面試題:海量資料處理利器-布隆過濾器
作者:小牛呼嚕嚕 | https://xiaoniuhululu.com
計算機內功、JAVA底層、面試相關資料等更多精彩文章在公眾號「小牛呼嚕嚕 」
概念
通常我們會遇到很多要判斷一個元素是否在某個集合中的業務場景,一般想到的是將集合中所有元素儲存起來,然後通過比較確定。連結串列、樹、雜湊表(又叫雜湊表,Hash table)等等資料結構都是這種思路。但是隨著集合中元素的增加,我們需要的儲存空間也會呈現線性增長,最終達到瓶頸。同時檢索速度也越來越慢,上述三種結構的檢索時間複雜度分別為O(n), O(logn), O(1)。這個時候,布隆過濾器就應運而生。
布隆過濾器(Bloom Filter)是1970年由布隆提出的。布隆過濾器其實就是一個很長的二進位制向量和一系列隨機對映函數。可以用於快速檢索一個元素是否在一個集合中出現的方法。
原理
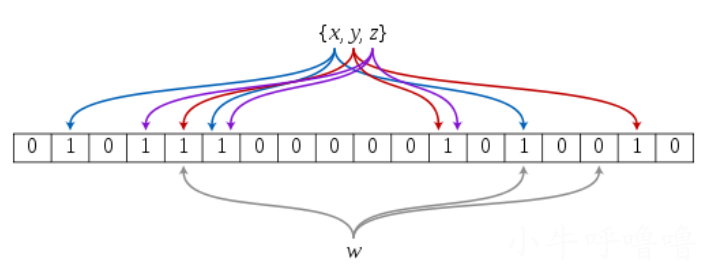
如果想判斷一個元素是不是在一個集合裡,我們一般想到的是將所有元素儲存起來,然後通過比較確定。我們熟悉的連結串列,樹等等資料結構都是這種思路。但是隨著集合中元素的增加,我們需要的儲存空間越來越大,檢索速度也越來越慢。不過世界上還有一種叫作雜湊表(又叫雜湊表)的資料結構。它可以通過一個Hash函數將一個元素對映成一個位陣列中的一個點。這樣一來,我們只要看看這個點是不是 1 就知道可以集合中有沒有它了。這其實就是布隆過濾器的基本思想。
Hash演演算法面臨的問題就是hash衝突。假設 Hash 函數是良好的,如果我們的位陣列長度為 m 個點,那麼如果我們想將衝突率降低到例如 1%, 這個雜湊表就只能容納 m/100 個元素。顯然這就不叫空間有效了(Space-efficient)。解決方法:就是使用多個 Hash演演算法,如果它們有一個說元素不在集合中,那肯定就不在。如果它們都說在,有一定可能性它們在說謊,雖然概率比較低。
演演算法:
- 首先需要k個hash函數,每個函數可以把key雜湊成為1個整數
- 初始化時,需要一個長度為n位元的陣列,每個位元位初始化為0
- 某個key加入集合時,用k個hash函數計算出k個雜湊值,並把陣列中對應的位元位置為1
- 判斷某個key是否在集合時,用k個hash函數計算出k個雜湊值,並查詢陣列中對應的位元位,如果所有的位元位都是1,認為在集合中。
其優點:
- 空間效率和查詢時間都比一般的演演算法要好的多,比如增加和查詢元素的時間複雜為O(N)
- 由於不需要儲存key,所以特別節省儲存空間。
- 保密性強,布隆過濾器不儲存元素本身~~
其缺點:
- 由於採用hash演演算法,可能出現hash衝突,導致有一定的誤判率,但是可以通過調整引數來降低
布隆過濾器的誤判是指多個輸入經過雜湊之後在相同的bit位置1了,這樣就無法判斷究竟是哪個輸入產生的,因此誤判的根源在於相同的 bit 位被多次對映且置 1。
- 無法獲取元素本身
- 由於hash演演算法導致hash衝突必然存在,所以刪除元素是很困難的,而且刪掉元素會導致誤判率增加。
布隆過濾器的使用場景
我們可以充分利用布隆過濾器的特點:如果布隆過濾器說有一個說元素不在集合中,那肯定就不在。如果布隆過濾器說在,有一定可能性它在說謊。
- 比較熱門的場景就是:解決Redis快取穿透問題
快取穿透: 指使用者的請求去查詢快取和資料庫中都不存在的資料,可使用者還是源源不斷的發起請求,導致每次請求都會打到資料庫上,從而壓垮資料庫
- 郵件過濾,使用布隆過濾器來做郵件黑名單過濾,還有重複推薦內容過濾,網址過濾, web請求存取攔截器,等等
- 許多資料庫內建布隆過濾器,用於判斷資料是否存在,可以減少資料庫很多不必要的磁碟IO操作
簡單模擬布隆過濾器
我們來看一個例子:
public class MyBloomFilter {
/**
* 一個長度為10 億的位元位
*/
private static final int DEFAULT_SIZE = 256 << 22;
/**
* 為了降低錯誤率,使用加法hash演演算法,所以定義一個8個元素的質數陣列
*/
private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61};
/**
* 相當於構建 8 個不同的hash演演算法
*/
private static HashFunction[] functions = new HashFunction[seeds.length];
/**
* 初始化布隆過濾器的 bitmap
*/
private static BitSet bitset = new BitSet(DEFAULT_SIZE);
/**
* 新增資料
*
* @param value 需要加入的值
*/
public static void add(String value) {
if (value != null) {
for (HashFunction f : functions) {
//計算 hash 值並修改 bitmap 中相應位置為 true
bitset.set(f.hash(value), true);
}
}
}
/**
* 判斷相應元素是否存在
* @param value 需要判斷的元素
* @return 結果
*/
public static boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (HashFunction f : functions) {
ret = bitset.get(f.hash(value));
//一個 hash 函數返回 false 則跳出迴圈
if (!ret) {
break;
}
}
return ret;
}
/**
* 模擬使用者在不線上。。。
*/
public static void main(String[] args) {
for (int i = 0; i < seeds.length; i++) {
functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]);
}
// 新增1億資料
for (int i = 0; i < 100000000; i++) {
add(String.valueOf(i));
}
String id = "123456789";
add(id);
System.out.println(contains(id)); //結果: true
System.out.println("" + contains("234567890")); //結果: false
}
}
class HashFunction {
private int size;
private int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
int r = (size - 1) & result;
return (size - 1) & result;
}
}
我們平時學習的時候可以去實現一下演演算法,但實際開發過程中,一般不推薦重複造輪子,簡單的實現布隆過濾器, 我們一般可以用google.guava庫
Guava布隆過濾器
首先引入依賴:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
舉個例子:
// 建立布隆過濾器物件,預計包含的資料量:2000個,和允許的誤差值0.01
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
2000,
0.01);
System.out.println(filter.mightContain(10));// 判斷指定元素是否存在
System.out.println(filter.mightContain(20));
filter.put(10);// 將元素新增進布隆過濾器
filter.put(20);
System.out.println(filter.mightContain(10));// 判斷指定元素是否存在
System.out.println(filter.mightContain(20));
其中:當mightContain()方法返回_true_時,我們可以大概率確定該元素在過濾器中,但當過濾器返回_false_時,我們可以100%確定該元素不存在於過濾器中。
布隆過濾器的 允許的誤差值 越小,需要的儲存空間就越大,對於不需要過於精確的場景,允許的誤差值 設定稍大一點也可以。
Guava 提供的布隆過濾器的實現還是很不錯的,但是隨著微服務、分散式的不斷髮展,對於微服務多範例的場景下就不太適用了,只適合單機,解決方案是:一般是藉助Redis中的布隆過濾器
Redis布隆過濾器
Redis 4.0 的時候官方提供了外掛機制,布隆過濾器正式登場。以下網站可以下載官方提供的已經編譯好的可拓展模組。
https://redis.com/redis-enterprise-software/download-center/modules
這邊使用docker安裝,自己挑選合適的映象
~ docker pull redislabs/rebloom:latest
~ docker run -p 6379:6379 --name redis-bloom redislabs/rebloom:latest
~ docker exec -it redis-bloom bash
root@113d012d35:/data# redis-cli
127.0.0.1:6379>
進入容器內部後,常用的命令:
//-------------------------常用命令
BF.ADD --新增一個元素到布隆過濾器
BF.EXISTS --判斷元素是否在布隆過濾器
BF.MADD --新增多個元素到布隆過濾器
BF.MEXISTS --判斷多個元素是否在布隆過濾器
//-------------------------具體操作
127.0.0.1:6379> BF.ADD myFilter hello
(integer) 1
127.0.0.1:6379> BF.ADD myFilter people
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter hello
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter people
(integer) 1
127.0.0.1:6379> BF.EXISTS myFilter github
(integer) 0
布穀鳥過濾器
為了解決布隆過濾器不能刪除元素的問題,布穀鳥過濾器應運而生。論文《Cuckoo Filter:Better Than Bloom》作者將布穀鳥過濾器和布隆過濾器進行了深入的對比。但是其刪除並不完美,存在誤刪的概率,還存在插入複雜度比較高等問題。由於使用較少,本文就不過多介紹了,感興趣的自行了解文章。
參考資料:
https://www.cnblogs.com/feily/articles/14048396.html
https://www.cnblogs.com/liyulong1982/p/6013002.html
本篇文章到這裡就結束啦,很感謝你能看到最後,如果覺得文章對你有幫助,別忘記關注我!更多精彩的文章
