謠言檢測(GACL)《Rumor Detection on Social Media with Graph Adversarial Contrastive Learning》
論文資訊
論文標題:Rumor Detection on Social Media with Graph AdversarialContrastive Learning
論文作者:Tiening Sun、Zhong Qian、Sujun Dong
論文來源:2022, WWW
論文地址:download
論文程式碼:download
Abstract
儘管基於GNN的方法在謠言檢測領域取得了一些成功,但是這些基於交叉熵損失的方法常常導致泛化能力差,並且缺乏對一些帶有噪聲的或者對抗性的樣本的魯棒性,尤其是一些惡意謠言。有時,僅僅設定一個簡單的擾動就會導致標籤被高度置信地錯誤分類,這對謠言分類系統無疑是一個巨大的潛在危害。因此,現有的資料驅動模型需要變得更加健壯,以應對通常由正常使用者無意識地產生和傳播的錯誤資訊或者由謠言製造者惡意設計的混亂對話結構。
在本文中,我們提出了一種新的圖對抗對比學習(GACL)方法來對抗這些複雜的情況,其中引入對比學習作為損失函數的一部分,用於明確感知同類和不同類的對談執行緒之間的差異。同時,設計了一個對抗性特徵變換(AFT)模組來產生相互衝突的樣本,以加壓模型以挖掘事件不變的特徵。這些對抗性樣本也被用作對比學習的硬負樣本,使模型更魯棒和有效。在三個公共基準資料集上的實驗結果表明,我們的 GACL 方法比其他最先進的模型取得了更好的結果。
1 Introduction
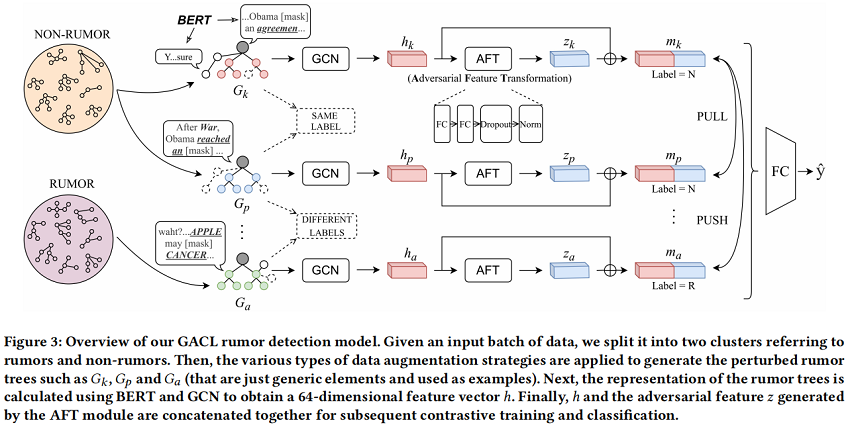
本文提出一個圖對抗對比學習(GACL)方法謠言檢測。具體來說,首先採用 edge perturbation 和 dropout 等圖資料增強策略掩模來模擬 Figure 1(b) 的情況,它為模型提供了豐富噪聲的輸入資料。然後,我們引入 Figure 2 所示的監督圖對比學習 來訓練 GNN 編碼器 明確地感知增強資料的差異,並學習魯棒表示。與自監督對比學習策略不同,本文的方法可以更有效地利用標籤資訊。這樣,就可以防止在一些包含噪聲的情況下,如錯誤的註釋和混亂的字元被檢測模型錯誤地分類。
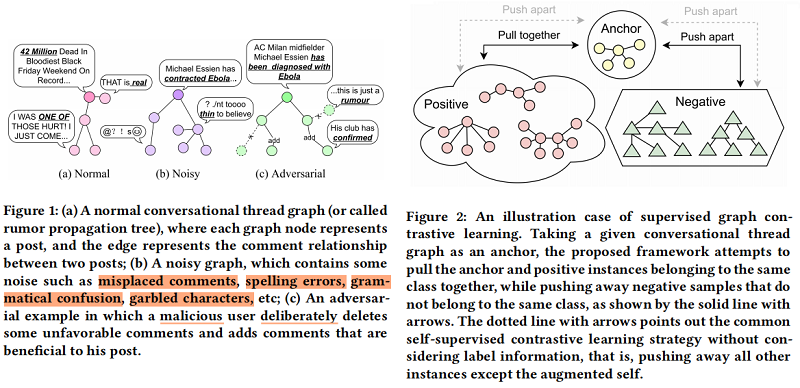
有時,僅憑這一點是不夠的。因為在現實世界中,除了由普通使用者無意中創造和傳播的錯誤資訊外,還有一些由謠言生產者精心設計和故意推廣的惡意謠言,如 Figure 1(c) 所示,這可能會使該模型失效。一些研究人員也注意到了這個問題。Ma等人[21]分析了一個關於「沙烏地阿拉伯斬首第一個女性機器人公民」的謠言案例,以說明謠言機器人如何使用高頻和指示性詞彙來掩蓋事實。Yang等人 [32] 還提到,謠言生產者經常操縱由使用者、訊息來源和評論組成的關係網路,以逃避檢測。無論是文字篡改還是網路操縱,謠言製作者的目的都是使謠言在高維空間中接近非謠言樣本,從而混淆模型。因此,為了解決這個問題,我們開發了一個對抗性特徵轉換(AFT)模組,旨在利用對抗性訓練來生成具有挑戰性的特徵。這些對抗性特徵將作為對比學習中的硬負樣本,幫助模型加強對這些困難樣本的特徵學習,實現魯棒性和有效的檢測。此外,我們直觀地相信,這些對抗性的特徵可以被解碼成各種不同型別的擾動。
本文貢獻:
-
- 據我們所知,這是第一個將對比學習引入謠言檢測任務的研究,旨在通過感知同一標籤和不同標籤樣本之間的差異來提高表徵質量。
- 我們提出了GACL模型,它不僅考慮了謠言的傳播結構資訊,還模擬了噪聲和對抗性情況,並利用對比學習捕獲了事件不變特徵。
- 在GACL框架下,我們開發了AFT模組來生成對抗性特徵,這些特徵作為對比學習中的硬負樣本,以學習更魯棒的表示。
- 我們通過實驗證明,我們的模型在真實世界的資料集上優於最先進的基線。
2 Method
2.1 Definition
本文將謠言檢測定義為一種分類任務,其目的是從一組帶標籤的訓練事件中學習一個分類器, 然後用它來預測測試事件的標籤。使用 $C=\left\{c_{1}, c_{2}, \cdots, c_{n}\right\}$ , $c_{i}$ 是第 $i$ 個事件, $n$ 是事件的數量。每個事件 $c=(y, G)$ 包含 ground-truth 標籤 $y \in\{R, N\}$ (也就是 Rumor 和 Non-rumor) 和其傳播結構樹 $G=(V, E)$ , $V$ 和 $E$ 分別是節點和邊的集合。有時謠言檢測被定義為一個四類的分類任務,相應的 $y \in\{N, F, T, U\}$ ( Non-rumor、False Rumor、True Rumor、Unverified Rumor)。在模型訓練階段,$\hat{G}$ 由資料增強生成,目的是與原圖 $G$ 一起學習一個分類器 $f(\cdot)$ 。在測試階段,只有原圖 $G$ 會被用來預測給定事件 $c_{i}$ 的標籤。
2.2 Framework
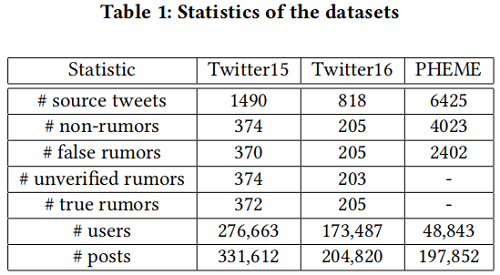
2.3 Graph Data Augmentation
GACL採用 Edge perturbation 策略進行資料增強。對於一個圖 $G=(V, E) $ ,其鄰接矩陣為 $A$ ,特徵矩陣為 $X$ , Edge perturbation 在訓練時將會根據一定的概率 $r$ 來隨機丟棄、 新增或者誤置一些邊,以此來干擾 $G$ 的連線。假設新生成的增強圖為 $\hat{G}^{\prime}$,$A_{\text {perturbation }}$ 為一 個從原來的邊集合中隨機取樣的矩陣,則 $\hat{G}$ 的鄰接矩陣 $A^{\prime}$ 可以計算為對謠言製造者設計的偽裝結構。
此外,對於謠言檢測任務,上圖中由 $post$ 組成的圖節點的文字資訊也是正確分類謠言的關鍵線索之一,還需要對其進行增強以提供一些噪聲。本文采用 Dropout mask 來對這些文字進行增強,也就是隨機 mask 每個 post 中的一些詞,如上圖所示。
2.4 Graph Representation
本文使用 BERT 來獲取事件的原文和評論的句子表示,以構建新的 $X$ 。為了強調 source post 的重要性,以 [CLS] Source [SEP] Comment [SEP] 的形式來將原文和評論連線起來,以 [CLS] 這個 token 的最終表示作為節點的表示。
本文使用一個兩層 $\mathrm{GCN}$ 作為 encoder 。當前圖記為 $G_{k} $ ,其增強圖為 $\hat{G}_{k}$ ,經過兩層 $\mathrm{GCN}$ 後學習到的節點表示矩陣為 $H_{k}^{(2)}$ ,最後使用一個 mean-pooling 來獲得圖的表示:
$h_{k}=M E A N\left(H_{k}^{(2)}\right)$
2.5 AFT Component
如 Figure 3 所示,AFT 由 $L = 2$ fully connected layers、Dropout 和 Normalization (DN) 組成。經過 AFT module 後,$h_k$ 轉換為 $z_k$,公式為
$z_{k}=D N\left(\max \left(0, h_{k} W_{1}^{A F T}+b_{1}\right) W_{2}^{A F T}+b_{2}\right)$
將得到的 $z_k$ 向量作為對比學習中的硬負樣本。
現在,對於 batch 中的每一個 post,我們得到了 GCN 編碼的相應圖表示 $h_{k}$,以及 AFT 生成的對抗表示 $z_{k}$。然後,我們將它們連線起來,以將資訊合併為
$m_{k}=\operatorname{concat}\left(h_{k}, z_{k}\right)$
接下來,將 $m_{k}$ 輸入全連線層和 softmax 層,輸出計算為
$\hat{y}_{k}=\operatorname{softmax}\left(W_{k}^{F} m_{k}+b_{k}^{F}\right)$
其中,$\hat{y} \in \mathbb{R}^{1 \times C}$ 為預測的概率分佈。$W^{F}$ 和 $b^{F}$ 分別為可訓練的權重矩陣和偏差。
2.6 Adversarial Contrastive Learning
本文采用的損失函數旨在給定標籤資訊的條件下最大化正樣本之間的一致性同時拉遠負樣本。 如 Figure 3 ,以 $m_{k}$ 作為錨點,具備與 $m_{k}$ 相同標籤的 $m_{p}$ 作為正樣本,具備與 $m_{k}$ 不同標籤的 $m_{a}$ 作為負樣本。對比損失的目的是讓具有相同標籤的樣本餘弦相似度變大,具有不同標籤的樣本餘弦相似度變小。最終的損失函數為:
$\mathcal{L}=\mathcal{L}_{c e}+\alpha \mathcal{L}_{s u p}$
這兩部分損失分別是:
$\mathcal{L}_{c e}=-\frac{1}{N} \sum\limits ^{N} \sum\limits^{M} y_{k, c} \log \left(\hat{y}_{k, c}\right)$
${\large \mathcal{L}_{s u p}=-\sum\limits _{k \in K} \log \left\{\frac{1}{|P(k)|} \sum\limits _{p \in P(k)} \frac{\exp \left(\operatorname{sim}\left(m_{k}, m_{p}\right) \tau\right)}{\sum\limits _{a \in A(k)} \exp \left(\operatorname{sim}\left(m_{k}, m_{a}\right) \tau\right)}\right\}} $
$k$ 代表第幾個樣本, $c$ 代表類別, $A(k)=\left\{a \in K: y_{a} \neq y_{k}\right\}$ 是負樣本索引,$P(k)=\left\{p \in K: y_{p}=y_{k}\right\}$ 是正樣本索引, $\operatorname{sim}(\cdot)$ 為餘弦相似度,即 $\operatorname{sim}\left(m_{k}, m_{p}\right)=m_{k}^{T} m_{p} /\left\|m_{k}\right\|\left\|m_{p}\right\|$ , $\tau \in \mathbb{R}^{\dagger}$ 是溫度超引數。
一部分研究表明BERT驅動的句子表示容易造成坍塌現象,這是由於句子的語意資訊由高頻詞主導。在謠言檢測中,高頻詞經常被謠言製造者利用來逃避檢測。因此採用對比學習的方式能夠 平滑化句子的語意資訊,並且理論上能夠增加低頻但重要的詞的權重。本文通過最小化 $\mathcal{L}$ 來更新模型的引數,但不包括 AFT 的引數。
AFT 基於對抗學習單獨訓練。模型中 AFT 的引數記作 $\theta_{a}$ ,其他引數記作 $\theta_{s}$ 。在每一個 epoch 中,我們最小化 $\mathcal{L}$ 來更新 $\theta_{s}$ ,最大化 \mathcal{L} 來更新 \theta_{a} 。我們利用對抗學習來最小化對抗樣本與相同標籤樣本的一致性,最大化對抗樣本與不同標籤樣本的一致性。整個演演算法如下:

3 Experiment
Datasets
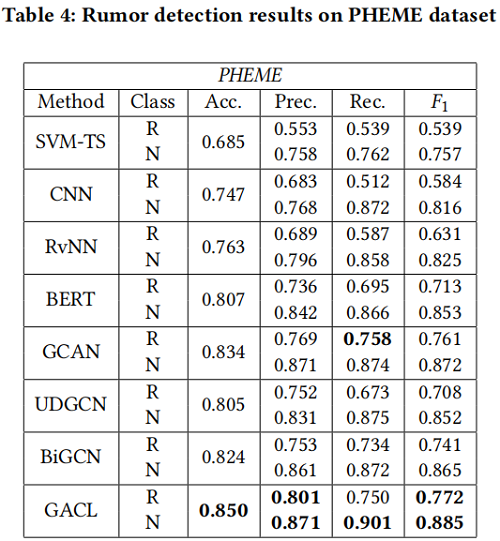
Ablation study


4 Conclusion
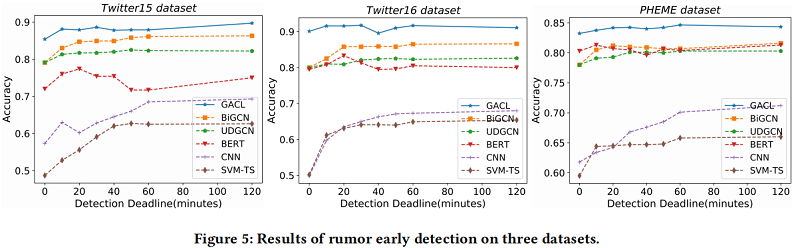
本文提出了一種新的謠言檢測模型,即GACL。首先,採用訓練前模型BERT獲得GACL中每個貼文的表示,然後使用GCN對謠言傳播的結構資訊進行編碼。其次,引入對比學習,通過捕獲同一類範例之間的共性和不同類範例之間的差異來提高表示的質量。最後,將AFT模組載入到模型中,採用對抗性學習策略進行訓練,以生成對抗性特徵。這些對抗性特徵在對比學習中作為硬負樣本,並在訓練階段作為輸入向量的一部分輸入到softmax模組中,有利於捕獲事件不變特徵。實驗結果表明,我們的GACL方法對三個公共真實資料集的謠言檢測具有良好的有效性和魯棒性,並且在早期謠言檢測任務中顯著優於其他最先進的模型。
我們未來的工作將集中於多模態資訊的融合和提取、偏見檢測和模型決策的可解釋性。
因上求緣,果上努力~~~~ 作者:關注我更新論文解讀,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/16737902.html