python-資料描述與分析(1)
資料描述與分析
在進行資料分析之前,我們需要做的事情是對資料有初步的瞭解,這個瞭解就涉及對行業的瞭解和對資料本身的敏感程度,通俗來說就是對資料的分佈有大概的理解,此時我們需要工具進行資料的描述,觀測資料的形狀等;而後才是對資料進行建模分析,挖掘資料中隱藏的位置資訊。目前在資料描述和簡單分析方面做的比較好的是Pandas庫。當然,它還需要結合我們之前提到的Numpy,Scipy等科學計算相關庫才能發揮功效。
1.Pandas 資料結構
在進行Pandas相關介紹時我們首先需要知道的是Pandas 的兩個資料結構(即物件)Series 和 DataFrame,這是Pandas的核心結構,掌握了此二者結構和屬性要素,會在具體的資料處理過程中如虎添翼。
1.1 Series 簡介
Series 是一種類似於以為資料的物件,它由兩部分組成,第一部分是一維資料,另外一部分是與此一維資料對應的標籤資料。具體如下:
import pandas as pd centerSeries =pd.Series(["中國科學院","文獻情報中心","大樓","北四環西路",]) print (centerSeries)
#output: 0 中國科學院 1 文獻情報中心 2 大樓 3 北四環西路 dtype: object
因為我們沒有指定它的標籤資料,而python預設是通過數位排序進行標識,接下來給他新增標示資料,具體如下:
centerSeries =pd.Series(["中國科學院","文獻情報中心","大樓","北四環西路",],index=["a","b","c","d"]) print (centerSeries) #index的size和Series的size必須一樣長,否則報錯
#output: a 中國科學院 b 文獻情報中心 c 大樓 d 北四環西路 dtype: object
對比之前的預設標識,我們可以看出它由1,2,3,4變成了a,b,c,d。接下來將解釋這樣標識的意義,具體如下:
import pandas as pd centerSeries =pd.Series(["中國科學院","文獻情報中心","大樓","北四環西路",],index=["a","b","c","d"]) print (centerSeries[0]) #通過一維陣列進行獲取資料 print (centerSeries[1]) print (centerSeries["c"]) #通過標識index獲取資料 print (centerSeries["d"])
#output: 中國科學院 文獻情報中心 大樓 北四環西路
另外,我們可以看到通過一維陣列格式獲取資料和通過index標識獲取資料都可以,這樣的index就像曾經學過的資料庫中的id列的作用,相當於建立了每個資料的索引。當然,針對Series的操作不只限於此,還有很多需要我們自己去通過「help」檢視得到的。
1.2 DataFrame 簡介
DataFrame 是一個表格型的資料結構,它包含有列和行的索引,當然你也可以把它看作是由Series組織成的字典。需要說明的是,DataFrame的每一列中不需要資料型別相同,且它的資料是通過一個或者多個二維塊進行存放,在瞭解DataFrame之前如果讀者對層次化索引有所瞭解,那麼DataFrame 可能相對容易理解,當然如果讀者並不知道何謂層次化索引也沒關係,舉個例子:他類似於常見的excel的表格格式,可將它理解為一張excel表,具體如下:
#簡單的DataFrame 製作 #字典格式的資料 data = {"name":["國科圖","國科圖","文獻情報中心","文獻情報中心"], "year":["2012","2013","2014","2015"], "local":["北四環西路","北四環西路","北四環西路","北四環西路"], "student":["甲","乙","丙","丁"]} centerDF = pd.DataFrame(data) print(centerDF)
#output: name year local student 0 國科圖 2012 北四環西路 甲 1 國科圖 2013 北四環西路 乙 2 文獻情報中心 2014 北四環西路 丙 3 文獻情報中心 2015 北四環西路 丁
#調整列的順序 data = {"local":["北四環西路","北四環西路","北四環西路","北四環西路"], "name":["國科圖","國科圖","文獻情報中心","文獻情報中心"], "year":["2012","2013","2014","2015"], "student":["甲","乙","丙","丁"]} centerDF = pd.DataFrame(data,columns=["year","name","local","student"]) print(centerDF)
#output: year name local student 0 2012 國科圖 北四環西路 甲 1 2013 國科圖 北四環西路 乙 2 2014 文獻情報中心 北四環西路 丙 3 2015 文獻情報中心 北四環西路 丁
#更改index的預設設定 data = {"name":["國科圖","國科圖","文獻情報中心","文獻情報中心"], "year":["2012","2013","2014","2015"], "local":["北四環西路","北四環西路","北四環西路","北四環西路"], "student":["甲","乙","丙","丁"]} centerDF = pd.DataFrame(data,columns=["year","name","local","student"],index=["a","b","c","d"]) print(centerDF)
#output: year name local student a 2012 國科圖 北四環西路 甲 b 2013 國科圖 北四環西路 乙 c 2014 文獻情報中心 北四環西路 丙 d 2015 文獻情報中心 北四環西路 丁
既然DataFrame 是行列格式的資料,那麼理所當然可以通過行、列的方式進行資料獲取,按列進行資料據獲取,具體如下:
data = {"name":["國科圖","國科圖","文獻情報中心","文獻情報中心"],
"year":["2012","2013","2014","2015"],
"local":["北四環西路","北四環西路","北四環西路","北四環西路"],
"student":["甲","乙","丙","丁"]}
centerDF = pd.DataFrame(data,columns=["year","name","local","student"],index=["a","b","c","d"])
print (centerDF["name"])
print (centerDF["student"])
#output: a 國科圖 b 國科圖 c 文獻情報中心 d 文獻情報中心 Name: name, dtype: object a 甲 b 乙 c 丙 d 丁 Name: student, dtype: object
另外,可以看出按列進行獲取時他們的index標識是相同的,且每一列是一個Series 物件
按行進行資料獲取,其實是通過index進行操作,具體如下:
data = {"name":["國科圖","國科圖","文獻情報中心","文獻情報中心"],
"year":["2012","2013","2014","2015"],
"local":["北四環西路","北四環西路","北四環西路","北四環西路"],
"student":["甲","乙","丙","丁"]}
centerDF = pd.DataFrame(data,columns=["year","name","local","student"],index=["a","b","c","d"])
print (centerDF.loc["a"])
#在使用進行DataFrame.ix進行表中的資料塊選擇的時候,會丟擲’DataFrame’ object has no attribute ‘ix’,這個是由於在不同的pandas的版本中,DataFrame的相關屬性已過期,已不推薦使用導致的。
#參考程式碼先鋒網

#output: year 2012 name 國科圖 local 北四環西路 student 甲 Name: a, dtype: object
另外,同樣可以看出每一行是一個Series 物件,此時該Series的index其實就是DataFrame 的列名稱,綜上來看,對於一個DataFrame 來說,它是縱橫雙向進行索引,只是每個Series(縱橫)都共用一個索引而已
1.3 利用Pandas載入、儲存資料
在進行資料處理時我們首要工作是把資料載入到記憶體中,這一度成為程式編輯的軟肋,但是Pandas包所提供的功能幾乎涵蓋了大多數的資料處理的載入問題,如read_csv、read_ExcelFile
(1)載入csv格式的資料
import pandas as pd data_csv = pd.read_csv("D:/python_cailiao/test.csv") #它的預設屬性有sep="," data_csv
#output:
school institute grades name 0 中國科學院大學 文獻情報中心 15級 田鵬偉 1 中國科學院大學 文獻情報中心 15級 李四 2 中國科學院大學 文獻情報中心 15級 王五 3 中國科學院大學 文獻情報中心 15級 張三
data_csv = pd.read_csv("D:/python_cailiao/test.csv",sep="#") #更改預設屬性sep="#" data_csv
#output: school,institute,grades,name 0 中國科學院大學,文獻情報中心,15級,田鵬偉 1 中國科學院大學,文獻情報中心,15級,李四 2 中國科學院大學,文獻情報中心,15級,王五 3 中國科學院大學,文獻情報中心,15級,張三
data_csv = pd.read_csv("D:/python_cailiao/test.csv",header=None,skiprows=[0]) #不要表頭Header data_csv
#output: school institute grades name 0 中國科學院大學 文獻情報中心 15級 田鵬偉 1 中國科學院大學 文獻情報中心 15級 李四 2 中國科學院大學 文獻情報中心 15級 王五 3 中國科學院大學 文獻情報中心 15級 張三
data_csv.columns=["school","institute","grades","name"] data_csv #自行新增表頭列
#output: school institute grades name 0 中國科學院大學 文獻情報中心 15級 田鵬偉 1 中國科學院大學 文獻情報中心 15級 李四 2 中國科學院大學 文獻情報中心 15級 王五 3 中國科學院大學 文獻情報中心 15級 張三
另外,綜上,通過對csv格式的檔案進行讀取,我們可以指定讀入的格式(sep=","),也可以指定他的header為空None,最後新增column,而之所以可以後來新增的原因是讀入的csv已經是DataFrame格式物件
(2)儲存csv資料
data_csv.loc[1,"name"]="顧老師" data_csv.to_csv("D:/python_cailiao/save.csv")

(1)載入excel格式的資料
data_excel = pd.read_excel("D:/python_cailiao/excel.xlsx",sheet_name="test") data_excel
#output: school institute grades name 0 中國科學院大學 文獻情報中心 15級 田鵬偉 1 中國科學院大學 文獻情報中心 15級 李四 2 中國科學院大學 文獻情報中心 15級 王五 3 中國科學院大學 文獻情報中心 15級 張三
data_excel.loc[1,"name"]="顧立平老師" data_excel
#output: school institute grades name 0 中國科學院大學 文獻情報中心 15級 田鵬偉 1 中國科學院大學 文獻情報中心 15級 顧立平老師 2 中國科學院大學 文獻情報中心 15級 王五 3 中國科學院大學 文獻情報中心 15級 張三
(2)儲存資料
data_excel.to_excel("D:/python_cailiao/save.xlsx",sheet_name="test")
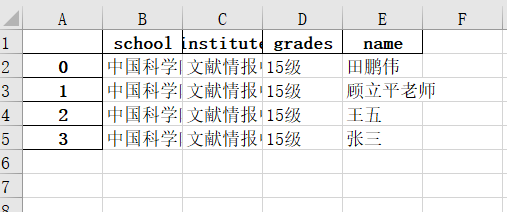
另外,對於excel檔案來說同csv格式的處理相差無幾,但是excel檔案在處理時需要指定sheetname屬性(讀取和寫入sheet_name)
參考書目:《資料館員的python簡明手冊》