原生Redis跨資料中心雙向同步優化實踐
一、背景
公司基於業務發展以及戰略部署,需要實現在多個資料中心單元化部署,一方面可以實現多資料中心容災,另外可以提升使用者請求存取速度。需要保證多資料中心容災或者實現使用者就近存取的話,需要各個資料中心擁有一致的全量資料,如果真正實現使用者就近讀寫,也就是實現真正的業務異地多活,資料同步是異地多活的基礎,這就需要多資料中心間資料能夠雙向同步。
二、原生redis遇到的問題
1、不支援雙主同步
原生redis並沒有提供跨機房的主主同步機制,僅支援主從同步;如果僅利用redis的主從資料同步機制,只能將主節點與從節點部署在不同的機房。當主節點所在機房出現故障時,從節點可以升級為主節點,應用可以持續對外提供服務。但這種模式下,若要寫資料,則只能通過主節點寫,異地機房無法實現就近寫入,所以不能做到真正的異地多活,只能做到備份容災。而且機房故障切換時,需要運維手動介入。
因此,想要實現主主同步機制,需要同步工具模擬從節點方式,將本地機房中資料同步到其他機房,其他機房亦如此。同時,使用同步工具實現跨資料中心資料同步,會遇到以下一些問題。
(1)資料迴環
資料迴環的意思是,A機房就近寫入的資料,通過同步工具同步到B機房後,然後又通過B機房同步工具同步回A機房了。所以在同步的過程中需要識別本地就近寫入的資料還是其他資料中心同步過來的資料,只有本地就近寫入的資料需要同步到其他資料中心。
(2)冪等性
同步過程中的命令可能因斷點續傳等原因導致重複同步了,此時需要保證同一命令多次執行保證冪等。
(3)多寫衝突
以雙寫衝突為例,如下圖所示:
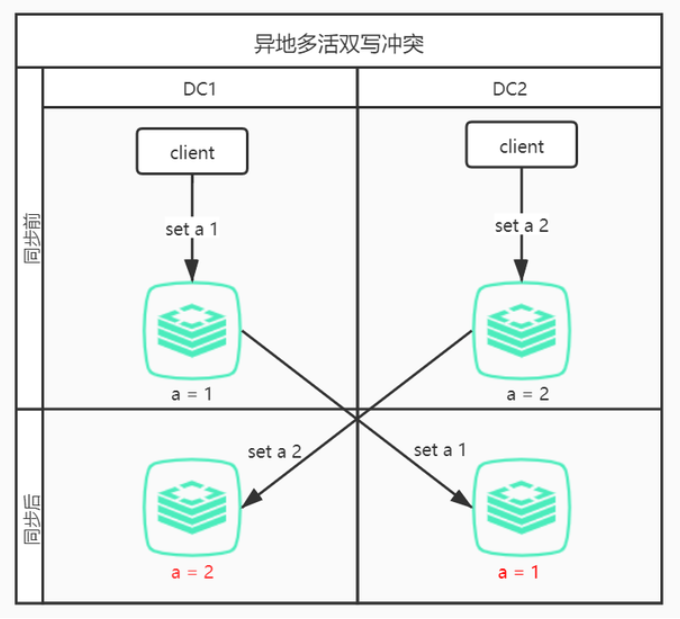
DC1寫入set a 1,同時DC2寫入set a 2,當這兩條命令通過同步工具同步到對方機房時,導致最終DC1中儲存的a為2,DC2中儲存的a為1,也就是說兩個機房最終資料不一致。
2、斷點續傳
針對瞬時的斷開重連、從節點重啟等場景,redis為了提高該場景下的主從同步效率,在主節點中增加了環形複製緩衝區,主節點往從節點寫資料的同時也往復制緩衝區中也寫入一份資料,當從節點斷開重連時,則只需要通過複製緩衝區把斷開期間新增的增量資料傳送給從節點即可,避免了全量同步,提升了這些場景下的同步效率。
但是,該記憶體複製緩衝區一般來說不會太大,生產目前預設設定為64M,跨資料中心同步場景下,網路環境複雜,斷線的頻率和時長可能比同機房更頻繁和更長;同時,跨資料中心同步資料也是為了機房級故障容災,所以要求能夠支援更長時間的斷點續傳,無限增大記憶體複製緩衝區大小顯然不是一個好主意。
下面來看看我們支援redis跨資料中心同步的優化工作。
三、redis節點改造
為了支援異地多活場景,我們對原生redis程式碼進行了優化改造,主要包括以下幾個方面:
1、對RESP協定進行擴充套件
為了支援更高效的斷點續傳,以及為了解決資料迴環問題,我們在redis主節點中對每條需要同步給從節點的命令(大部分為寫命令)增加了id,並且擴充套件了RESP協定,在每條相關命令的頭部增加了形如#{id}\r\n形式的協定。
本地業務使用者端寫入的資料依然遵循原生RESP協定,主節點執行完命令後,同步到從節點的寫命令在同步前會進行協定擴充套件,增加頭部id協定;非本地業務使用者端(即來自其他資料中心同步)寫入的資料均使用擴充套件的RESP協定。
2、寫命令實時寫紀錄檔
為了支援更長時間的斷點續傳,容忍長時間的機房級故障,本地業務使用者端寫入的寫命令在進行協定擴充套件後,會順序寫入紀錄檔檔案,同時生成對應的索引檔案;為了減少紀錄檔檔案大小,以及提高通過紀錄檔檔案斷點續傳的效率,來自其他資料中心同步過來的資料不寫入紀錄檔檔案中。
3、同步流程改造
原生redis資料同步分為全量同步和部分同步,並且每個主節點有一個記憶體環形複製緩衝區;初次同步使用全量同步,斷點續傳時使用部分同步,即先嚐試從主節點環形複製緩衝區中進行同步,同步成功的話則同步完緩衝區中的資料後即可進行增量資料同步,如果不成功,則仍然需要先進行全量同步再增量同步。
由於全量同步需要生成一個子程序,並且在子程序中生成一個RDB檔案,所以對主節點效能影響比較大,我們應該儘量減少全量同步的次數。
為了減少全量同步的次數,我們對redis同步流程進行改造,當部分同步中無法使用環形複製緩衝區完成同步時,增加先嚐試使用紀錄檔rlog進行同步,如果同步成功,則同步完紀錄檔中資料後即可進行增量同步,否則需要先進行全量同步。
四、rLog紀錄檔設計
分為索引檔案與紀錄檔檔案,均採用順序寫的方式,提高效能,經測試與原生redis開啟aof持久化效能一致;但是rlog會定期刪除,原生redis為了防止aof檔案無限膨脹,會定期通過子程序執行aof檔案重寫,這個對主節點效能比較大,所以實質上rlog對redis的效能相對於aof會更小。
索引檔案和紀錄檔檔案檔名均為檔案中儲存的第一條命令的id。
索引檔案與紀錄檔檔案均先寫記憶體緩衝區,然後批次寫入作業系統緩衝區,並每秒定期重新整理作業系統緩衝區真正落入磁碟檔案中。相比較於aof檔案緩衝區,我們對rlog緩衝區進行了預分配優化,達到提升效能目的。
1、索引檔案格式
索引檔案格式如下所示,每條命令對應的索引資料包含三部分:
-
pos:該條命令第一個位元組在對應的紀錄檔檔案中相對於該紀錄檔檔案起始位置的偏移
-
len:該條命令的長度
-
offset:該條命令第一個位元組在主節點複製緩衝區中累積的偏移
2、紀錄檔檔案拆分
為了防止單個檔案無限膨脹,redis在寫檔案時會定期對檔案進行拆分,拆分依據兩個維度,分別是檔案大小和時間。
預設拆分閾值分別為,當紀錄檔檔案大小達到128M或者每隔一小時同時並且紀錄檔條目數大於10w時,寫新的紀錄檔檔案和索引檔案。
在每次迴圈處理中,當記憶體緩衝區的資料全部寫入檔案時,判斷是否滿足紀錄檔檔案拆分條件,如果滿足,加上一個紀錄檔檔案拆分標誌,下一次迴圈處理中,將記憶體緩衝區資料寫入檔案之前,先關閉當前的索引檔案和紀錄檔,同時新建索引檔案和紀錄檔檔案。
3、紀錄檔檔案刪除
為了防止紀錄檔檔案數量無限增長並且消耗磁碟儲存空間,以及由於未做紀錄檔重寫、通過過多的檔案進行斷點續傳效率低下、意義不大,所以redis定期對紀錄檔檔案和相應的索引檔案進行刪除。
預設紀錄檔檔案最多保留一天,redis定期刪除一天以前的紀錄檔檔案和索引檔案,也就是最多容忍一天時間的機房級故障,否則需要進行機房間資料全量同步。
在斷點續傳時,如果需要從紀錄檔檔案中同步資料,在同步開始前會臨時禁止紀錄檔檔案刪除邏輯,待同步完成後恢復正常,避免出現在同步的資料被刪除的情況。
五、redis資料同步
1、斷點續傳
如前所述,為了容忍更長時間的機房級故障,提高跨資料中心容災能力,提升機房間故障恢復效率,我們對redis同步流程進行改造,當部分同步中無法使用環形複製緩衝區完成同步時,增加先嚐試使用紀錄檔rlog進行同步,流程圖如下所示:
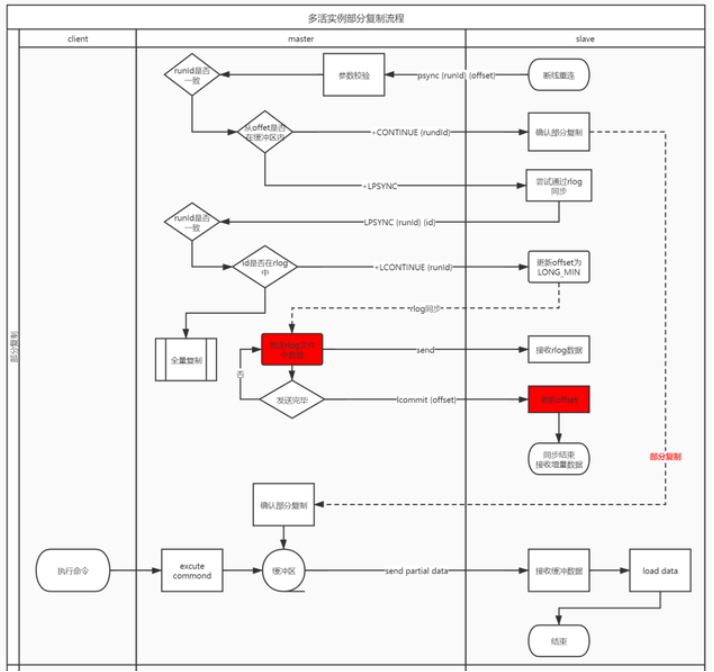
首先,同步工具連線上主節點後,除了傳送認證外,需要先通過replconf capa命令告知主節點具備通過rlog斷點續傳的能力。
-
從節點先傳送psync runId offset,如果是第一次啟動,則先傳送psync ? -1,主節點會返回一個runId和offset
-
如果能夠通過複製緩衝區同步,主節點給從節點返回 +CONTINUE runId
-
如果不能夠通過複製緩衝區同步,主節點給從節點返回 +LPSYNC
-
如果從節點收到+CONTINUE,則繼續接收增量資料即可,並繼續更新offset和命令id
-
如果從節點收到+LPSYNC,則從節點繼續給主節點傳送 LPSYNC runId id
-
主節點收到LPSYNC命令後,如果能夠通過rlog繼續同步資料,則給從節點傳送 +LCONTINUE runId;
-
從節點收到+LCONTINUE後,可以把offset設定為LONG_LONG_MIN,或者後續資料不更新offset;繼續接收通過rlog同步的增量資料即可;
-
通過rlog同步的增量資料傳輸完畢後,主節點會給從節點傳送 lcommit offset命令;
-
從節點在解析資料的過程中,收到lcommit命令時,更新本地offset,後續的增量資料繼續增加offset,同時lcommit命令無需同步到對端(通過id<0識別即可,所有id<0的命令均無需同步到對端)
-
如果不能,此時主節點給從節點返回 +FULLRESYNC runId offset;後續進行全量同步;
2、冪等性
遷移工具為了提高效能,並不是實時往zk儲存同步偏移offset和id,而是定期(預設每秒)向zk進行同步,所以當斷點續傳時,遷移工具從zk獲取斷線前同步的偏移,嘗試向主節點繼續同步資料,這中間可能會有部分資料重複傳送,所以為了保證資料一致性,需要保證命令多次執行具備冪等性。
為了保證redis命令具備冪等性,對redis中部分非冪等性命令進行了改造,具體設計改造的命令如下所示:

注:list型別命令暫未改造,不具備冪等性
3、資料迴環處理
資料迴環主要是指,當同步工具從A機房redis讀取的資料,通過MQ同步到B機房寫入後,B機房的同步工具又獲取到,再次同步到A機房,導致資料迴圈複製問題。
對於同步到從節點以及遷移工具的資料,會在頭部新增id欄位,針對不同來源的資料或者無需同步到遠端的資料通過id來標識區分;本地業務使用者端寫入的資料需要同步到遠端資料中心,分配id大於0;來源於其他資料中心的資料分配id小於0;一些僅用於主從心跳互動的命令資料分配id也小於0。
同步工具解析完資料後,過濾掉id小於0的命令,只需要向遠端寫入id大於0的資料,即本地業務使用者端寫入的資料。來源於其他資料中心的資料均不回寫到遠端資料中心。
4、過期與淘汰資料
目前過期與淘汰均由各資料中心redis節點分別獨立處理,由過期與淘汰刪除的資料不進行同步;即由過期與淘汰產生的刪除命令其id分配為小於0,並由同步工具過濾掉。
(1)同步產生的問題
為什麼不同步過去?因為在記憶體中hash表裡面儲存的資料沒有標記資料中心來源,過期與淘汰的資料有可能來自於其他資料中心,如果來自於其他資料中心的資料被過期或淘汰並且又同步到遠端其他資料中心,就會出現資料雙寫衝突的場景。雙寫衝突可能會導致資料不一致。
(2)不同步產生的問題
對於過期資料來說,不同步刪除可能會導致不同資料中心資料顯示不一致,但是一定會最終一致,且不會出現髒讀;
對於淘汰資料來說,目前的不同步刪除的方案,假如出現淘汰,會導致不同資料中心資料不一致;目前只有通過運維手段,比如充足預分配、及時關注記憶體使用率告警,來規避淘汰資料現象發生。
5、資料遷移
在redis叢集模式中,一般是在發生橫向擴容增加叢集主節點數時,需要進行槽以及資料的遷移。
redis叢集中資料遷移以槽為維度進行遷移,將槽中所有資料從源節點遷移到目標節點,然後將槽號標記為由新的目標節點負責,同時每遷移完一個Key,會在源節點中進行刪除,將migrate命令替換為del命令;同時遷移資料是在源節點中給目標節點傳送restore命令實現。
我們資料遷移的策略依然是,各個資料中心獨立的完成擴容與資料遷移工作,遷移過程產生的del和restore命令不進行跨資料中心同步;把替換後的del命令和傳送給目標節點的restore命令都分配小於0的id,於是同步過程中會由同步工具進行過濾掉。
六、redis效能
經測試,redis多活範例(預設開啟rlog紀錄檔),相對於原生redis範例(開啟aof持久化)效能基本一致;如下圖所示:
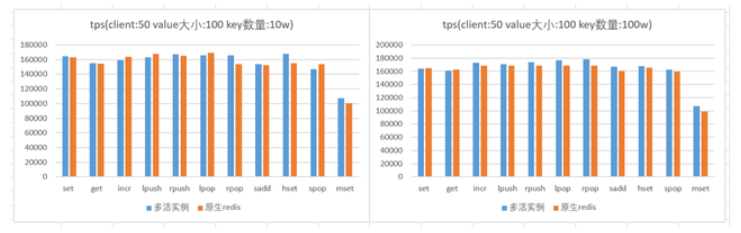
注:以上圖表使用redis benchmark進行壓測,壓測時,使用者端和伺服器端在同一個機器上
七、待優化項
1、多寫衝突
多個資料中心同時寫,key衝突問題暫未解決。
後續解決方案為使用CRDT協定;CRDT(Conflict-Free Replicated Data Type)是各種基礎資料結構最終一致演演算法的理論總結,能根據一定的規則自動合併,解決衝突,達到強最終一致的效果。
目前解決方案為業務對寫入不同機房的資料進行拆分,以保證不會出現衝突。
2、list型別冪等性
五種基本型別裡面,list型別大部分操作都是非冪等的,暫時未做冪等性改造優化。不建議使用或者業務自身保證使用list的資料操作冪等。
3、過期與淘汰資料一致性問題
正如前文所述,淘汰資料不進行跨資料中心同步會導致資料不一致,如果同步資料可能會出現同一個Key多寫衝突,也可能出現資料不一致情況。
目前解決方案為業務儘量合理提前預估所需記憶體容量、充足預分配、及時關注記憶體使用率告警,來規避淘汰資料現象發生。
作者:羅明