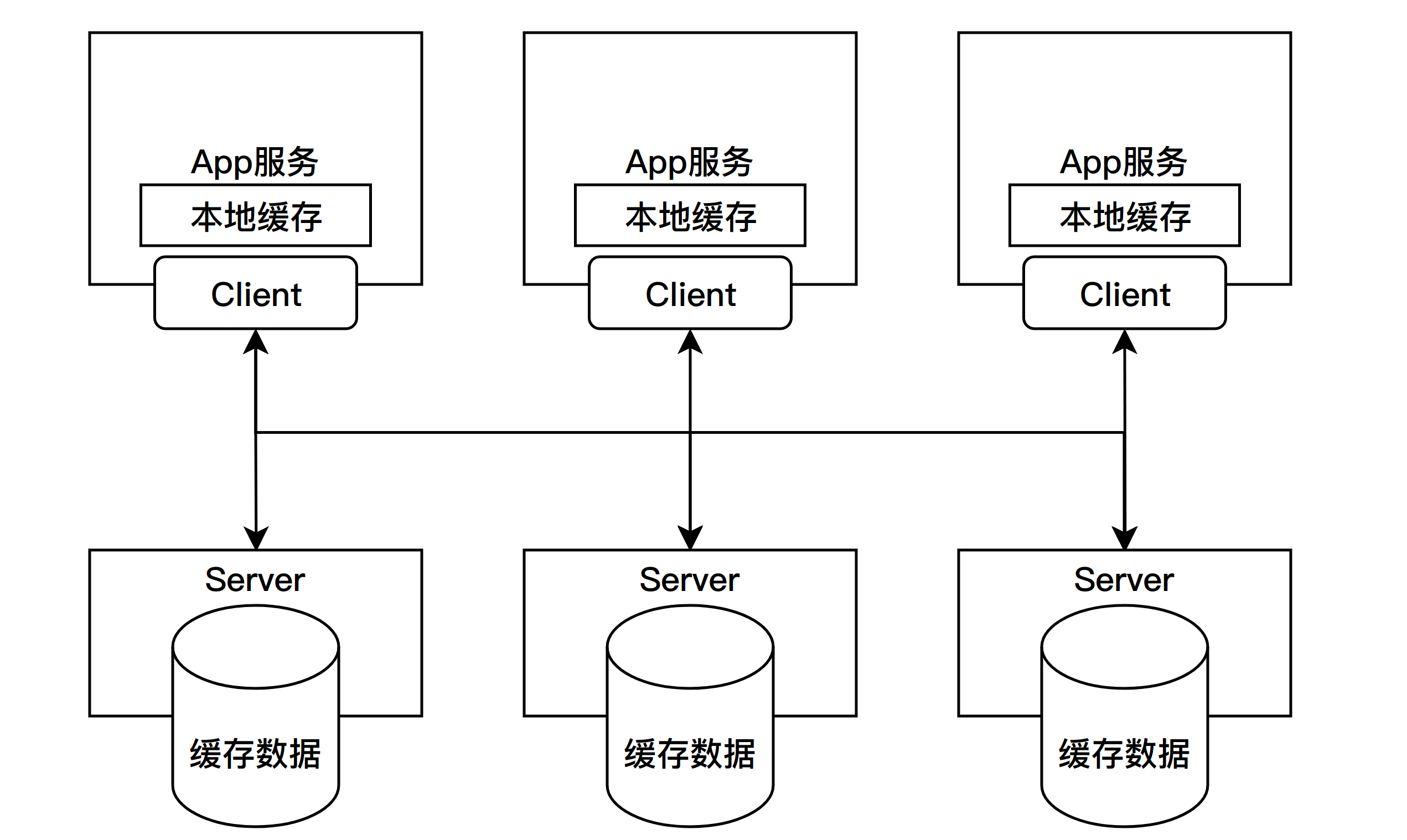
2.1.2 服務發現
Apache Geode提供了定位器(Locator)程序,為參與快取的所有成員(Client、Server、其它的Locator)提供其他成員的發現和負載均衡。Locator既可以和其他Geode程序部署在一起,也可以獨立部署,獨立部署可以更好地保證定位器的可靠性和可用性(因為一旦一起的Geode程序掛了,這個Locator也很難倖免於難)。可以部署多個Locator共同起作用,client連線時可以選擇連線到哪個Locator上。
Client可以設定連線到哪個Server伺服器,但更合理的設定方式是連線到某個Locator上,由這個Locator為Client分配一個負載較低的Server,Client啟動後只會和Locator溝通一次,在獲知被分配到的Server的IP和埠之後,每次讀寫都會直接連線到Server上。
2.1.3 資料儲存形式和區域
市面上大部分的記憶體資料儲存,都將資料按鍵值對的格式進行存放,Geode也是如此。但與Redis等簡單的KV不同,Geode將KV資料們按資料區域(Region)進行組織。對於不同的區域可以單獨設定(如是否分割區或需要副本)。
資料區域可以類比於關係型資料庫中的表的概念,是一系列結構相同的資料結構的集合。實際上,在實現上資料區域就是一個ConcurrentMap<K, V>,其鍵就是一條資料的唯一性標識(型別任意,只要重寫了equals和hashcode以便於Region確認鍵的唯一),其值是一個表達完整資料概念的物件,這樣其實也讓一條資料中按類的成員又劃分出了列的概念。基於這種類似關係型資料庫的儲存模式,Geode提供了一種類似於SQL的查詢語言,稱為OQL,並支援多區域查詢(類似於連表查詢)。
下面是一個OQL查詢的小例子:
class DictPlatform implements DataSerializable {
short platformId;
String name;
String status;
}
class TestServiceImpl {
public void query() {
String queryString = "SELECT dp.platformId, dp.name FROM /dict_platform dp WHERE dp.status >= 0;"
QueryService queryService = cache.getQueryService();
Query query = queryService.newQuery(queryString);
SelectResults results = (SelectResults)query.execute();
DictPlatform p = (DictPlatform)results.iterator().next();
}
}- 2.1.3.1 區域的分散式儲存和複製
資料區域可設定的型別主要為 Partitioned , Replicated , Distributed non-replicated , Non-distributed 這四種。下面重點介紹前兩種型別。
- Partitioned 分割區區域
如果某個區域資料量很大,一個成員放不下,可以將這個區域劃分為多個bucket,分別儲存在不同的server上,為了保證高可用,可以讓不同的bucket的副本分佈在多個server上,以某個server上的bucket作為master,很類似於Apache Kafka的設計。當儲存不夠,可以增加新的server,增加新server後的需要發起重平衡,重平衡不需要停機,但可能會導致正在執行的事務失敗。
可以從任何一個副本中讀取到資料,如果和Client聯絡的那個Server沒有想存取的分割區的副本,需要經過server間的一跳,將請求轉給目標server。因此,分割區的讀效能稍差。 - Replicated 複製區域
如果某個區域資料量不大,為了提高讀效能,複製區域可以將區域中所有資料完整地複製給其它副本,這樣所有server中儲存著完全相同的資料。
- Partitioned 分割區區域
2.1.4 資料量的控制和熱點資料
Geode有兩種模式控制記憶體中的資料規模,持久化和失效。但無論如何,熱點資料都通過最近最少使用(LRU)演演算法來判斷。
- 2.1.4.1 持久化
持久化(Persisted) 和 溢位(Overflowed) 是配合使用的兩個概念,設定共同使用持久化和溢位之後,所有資料都會被複制到磁碟,在記憶體中只保留熱點資料的值,但所有資料的鍵都會被保留,以便於確認資料在磁碟上是否存在。記憶體中資料量達到閾值後(指定條數或記憶體負載),排在LRU隊尾的資料會被溢位到磁碟中(也即刪除),當這個鍵對應的資料又一次被存取到,這個鍵會被恢復到記憶體中。
磁碟中的值和記憶體中的值在應用程式看來沒有任何區別。 - 2.1.4.2 失效
驅逐(Eviction) 和 到期(Expiration) 是可設定的兩種資料失效的方式,總的來說,失效就是值當資料滿足某些條件時,就從記憶體中刪除掉。
- 驅逐
驅逐是指當記憶體中的資料量到達一定閾值時,將LRU隊尾的資料銷燬。這個閾值可以是條數或佔用的記憶體大小。驅逐和溢位並不是互斥的,溢位實際上是一種不會丟失資料的驅逐。 - 到期
到期是指按時間銷燬掉冷資料,到期有兩種計算方式,一種是從資料建立或更新開始計算,被稱為TTL(Time to live),另一種是上次被存取開始計算,被稱為Idle timeout。第二種更適用於熱點資料的儲存,第一種更適合於業務要求的定時失效的資料。
- 驅逐
三、Apache Geode是否能滿足我們的需要
3.1 效能
3.2.1 吞吐量和延遲
讀寫吞吐量由並行主記憶體儲器資料結構和高度優化的分發基礎結構提供。 應用程式可以通過同步或非同步複製在記憶體中動態複製資料,以實現高讀取吞吐量,或者跨多個系統成員對資料進行分割區,以實現高讀寫吞吐量。 如果資料存取在整個資料集中相當平衡,則資料分割區會使聚合吞吐量翻倍。 吞吐量的線性增加僅受骨幹網容量的限制。
優化的快取層最大限度地減少了執行緒和程序之間的上下文切換。 它管理高度並行結構中的資料,以最大限度地減少爭用點。 如果接收器可以跟上,則與對等成員的通訊是同步的,這使得資料分發的延遲保持最小。 伺服器以序列化形式管理物件圖,以減少垃圾收集器的壓力。
使用者端可以將單個資料請求直接傳送到持有資料key的伺服器,從而避免多跳以定位已分割區的資料。 使用者端中的後設資料標識正確的伺服器。
3.2.3 索引
Geode的查詢支援索引以提高查詢效率。實際上,Geode維護了一個鍵和索引值之間關係的資料結構(一般是一顆B樹),並支援範圍查詢。
但和所有的關係型資料庫一樣,索引能帶來收益的前提是良好的索引設計,而且必然會帶來寫效率的降低。
3.2 CAP
我們知道分散式系統存在CAP不可能三角,即一個分散式系統最多隻能同時滿足 一致性(Consistency) 、 可用性(Availability) 和 分割區容錯性(Partition tolerance) 這三項中的兩項。下面從一致性、可用性和分割區容錯性上分析Apache Geode的效能優劣。
一致性
Apache Geode的定位是一款強一致性的記憶體資料庫。一致性的破壞有兩種渠道: 副本更新的延遲或失敗 和 並行更新 。
- 對於分割區區域,即使該分割區設定了冗餘的副本,也只允許在主副本上按順序寫入,寫入過程中會進行鎖定,防止並行更新。對主副本的寫入,必須在同步地執行對冗餘副本的寫入後才算成功。
- 對於複製區域的寫操作,Geode會保證所有的副本都成功執行寫入後,才返回成功。Geode並行地執行對多個server的資料分發,但仍會降低寫入的效率。
對於複製區域的並行更新可能擊中任何一個副本,這樣就出現了並行問題。Geode在更新前提供了一致性檢查,檢測並一致地解決並行和無序更新。這個一致性檢查實際上是使用版本號和時間戳來保證,多個更新到來時,只保留最高版本的更新請求。如果有多個相同版本的更新請求,每個成員都有一個資格ID,最高資格ID的成員的更新生效。
可用性
- 對於複製區域,每個server上都儲存著相同的資料,因此一個server宕機完全不影響資料的正常讀寫。
- 對於分割區區域,為了保證高可用性,可以對分割區設定冗餘副本,在某個server宕機後,Geode會自動地將副本標記為master,當可用的副本數量到達一個閾值後,Geode會啟動一個執行緒,啟用一個新的server作為新的副本的據點,將所有資料複製到這個新的server上並標記為可用副本。這個過程是否立即執行是可設定的,也可以等一會看宕機的server是否能恢復。
上面提到的持久化能力也提高了區域的災備能力,Geode允許以分割區為維度進行落盤持久化,並在一個新的server啟動後,將磁碟中的內容恢復到記憶體中。
分割區容錯性
Apache Geode作為分散式記憶體資料庫,天然地滿足了分割區容錯性。
3.3 複雜業務場景的需要
3.2.1 事務支援
Geode提供了ACID事務的能力,但基於樂觀鎖,重新定義了ACID。
- 原子性
樂觀事務通過使用預約系統提供原子性並實現速度,而不是使用傳統的兩階段鎖行關聯式資料庫技術。這種保留阻止了其他交叉事務的完成,允許提交檢查衝突,並在對資料進行更改之前以全有或全無的方式保留資源。在本地和遠端完成所有更改之後,將釋放預訂。在預訂系統中,交叉事務將被簡單地丟棄。避免了獲取鎖的序列化。 - 一致性
一致性要求在事務中編寫的資料必須遵守為受影響區域建立的鍵和值約束。請注意,事務的有效性是應用程式的責任。 - 隔離
隔離是事務狀態對系統元件可見的級別。Geode事務具有可重複的讀隔離。一旦為給定的鍵讀取提交的值,它總是返回相同的值。如果事務中的寫操作刪除了已讀取的鍵的值,則後續的讀操作將返回事務參照。
預設設定在流程執行緒級別隔離事務。當一個事務正在進行時,它的更改只在執行該事務的執行緒中可見。同一程序中的其他執行緒和其他程序中的執行緒在提交操作開始之前不能看到更改。在開始提交之後,更改在快取中是可見的,但是存取更改資料的其他執行緒可能會看到事務的部分結果,從而導致髒讀。但可以通過修改設定避免髒讀。 - 永續性
關聯式資料庫通過使用磁碟儲存進行恢復和事務紀錄檔記錄來提供永續性。Geode針對效能進行了優化,不支援事務的磁碟永續性。
3.2.2 Functions
可以在Geode服務中註冊一些函數,應用程式只需要傳送函數的名稱就可以執行函數內容。
3.2.3 連續查詢
這是一個類似於訊息佇列的機制,Client向Server釋出一個OQL查詢,當Server執行了會導致這個OQL的查詢結果發生變更的事件後,會將這個事件和新的結果通知給Client,Client可以基於此做一些特殊的操作。比如我們在快取中管理庫存量,釋出一個連續查詢 "SELECT * FROM /stock s WHERE s.stock_num + +s.purchase_num < 100",當這個查詢收到值時,就向採購領域釋出採購預警事件。
3.2.4 異構
Geode提供了多種序列化方式,當想要在異構的系統中使用Geode時,可以不使用Java的序列化,而是其它更通用的序列化方式,如PDX或DataSerializer,PDX可以不用反序列化整個資料物件,就讀到其中的欄位的值,還能相容多版本的物件;DataSerializable則提供了更快速的序列化。