資料結構與演演算法【Java】08---樹結構的實際應用
前言
資料 data 結構(structure)是一門 研究組織資料方式的學科,有了程式語言也就有了資料結構.學好資料結構才可以編寫出更加漂亮,更加有效率的程式碼。
- 要學習好資料結構就要多多考慮如何將生活中遇到的問題,用程式去實現解決.
- 程式 = 資料結構 + 演演算法
- 資料結構是演演算法的基礎, 換言之,想要學好演演算法,需要把資料結構學到位
我會用資料結構與演演算法【Java】這一系列的部落格記錄自己的學習過程,如有遺留和錯誤歡迎大家提出,我會第一時間改正!!!
注:資料結構與演演算法【Java】這一系列的部落格參考於B站尚矽谷的視訊,視訊原地址為【尚矽谷】資料結構與演演算法(Java資料結構與演演算法)
上一篇文章資料結構與演演算法【Java】07---樹結構基礎部分
1、堆排序
1.1、堆排序簡介
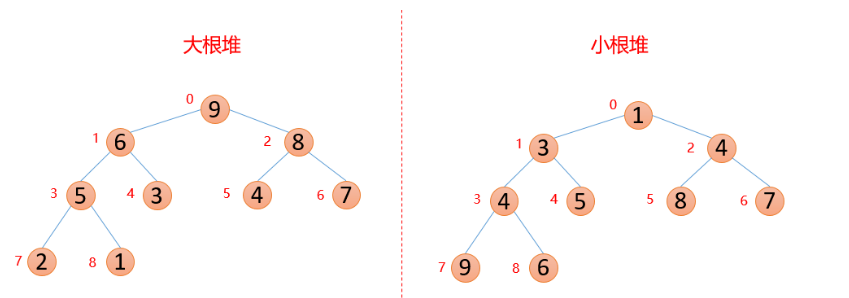
1.堆排序是利用堆這種資料結構而設計的一種排序演演算法,堆排序是一種選擇排序,它的最壞,最好,平均時間複雜度均為 O(nlogn),它是不穩定排序。
-
堆是具有以下性質的完全二元樹:每個結點的值都大於或等於其左右孩子結點的值,稱為大根堆(或大頂堆), 注意 : 沒有
要求結點的左孩子的值和右孩子的值的大小關係。 -
每個結點的值都小於或等於其左右孩子結點的值,稱為小根堆(或小頂堆)
-
一般升序採用大根堆,降序採用小根堆

1.2、堆排序過程演示
堆排序的基本思想是:
- 將待排序序列構造成一個大根堆
- 此時,整個序列的最大值就是堆頂的根節點。
- 將其與末尾元素進行交換,此時末尾就為最大值。
- 然後將剩餘 n-1 個元素重新構造成一個堆,這樣會得到 n 個元素的次小值。如此反覆執行,便能得到一個有序
序列了。
步驟圖解
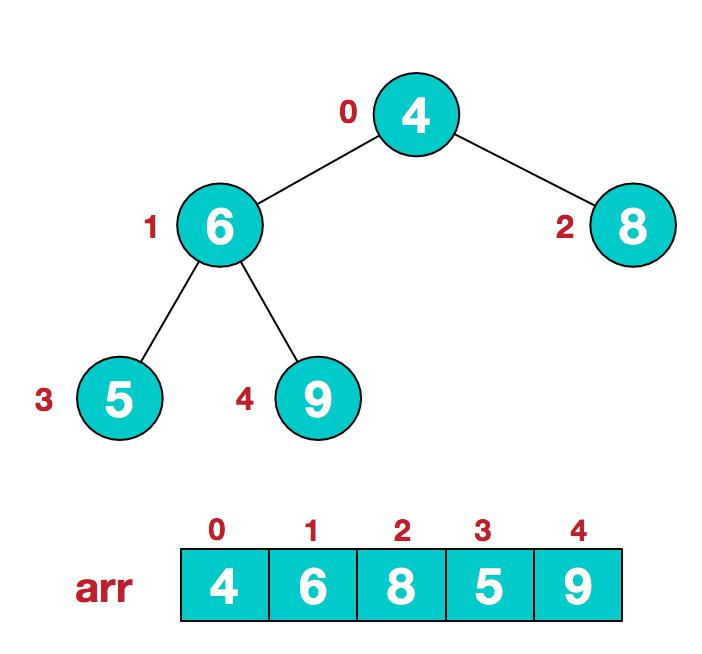
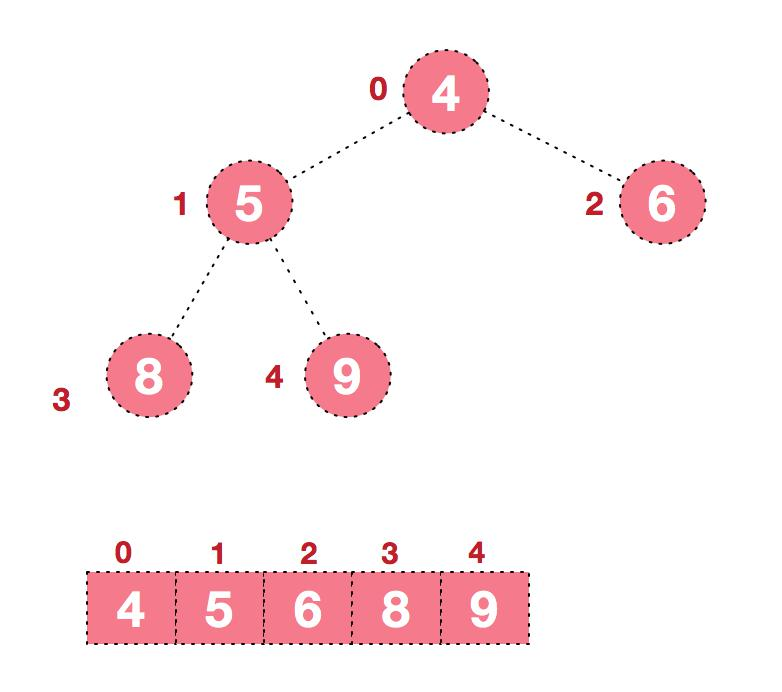
要求:給你一個陣列 {4,6,8,5,9} , 要求使用堆排序法,將陣列升序排序。
- 步驟一 構造初始堆。將給定無序序列構造成一個大根堆(一般升序採用大根堆,降序採用小根堆)。
- 原始的陣列 [4, 6, 8, 5, 9]
-
假設給定無序序列結構如下
-
此時我們從最後一個非葉子結點開始(葉結點自然不用調整,第一個非葉子結點
arr.length/2-1=5/2-1=1,也就是下面的 6 結點),從左至右,從下至上進行調整。
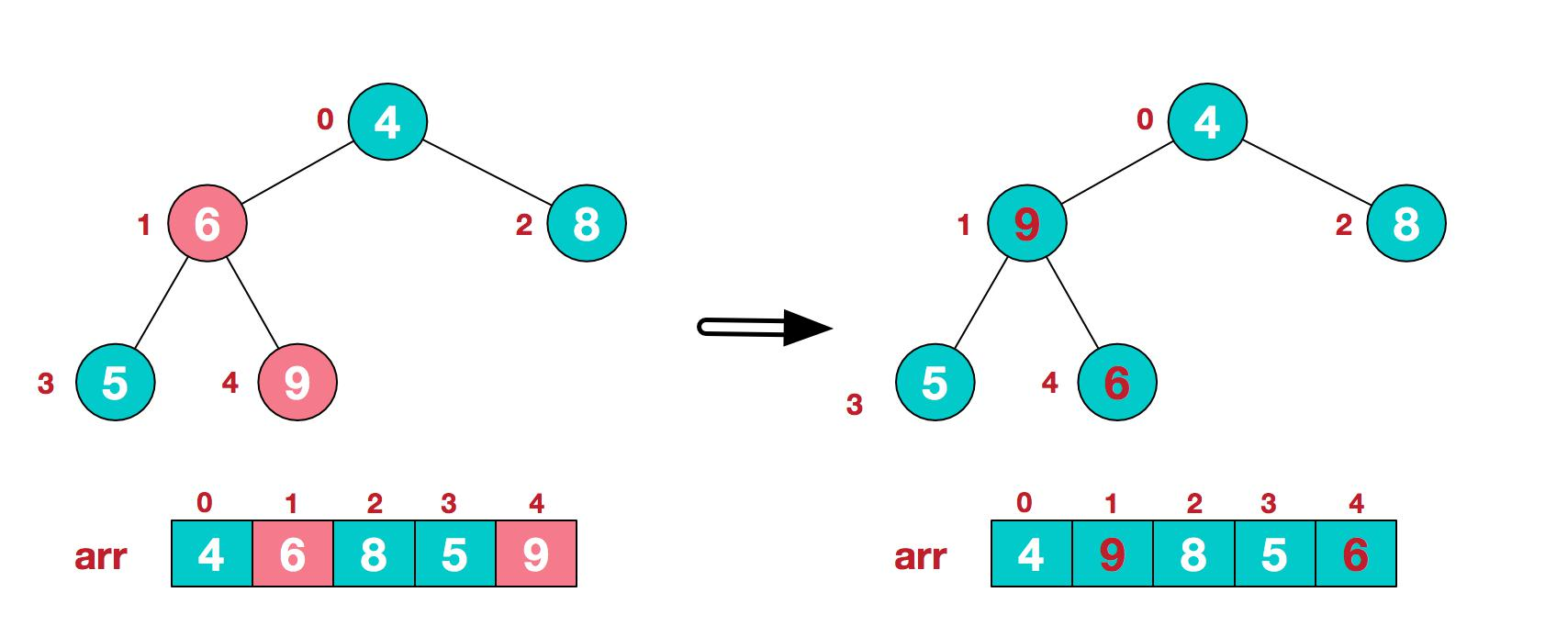
3.找到第二個非葉節點 4,由於[4,9,8]中 9 元素最大,4 和 9 交換。
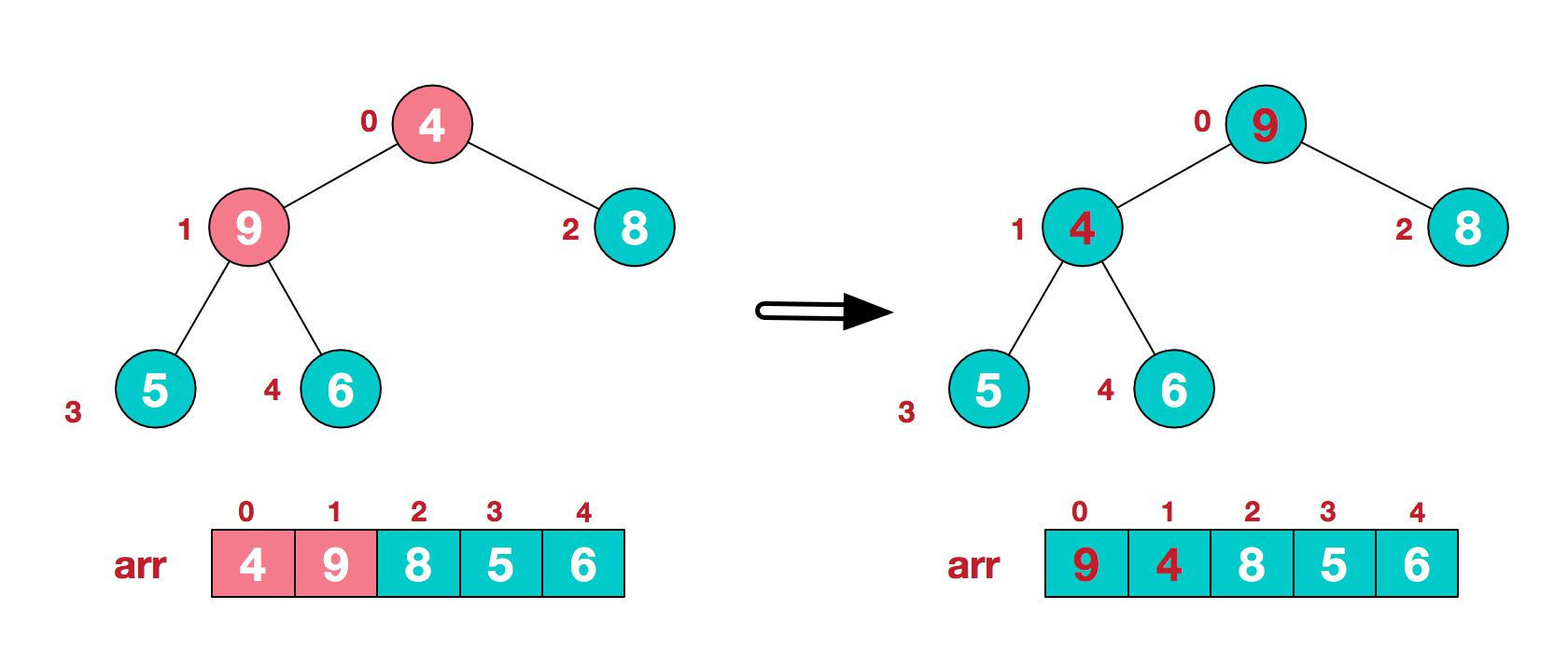
4.這時,交換導致了子根[4,5,6]結構混亂,繼續調整,[4,5,6]中 6 最大,交換 4 和 6。
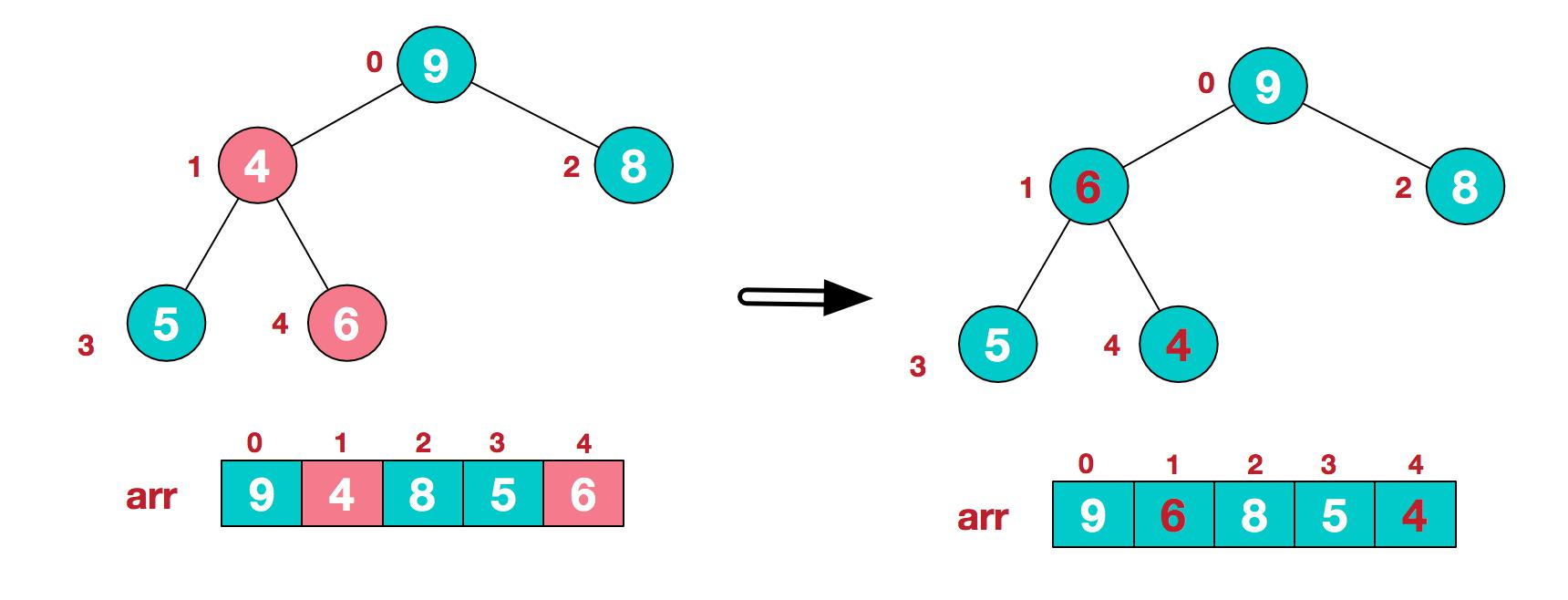
此時,我們就將一個無序序列構造成了一個大頂堆.
- 步驟二 將堆頂元素與末尾元素進行交換,使末尾元素最大。然後繼續調整堆,再將堆頂元素與末尾元素交換得到第二大元素。如此反覆進行交換、重建、交換
1.將堆頂元素 9 和末尾元素 4 進行交換
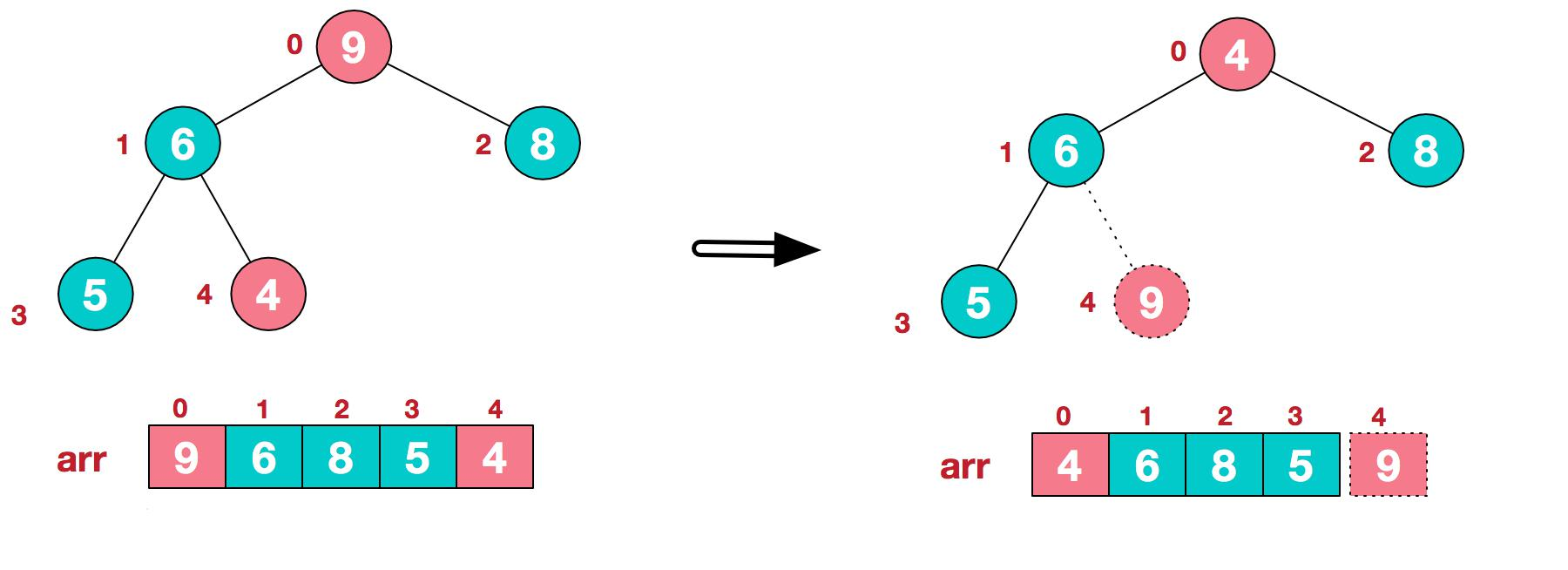
2.重新調整結構,使其繼續滿足堆定義
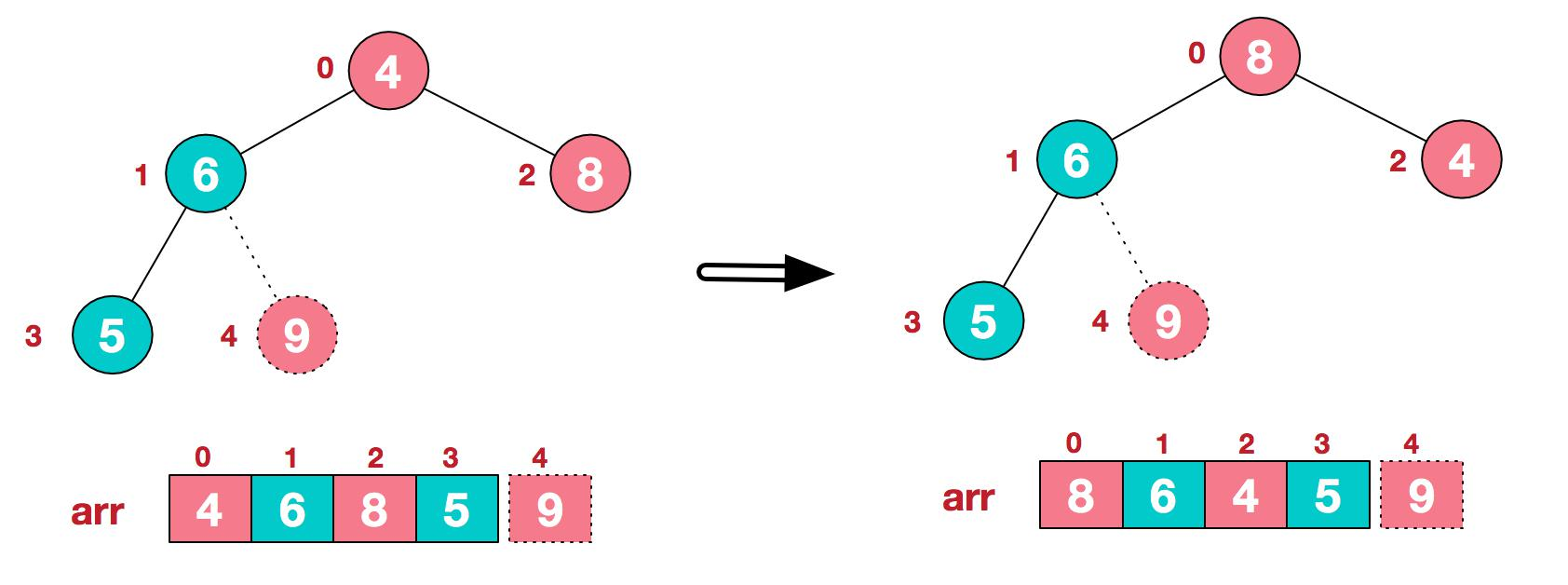
3.再將堆頂元素 8 與末尾元素 5 進行交換,得到第二大元素 8
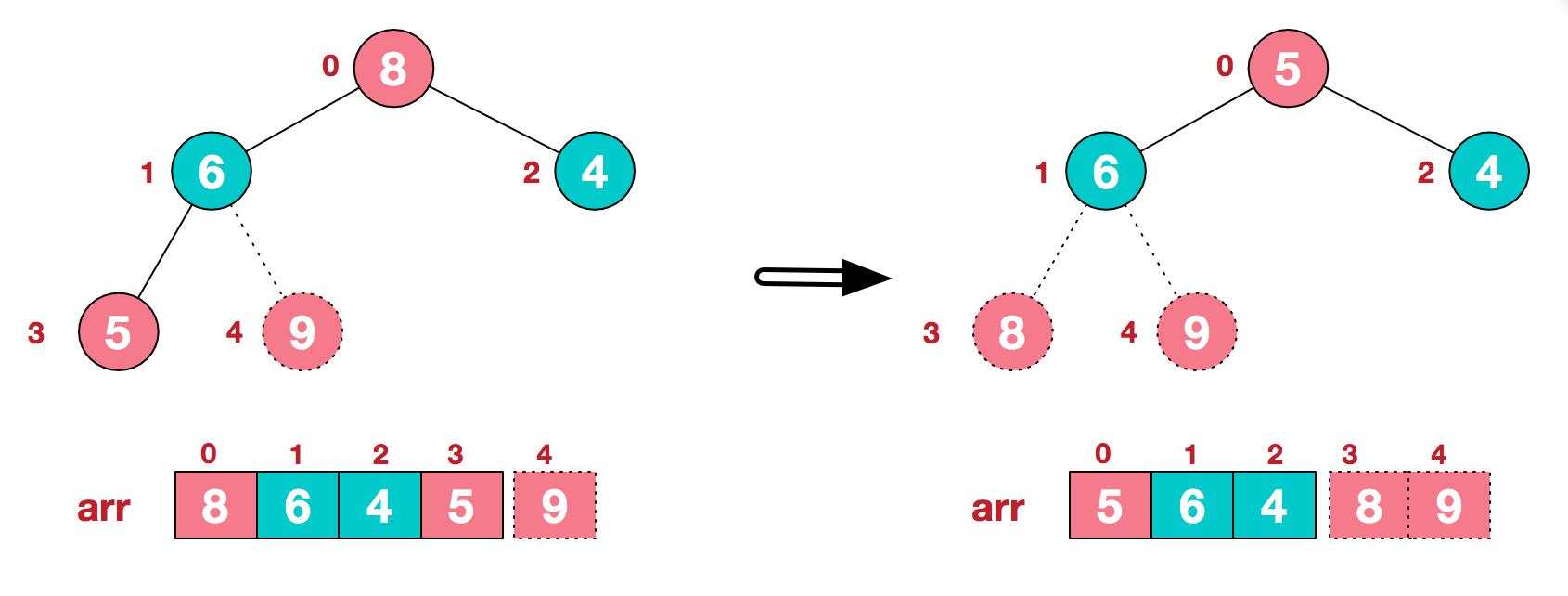
4.後續過程,繼續進行調整,交換,如此反覆進行,最終使得整個序列有序
再簡單總結下堆排序的基本思路:
1).將無序序列構建成一個堆,根據升序降序需求選擇大根堆或小根堆;
2).將堆頂元素與末尾元素交換,將最大元素"沉"到陣列末端;
3).重新調整結構,使其滿足堆定義,然後繼續交換堆頂元素與當前末尾元素,反覆執行調整+交換步驟,直到整個序列有序
動態演示

1.3、堆排序程式碼實現
堆排序的理解還是比較困難的,尤其是程式碼實現過程,下面提供兩種程式碼實現,大家可以選擇適合自己的實現方法來理解堆排序
程式碼實現(一)
import java.util.Arrays;
public class HeapSort {
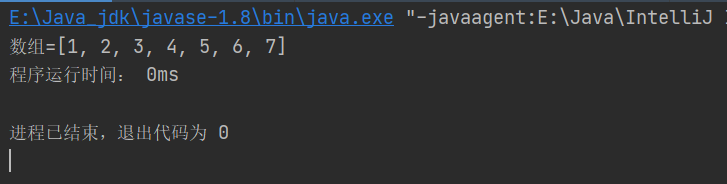
public static void main(String[] args) {
//升序--->大頂堆
long startTime=System.currentTimeMillis();
int arr[] = {5,3,7,1,4,6,2};
heapSort(arr);
long endTime=System.currentTimeMillis();
System.out.println("程式執行時間: "+(endTime-startTime)+"ms");
}
//編寫一個堆排序的方法
public static void heapSort(int arr[]) {
int temp = 0;
//完成我們最終程式碼
//將無序序列構建成一個堆,根據升序降序需求選擇大頂堆或小頂堆
for(int i = arr.length / 2 -1; i >=0; i--) {
adjustHeap(arr, i, arr.length);
}
/*
* 2).將堆頂元素與末尾元素交換,將最大元素"沉"到陣列末端;
3).重新調整結構,使其滿足堆定義,然後繼續交換堆頂元素與當前末尾元素,反覆執行調整+交換步驟,直到整個序列有序。
*/
for(int j = arr.length-1;j >0; j--) {
//交換
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
adjustHeap(arr, 0, j);
}
System.out.println("陣列=" + Arrays.toString(arr));
}
//將一個陣列(二元樹), 調整成一個大頂堆
/**
* 功能: 完成 將 以 i 對應的非葉子結點的樹調整成大頂堆
* 舉例 int arr[] = {4, 6, 8, 5, 9}; => i = 1 => adjustHeap => 得到 {4, 9, 8, 5, 6}
* 如果我們再次呼叫 adjustHeap 傳入的是 i = 0 => 得到 {4, 9, 8, 5, 6} => {9,6,8,5, 4}
* @param arr 待調整的陣列
* @param i 表示非葉子結點在陣列中索引
* @param length 表示對多少個元素繼續調整, length 是在逐漸的減少
*/
public static void adjustHeap(int arr[], int i, int length) {
int temp = arr[i];//先取出當前元素的值,儲存在臨時變數
//開始調整
//說明
//1. k = i * 2 + 1 k 是 i結點的左子結點
for(int k = i * 2 + 1; k < length; k = k * 2 + 1) {
if(k+1 < length && arr[k] < arr[k+1]) { //說明左子結點的值小於右子結點的值
k++; // k 指向右子結點
}
if(arr[k] > temp) { //如果子結點大於父結點
arr[i] = arr[k]; //把較大的值賦給當前結點
i = k; //!!! i 指向 k,繼續迴圈比較
} else {
break;//!
}
}
//當for 迴圈結束後,我們已經將以i 為父結點的樹的最大值,放在了 最頂(區域性)
arr[i] = temp;//將temp值放到調整後的位置
}
}
結果:
程式碼實現(二)
//交換陣列中的元素
public static void swap(int[]num ,int i,int j) {
int temp=num[i];
num[i]=num[j];
num[j]=temp;
}
//將待排序的陣列構建成大根堆
public static void buildbigheap(int []num,int end) {
//從最後一個非葉子節點開始構建,依照從下往上,從右往左的順序
for(int i=end/2;i>=0;i--) {
adjustnode(i, end, num);
}
}
//調整該節點及其以下的所有節點
public static void adjustnode(int i,int end,int []num) {
int left=2*i+1;
int right=2*i+2;
int big=i;
//判斷小分支那個是大元素
if(left<end&&num[i]<num[left])
i=left;
if(right<end&&num[i]<num[right])
i=right;
if(i!=big) {
//交換順序之後需要繼續校驗
swap(num, i, big);
//重新校驗,防止出現交換之後根節點小於孩子節點的情況
adjustnode(i, end, num);
}
}
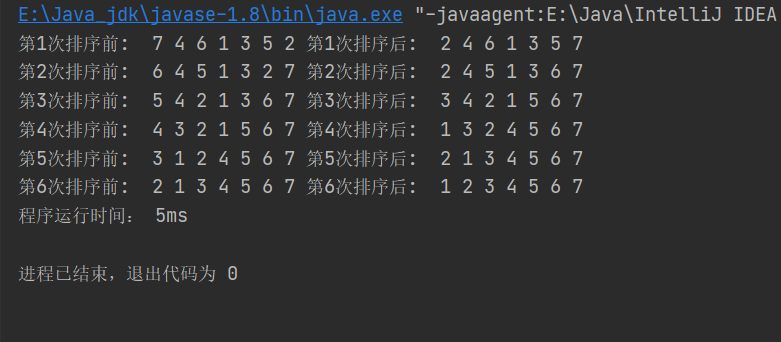
public static void main(String[] args) {
int []num ={5,3,7,1,4,6,2};
long startTime=System.currentTimeMillis();
//第一次構建大根堆
buildbigheap(num, num.length);
for(int j=num.length-1;j>0;j--) {
System.out.print("第"+(num.length-j)+"次排序前: ");
for(int k=0;k<num.length;k++) {
System.out.print(num[k]+" ");
}
//交換隊頭已經排序得到的最大元素與隊尾元素
swap(num, 0, j);
System.out.print("第"+(num.length-j)+"次排序後: ");
for(int k=0;k<num.length;k++) {
System.out.print(num[k]+" ");
}
System.out.println();
//交換結束之後,大根堆已經被破壞,需要開始重新構建大根堆
buildbigheap(num,j);
}
long endTime=System.currentTimeMillis();
System.out.println("程式執行時間: "+(endTime-startTime)+"ms");
}
結果:
2、赫夫曼樹
2.1、簡介
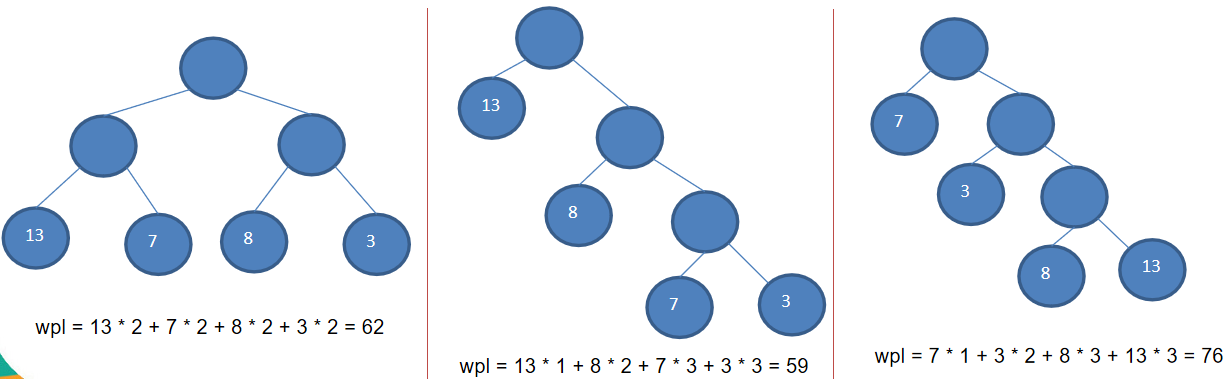
1、給定 n 個權值作為 n 個葉子結點,構造一棵二元樹, 若該樹的帶權路徑長度(wpl) 達到最小,稱這樣的二元樹為
最優二元樹,也稱為哈夫曼樹(Huffman Tree), 還有的書翻譯為霍夫曼樹。
2、赫夫曼樹是帶權路徑長度最短的樹,權值較大的結點離根較近
重要概念和舉例說明
- 路徑和路徑長度:在一棵樹中,從一個結點往下可以達到的孩子或孫子結點之間的通路,稱為路徑。通中分支的數目稱為路徑長度。若規定根結點的層數為 1,則從根結點到第 L 層結點的路徑長度為 L-1
- 結點的權及帶權路徑長度:若將樹中結點賦給一個有著某種含義的數值,則這個數值稱為該結點的權。 結
點的帶權路徑長度為:從根結點到該結點之間的路徑長度與該結點的權的乘積 - 樹的帶權路徑長度:樹的帶權路徑長度規定為 所有葉子結點的帶權路徑長度之和,記為
WPL(weighted path length),權值越大的結點離根結點越近的二元樹才是最優二元樹。 - WPL 最小的就是赫夫曼樹
2.2、赫夫曼樹建立思路圖解
給出一個數列 {13, 7, 8, 3, 29, 6, 1},要求轉成一顆赫夫曼樹
構成赫夫曼樹的步驟:
- 從小到大進行排序, 將每一個資料,每個資料都是一個節點 , 每個節點可以看成是一顆最簡單的二元樹
- 取出根節點權值最小的兩顆二元樹
- 組成一顆新的二元樹, 該新的二元樹的根節點的權值是前面兩顆二元樹根節點權值的和
- 再將這顆新的二元樹,以根節點的權值大小 再次排序, 不斷重複 1-2-3-4 的步驟,直到數列中,所有的數
據都被處理,就得到一顆赫夫曼樹
圖解:
(1)選出最小的兩個陣列成二元樹
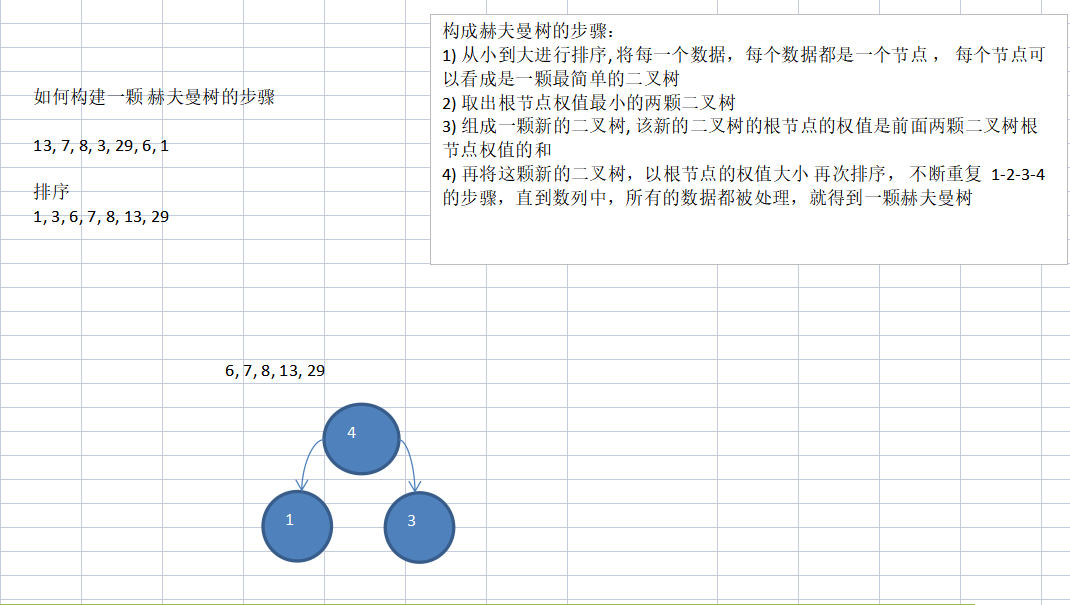
(2)接下來在4,6,7,8...中選擇最小的兩個4,6(注意這裡要加入第一步組成的節點4,大的在右邊,小的在左邊)
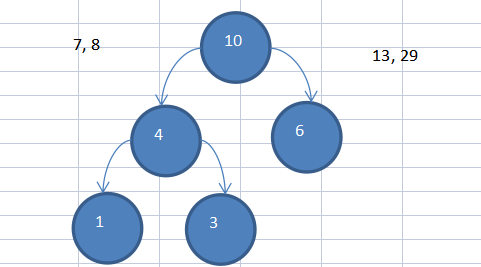
(3)重複上述步驟
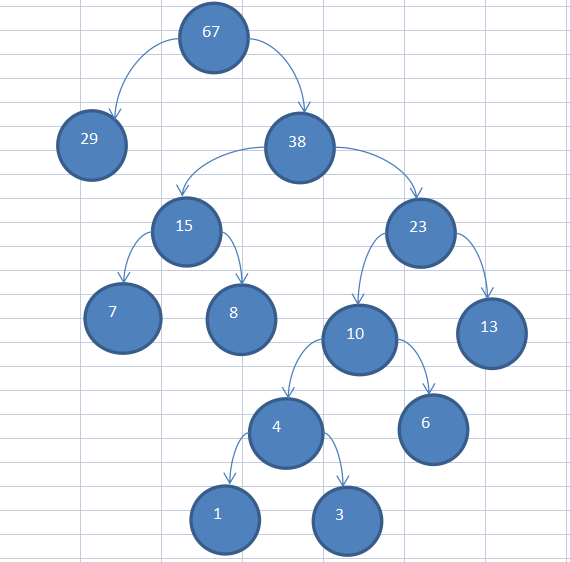
2.3、赫夫曼樹程式碼實現
public class HuffmanTree {
public static void main(String[] args) {
int arr[] = { 13, 7, 8, 3, 29, 6, 1 };
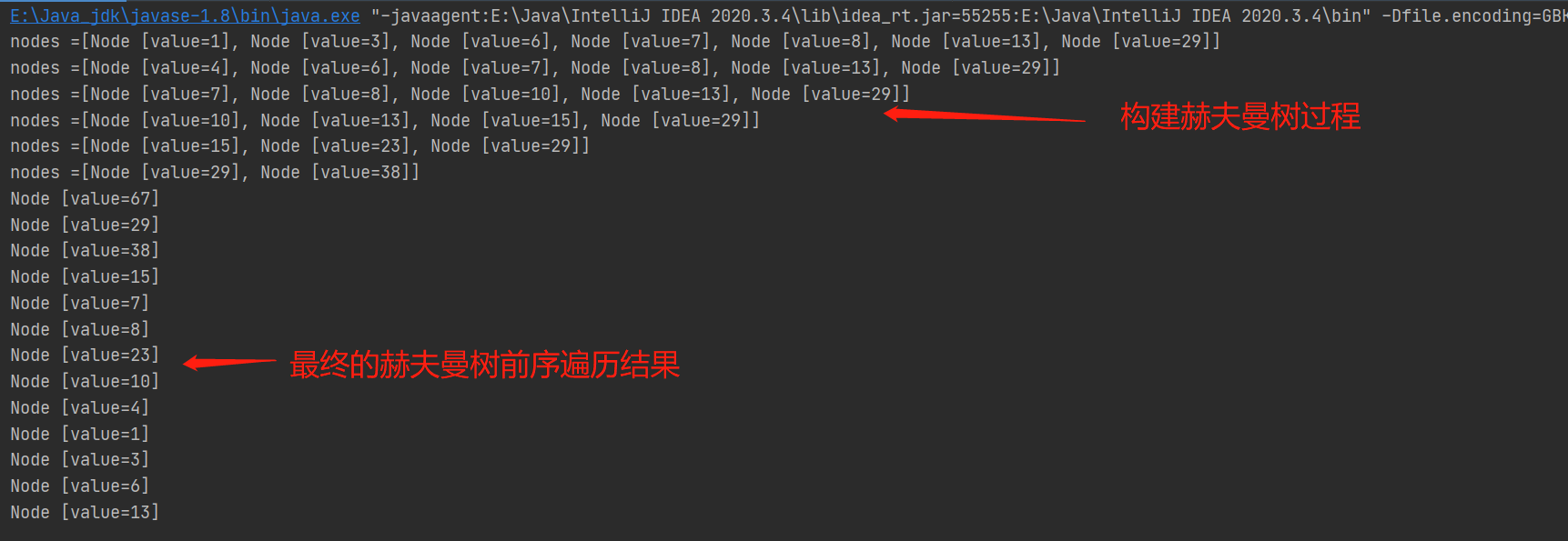
Node root = createHuffmanTree(arr);
preOrder(root); //67,29,38,15,7,8,23,10,4,1,3,6,13
}
//編寫一個前序遍歷的方法
public static void preOrder(Node root) {
if(root != null) {
root.preOrder();
}else{
System.out.println("是空樹,不能遍歷~~");
}
}
// 建立赫夫曼樹的方法
/**
*
* @param arr 需要建立成哈夫曼樹的陣列
* @return 建立好後的赫夫曼樹的root結點
*/
public static Node createHuffmanTree(int[] arr) {
// 第一步為了操作方便
// 1. 遍歷 arr 陣列
// 2. 將arr的每個元素構成成一個Node
// 3. 將Node 放入到ArrayList中
List<Node> nodes = new ArrayList<Node>();
for (int value : arr) {
nodes.add(new Node(value));
}
//我們處理的過程是一個迴圈的過程
while(nodes.size() > 1) {
//排序 從小到大
Collections.sort(nodes);
System.out.println("nodes =" + nodes);
//取出根節點權值最小的兩顆二元樹
//(1) 取出權值最小的結點(二元樹)
Node leftNode = nodes.get(0);
//(2) 取出權值第二小的結點(二元樹)
Node rightNode = nodes.get(1);
//(3)構建一顆新的二元樹
Node parent = new Node(leftNode.value + rightNode.value);
parent.left = leftNode;
parent.right = rightNode;
//(4)從ArrayList刪除處理過的二元樹
nodes.remove(leftNode);
nodes.remove(rightNode);
//(5)將parent加入到nodes
nodes.add(parent);
}
//返回哈夫曼樹的root結點
return nodes.get(0);
}
}
// 建立結點類
// 為了讓Node 物件持續排序Collections集合排序
// 讓Node 實現Comparable介面
class Node implements Comparable<Node> {
int value; // 結點權值
char c; //字元
Node left; // 指向左子結點
Node right; // 指向右子結點
//寫一個前序遍歷
public void preOrder() {
System.out.println(this);
if (this.left != null) {
this.left.preOrder();
}
if (this.right != null) {
this.right.preOrder();
}
}
public Node(int value) {
this.value = value;
}
@Override
public String toString() {
return "Node [value=" + value + "]";
}
@Override
public int compareTo(Node o) {
// TODO Auto-generated method stub
// 表示從小到大排序
return this.value - o.value;
}
}
結果:
3、赫夫曼編碼
3.1、簡介
- 赫夫曼編碼也翻譯為 哈夫曼編碼(Huffman Coding),又稱霍夫曼編碼,是一種編碼方式, 屬於一種程式演演算法
- 赫夫曼編碼是赫哈夫曼樹在電訊通訊中的經典的應用之一。
- 赫夫曼編碼廣泛地用於資料檔案壓縮。其壓縮率通常在 20%~90%之間
- 赫夫曼碼是可變字長編碼(VLC)的一種。Huffman 於 1952 年提出一種編碼方法,稱之為最佳編碼
3.2、原理剖析
- 通訊領域中資訊的處理方式 1-定長編碼

- 通訊領域中資訊的處理方式 2-變長編碼

- 通訊領域中資訊的處理方式 3-赫夫曼編碼
1、傳輸的 字串i like like like java do you like a java
2、d:1 y:1 u:1 j:2 v:2 o:2 l:4 k:4 e:4 i:5 a:5 :9 // 各個字元對應的個數
3、按照上面字元出現的次數構建一顆赫夫曼樹, 次數作為權值
構成赫夫曼樹的步驟:
- 從小到大進行排序, 將每一個資料,每個資料都是一個節點 , 每個節點可以看成是一顆最簡單的二元樹
- 取出根節點權值最小的兩顆二元樹
- 組成一顆新的二元樹, 該新的二元樹的根節點的權值是前面兩顆二元樹根節點權值的和
- 再將這顆新的二元樹,以根節點的權值大小 再次排序, 不斷重複 1-2-3-4 的步驟,直到數列中,所有的資料都被處理,
就得到一顆赫夫曼樹
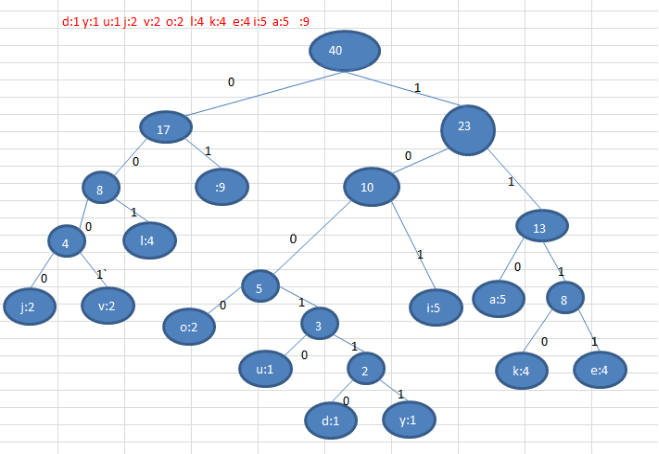
4、根據赫夫曼樹,給各個字元,規定編碼 (字首編碼), 向左的路徑為 0 向右的路徑為 1 , 編碼如下:
o: 1000
u: 10010
d: 100110
y: 100111
i: 101
a : 110
k: 1110
e: 1111
j: 0000
v: 0001
l: 001
: 01(空格)
5、按照上面的赫夫曼編碼,我們的"i like like like java do you like a java" 字串對應的編碼為 (注意這裡我們使用的無失真壓縮)
1010100110111101111010011011110111101001101111011110100001100001110011001111000011001111000100100100110111101111011100100001100001110
通過赫夫曼編碼處理 長度為 133,且不會有多義性
6、長度為 : 133
說明:原來長度是359 , 壓縮了 (359-133) / 359 = 62.9%
此編碼滿足字首編碼, 即字元的編碼都不能是其他字元編碼的字首。不會造成匹配的多義性
赫夫曼編碼是無失真處理方案(可以完全恢復)
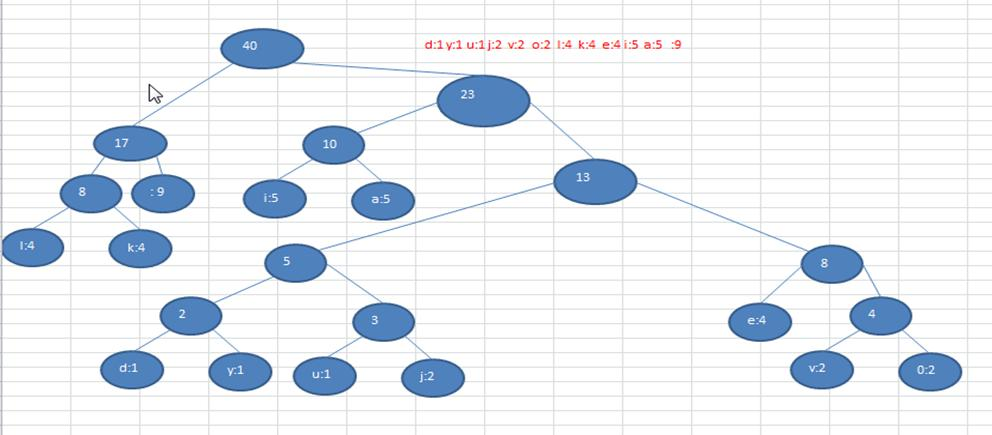
注:這個赫夫曼樹根據 排序方法不同,也可能不太一樣,這樣對應的 赫夫曼編碼也不完全一樣,但是 wpl 是
一樣的,都是最小的, 最後生成的赫夫曼編碼的長度是一樣,比如: 如果我們讓每次生成的新的二元樹總是排在權
值相同的二元樹的最後一個,則生成的二元樹如下圖,但是編碼長度是不會變的,還是133
3.3、建立赫夫曼樹(資料壓縮)
將給出的一段文字,比如"i like like like java do you like a java", 根據前面的講的赫夫曼編碼原理,對其進行數
據 壓 縮 處 理 , 形 式 如
"1010100110111101111010011011110111101001101111011110100001100001110011001111000011001111000100100100 110111101111011100100001100001110"
功能: 根據赫夫曼編碼壓縮資料的原理,需要建立 "i like like like java do you like a java" 對應的赫夫曼樹
思路:
(1) Node { data (存放資料), weight (權值), left 和 right }
(2) 得到 "i like like like java do you like a java" 對應的 byte[] 陣列
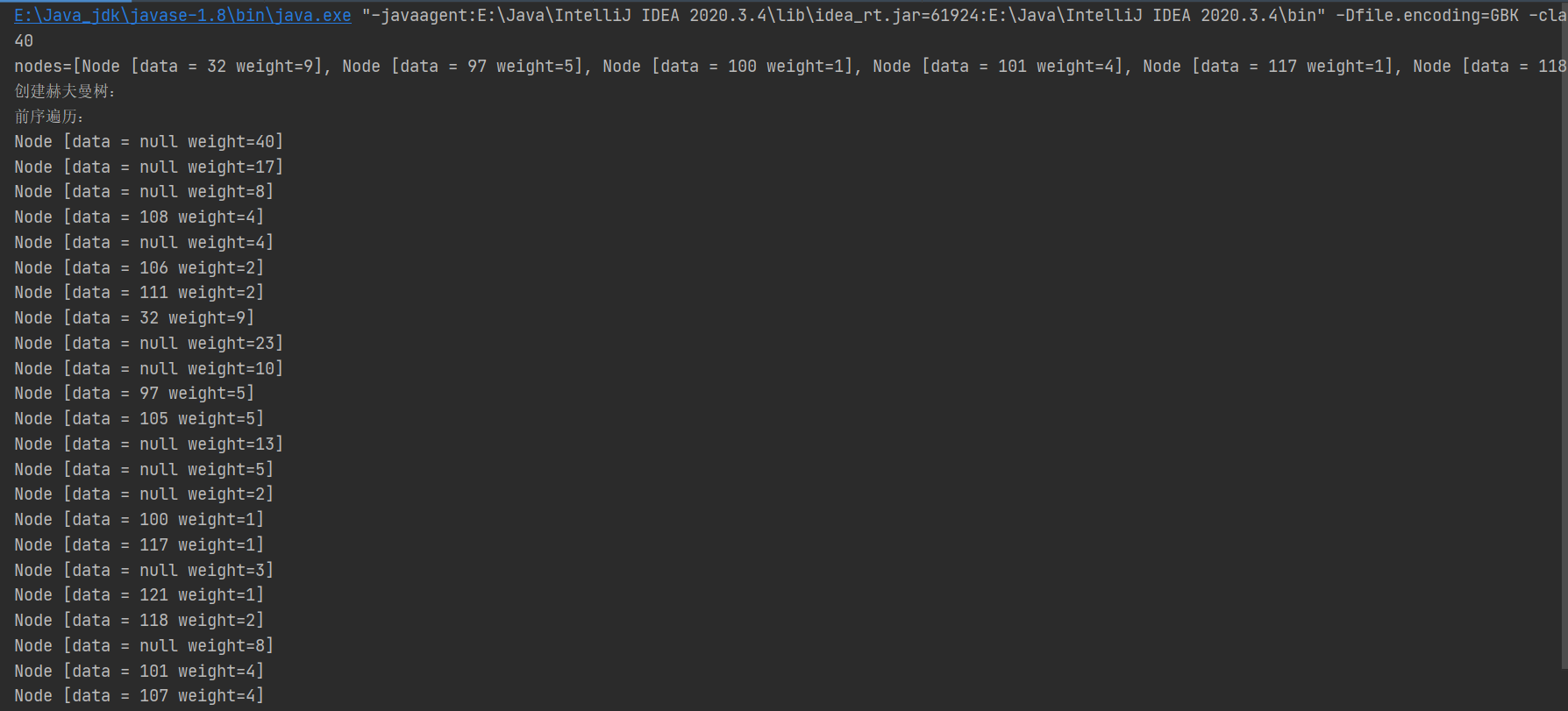
(3) 編寫一個方法,將準備構建赫夫曼樹的Node 節點放到 List , 形式 [Node[date=97 ,weight = 5], Node[]date=32,weight = 9]......], 體現 d:1 y:1 u:1 j:2 v:2 o:2 l:4 k:4 e:4 i:5 a:5 :9
(4) 可以通過List 建立對應的赫夫曼樹
程式碼實現
import java.util.*;
public class HuffmanCode {
public static void main(String[] args) {
String content = "i like like like java do you like a java";
byte[] contentBytes = content.getBytes();
System.out.println(contentBytes.length);//40
List<Node> nodes = getNodes(contentBytes);
System.out.println("nodes="+nodes);
//測試建立的二元樹
System.out.println("建立赫夫曼樹:");
Node huffmanTreeRoot = createHuffmanTree(nodes);
System.out.println("前序遍歷:");
huffmanTreeRoot.preOrder();
}
//前序遍歷的方法
public static void preOrder(Node root){
if (root != null){
root.preOrder();
}else {
System.out.println("赫夫曼樹為空");
}
}
/**
*
* @param bytes 接收位元組陣列
* @return 返回的就是 List 形式 [Node[date=97 ,weight = 5], Node[]date=32,weight = 9]......],
*/
private static List<Node> getNodes(byte[] bytes){
//1.建立一個ArrayList
ArrayList<Node> nodes = new ArrayList<>();
//遍歷bytes,儲存每一個byte出現的次數=》map[key,value]
HashMap<Byte,Integer> counts = new HashMap<>();
for (byte b: bytes) {
Integer count = counts.get(b);
if (count == null){//Map還沒有這個資料
counts.put(b,1);
}else {
counts.put(b,count+1);
}
}
//把每個鍵值對轉成一個Node物件,並加入到nodes集合
//遍歷map
for (Map.Entry<Byte,Integer> entry : counts.entrySet()){
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
//通過list建立應的赫夫曼樹
private static Node createHuffmanTree(List<Node> nodes){
while (nodes.size() > 1){
//排序,從小到大
Collections.sort(nodes);
//取出第一棵最小的二元樹左節點
Node leftNode = nodes.get(0);
//取出第二棵最小的二元樹右節點
Node rightNode = nodes.get(1);
//建立一棵新的二元樹,它的根節點沒有data,只有權值
Node parent = new Node(null, leftNode.weight+ rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
//將已經處理的兩棵二元樹從nodes刪除
nodes.remove(leftNode);
nodes.remove(rightNode);
//將新的二元樹加入到nodes
nodes.add(parent);
}
//nodes 最後的節點就是赫夫曼樹的根節點
return nodes.get(0);
}
}
//建立Node,帶資料和權值
class Node implements Comparable<Node>{
Byte data;//存放資料本身 a===>97 ascii碼
int weight;//權值,表示字元出現的次數
Node left;
Node right;
public Node(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
@Override
public int compareTo(Node o) {
//從小到大排序
return this.weight-o.weight;
}
public String toString() {
return "Node [data = " + data + " weight=" + weight + "]";
}
//前序遍歷
public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
}
}
結果:(建立出赫夫曼樹前序遍歷)
3.4、生成赫夫曼編碼和赫夫曼編碼後的資料(資料壓縮)
我們已經生成了 赫夫曼樹, 下面我們繼續完成任務
- 生成赫夫曼樹對應的赫夫曼編碼 , 如下表:
=01 a=100 d=11000 u=11001 e=1110 v=11011 i=101 y=11010 j=0010 k=1111 l=000 o=0011 - 使用赫夫曼編碼來生成赫夫曼編碼資料 ,即按照上面的赫夫曼編碼,將"i like like like java do you like a java"
字串生成對應的編碼資料, 形式如下.
10101000101111111100100010111111110010001011111111001001010011011100011100000110111010001111001010 00101111111100110001001010011011100
1、生成赫夫曼樹對應的赫夫曼編碼
程式碼實現
//測試是否生成了對應的赫夫曼編碼
Map<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot);
System.out.println("生成的對應的赫夫曼編碼="+ HuffmanCode.huffmanCodes);
//...
//生成赫夫曼樹對應的赫夫曼編碼
//思路:
//1. 將赫夫曼編碼表存放在 Map<Byte,String> 形式
// 生成的赫夫曼編碼表{32(空格)=01, 97(a)=100, 100(...)=11000, 117=11001, 101=1110, 118=11011, 105=101, 121=11010, 106=0010, 107=1111, 108=000, 111=0011}
static Map<Byte, String> huffmanCodes = new HashMap<Byte,String>();
//2. 在生成赫夫曼編碼表示,需要去拼接路徑, 定義一個StringBuilder 儲存某個葉子結點的路徑
static StringBuilder stringBuilder = new StringBuilder();
//為了呼叫方便,我們過載 getCodes
private static Map<Byte, String> getCodes(Node root) {
if(root == null) {
return null;
}
//處理root的左子樹
getCodes(root.left, "0", stringBuilder);
//處理root的右子樹
getCodes(root.right, "1", stringBuilder);
return huffmanCodes;
}
/**
* 功能:將傳入的node結點的所有葉子結點的赫夫曼編碼得到,並放入到huffmanCodes集合
* @param node 傳入結點
* @param code 路徑: 左子結點是 0, 右子結點 1
* @param stringBuilder 用於拼接路徑
*/
private static void getCodes(Node node,String code,StringBuilder stringBuilder){
StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);
//將code加入到 stringBuilder2 (拼接路徑)
stringBuilder2.append(code);
if (node != null){//如果node等於空,不處理
//判斷當前node是葉子節點還是非葉子結點
if (node.data == null){//非葉子節點
//遞迴處理
//向左遞迴
getCodes(node.left, "0", stringBuilder2);
//向右遞迴
getCodes(node.right, "1", stringBuilder2);
}else {//進入到這裡說明是葉子節點,找到了最後
huffmanCodes.put(node.data,stringBuilder2.toString());
}
}
}
結果:

2、使用赫夫曼編碼來生成赫夫曼編碼資料
程式碼實現
//測試返回byte陣列
byte[] huffmanCodeBytes = zip(contentBytes, huffmanCodes);
System.out.println("huffmanCodeBytes="+Arrays.toString(huffmanCodeBytes));//17
//...
//編寫一個方法,將字串對應的byte[] 陣列,通過生成的赫夫曼編碼表,返回一個赫夫曼編碼 壓縮後的byte[]
/**
*
* @param bytes 這是原始的字串對應的 byte[]
* @param huffmanCodes 生成的赫夫曼編碼map
* @return 返回赫夫曼編碼處理後的 byte[]
* 舉例: String content = "i like like like java do you like a java"; =》 byte[] contentBytes = content.getBytes();
* 返回的是 字串 "1010100010111111110010001011111111001000101111111100100101001101110001110000011011101000111100101000101111111100110001001010011011100"
* => 對應的 byte[] huffmanCodeBytes ,即 8位元對應一個 byte,放入到 huffmanCodeBytes
* huffmanCodeBytes[0] = 10101000(二補數) => byte [推導 10101000=> 10101000 - 1 => 10100111(反碼)=> 11011000(原碼)= -88 ]
* huffmanCodeBytes[1] = -88
*/
private static byte[] zip(byte[] bytes, Map<Byte, String> huffmanCodes) {
//1.利用 huffmanCodes 將 bytes 轉成 赫夫曼編碼對應的字串
StringBuilder stringBuilder = new StringBuilder();
//遍歷bytes 陣列
for(byte b: bytes) {
stringBuilder.append(huffmanCodes.get(b));
}
//System.out.println("測試 stringBuilder~~~=" + stringBuilder.toString());
//將 "1010100010111111110..." 轉成 byte[]
//統計返回 byte[] huffmanCodeBytes 長度
//一句話 int len = (stringBuilder.length() + 7) / 8;
int len;
if(stringBuilder.length() % 8 == 0) {
len = stringBuilder.length() / 8;
} else {
len = stringBuilder.length() / 8 + 1;
}
//建立 儲存壓縮後的 byte陣列
byte[] huffmanCodeBytes = new byte[len];
int index = 0;//記錄是第幾個byte
for (int i = 0; i < stringBuilder.length(); i += 8) { //因為是每8位元對應一個byte,所以步長 +8
String strByte;
if(i+8 > stringBuilder.length()) {//不夠8位元
strByte = stringBuilder.substring(i);
}else{
strByte = stringBuilder.substring(i, i + 8);
}
//將strByte 轉成一個byte,放入到 huffmanCodeBytes
huffmanCodeBytes[index] = (byte)Integer.parseInt(strByte, 2);
index++;
}
return huffmanCodeBytes;
}
3.5、資料壓縮小結
將3.3與3.4中編寫的所有方法封裝成一個方法
//使用一個方法,將前面的方法封裝起來,便於我們的呼叫
/**
* @param bytes 原始的字串對應的位元組陣列
* @return 是經過 赫夫曼編碼處理後的位元組陣列(壓縮後的陣列)
*/
private static byte[] huffmanZip(byte[] bytes){
List<Node> nodes = getNodes(bytes);
//根據nodes建立的赫夫曼樹
Node huffmanTreeRoot = createHuffmanTree(nodes);
//生成對應的赫夫曼編碼(根據赫夫曼樹)
Map<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot);
//根據生成的赫夫曼編碼來對原始的位元組陣列進行壓縮
byte[] huffmanCodeBytes = zip(bytes, huffmanCodes);
return huffmanCodeBytes;
}
資料壓縮的所有程式碼
import java.util.*;
public class HuffmanCode {
public static void main(String[] args) {
String content = "i like like like java do you like a java";
byte[] contentBytes = content.getBytes();
System.out.println("原始的content字串長度為:"+contentBytes.length);//40
byte[] huffmanCodesBytes = huffmanZip(contentBytes);
System.out.println("對content字串壓縮後的結果是:"+Arrays.toString(huffmanCodesBytes));
System.out.println("長度為:"+huffmanCodesBytes.length);//17
}
//使用一個方法,將前面的方法封裝起來,便於我們的呼叫
/**
* @param bytes 原始的字串對應的位元組陣列
* @return 是經過 赫夫曼編碼處理後的位元組陣列(壓縮後的陣列)
*/
private static byte[] huffmanZip(byte[] bytes){
List<Node> nodes = getNodes(bytes);
//根據nodes建立的赫夫曼樹
Node huffmanTreeRoot = createHuffmanTree(nodes);
//生成對應的赫夫曼編碼(根據赫夫曼樹)
Map<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot);
//根據生成的赫夫曼編碼來對原始的位元組陣列進行壓縮
byte[] huffmanCodeBytes = zip(bytes, huffmanCodes);
return huffmanCodeBytes;
}
//編寫一個方法,將字串對應的byte[] 陣列,通過生成的赫夫曼編碼表,返回一個赫夫曼編碼 壓縮後的byte[]
/**
*
* @param bytes 這是原始的字串對應的 byte[]
* @param huffmanCodes 生成的赫夫曼編碼map
* @return 返回赫夫曼編碼處理後的 byte[]
* 舉例: String content = "i like like like java do you like a java"; =》 byte[] contentBytes = content.getBytes();
* 返回的是 字串 "1010100010111111110010001011111111001000101111111100100101001101110001110000011011101000111100101000101111111100110001001010011011100"
* => 對應的 byte[] huffmanCodeBytes ,即 8位元對應一個 byte,放入到 huffmanCodeBytes
* huffmanCodeBytes[0] = 10101000(二補數) => byte [推導 10101000=> 10101000 - 1 => 10100111(反碼)=> 11011000(原碼)= -88 ]
* huffmanCodeBytes[1] = -88
*/
private static byte[] zip(byte[] bytes, Map<Byte, String> huffmanCodes) {
//1.利用 huffmanCodes 將 bytes 轉成 赫夫曼編碼對應的字串
StringBuilder stringBuilder = new StringBuilder();
//遍歷bytes 陣列
for(byte b: bytes) {
stringBuilder.append(huffmanCodes.get(b));
}
//System.out.println("測試 stringBuilder~~~=" + stringBuilder.toString());
//將 "1010100010111111110..." 轉成 byte[]
//統計返回 byte[] huffmanCodeBytes 長度
//一句話 int len = (stringBuilder.length() + 7) / 8;
int len;
if(stringBuilder.length() % 8 == 0) {
len = stringBuilder.length() / 8;
} else {
len = stringBuilder.length() / 8 + 1;
}
//建立 儲存壓縮後的 byte陣列
byte[] huffmanCodeBytes = new byte[len];
int index = 0;//記錄是第幾個byte
for (int i = 0; i < stringBuilder.length(); i += 8) { //因為是每8位元對應一個byte,所以步長 +8
String strByte;
if(i+8 > stringBuilder.length()) {//不夠8位元
strByte = stringBuilder.substring(i);
}else{
strByte = stringBuilder.substring(i, i + 8);
}
//將strByte 轉成一個byte,放入到 huffmanCodeBytes
huffmanCodeBytes[index] = (byte)Integer.parseInt(strByte, 2);
index++;
}
return huffmanCodeBytes;
}
//生成赫夫曼樹對應的赫夫曼編碼
//思路:
//1. 將赫夫曼編碼表存放在 Map<Byte,String> 形式
// 生成的赫夫曼編碼表{32(空格)=01, 97(a)=100, 100(...)=11000, 117=11001, 101=1110, 118=11011, 105=101, 121=11010, 106=0010, 107=1111, 108=000, 111=0011}
static Map<Byte, String> huffmanCodes = new HashMap<Byte,String>();
//2. 在生成赫夫曼編碼表示,需要去拼接路徑, 定義一個StringBuilder 儲存某個葉子結點的路徑
static StringBuilder stringBuilder = new StringBuilder();
//為了呼叫方便,我們過載 getCodes
private static Map<Byte, String> getCodes(Node root) {
if(root == null) {
return null;
}
//處理root的左子樹
getCodes(root.left, "0", stringBuilder);
//處理root的右子樹
getCodes(root.right, "1", stringBuilder);
return huffmanCodes;
}
/**
* 功能:將傳入的node結點的所有葉子結點的赫夫曼編碼得到,並放入到huffmanCodes集合
* @param node 傳入結點
* @param code 路徑: 左子結點是 0, 右子結點 1
* @param stringBuilder 用於拼接路徑
*/
private static void getCodes(Node node,String code,StringBuilder stringBuilder){
StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);
//將code加入到 stringBuilder2 (拼接路徑)
stringBuilder2.append(code);
if (node != null){//如果node等於空,不處理
//判斷當前node是葉子節點還是非葉子結點
if (node.data == null){//非葉子節點
//遞迴處理
//向左遞迴
getCodes(node.left, "0", stringBuilder2);
//向右遞迴
getCodes(node.right, "1", stringBuilder2);
}else {//進入到這裡說明是葉子節點,找到了最後
huffmanCodes.put(node.data,stringBuilder2.toString());
}
}
}
//前序遍歷的方法
public static void preOrder(Node root){
if (root != null){
root.preOrder();
}else {
System.out.println("赫夫曼樹為空");
}
}
/**
*
* @param bytes 接收位元組陣列
* @return 返回的就是 List 形式 [Node[date=97 ,weight = 5], Node[]date=32,weight = 9]......],
*/
private static List<Node> getNodes(byte[] bytes){
//1.建立一個ArrayList
ArrayList<Node> nodes = new ArrayList<>();
//遍歷bytes,儲存每一個byte出現的次數=》map[key,value]
HashMap<Byte,Integer> counts = new HashMap<>();
for (byte b: bytes) {
Integer count = counts.get(b);
if (count == null){//Map還沒有這個資料
counts.put(b,1);
}else {
counts.put(b,count+1);
}
}
//把每個鍵值對轉成一個Node物件,並加入到nodes集合
//遍歷map
for (Map.Entry<Byte,Integer> entry : counts.entrySet()){
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
//通過list建立應的赫夫曼樹
private static Node createHuffmanTree(List<Node> nodes){
while (nodes.size() > 1){
//排序,從小到大
Collections.sort(nodes);
//取出第一棵最小的二元樹左節點
Node leftNode = nodes.get(0);
//取出第二棵最小的二元樹右節點
Node rightNode = nodes.get(1);
//建立一棵新的二元樹,它的根節點沒有data,只有權值
Node parent = new Node(null, leftNode.weight+ rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
//將已經處理的兩棵二元樹從nodes刪除
nodes.remove(leftNode);
nodes.remove(rightNode);
//將新的二元樹加入到nodes
nodes.add(parent);
}
//nodes 最後的節點就是赫夫曼樹的根節點
return nodes.get(0);
}
}
//建立Node,帶資料和權值
class Node implements Comparable<Node>{
Byte data;//存放資料本身 a===>97 ascii碼
int weight;//權值,表示字元出現的次數
Node left;
Node right;
public Node(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
@Override
public int compareTo(Node o) {
//從小到大排序
return this.weight-o.weight;
}
public String toString() {
return "Node [data = " + data + " weight=" + weight + "]";
}
//前序遍歷
public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
}
}
資料壓縮的結果:

壓縮率:(40-17)/40=57.5%
3.6、使用赫夫曼編碼解碼(資料解壓)
使用赫夫曼編碼來解碼資料,具體要求是
- 前面我們得到了赫夫曼編碼和對應的編碼
byte[] , 即:[-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28] - 現在要求使用赫夫曼編碼, 進行解碼,又
重新得到原來的字串"i like like like java do you like a java"
在資料解壓的過程中我們需要兩個方法,一個是將壓縮後的結果轉為二進位制的字串,一個是對壓縮資料進行解碼
/**
* 將一個byte 轉成一個二進位制的字串, 這裡需要利用二進位制的原碼,反碼,二補數
* @param b 傳入的 byte
* @param flag 標誌是否需要補高位如果是true ,表示需要補高位,如果是false表示不補, 如果是最後一個位元組,無需補高位
* @return 是該b 對應的二進位制的字串,(注意是按二補數返回)
*/
private static String byteToBitString(boolean flag, byte b) {
//使用變數儲存 b
int temp = b; //將 b 轉成 int
//如果是正數我們還存在補高位
if(flag) {
temp |= 256; //按位元與 256 1 0000 0000 | 0000 0001 => 1 0000 0001
}
String str = Integer.toBinaryString(temp); //返回的是temp對應的二進位制的二補數
if(flag) {
return str.substring(str.length() - 8);
} else {
return str;
}
}
//編寫一個方法,完成對壓縮資料的解碼
/**
*
* @param huffmanCodes 赫夫曼編碼表 map(key = value)
* @param huffmanBytes 赫夫曼編碼得到的位元組陣列
* @return 就是原來的字串對應的陣列
*/
private static byte[] decode(Map<Byte,String> huffmanCodes, byte[] huffmanBytes) {
//1. 先得到 huffmanBytes 對應的 二進位制的字串 , 形式 1010100010111...
StringBuilder stringBuilder = new StringBuilder();
//將byte陣列轉成二進位制的字串
for(int i = 0; i < huffmanBytes.length; i++) {
byte b = huffmanBytes[i];
//判斷是不是最後一個位元組
boolean flag = (i == huffmanBytes.length - 1);
stringBuilder.append(byteToBitString(!flag, b));
}
//把字串按照指定的赫夫曼編碼進行解碼
//把赫夫曼編碼表進行調換,因為反向查詢 a->100 100->a
Map<String, Byte> map = new HashMap<String,Byte>();
for(Map.Entry<Byte, String> entry: huffmanCodes.entrySet()) {
map.put(entry.getValue(), entry.getKey());
//key = value 變成 value = key
}
//建立要給集合,存放byte
List<Byte> list = new ArrayList<>();
//i 可以理解成就是索引,掃描 stringBuilder
for(int i = 0; i < stringBuilder.length(); ) {
int count = 1; // 小的計數器
boolean flag = true;
Byte b = null;
while(flag) {
//1010100010111...
//遞增的取出 key 1 (1,10,101...匹配)
String key = stringBuilder.substring(i, i+count);//i 不動,讓count移動,指定匹配到一個字元
b = map.get(key);
if(b == null) {//說明沒有匹配到
count++;
}else {
//匹配到
flag = false;
}
}
list.add(b);
i += count;//i 直接移動到 count
}
//當for迴圈結束後,我們list中就存放了所有的字元 "i like like like java do you like a java"
//把list 中的資料放入到byte[] 並返回
byte b[] = new byte[list.size()];
for(int i = 0;i < b.length; i++) {
b[i] = list.get(i);
}
return b;
}
測試
//解壓
byte[] sourceBytes = decode(huffmanCodes, huffmanCodesBytes);
System.out.println("(解壓後)原來的字串="+new String(sourceBytes));

3.6、檔案壓縮
我們學習了通過赫夫曼編碼對一個字串進行編碼和解碼, 下面我們來完成對檔案的壓縮和解壓, 具體要求:
給你一個圖片檔案,要求對其進行無失真壓縮, 看看壓縮效果如何
思路:讀取檔案-> 得到赫夫曼編碼表 -> 完成壓縮
首先我們建立一個圖片檔案

壓縮程式碼
//編寫方法,將一個檔案進行壓縮
/**
*
* @param srcFile 你傳入的希望壓縮的檔案的全路徑
* @param dstFile 我們壓縮後將壓縮檔案放到哪個目錄
*/
public static void zipFile(String srcFile, String dstFile) {
//建立輸出流
OutputStream os = null;
ObjectOutputStream oos = null;
//建立檔案的輸入流
FileInputStream is = null;
try {
//建立檔案的輸入流
is = new FileInputStream(srcFile);
//建立一個和原始檔大小一樣的byte[]
byte[] b = new byte[is.available()];
//讀取檔案
is.read(b);
//直接對原始檔壓縮
byte[] huffmanBytes = huffmanZip(b);
//建立檔案的輸出流, 存放壓縮檔案
os = new FileOutputStream(dstFile);
//建立一個和檔案輸出流關聯的ObjectOutputStream
oos = new ObjectOutputStream(os);
//把 赫夫曼編碼後的位元組陣列寫入壓縮檔案
oos.writeObject(huffmanBytes);
//這裡我們以物件流的方式寫入 赫夫曼編碼,是為了以後我們恢復原始檔時使用
//注意一定要把赫夫曼編碼 寫入壓縮檔案
oos.writeObject(huffmanCodes);
}catch (Exception e) {
System.out.println(e.getMessage());
}finally {
try {
is.close();
oos.close();
os.close();
}catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
測試程式碼
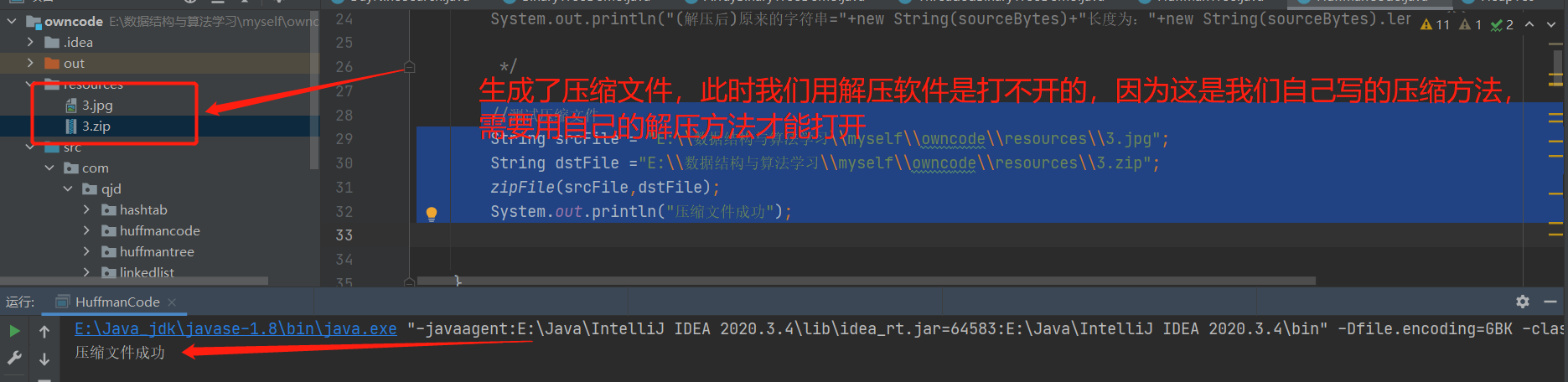
//測試壓縮檔案
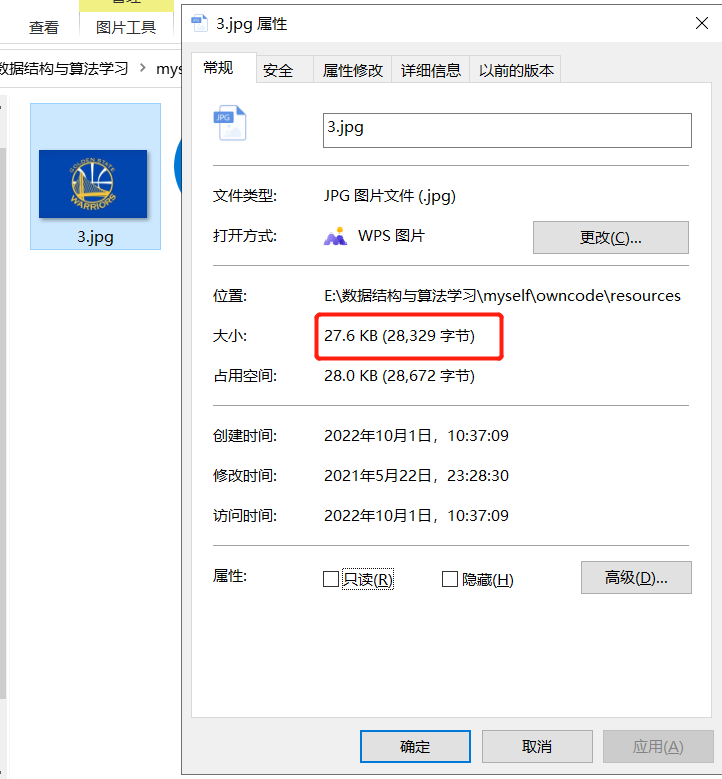
String srcFile = "E:\\資料結構與演演算法學習\\myself\\owncode\\resources\\3.jpg";
String dstFile ="E:\\資料結構與演演算法學習\\myself\\owncode\\resources\\3.zip";
zipFile(srcFile,dstFile);
System.out.println("壓縮檔案成功");
結果
3.7、檔案解壓
具體要求:將前面壓縮的檔案,重新恢復成原來的檔案。
思路:讀取壓縮檔案(資料和赫夫曼編碼表)-> 完成解壓(檔案恢復)
檔案解壓程式碼
//編寫一個方法,完成對壓縮檔案的解壓
/**
*
* @param zipFile 準備解壓的檔案
* @param dstFile 將檔案解壓到哪個路徑
*/
public static void unZipFile(String zipFile, String dstFile) {
//定義檔案輸入流
InputStream is = null;
//定義一個物件輸入流
ObjectInputStream ois = null;
//定義檔案的輸出流
OutputStream os = null;
try {
//建立檔案輸入流
is = new FileInputStream(zipFile);
//建立一個和 is關聯的物件輸入流
ois = new ObjectInputStream(is);
//讀取byte陣列 huffmanBytes
byte[] huffmanBytes = (byte[])ois.readObject();
//讀取赫夫曼編碼表
Map<Byte,String> huffmanCodes = (Map<Byte,String>)ois.readObject();
//解碼
byte[] bytes = decode(huffmanCodes, huffmanBytes);
//將bytes 陣列寫入到目標檔案
os = new FileOutputStream(dstFile);
//寫資料到 dstFile 檔案
os.write(bytes);
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
try {
os.close();
ois.close();
is.close();
} catch (Exception e2) {
System.out.println(e2.getMessage());
}
}
}
測試程式碼
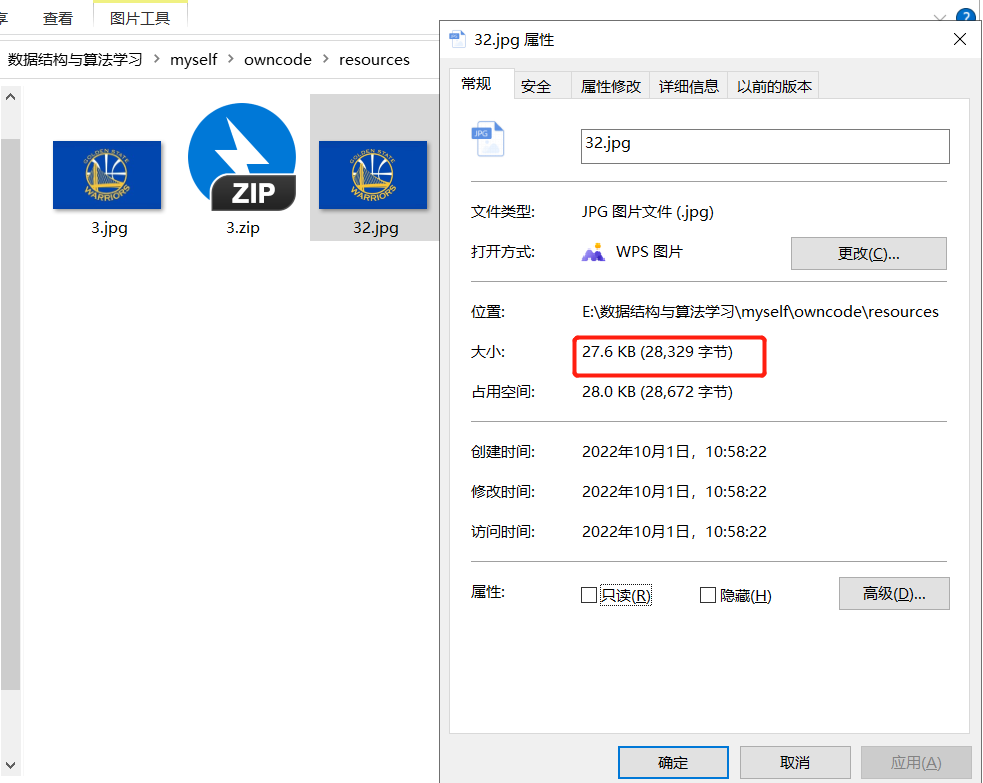
//測試解壓檔案
String zipFile = "E:\\資料結構與演演算法學習\\myself\\owncode\\resources\\3.zip";
String dstFile = "E:\\資料結構與演演算法學習\\myself\\owncode\\resources\\32.jpg";
unZipFile(zipFile,dstFile);
System.out.println("解壓成功");
結果
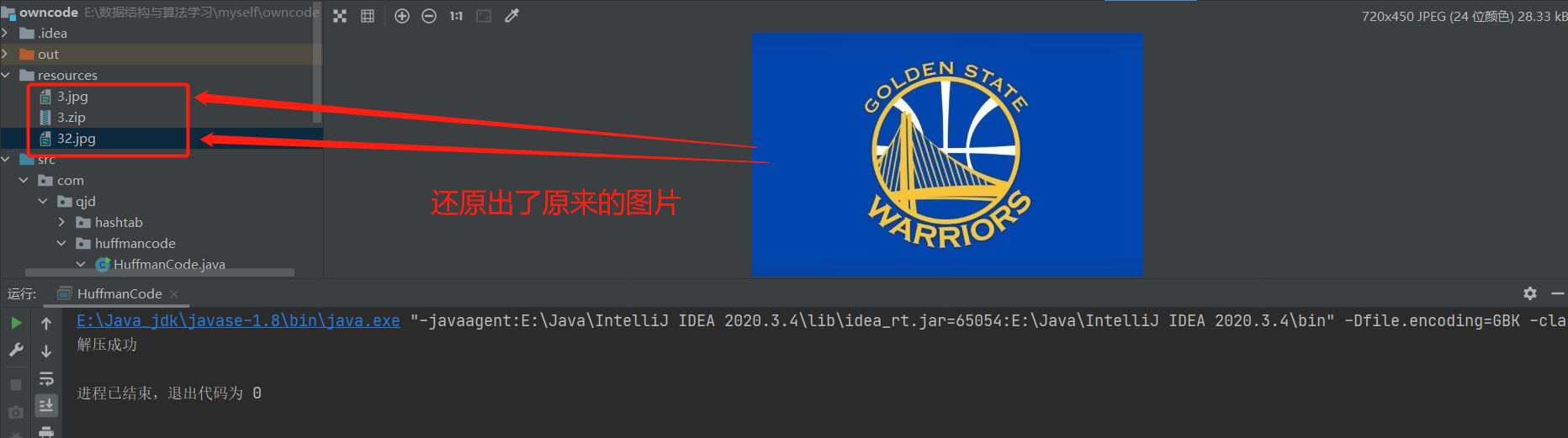
我們取資料夾中檢視發現原始的圖片和解壓後的檔案大小一樣---->無失真壓縮
3.8、程式碼彙總
我們將赫夫曼編碼所有的程式碼進行彙總
package com.qjd.huffmancode;
import java.io.*;
import java.util.*;
public class HuffmanCode {
public static void main(String[] args) {
/*
String content = "i like like like java do you like a java";
byte[] contentBytes = content.getBytes();
System.out.println("原始的content字串長度為:"+contentBytes.length);//40
//壓縮
byte[] huffmanCodesBytes = huffmanZip(contentBytes);
System.out.println("對content字串壓縮後的結果是:"+Arrays.toString(huffmanCodesBytes)+"長度為:"+huffmanCodesBytes.length);
//解壓
byte[] sourceBytes = decode(huffmanCodes, huffmanCodesBytes);
System.out.println("(解壓後)原來的字串="+new String(sourceBytes)+"長度為:"+new String(sourceBytes).length());
*/
//測試壓縮檔案
// String srcFile = "E:\\資料結構與演演算法學習\\myself\\owncode\\resources\\3.jpg";
// String dstFile ="E:\\資料結構與演演算法學習\\myself\\owncode\\resources\\3.zip";
// zipFile(srcFile,dstFile);
// System.out.println("壓縮檔案成功");
//測試解壓檔案
String zipFile = "E:\\資料結構與演演算法學習\\myself\\owncode\\resources\\3.zip";
String dstFile = "E:\\資料結構與演演算法學習\\myself\\owncode\\resources\\32.jpg";
unZipFile(zipFile,dstFile);
System.out.println("解壓成功");
}
//編寫一個方法,完成對壓縮檔案的解壓
/**
*
* @param zipFile 準備解壓的檔案
* @param dstFile 將檔案解壓到哪個路徑
*/
public static void unZipFile(String zipFile, String dstFile) {
//定義檔案輸入流
InputStream is = null;
//定義一個物件輸入流
ObjectInputStream ois = null;
//定義檔案的輸出流
OutputStream os = null;
try {
//建立檔案輸入流
is = new FileInputStream(zipFile);
//建立一個和 is關聯的物件輸入流
ois = new ObjectInputStream(is);
//讀取byte陣列 huffmanBytes
byte[] huffmanBytes = (byte[])ois.readObject();
//讀取赫夫曼編碼表
Map<Byte,String> huffmanCodes = (Map<Byte,String>)ois.readObject();
//解碼
byte[] bytes = decode(huffmanCodes, huffmanBytes);
//將bytes 陣列寫入到目標檔案
os = new FileOutputStream(dstFile);
//寫資料到 dstFile 檔案
os.write(bytes);
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
try {
os.close();
ois.close();
is.close();
} catch (Exception e2) {
System.out.println(e2.getMessage());
}
}
}
//編寫方法,將一個檔案進行壓縮
/**
*
* @param srcFile 你傳入的希望壓縮的檔案的全路徑
* @param dstFile 我們壓縮後將壓縮檔案放到哪個目錄
*/
public static void zipFile(String srcFile, String dstFile) {
//建立輸出流
OutputStream os = null;
ObjectOutputStream oos = null;
//建立檔案的輸入流
FileInputStream is = null;
try {
//建立檔案的輸入流
is = new FileInputStream(srcFile);
//建立一個和原始檔大小一樣的byte[]
byte[] b = new byte[is.available()];
//讀取檔案
is.read(b);
//直接對原始檔壓縮
byte[] huffmanBytes = huffmanZip(b);
//建立檔案的輸出流, 存放壓縮檔案
os = new FileOutputStream(dstFile);
//建立一個和檔案輸出流關聯的ObjectOutputStream
oos = new ObjectOutputStream(os);
//把 赫夫曼編碼後的位元組陣列寫入壓縮檔案
oos.writeObject(huffmanBytes);
//這裡我們以物件流的方式寫入 赫夫曼編碼,是為了以後我們恢復原始檔時使用
//注意一定要把赫夫曼編碼 寫入壓縮檔案
oos.writeObject(huffmanCodes);
}catch (Exception e) {
System.out.println(e.getMessage());
}finally {
try {
is.close();
oos.close();
os.close();
}catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
//完成資料的解壓
//思路
//1. 將huffmanCodeBytes [-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28]
// 重新先轉成 赫夫曼編碼對應的二進位制的字串 "1010100010111..."
//2. 赫夫曼編碼對應的二進位制的字串 "1010100010111..." =》 對照 赫夫曼編碼 =》 "i like like like java do you like a java"
/**
* 將一個byte 轉成一個二進位制的字串, 這裡需要利用二進位制的原碼,反碼,二補數
* @param b 傳入的 byte
* @param flag 標誌是否需要補高位如果是true ,表示需要補高位,如果是false表示不補, 如果是最後一個位元組,無需補高位
* @return 是該b 對應的二進位制的字串,(注意是按二補數返回)
*/
private static String byteToBitString(boolean flag, byte b) {
//使用變數儲存 b
int temp = b; //將 b 轉成 int
//如果是正數我們還存在補高位
if(flag) {
temp |= 256; //按位元與 256 1 0000 0000 | 0000 0001 => 1 0000 0001
}
String str = Integer.toBinaryString(temp); //返回的是temp對應的二進位制的二補數
if(flag) {
return str.substring(str.length() - 8);
} else {
return str;
}
}
//編寫一個方法,完成對壓縮資料的解碼
/**
*
* @param huffmanCodes 赫夫曼編碼表 map(key = value)
* @param huffmanBytes 赫夫曼編碼得到的位元組陣列
* @return 就是原來的字串對應的陣列
*/
private static byte[] decode(Map<Byte,String> huffmanCodes, byte[] huffmanBytes) {
//1. 先得到 huffmanBytes 對應的 二進位制的字串 , 形式 1010100010111...
StringBuilder stringBuilder = new StringBuilder();
//將byte陣列轉成二進位制的字串
for(int i = 0; i < huffmanBytes.length; i++) {
byte b = huffmanBytes[i];
//判斷是不是最後一個位元組
boolean flag = (i == huffmanBytes.length - 1);
stringBuilder.append(byteToBitString(!flag, b));
}
//把字串按照指定的赫夫曼編碼進行解碼
//把赫夫曼編碼表進行調換,因為反向查詢 a->100 100->a
Map<String, Byte> map = new HashMap<String,Byte>();
for(Map.Entry<Byte, String> entry: huffmanCodes.entrySet()) {
map.put(entry.getValue(), entry.getKey());
//key = value 變成 value = key
}
//建立要給集合,存放byte
List<Byte> list = new ArrayList<>();
//i 可以理解成就是索引,掃描 stringBuilder
for(int i = 0; i < stringBuilder.length(); ) {
int count = 1; // 小的計數器
boolean flag = true;
Byte b = null;
while(flag) {
//1010100010111...
//遞增的取出 key 1 (1,10,101...匹配)
String key = stringBuilder.substring(i, i+count);//i 不動,讓count移動,指定匹配到一個字元
b = map.get(key);
if(b == null) {//說明沒有匹配到
count++;
}else {
//匹配到
flag = false;
}
}
list.add(b);
i += count;//i 直接移動到 count
}
//當for迴圈結束後,我們list中就存放了所有的字元 "i like like like java do you like a java"
//把list 中的資料放入到byte[] 並返回
byte b[] = new byte[list.size()];
for(int i = 0;i < b.length; i++) {
b[i] = list.get(i);
}
return b;
}
//使用一個方法,將前面的方法封裝起來,便於我們的呼叫
/**
* @param bytes 原始的字串對應的位元組陣列
* @return 是經過 赫夫曼編碼處理後的位元組陣列(壓縮後的陣列)
*/
private static byte[] huffmanZip(byte[] bytes){
List<Node> nodes = getNodes(bytes);
//根據nodes建立的赫夫曼樹
Node huffmanTreeRoot = createHuffmanTree(nodes);
//生成對應的赫夫曼編碼(根據赫夫曼樹)
Map<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot);
//根據生成的赫夫曼編碼來對原始的位元組陣列進行壓縮
byte[] huffmanCodeBytes = zip(bytes, huffmanCodes);
return huffmanCodeBytes;
}
//編寫一個方法,將字串對應的byte[] 陣列,通過生成的赫夫曼編碼表,返回一個赫夫曼編碼 壓縮後的byte[]
/**
*
* @param bytes 這是原始的字串對應的 byte[]
* @param huffmanCodes 生成的赫夫曼編碼map
* @return 返回赫夫曼編碼處理後的 byte[]
* 舉例: String content = "i like like like java do you like a java"; =》 byte[] contentBytes = content.getBytes();
* 返回的是 字串 "1010100010111111110010001011111111001000101111111100100101001101110001110000011011101000111100101000101111111100110001001010011011100"
* => 對應的 byte[] huffmanCodeBytes ,即 8位元對應一個 byte,放入到 huffmanCodeBytes
* huffmanCodeBytes[0] = 10101000(二補數) => byte [推導 10101000=> 10101000 - 1 => 10100111(反碼)=> 11011000(原碼)= -88 ]
* huffmanCodeBytes[1] = -88
*/
private static byte[] zip(byte[] bytes, Map<Byte, String> huffmanCodes) {
//1.利用 huffmanCodes 將 bytes 轉成 赫夫曼編碼對應的字串
StringBuilder stringBuilder = new StringBuilder();
//遍歷bytes 陣列
for(byte b: bytes) {
stringBuilder.append(huffmanCodes.get(b));
}
//System.out.println("測試 stringBuilder~~~=" + stringBuilder.toString());
//將 "1010100010111111110..." 轉成 byte[]
//統計返回 byte[] huffmanCodeBytes 長度
//一句話 int len = (stringBuilder.length() + 7) / 8;
int len;
if(stringBuilder.length() % 8 == 0) {
len = stringBuilder.length() / 8;
} else {
len = stringBuilder.length() / 8 + 1;
}
//建立 儲存壓縮後的 byte陣列
byte[] huffmanCodeBytes = new byte[len];
int index = 0;//記錄是第幾個byte
for (int i = 0; i < stringBuilder.length(); i += 8) { //因為是每8位元對應一個byte,所以步長 +8
String strByte;
if(i+8 > stringBuilder.length()) {//不夠8位元
strByte = stringBuilder.substring(i);
}else{
strByte = stringBuilder.substring(i, i + 8);
}
//將strByte 轉成一個byte,放入到 huffmanCodeBytes
huffmanCodeBytes[index] = (byte)Integer.parseInt(strByte, 2);
index++;
}
return huffmanCodeBytes;
}
//生成赫夫曼樹對應的赫夫曼編碼
//思路:
//1. 將赫夫曼編碼表存放在 Map<Byte,String> 形式
// 生成的赫夫曼編碼表{32(空格)=01, 97(a)=100, 100(...)=11000, 117=11001, 101=1110, 118=11011, 105=101, 121=11010, 106=0010, 107=1111, 108=000, 111=0011}
static Map<Byte, String> huffmanCodes = new HashMap<Byte,String>();
//2. 在生成赫夫曼編碼表示,需要去拼接路徑, 定義一個StringBuilder 儲存某個葉子結點的路徑
static StringBuilder stringBuilder = new StringBuilder();
//為了呼叫方便,我們過載 getCodes
private static Map<Byte, String> getCodes(Node root) {
if(root == null) {
return null;
}
//處理root的左子樹
getCodes(root.left, "0", stringBuilder);
//處理root的右子樹
getCodes(root.right, "1", stringBuilder);
return huffmanCodes;
}
/**
* 功能:將傳入的node結點的所有葉子結點的赫夫曼編碼得到,並放入到huffmanCodes集合
* @param node 傳入結點
* @param code 路徑: 左子結點是 0, 右子結點 1
* @param stringBuilder 用於拼接路徑
*/
private static void getCodes(Node node,String code,StringBuilder stringBuilder){
StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);
//將code加入到 stringBuilder2 (拼接路徑)
stringBuilder2.append(code);
if (node != null){//如果node等於空,不處理
//判斷當前node是葉子節點還是非葉子結點
if (node.data == null){//非葉子節點
//遞迴處理
//向左遞迴
getCodes(node.left, "0", stringBuilder2);
//向右遞迴
getCodes(node.right, "1", stringBuilder2);
}else {//進入到這裡說明是葉子節點,找到了最後
huffmanCodes.put(node.data,stringBuilder2.toString());
}
}
}
//前序遍歷的方法
public static void preOrder(Node root){
if (root != null){
root.preOrder();
}else {
System.out.println("赫夫曼樹為空");
}
}
/**
*
* @param bytes 接收位元組陣列
* @return 返回的就是 List 形式 [Node[date=97 ,weight = 5], Node[]date=32,weight = 9]......],
*/
private static List<Node> getNodes(byte[] bytes){
//1.建立一個ArrayList
ArrayList<Node> nodes = new ArrayList<>();
//遍歷bytes,儲存每一個byte出現的次數=》map[key,value]
HashMap<Byte,Integer> counts = new HashMap<>();
for (byte b: bytes) {
Integer count = counts.get(b);
if (count == null){//Map還沒有這個資料
counts.put(b,1);
}else {
counts.put(b,count+1);
}
}
//把每個鍵值對轉成一個Node物件,並加入到nodes集合
//遍歷map
for (Map.Entry<Byte,Integer> entry : counts.entrySet()){
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
//通過list建立應的赫夫曼樹
private static Node createHuffmanTree(List<Node> nodes){
while (nodes.size() > 1){
//排序,從小到大
Collections.sort(nodes);
//取出第一棵最小的二元樹左節點
Node leftNode = nodes.get(0);
//取出第二棵最小的二元樹右節點
Node rightNode = nodes.get(1);
//建立一棵新的二元樹,它的根節點沒有data,只有權值
Node parent = new Node(null, leftNode.weight+ rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
//將已經處理的兩棵二元樹從nodes刪除
nodes.remove(leftNode);
nodes.remove(rightNode);
//將新的二元樹加入到nodes
nodes.add(parent);
}
//nodes 最後的節點就是赫夫曼樹的根節點
return nodes.get(0);
}
}
//建立Node,帶資料和權值
class Node implements Comparable<Node>{
Byte data;//存放資料本身 a===>97 ascii碼
int weight;//權值,表示字元出現的次數
Node left;
Node right;
public Node(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
@Override
public int compareTo(Node o) {
//從小到大排序
return this.weight-o.weight;
}
public String toString() {
return "Node [data = " + data + " weight=" + weight + "]";
}
//前序遍歷
public void preOrder() {
System.out.println(this);
if(this.left != null) {
this.left.preOrder();
}
if(this.right != null) {
this.right.preOrder();
}
}
}
3.9、赫夫曼編碼壓縮注意事項
- 如果檔案本身就是經過壓縮處理的,那麼使用赫夫曼編碼再壓縮效率不會有明顯變化, 比如視訊,ppt 等等檔案
[舉例:壓縮一個 .ppt] - 赫夫曼編碼是按位元組來處理的,因此可以處理所有的檔案(二進位制檔案、文字檔案) [舉例壓一個.xml 檔案]
- 如果一個檔案中的內容,重複的資料不多,壓縮效果也不會很明顯.
4、二叉排序樹(BST)
4.1、實際需求
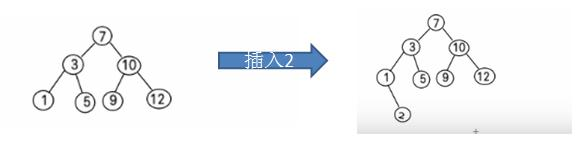
給出一個數列 (7, 3, 10, 12, 5, 1, 9),要求能夠高效的完成對資料的查詢和新增
解決方案:
1、使用陣列
陣列未排序, 優點:直接在陣列尾新增,速度快。 缺點:查詢速度慢.
陣列排序,優點:可以使用二分查詢,查詢速度快,缺點:為了保證陣列有序,在新增新資料時,找到插入位置後,後面的資料需整體移動,速度慢。
2、使用鏈式儲存-連結串列
不管連結串列是否有序,查詢速度都慢,新增資料速度比陣列快,不需要資料整體移動。
3、使用二叉排序樹
4.2、二叉排序樹簡介
二叉排序樹:
BST: (Binary Sort(Search) Tree), 對於二叉排序樹的 任何一個非葉子節點,要求 左子節點的值比當前節點的值小, 右子節點的值比當前節點的值大。
特別說明:如果有相同的值,可以將該節點放在左子節點或右子節點
比如針對前面的資料 (7, 3, 10, 12, 5, 1, 9) ,對應的二叉排序樹為:
4.3、二叉排序樹的建立與遍歷
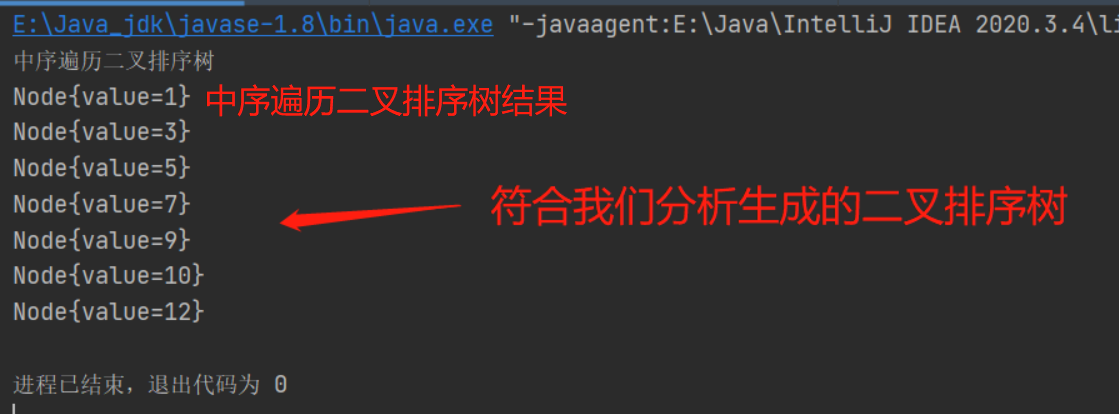
一個陣列建立成對應的二叉排序樹,並使用中序遍歷二叉排序樹,比如: 陣列為 Array(7, 3, 10, 12, 5, 1, 9) , 創
建成對應的二叉排序樹為 :

二叉排序樹的建立與遍歷程式碼
public class BinarySortTreeDemo {
public static void main(String[] args) {
int[] arr = {7,3,10,12,5,1,9};
BinarySortTree binarySortTree = new BinarySortTree();
//迴圈的新增節點到二叉排序樹
for (int i = 0; i < arr.length; i++) {
binarySortTree.add(new Node(arr[i]));
}
//中序遍歷二叉排序樹
System.out.println("中序遍歷二叉排序樹");
binarySortTree.infixOrder();
}
}
//建立二叉排序樹
class BinarySortTree{
private Node root;
//新增節點的方法
public void add(Node node){
if (root == null){
root = node;//如果root為空則直接讓root指向node
}else {
root.add(node);
}
}
//中序遍歷
public void infixOrder(){
if (root != null){
root.infixOrder();
}else {
System.out.println("二叉排序樹為空,不能遍歷");
}
}
}
//建立Node節點
class Node{
int value;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
//新增節點的方法
//遞迴的形式新增節點,需要滿足二叉排序樹的要求
public void add(Node node){
if (node == null){
return;
}
//判斷傳入的節點的值,和當前子樹根節點的值的關係
if (node.value<this.value){
//如果當前節點左子節點為空,直接將node給左節點
if (this.left == null){
this.left = node;
}else {//如果當前節點左子節點不為空,就遞迴的向左子樹進行新增
this.left.add(node);
}
}else {//新增的節點的值大於當前節點的值
if (this.right == null){
this.right = node;
}else {
this.right.add(node);
}
}
}
//中序遍歷的方法
public void infixOrder() {
if(this.left != null) {
this.left.infixOrder();
}
System.out.println(this);
if(this.right != null) {
this.right.infixOrder();
}
}
@Override
public String toString() {
return "Node{" +
"value=" + value +
'}';
}
}
結果:
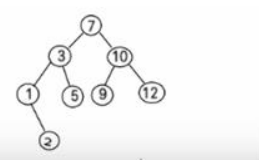
4.4、二元樹的刪除
二叉排序樹的刪除情況比較複雜,有下面三種情況需要考慮
-
點 刪除葉子節點 (比如:2, 5, 9, 12)
-
刪除點 只有一顆子樹的節點 (比如:1)
-
刪除 有兩顆子樹的節點. (比如:7, 3,10 )
思路分析
第一種情況:刪除葉子節點 (比如:2, 5, 9, 12)
思路
(1) 需求先去找到要刪除的結點 targetNode
(2) 找到targetNode 的 父結點parent
(3) 確定 targetNode 是 parent的左子結點 還是右子結點
(4) 根據前面的情況來對應刪除
左子結點 parent.left = null
右子結點 parent.right = null;
第二種情況: 刪除只有一顆子樹的節點 比如1
思路
(1) 需求先去找到要刪除的結點 targetNode
(2) 找到targetNode 的 父結點parent
(3) 確定targetNode 的子結點是左子結點還是右子結點
(4) targetNode 是parent的左子結點還是右子結點
(5) 如果targetNode 有左子結點
- 1 如果
targetNode是parent的左子結點
parent.left = targetNode.left;
5.2 如果targetNode是 parent 的右子結點
parent.right = targetNode.left;
(6) 如果targetNode 有右子結點
6.1 如果 targetNode 是 parent 的左子結點
parent.left = targetNode.right;
6.2 如果 targetNode 是parent的右子結點
parent.right = targetNode.right
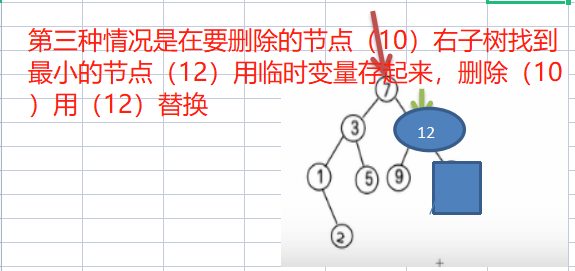
第三種情況 : 刪除有兩顆子樹的節點. (比如:7, 3,10 )
思路
(1) 需求先去找到要刪除的結點 targetNode
(2) 找到targetNode 的 父結點parent
(3) 從targetNode 的右子樹找到最小的結點
(4) 用一個臨時變數,將 最小結點的值儲存 temp = 12
(5) 刪除該最小結點
(6) targetNode.value = temp
程式碼實現
package com.qjd.binarysorttree;
public class BinarySortTreeDemo {
public static void main(String[] args) {
int[] arr = {7,3,10,12,5,1,9,2};
BinarySortTree binarySortTree = new BinarySortTree();
//迴圈的新增節點到二叉排序樹
for (int i = 0; i < arr.length; i++) {
binarySortTree.add(new Node(arr[i]));
}
//中序遍歷二叉排序樹
System.out.println("中序遍歷二叉排序樹");
binarySortTree.infixOrder();
//測試刪除節點
// binarySortTree.delNode(2);
// binarySortTree.delNode(5);
// binarySortTree.delNode(9);
// binarySortTree.delNode(12);
// binarySortTree.delNode(1);
binarySortTree.delNode(10);
System.out.println("刪除節點後");
binarySortTree.infixOrder();
}
}
//建立二叉排序樹
class BinarySortTree{
private Node root;
//新增節點的方法
public void add(Node node){
if (root == null){
root = node;//如果root為空則直接讓root指向node
}else {
root.add(node);
}
}
//查詢要刪除的結點
public Node search(int value) {
if(root == null) {
return null;
} else {
return root.search(value);
}
}
//查詢父結點
public Node searchParent(int value) {
if(root == null) {
return null;
} else {
return root.searchParent(value);
}
}
//編寫方法:
//1. 返回的 以node 為根結點的二叉排序樹的最小結點的值
//2. 刪除node 為根結點的二叉排序樹的最小結點
/**
*
* @param node 傳入的結點(當做二叉排序樹的根結點)
* @return 返回的 以node 為根結點的二叉排序樹的最小結點的值
*/
public int delRightTreeMin(Node node) {
Node target = node;
//!!!這裡是向右子樹查詢,但是因為是二叉排序樹所以最小值一定在左子樹上
while(target.left != null) {
target = target.left;
}
//這時 target就指向了最小結點
//刪除最小結點
delNode(target.value);
return target.value;
}
//刪除結點
public void delNode(int value) {
if(root == null) {
return;
}else {
//1.需要先去找到要刪除的結點 targetNode
Node targetNode = search(value);
//如果沒有找到要刪除的結點
if(targetNode == null) {
return;
}
//如果我們發現當前這顆二叉排序樹只有一個結點
if(root.left == null && root.right == null) {
root = null;
return;
}
//去找到targetNode的父結點
Node parent = searchParent(value);
//如果要刪除的結點是葉子結點
if(targetNode.left == null && targetNode.right == null) {
//判斷targetNode 是父結點的左子結點,還是右子結點
if(parent.left != null && parent.left.value == value) { //是左子結點
parent.left = null;
} else if (parent.right != null && parent.right.value == value) {//是右子結點
parent.right = null;
}
} else if (targetNode.left != null && targetNode.right != null) { //刪除有兩顆子樹的節點
int minVal = delRightTreeMin(targetNode.right);//在右子樹中查詢最小值
targetNode.value = minVal;
} else { // 刪除只有一顆子樹的結點
//如果要刪除的結點有左子結點
if(targetNode.left != null) {
if(parent != null) {
//如果 targetNode 是 parent 的左子結點
if(parent.left.value == value) {
parent.left = targetNode.left;
} else { // targetNode 是 parent 的右子結點
parent.right = targetNode.left;
}
} else {
root = targetNode.left;
}
} else { //如果要刪除的結點有右子結點
if(parent != null) {
//如果 targetNode 是 parent 的左子結點
if(parent.left.value == value) {
parent.left = targetNode.right;
} else { //如果 targetNode 是 parent 的右子結點
parent.right = targetNode.right;
}
} else {
root = targetNode.right;
}
}
}
}
}
//中序遍歷
public void infixOrder(){
if (root != null){
root.infixOrder();
}else {
System.out.println("二叉排序樹為空,不能遍歷");
}
}
}
//建立Node節點
class Node{
int value;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
//查詢要刪除的節點
/**
*
* @param value 希望刪除的結點的值
* @return 如果找到返回該結點,否則返回null
*/
public Node search(int value) {
if(value == this.value) { //找到就是該結點
return this;
} else if(value < this.value) {//如果查詢的值小於當前結點,向左子樹遞迴查詢
//如果左子結點為空
if(this.left == null) {
return null;
}
return this.left.search(value);
} else { //如果查詢的值不小於當前結點,向右子樹遞迴查詢
if(this.right == null) {
return null;
}
return this.right.search(value);
}
}
//查詢要刪除結點的父結點
/**
*
* @param value 要找到的結點的值
* @return 返回的是要刪除的結點的父結點,如果沒有就返回null
*/
public Node searchParent(int value) {
//如果當前結點就是要刪除的結點的父結點,就返回
if((this.left != null && this.left.value == value) ||
(this.right != null && this.right.value == value)) {
return this;
} else {
//如果查詢的值小於當前結點的值, 並且當前結點的左子結點不為空
if(value < this.value && this.left != null) {
return this.left.searchParent(value); //向左子樹遞迴查詢
} else if (value >= this.value && this.right != null) {
return this.right.searchParent(value); //向右子樹遞迴查詢
} else {
return null; // 沒有找到父結點
}
}
}
//新增節點的方法
//遞迴的形式新增節點,需要滿足二叉排序樹的要求
public void add(Node node){
if (node == null){
return;
}
//判斷傳入的節點的值,和當前子樹根節點的值的關係
if (node.value<this.value){
//如果當前節點左子節點為空,直接將node給左節點
if (this.left == null){
this.left = node;
}else {//如果當前節點左子節點不為空,就遞迴的向左子樹進行新增
this.left.add(node);
}
}else {//新增的節點的值大於當前節點的值
if (this.right == null){
this.right = node;
}else {
this.right.add(node);
}
}
}
//中序遍歷的方法
public void infixOrder() {
if(this.left != null) {
this.left.infixOrder();
}
System.out.println(this);
if(this.right != null) {
this.right.infixOrder();
}
}
@Override
public String toString() {
return "Node{" +
"value=" + value +
'}';
}
}
結果:
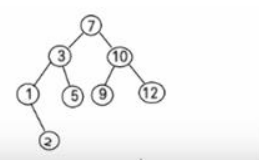
1、刪除葉子節點2、5、9
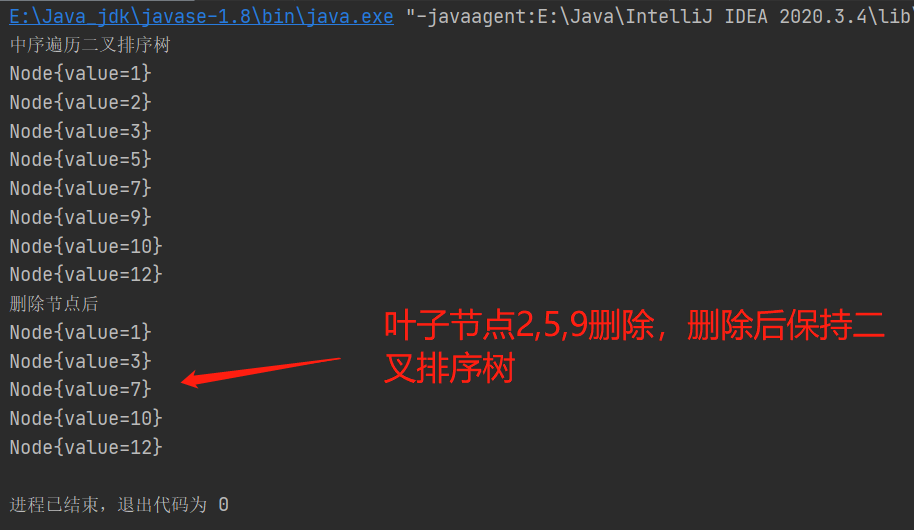
2、刪除只有一顆子樹的節點 1
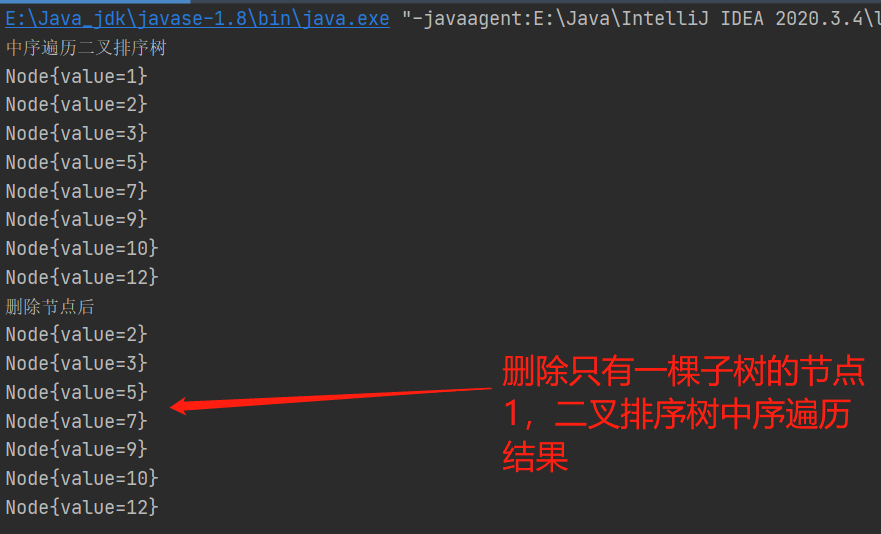
3、刪除有兩顆子樹的節點10
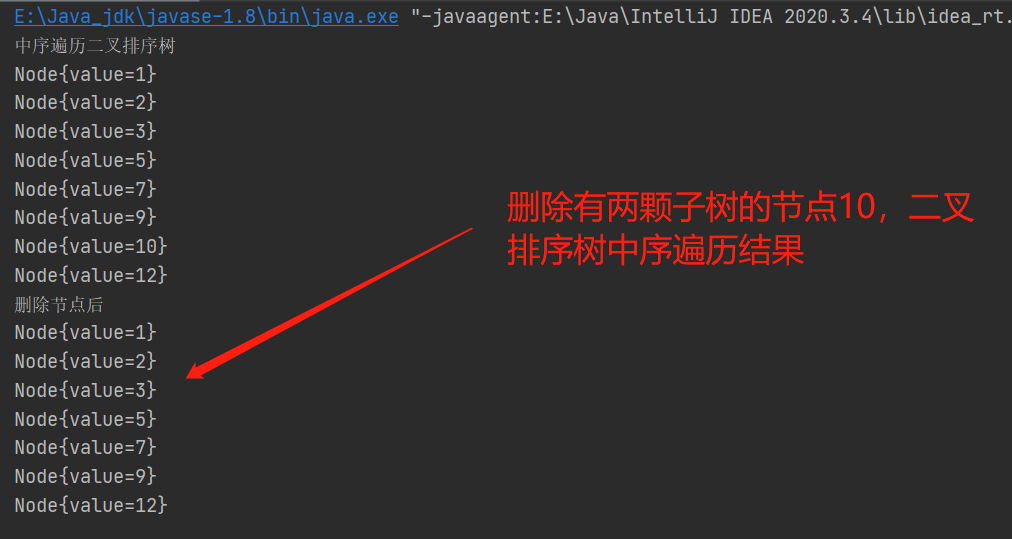
5、平衡二元樹(AVL)
5.1、實際案例
給出一個數列{1,2,3,4,5,6},要求建立一顆二叉排序樹(BST), 並分析問題所在.
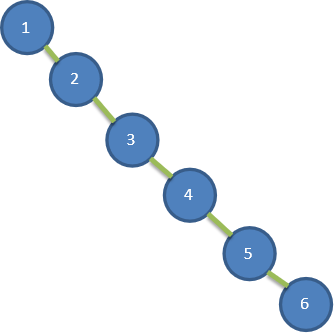
左邊 BST 存在的問題分析:
- 左子樹全部為空,從形式上看,更像一個單連結串列.
- 插入速度沒有影響
- 查詢速度明顯降低(因為需要依次比較), 不能發揮 BST的優勢,因為每次還需要比較左子樹,其查詢速度比單連結串列還慢
- 解決方案-平衡二元樹(AVL)
5.2、平衡二元樹簡介
- 平衡二元樹也叫平衡 二元搜尋樹(Self-balancing binary search tree)又被稱為 AVL 樹, 可以保證查詢效率較高。
- 具有以下特點:它是一 一 棵空樹或 它的左右兩個子樹的高度差的絕對值不超過 1,並且 左右兩個子樹都是一棵
平衡二元樹。平衡二元樹的常用實現方法有紅黑樹、AVL、替罪羊樹、Treap、伸展樹等。 - 舉例說明, 看看下面哪些 AVL 樹, 為什麼?
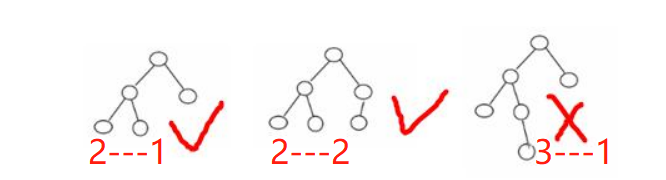
5.3、構建平衡二元樹
5.3.1、左旋轉
1、要求: 給出一個數列,建立出對應的平衡二元樹.數列 {4,3,6,5,7,8}
2、思路分析

5.3.2、右旋轉
1、要求: 給出一個數列,建立出對應的平衡二元樹.數列 {10,12, 8, 9, 7, 6}
2、思路分析

5.3.3、雙旋轉
前面的兩個數列,進行單旋轉(即一次旋轉)就可以將非平衡二元樹轉成平衡二元樹,但是在某些情況下,單旋轉
不能完成平衡二元樹的轉換。比如數列
int[] arr = { 10, 11, 7, 6, 8, 9 }; 執行原來的程式碼可以看到,並沒有轉成 AVL 樹.
int[] arr = {2,1,6,5,7,3}; 執行原來的程式碼可以看到,並沒有轉成 AVL 樹
1、問題分析
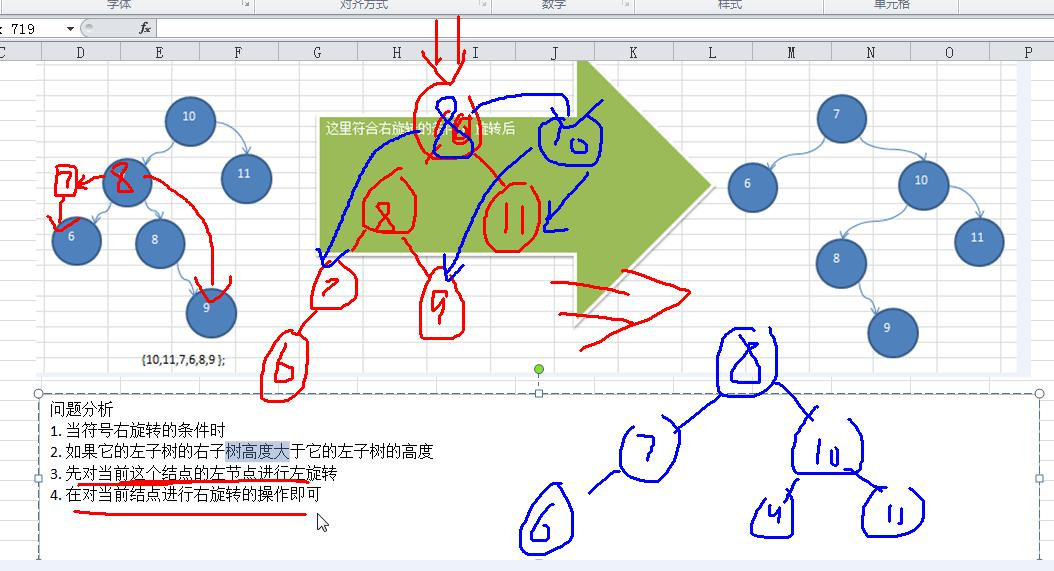
2、思路分析
- 當符號右旋轉的條件時
- 如果它的左子樹的右子樹高度大於它的左子樹的高度
- 先對當前這個結點的左節點進行左旋轉
- 在對當前結點進行右旋轉的操作即可
5.3.4、整體程式碼實現
public class AvlTreeDemo {
public static void main(String[] args) {
//int[] arr = {4,3,6,5,7,8};
//int[] arr = { 10, 12, 8, 9, 7, 6 };
int[] arr = { 10, 11, 7, 6, 8, 9 };
//建立一個 AVLTree物件
AVLTree avlTree = new AVLTree();
//新增結點
for(int i=0; i < arr.length; i++) {
avlTree.add(new Node(arr[i]));
}
//遍歷
System.out.println("中序遍歷");
avlTree.infixOrder();
System.out.println("在平衡處理後···");
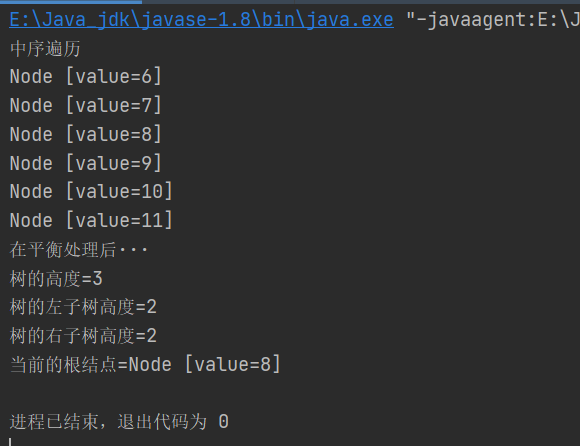
System.out.println("樹的高度=" + avlTree.getRoot().height()); //3
System.out.println("樹的左子樹高度=" + avlTree.getRoot().leftHeight()); // 2
System.out.println("樹的右子樹高度=" + avlTree.getRoot().rightHeight()); // 2
System.out.println("當前的根結點=" + avlTree.getRoot());//8
}
}
// 建立AVLTree
class AVLTree {
private Node root;
public Node getRoot() {
return root;
}
// 查詢要刪除的結點
public Node search(int value) {
if (root == null) {
return null;
} else {
return root.search(value);
}
}
// 查詢父結點
public Node searchParent(int value) {
if (root == null) {
return null;
} else {
return root.searchParent(value);
}
}
// 編寫方法:
// 1. 返回的 以node 為根結點的二叉排序樹的最小結點的值
// 2. 刪除node 為根結點的二叉排序樹的最小結點
/**
*
* @param node
* 傳入的結點(當做二叉排序樹的根結點)
* @return 返回的 以node 為根結點的二叉排序樹的最小結點的值
*/
public int delRightTreeMin(Node node) {
Node target = node;
// 迴圈的查詢左子節點,就會找到最小值
while (target.left != null) {
target = target.left;
}
// 這時 target就指向了最小結點
// 刪除最小結點
delNode(target.value);
return target.value;
}
// 刪除結點
public void delNode(int value) {
if (root == null) {
return;
} else {
// 1.需求先去找到要刪除的結點 targetNode
Node targetNode = search(value);
// 如果沒有找到要刪除的結點
if (targetNode == null) {
return;
}
// 如果我們發現當前這顆二叉排序樹只有一個結點
if (root.left == null && root.right == null) {
root = null;
return;
}
// 去找到targetNode的父結點
Node parent = searchParent(value);
// 如果要刪除的結點是葉子結點
if (targetNode.left == null && targetNode.right == null) {
// 判斷targetNode 是父結點的左子結點,還是右子結點
if (parent.left != null && parent.left.value == value) { // 是左子結點
parent.left = null;
} else if (parent.right != null && parent.right.value == value) {// 是由子結點
parent.right = null;
}
} else if (targetNode.left != null && targetNode.right != null) { // 刪除有兩顆子樹的節點
int minVal = delRightTreeMin(targetNode.right);
targetNode.value = minVal;
} else { // 刪除只有一顆子樹的結點
// 如果要刪除的結點有左子結點
if (targetNode.left != null) {
if (parent != null) {
// 如果 targetNode 是 parent 的左子結點
if (parent.left.value == value) {
parent.left = targetNode.left;
} else { // targetNode 是 parent 的右子結點
parent.right = targetNode.left;
}
} else {
root = targetNode.left;
}
} else { // 如果要刪除的結點有右子結點
if (parent != null) {
// 如果 targetNode 是 parent 的左子結點
if (parent.left.value == value) {
parent.left = targetNode.right;
} else { // 如果 targetNode 是 parent 的右子結點
parent.right = targetNode.right;
}
} else {
root = targetNode.right;
}
}
}
}
}
// 新增結點的方法
public void add(Node node) {
if (root == null) {
root = node;// 如果root為空則直接讓root指向node
} else {
root.add(node);
}
}
// 中序遍歷
public void infixOrder() {
if (root != null) {
root.infixOrder();
} else {
System.out.println("二叉排序樹為空,不能遍歷");
}
}
}
// 建立Node結點
class Node {
int value;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
// 返回左子樹的高度
public int leftHeight() {
if (left == null) {
return 0;
}
return left.height();
}
// 返回右子樹的高度
public int rightHeight() {
if (right == null) {
return 0;
}
return right.height();
}
// 返回 以該結點為根結點的樹的高度
public int height() {
return Math.max(left == null ? 0 : left.height(), right == null ? 0 : right.height()) + 1;
}
//左旋轉方法
private void leftRotate() {
//建立新的結點,以當前根結點的值
Node newNode = new Node(value);
//把新的結點的左子樹設定成當前結點的左子樹
newNode.left = left;
//把新的結點的右子樹設定成帶你過去結點的右子樹的左子樹
newNode.right = right.left;
//把當前結點的值替換成右子結點的值
value = right.value;
//把當前結點的右子樹設定成當前結點右子樹的右子樹
right = right.right;
//把當前結點的左子樹(左子結點)設定成新的結點
left = newNode;
}
//右旋轉
private void rightRotate() {
Node newNode = new Node(value);
newNode.right = right;
newNode.left = left.right;
value = left.value;
left = left.left;
right = newNode;
}
// 查詢要刪除的結點
/**
*
* @param value
* 希望刪除的結點的值
* @return 如果找到返回該結點,否則返回null
*/
public Node search(int value) {
if (value == this.value) { // 找到就是該結點
return this;
} else if (value < this.value) {// 如果查詢的值小於當前結點,向左子樹遞迴查詢
// 如果左子結點為空
if (this.left == null) {
return null;
}
return this.left.search(value);
} else { // 如果查詢的值不小於當前結點,向右子樹遞迴查詢
if (this.right == null) {
return null;
}
return this.right.search(value);
}
}
// 查詢要刪除結點的父結點
/**
*
* @param value
* 要找到的結點的值
* @return 返回的是要刪除的結點的父結點,如果沒有就返回null
*/
public Node searchParent(int value) {
// 如果當前結點就是要刪除的結點的父結點,就返回
if ((this.left != null && this.left.value == value) || (this.right != null && this.right.value == value)) {
return this;
} else {
// 如果查詢的值小於當前結點的值, 並且當前結點的左子結點不為空
if (value < this.value && this.left != null) {
return this.left.searchParent(value); // 向左子樹遞迴查詢
} else if (value >= this.value && this.right != null) {
return this.right.searchParent(value); // 向右子樹遞迴查詢
} else {
return null; // 沒有找到父結點
}
}
}
@Override
public String toString() {
return "Node [value=" + value + "]";
}
// 新增結點的方法
// 遞迴的形式新增結點,注意需要滿足二叉排序樹的要求
public void add(Node node) {
if (node == null) {
return;
}
// 判斷傳入的結點的值,和當前子樹的根結點的值關係
if (node.value < this.value) {
// 如果當前結點左子結點為null
if (this.left == null) {
this.left = node;
} else {
// 遞迴的向左子樹新增
this.left.add(node);
}
} else { // 新增的結點的值大於 當前結點的值
if (this.right == null) {
this.right = node;
} else {
// 遞迴的向右子樹新增
this.right.add(node);
}
}
//當新增完一個結點後,如果: (右子樹的高度-左子樹的高度) > 1 , 左旋轉
if(rightHeight() - leftHeight() > 1) {
//如果它的右子樹的左子樹的高度大於它的右子樹的右子樹的高度
if(right != null && right.leftHeight() > right.rightHeight()) {
//先對右子結點進行右旋轉
right.rightRotate();
//然後在對當前結點進行左旋轉
leftRotate(); //左旋轉..
} else {
//直接進行左旋轉即可
leftRotate();
}
return ; //必須要!!!
}
//當新增完一個結點後,如果 (左子樹的高度 - 右子樹的高度) > 1, 右旋轉
if(leftHeight() - rightHeight() > 1) {
//如果它的左子樹的右子樹高度大於它的左子樹的高度
if(left != null && left.rightHeight() > left.leftHeight()) {
//先對當前結點的左結點(左子樹)->左旋轉
left.leftRotate();
//再對當前結點進行右旋轉
rightRotate();
} else {
//直接進行右旋轉即可
rightRotate();
}
}
}
// 中序遍歷
public void infixOrder() {
if (this.left != null) {
this.left.infixOrder();
}
System.out.println(this);
if (this.right != null) {
this.right.infixOrder();
}
}
}
測試結果:
到這裡關於樹結構的實際應用的內容就結束了,關於樹結構的具體應用像赫夫曼編碼,二叉排序樹等程式碼比較複雜,
大家重點要根據思路圖解來分析解題過程,程式碼的具體實現要儘量理解,
最後希望這篇文章對大家有所幫助(◍•͈⌔•͈◍)