[演演算法2-陣列與字串的查詢與匹配] (.NET原始碼學習)
[演演算法2-陣列與字串的查詢與匹配] (.NET原始碼學習)
關鍵詞:1. 陣列查詢(演演算法) 2. 字串查詢(演演算法) 3. C#中的String(原始碼) 4. 特性Attribute 與內在屬性(原始碼) 5. 字串的比較(底層原理) 6. C#中的StringComparsion(原始碼) 7. 字串與暫存池(底層原理)
【注:本人在寫文章時遇到認為有必要或想要展開的點就會將其併入文章中,避免事後遺忘。因此非主題內容可能會比較多,篇幅也可能比較大,各位學者在瀏覽時可以自行轉跳到感興趣的部分進行閱覽,存在相關問題或建議,歡迎留言指導,謝謝!】
查詢,大體上可以分為兩類:陣列查詢、字串查詢。其中陣列查詢以二分為主;字串查詢以BK、BM、KMP三類演演算法為主。由於二分在之前的文章中已經詳細敘述過,在此不再重複論述。故本文主要以有關字串的查詢為重點,附帶.NET關於String型別及相關底層邏輯的原始碼分析為主,進行論述。
【# 請先閱讀注意事項】
【注:
(1)文章篇幅較長,可直接轉跳至想閱讀的部分。
(2)以下提到的複雜度僅為演演算法本身,不計入演演算法之外的部分(如,待排序陣列的空間佔用)且時間複雜度為平均時間複雜度。
(3)除特殊標識外,測試環境與程式碼均為.NET 6/C# 10。
(4)預設情況下,所有解釋與用例的目標資料均為升序。
(5)預設情況下,圖片與文字的關係:圖片下方,是該幅圖片的解釋。
(6)文末「 [ # … ] 」的部分僅作補充說明,非主題(演演算法)內容,該部分屬於 .NET 底層執行邏輯,有興趣可自行參閱。
(7)本文內容基本為本人理解所得,可能存在較多錯誤,歡迎指出並提出意見,謝謝。】
一、有關陣列
(一) 二分查詢及相關優化
關於二分的相關內容,在本人的這篇文章中(LC T668筆記 & 有關二分查詢、第K小數、BFPRT演演算法 - PaperHammer - 部落格園 (cnblogs.com))有較為詳細地論述,詳情請參閱。
在此,僅總結一下二分的要點:
1. 二分集合須保證有序。有序是二分的前提,在二分前須明確二分的物件,該物件必須具有有序性。
2. 確定搜尋區間形式(閉區間、左閉右開、左開右閉)。不同區間形式,迴圈條件與最終返回值不同;同時也應用於不同的場景。
3. 儘量寫或想清楚所有的if…else…,清楚地展現出所有細節,避免不必要的紕漏與麻煩。
(二) 有關方法BinarySearch()的原始碼
該方法的主要實現形式是雙指標或折半查詢,詳細內容在本人之前的文章([資料結構1.2-線性表] 動態陣列ArrayList(.NET原始碼學習) - PaperHammer - 部落格園 (cnblogs.com))中,詳情請參閱。
二、有關字串
(一) .NET中的String與C#中的string
1. C#是區分大小寫的語言,所以string與String理論上是不同的,但在編譯器的定義導航中,卻將這兩個型別均導航至同一個類——類String。
2. 據現有資料可知,String是.NET(以前稱為.NET Framework)中的類,string是C#中的類。在C#中使用string時,編譯器會將string自動對映到.NET中的String,同時呼叫的方法也是.NET中類String內部的方法。據該原理,使用String可以在一定程度上減少編譯器的工作量,但微軟官方不建議這樣,依舊建議使用string以符合相關規範。其他基本資料型別也是如此,如short對映Int16,int對映Int32,long對映Int64,double對映Double等。
3. 這樣做的原因個人猜測可能如下:.NET是一套底層執行規範,其需要對所有支援的語言定義一個通用的規則(CLS通用語言規範Common Language Specification)不同語言語法的不同,.NET通過CLS提供了公共的語法,不同語言經過IL的翻譯生成對應的.NET語法。如F#中的let賦值語句(let str = 「.NET」;;);VB中的String(Dim 變數名 As String = 「.NET」);加上現在C#中的string。它們都是基於.NET執行的,所以需要有一個總綱來規範化,使得每個語言具有獨特性的同時,可以實現相同或相近的功能。因此在.NET中定義了類String,無論時哪種語言,只要編譯時需要使用.NET,均須遵守其相關規範,將獨特的風格轉換為統一且通用的規範化表達。
4. 因此,String不是C#中的關鍵字,可以將其用作變數名。
以上是根據現有的遠古資料推斷出的執行方式,因為資料實在有限,本人目前對 CLR 瞭解並不是很深,如果存在錯誤或其他見解還請留言!
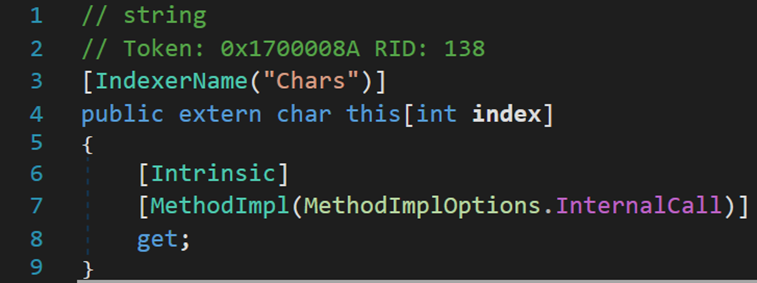
[# 有關MethodImpl]
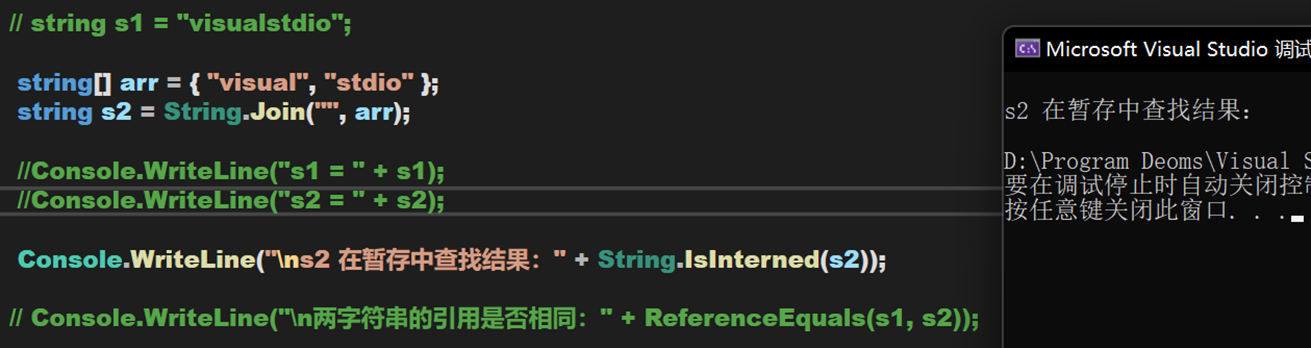
並且,無法再暫存池中查詢到 s2 的參照,據此推斷在編譯階段不能確定值得字串不會被寫入暫存池。
- StringBuilder 構建


同理,對於 StringBuilder 的構建,依舊無法在編譯階段確定其值,也就沒有寫入暫存池。
- 預留位置


由於預留位置需要呼叫方法體,因此無法在編譯階段確定 s2 的值。
- 字串的內插
先簡單介紹一下什麼是字串內插。由於預留位置需要我們在字串中先用數位標記位置,再到字串結束後寫下對應的值,過程較為繁瑣,因此引入內插操作。

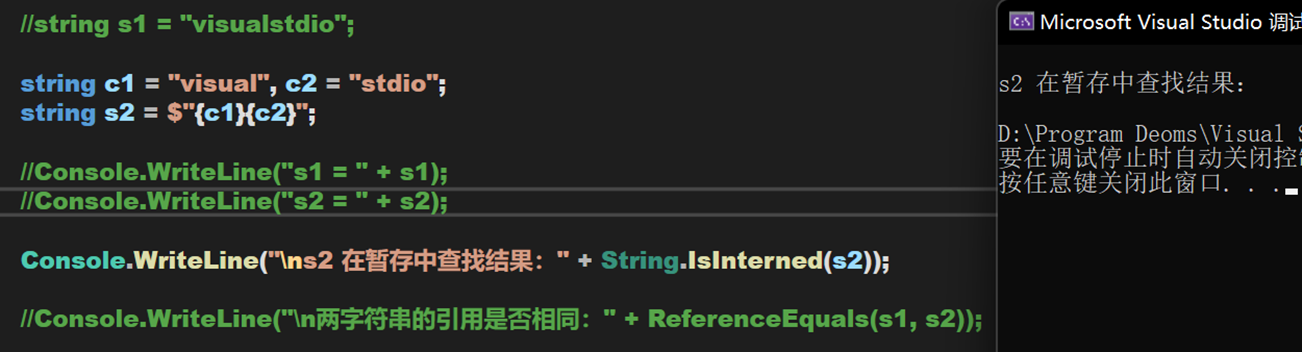
使用符號 ‘$’ 代表被標記的字串將實行內插操作。可看到,雖然內插操作看似不執行方法體,但依舊不指向暫存池中的物件,說明內插操作的值是在執行階段完成的。
不過,對於此處 s2 的定義方式,當 c1 與 c2 是常數時,其在編譯階段即可被確定,會被寫入暫存池。
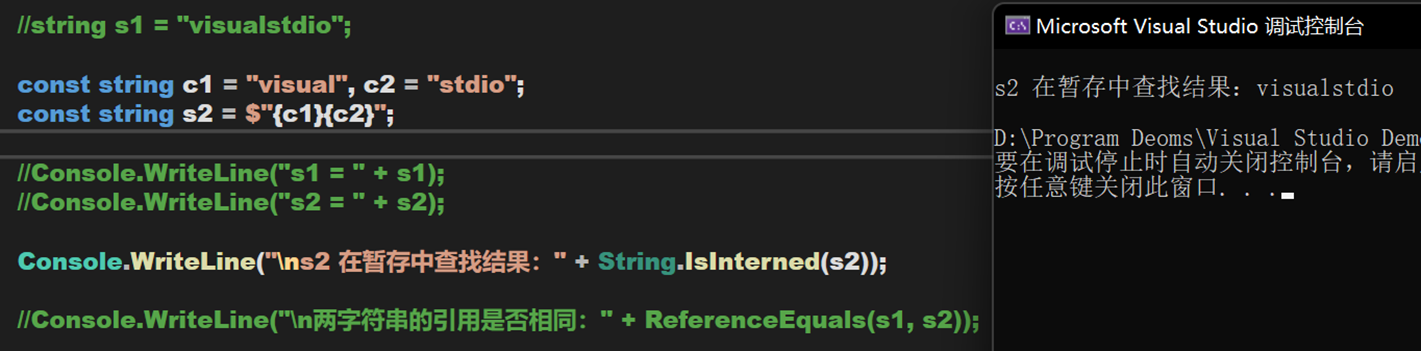
小結
對於暫存池的寫入,在此得出的結論是:
(1)只有在編譯階段可以確定的字串,才會被查詢或寫入暫存池中。如何判斷一個字串是在編譯階段被確定的?只需要在之前加上關鍵字 const 即可,報錯則表示不能在編譯階段確定。
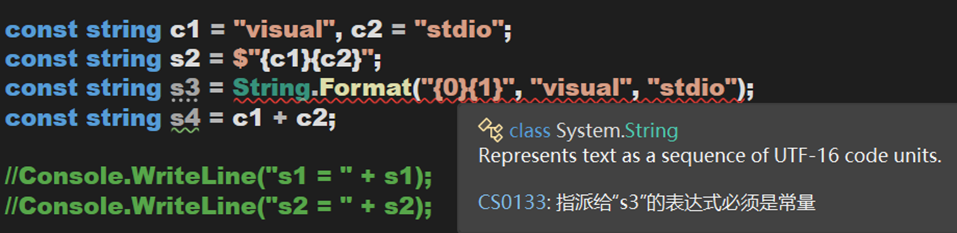
(2)除了直接完整初始化和使用運運算元這兩種方式以外(注:不排除有其他方式),其餘方式均不會再暫存池中進行查詢或寫入。
(3)對於存在於暫存池中的字串,即使之後不會再被使用,也不會被 GC 回收。
(4)若不想要讓字串池化。可加上特性標記 [assembly: CompilationRelaxations(CompilationRelaxations.NoStringInterning)]。即使加上後也不會被 GC 回收。
—— —— —— —— —— —— —— —— —— —— —— —— —— ——
下面解決剩下的問題:為什麼要針對字串專門建立一個暫存池這樣的機制,而值型別和其他參照型別沒有這樣的機制?
結合資料,個人推斷,應該是因為字串的不可變性。
(1)字串是參照型別,在建立時不斷地在堆上開闢新空間,會佔用較高記憶體,產生較大的消耗。而值型別是在棧上儲存,相比於堆來說,不是那麼消耗記憶體。
(2)字串的不可變性,使得其在確定之後就不可更改。此處的不可更改指的是,只要賦值,該值就會一直保留在記憶體中直到程式結束。為了避免出現大量重複物件,而建立大量重複範例佔用大量記憶體的問題,引入了暫存機制。而其他參照型別不具有不可變性,一般地可以在執行時隨意修改,相對而言不需要這樣的暫存機制。