設計了一個自動歸檔工具
背景
隨著業務的發展,一些事務類表(源源不斷產生業務資料)會越來越大,最終演變成我們說的大表,普通的查詢可能毫秒級、秒級返回,但是稍微複雜的就會超時,甚至佔滿資料庫cpu,進而導致大面積請求超時、堆積,jvm fullgc,觸發熔斷等連鎖反應。
前幾天業務高峰期的時候收到客戶反饋,說系統存取卡頓,已經嚴重影響業務,需要立即處理,根據以往的經驗我第一時間檢視了資料庫監控,果不其然cpu 100%。
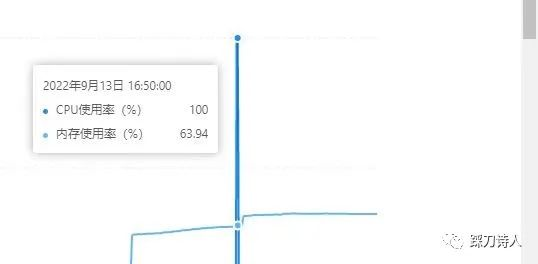
為了快速恢復業務,我將執行時間較長的對談kill掉。
事後分析了事發前的慢查語句,其中有一條查詢操作紀錄檔的sql引起了我的注意,類似於select * from op_log where create_time between xxx and yyy and log like '%keyword%',我一看op_log這個表已經超過2000w行資料,這麼查肯定會查死啊,往群裡一發老大立馬回覆到「這個表是有歸檔的,一般只保留幾個月的,不應該有這麼大,需要跟蹤一下」。
我查了程式碼,的確是有一個歸檔功能,簡單來說就是定時(每月一次)執行以下三行邏輯:
1.List<OpLog> opLogs = select * from op_log where create_time<當前時間-3個月
2.for each insert into op_log_history values xxx,yyy,zzz
3.delete from op_log where create_time<當前時間-3個月
那為什麼還會有這麼多的資料呢,存取人數並沒有明顯增加,帶著疑問我搜尋了9月1號的執行紀錄檔,原來是執行的時候發生了OOM,所以當次也就失敗了,由於8月份的紀錄檔已經刪除,所以不知道8月1號的執行情況,猜測應該也失敗了,因為這個歸檔功能做的實在是太過於簡陋,初看就有以下兩個明顯缺點:
1.select * from op_log where create_time<當前時間-3個月 一次性查詢所有滿足歸檔條件的資料,很容易佔滿jvm記憶體;
2.使用Spring的Schedule實現,沒有加任何重試、報警機制,不滿足系統可觀測性原則。
期望
第一時間調研了一些現成的解決方案,比如pt-archiver,優點是功能完善而且執行時間較久穩定性高,缺點是隻侷限於一些主流的資料庫,而有些客戶採購了一些較為小眾的資料庫,pt-archiver這類工具並不能覆蓋所有場景,鑑於此我們希望自己造輪子,針對不同的資料庫做簡單的適配改造即可,不至於被第三方工具牽絆,查閱了一些資料,常規的資料歸檔方式如下:
-
開發:寫個轉儲邏輯、寫個清理邏輯,部署在某個應用伺服器,週期排程這段程式碼。
-
DBA/運維:寫個轉儲SQL、寫個清理SQL,提交crontab部署在資料庫伺服器,週期排程這個指令碼。
常規的歸檔方式存在以下不足:
-
每個業務表都需要重複一次這樣的開發與設定。
-
無法有效全域性管控,如遇到重大活動、變更等重要視窗無法有效的暫停任務的排程。
-
任務未有效排程時無法及時、有效的通知介入,容易造成線上表資料量過大的問題降級服務效能。
-
執行紀錄檔無法統一管理,有效溯源檢視。
工作流程
針對上面提到的常規的歸檔方式做了一些改進,將歸檔這個動作做了相應的抽象,不需要每個業務表都重複開發一套歸檔邏輯,只需要簡單的設定即可形成一個歸檔任務,最終將歸檔任務同步給xxl-job,這樣就可以複用xxl-job的排程、故障重試、報警、檢視執行紀錄檔等功能。
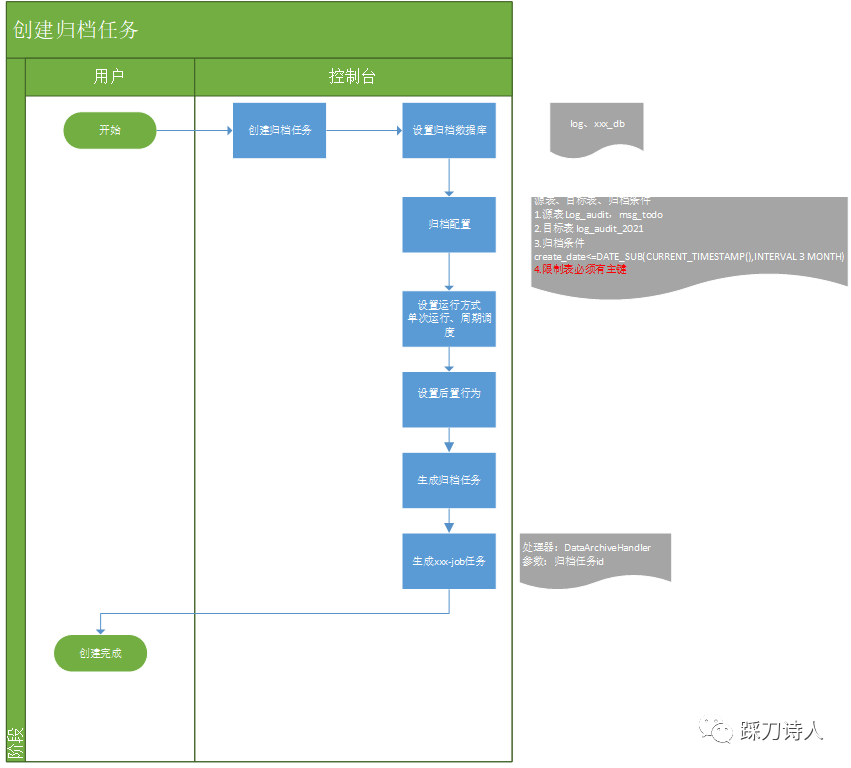
元件設計
控制端
功能列表如下:
1.歸檔任務建立、檢視、刪除;
2.歸檔歷史檢視、手動執行;
3.歸檔任務匯出、匯入。
任務列表
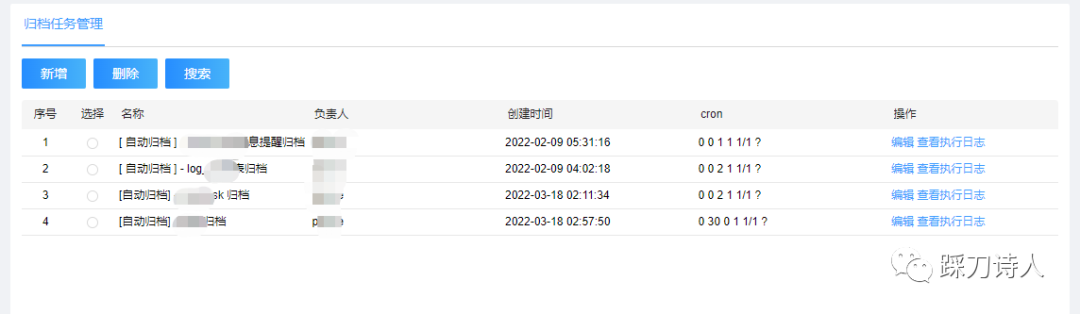
建立&編輯任務
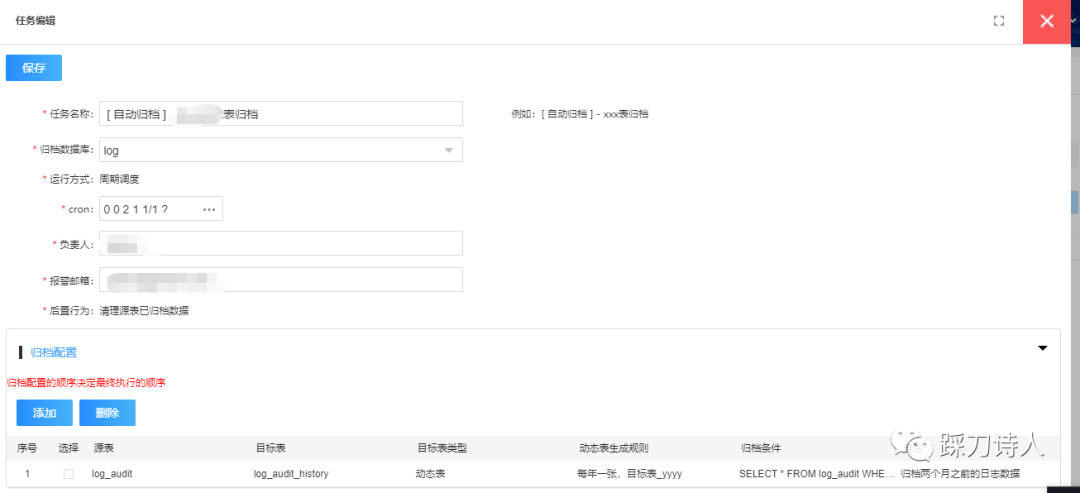
檢視任務執行歷史(複用xxx-job)
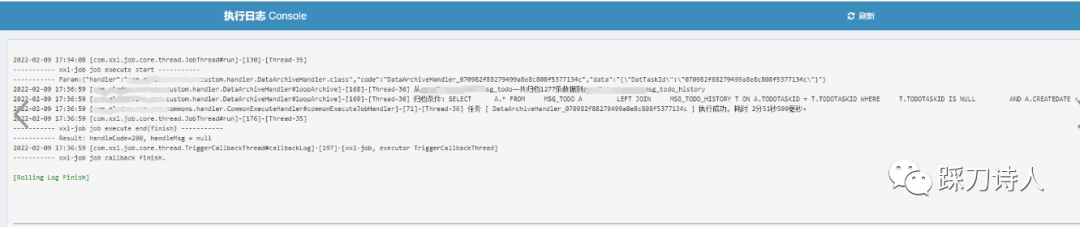
表關係e-r圖
目標表支援固定表和動態表兩種型別,當型別為動態表時,需要指定動態表生成規則,目前支援「每月一張」和「每年一張」兩種生成規則,假設目標表名為dst_table,下面表格列出不同組合下的目標表。
|
目標表名 |
目標表型別 |
動態表生成規則 |
最終目標表 |
|
dst_table |
固定表 |
NA |
dst_table |
|
dst_table |
動態表 |
每月一張 |
dst_table_yyyyMM,比如dst_table_202201 |
|
dst_table |
動態表 |
每年一張 |
dst_table_yyyy如dst_table_2022 |
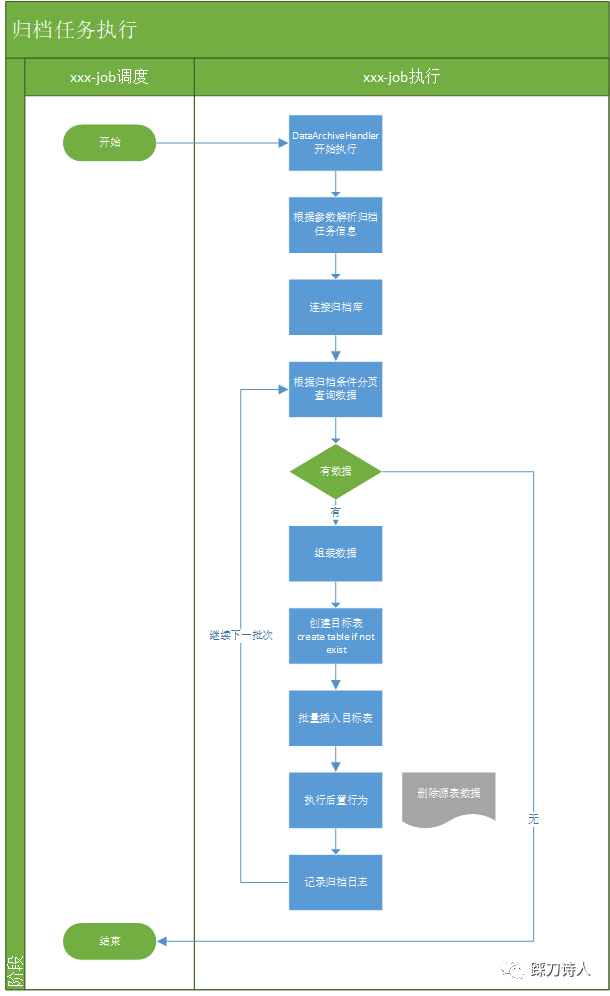
歸檔任務處理器
功能列表如下:
1.根據表示式建立歸檔表;
2.根據歸檔條件拉取歸檔資料並插入目標表;
3.執行後置行為,如刪除原表資料等;
4.記錄歸檔紀錄檔。
涉及到的一些實現細節
1.源表必須要有主鍵
這個主要是考慮異常情況下的重試功能,我們的歸檔邏輯是先插入目標表然後刪除源表,中間如果出現異常情況,可能會出現已經插入到目標表但是沒有從源表刪除的情況,下一次執行就會出現目標表中資料重複的情況,有了主鍵就可以利用資料庫的一些特性來規避,比如mysql中的insert ingore into,也許有人會問為什麼不引入事務機制保證插入和刪除的ACID特性呢,主要是怕麻煩,因為程式碼執行在spring+mybatis框架之下,開啟事務就要引入事務管理器那一套東西,倒不如用一些巧方法規避過去。
通過DatabaseMetaData可以獲取到表的主鍵資訊 DatabaseMetaData.getPrimaryKeys
2.歸檔條件的校驗
歸檔條件是開發手動錄入的sql,難免有手抖的情況,最大的風險在於漏加where條件,所以歸檔條件必須是要校驗的,這裡藉助了jsqlparser框架解析sql,判斷是否包含where。
String archivecondition = "select * from test_table";
Statements statements = CCJSqlParserUtil.parseStatements(archivecondition);
List<Statement> statementList = statements.getStatements();
for(Statement statement : statementList) {
if (!(statement instanceof Select)) {
throw new Exception("歸檔條件只支援select");
}
Select select = (Select) statement;
PlainSelect plainSelect = (PlainSelect) select.getSelectBody();
Expression expression = plainSelect.getWhere();
Assert.isNull(expression,"歸檔條件不包含where");
}
3.執行一段時間後源表和目標表欄位不一致導致儲存失敗
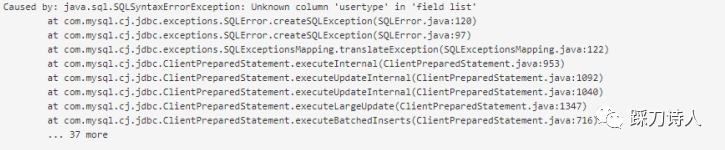
由於業務發展過程中源表中增加了新欄位,但是目標表由於是歸檔處理器自動建立,開發人員一般不會同步增加欄位,這就導致歸檔失敗,也有開發跟我提過需求:「歸檔處理器能不能識別到這類異常自動補全缺失的欄位」,我的回答是這類問題由人工處理,主要考慮到目標表經過長時間的執行可能已經變得異常龐大,貿然的加欄位必然引起資料庫的不穩定,線上大表的變更一定要謹慎,多和dba溝通,儘量選擇夜深人靜的時候。
總結
看似一個小功能也要多方面考慮,效能、相容性、普適性、易用性、可觀測性等等都值得我們深入推敲,想清楚了再幹,當你抱怨CRUD沒有技術含量的時候,就應該考慮怎麼把CRUD做出一朵花出來,這個歸檔功能就是一個再明顯不過的CRUD了。

