阿里雲基於邊緣雲業務場景的 「前端智慧化」 實踐
「前端智慧化」存在的價值和意義,被不斷拷問。
一部分人對「前端智慧化」持擁抱態度,認為這是前端領域的一種革命性技術。
另一部分人則認為「前端智慧化」可行性範圍有限,大多是一些Demo性產品,對能否真正應用到業務生產持懷疑態度。
其最終目的還是要將產品和技術能力融入業務體系,釋放技術紅利,驅動業務增長。
本文將結合阿里雲的業務場景,分析在中後臺領域中,「前端智慧化」如何降低開發成本,提升研發效能,從而創造更深遠的業務價值。
01 讓「前端智慧化」真的運轉起來
什麼是前端智慧化?
和垂直的「端智慧」方向不同,前端智慧化關注的領域更偏向於生產效率的提升。如果更準確的描述,「前端智慧化」應該是「前端開發智慧化」。
通過AI 與前端業務深入結合,基於AI能力提供的豐富預測、推薦資訊,結合研發邏輯積累,打造更加人性化、智慧化的前端程式碼。
當然,並不是機器能生成100%的程式碼去代替前端開發,出發點是讓機器能自動化、智慧化,為前端人員減少開發工作量,代替完成可抽象、可複用、UI編排、國際化等低成本、較為繁瑣的工作,最後產出一份可以二次開發、可維護、高質量的原始碼Procode。
每一套技術方案背後,必然有完整的理論體系和運作機制。
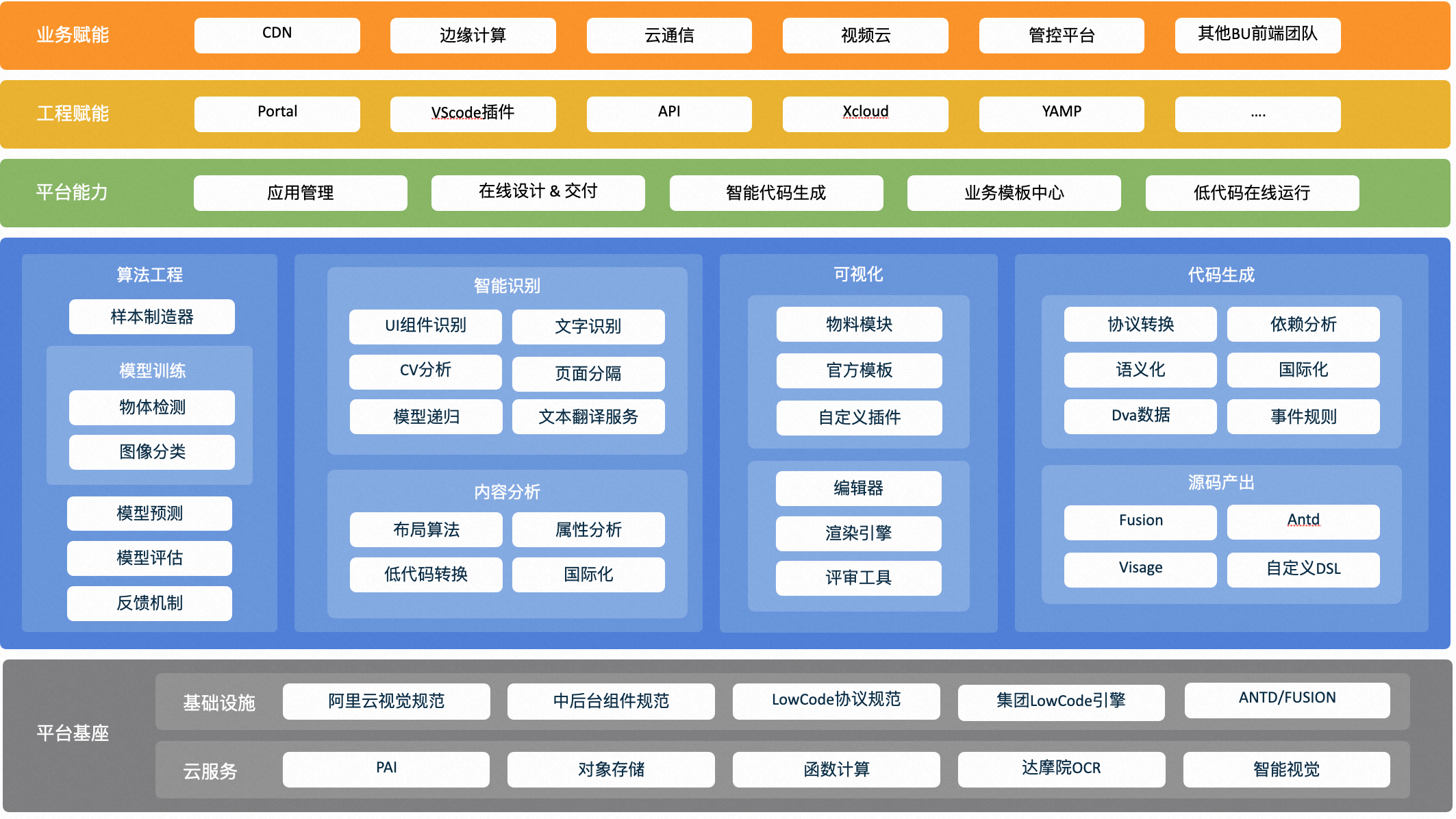
Dumbo平臺能力
阿里雲在怎樣的業務和技術背景下做邊緣雲 「前端智慧化」?
從業務增長上來講:由於雲端計算業務整合及調整,增加了大量的控制檯、中後臺管控等B端業務,在人力基本不變的情況下,團隊如何快速支撐起這部分業務?
從業務特性上來講:主要以ToB端、中後臺為主, 重管控crud、UI編排較統一、研發邏輯相似等,雲控制檯產品的國際化等特性。
前端業務側基於以上特性沉澱了前端技術框架,研發模式是基於元件化、場景化、模組化的方案。
通過這類研發方案,不僅能實現技術成本降低,元件化開發、最佳實踐地積累等,還能通過統一的視覺標準規範,減少視覺溝通成本和溝通成本, 從而大大提高開發效率。
雖然,基於這種方式的研發方案能帶來極大的提效,但在開發過程中也存在一些元件編排複雜、程式碼重複率高、大量無關核心業務邏輯開發的工作。
因此,我們思考如何基於現有研發方案,帶來進一步提效?
首先,明確前端的研發成本。主要包括:UI 元件編排、業務邏輯(互動與資料)、文案國際化、工程鏈路、溝通成本(設計、後端、產品)等。
其次,站在巨人的肩膀上看問題。團隊調研了一些現有的提效方案,主要包括:基於視覺化搭建平臺、基於視覺化物料原始碼開發站、基於AI能力的效能提升平臺等。
在此基礎上,結合自身業務場景、現有研發方案、開發模式、學習成本等綜合因素考慮,決定打造一個「智慧化」的面向阿里雲控制檯、中後臺原始碼開發平臺。
02 Dumbo的智慧化:「智慧識別」
Dumbo「智慧化」是一個利用影象識別演演算法,一鍵生成前端程式碼的智慧解決方案。目前已經落地於多個阿里雲控制檯及中後臺專案。
Dumbo的基本鏈路通過對標準化樣本進行生成,基於樣本來進行模型訓練。使用者只要輸入圖片,通過訓練的模型就能識別及最終產出前端所需程式碼。

智慧化的核心之一是「智慧識別」,主要包含:目標檢測演演算法、樣本生成、模型訓練及識別。
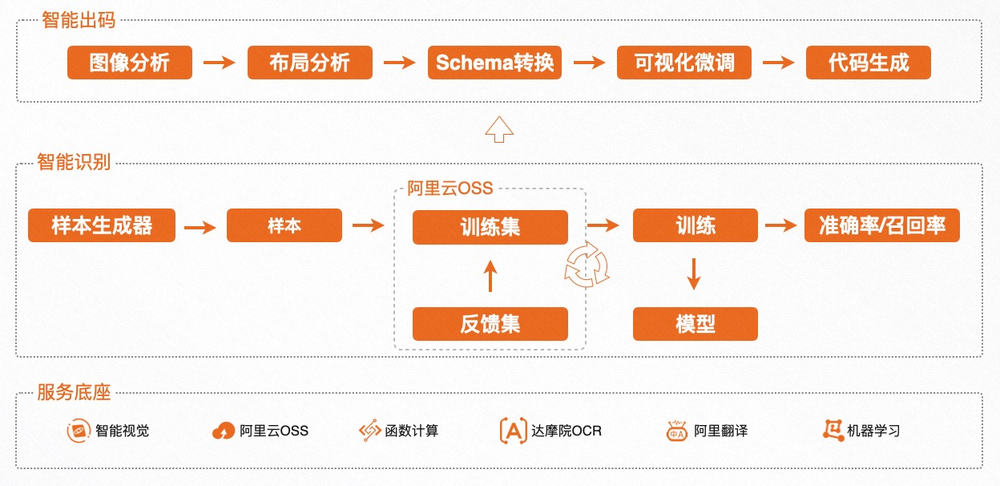
目標檢測演演算法
即輸入一張圖片,輸出圖片中感興趣物體的座標資訊。經典的目標檢測演演算法有兩種,one-stage與two-stage。one-stage演演算法即只對圖片處理一次,它的速度通常優於two-stage演演算法,代表演演算法有yolo系列。
而two-stage演演算法會對圖片處理兩次,先找到可能存在目標的區域,再對該區域做一次預測。這類演演算法速度較慢但準確率更好,代表演演算法有Faster R-CNN。
主要使用的目標檢測演演算法是SSD300。SSD300是2016年提出的一種目標檢測演演算法,它是一種one-stage演演算法,同時吸收了yolo和Faster R-CNN的優點,兼具速度和準確率。雖然在最新的目標檢測演演算法排名中,SSD已不再具有優勢。
「 在前端場景的目標檢測中,元件並沒有複雜的特徵形態,演演算法不是最重要的因素,樣本集和超引數的設定往往比演演算法本身更重要。」
SSD演演算法在準確率和速度上都較YOLO有較大提升,SSD演演算法在經過一次VGG-16轉換後,得到一個38 38 512的特徵圖,之後的每一次折積運算的同時都會輸出一次預測結果。
這麼做可以兼顧大目標和小目標的檢測,感受野小的feature map檢測小目標,感受野大的feature map檢測大目標。SSD同時引入了Faster RCNN中的Anchor,提出了相似的Prior box概念,在對樣本做標記時,也是基於Prior box的偏移來做的。
在每一個不同尺寸的feature map中,都預先設定好了多個Prior box,這些先驗框可通過人為規定或統計學方法計算得到。
在對目標做標記時,SSD要求找到與待檢測目標真實框交併比最大的先驗框,由它負責預測該目標,標記的資料為兩個框之間差值。預測的時候也是同理,因此,在SSD中,會多出一步轉換的過程,用來還原真實框的位置資訊。
Dumbo把該套目標檢測演演算法通過PAI深度學習訓練來訓練模型,並部署在PAI上的線上模型服務(ESA),通過函數計算來實現服務呼叫,實現了一套模型訓練服務。
樣本生成
目標檢測的模型訓練,樣本集尤為重要。對於現有場景而言,樣本集就是各種各樣的控制檯頁面截圖。
想要識別的元件,需要在圖片中標註出來,標註格式有多種,常見的格式有xml、json、csv等。根據SSD演演算法需要的標準細節,採用了xml格式對元件進行標註。以Button為例,標註資訊包括元件的左上角頂點座標、元件的長度和寬度。
不同的目標檢測演演算法需要的資料可能不同,有的需要元件中心點的座標資料,有的則需要元件佔圖片的比例資料。這些資料都可以通過計算相互轉換,本質並沒有發生變化。
將圖片中所有元件都標註完成後,得到了一對樣本圖片與標註檔案的集合,大量這樣的集合便構成了樣本集。
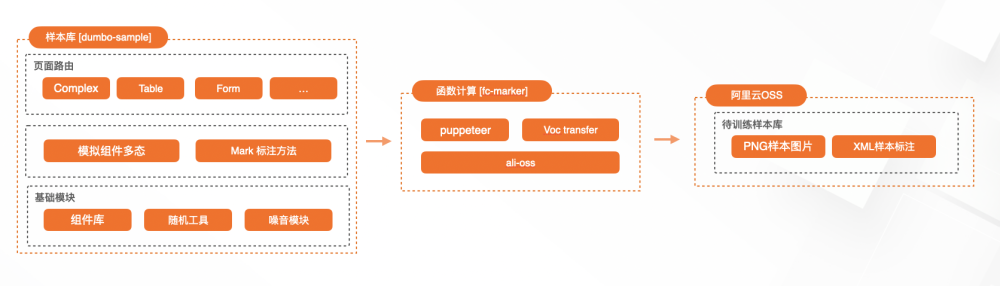
僅使用真實控制檯頁面截圖是遠遠不夠的,並且手動標註費時又容易出錯。對此分別使用了fusion構建了動態樣本資料集。fusion風格樣本主要以阿里雲控制檯標準為主,用於訓練阿里雲控制檯場景模型。
下圖是使用fusion構建的一個隨機控制檯頁面,目前,各型別的元件分佈演演算法採用的是圍繞視覺規範為均值的正態分佈,這麼做可以在少量樣本條件下訓練出表現更好的模型。後續將使用更加均勻的分佈演演算法改造樣本集,因為在前端領域的目標檢測中,並不適合完全均勻分佈的佈局演演算法。
舉個例子,PageHeader元件,位置資訊是其自身的一項特徵,如果在頁面底部出現了一個和PageHeader一模一樣的元件,也不應該將其標註為PageHeader。
元件內部屬性的隨機化,也要遵循一些約束,比如Select元件,邊框、右側的arrow-down Icon是其主要特徵,在使用程式碼生成時,最好不要忽略它們。圓角、邊框顏色等則不是主要特徵,可以儘量隨機化,讓訓練出的模型更具魯棒性。
一個值得思考的特徵是placeholder,「請選擇xxx」,這裡的「請選擇」實際上也是一項重要的特徵,思考一下,如果一個元件,除了右側沒有arrow-down圖示,其他特徵和Select元件一致,那麼,應該將其判斷為Select還是Input?
總結起來,訓練模型的過程,其實是讓模型挖掘到元件的完整特徵資訊,並根據各項特徵的重要程度做權重優化的過程。有了樣本圖片,還需要標註資訊。在Dumbo中,使用js方法獲取了每個元件的位置和長寬資料,在通過puppeteer截圖的過程中,自動匯出標註檔案。
基於以上說明,產出樣本生成服務如下:
模型訓練及識別
Dumbo提供了整套的模型訓練服務,可以方便的將已經生成好的樣本檔案進行模型訓練,這塊基於PAI的能力,把整個模型訓練鏈路整合到專案中,下圖為模型訓練的整體鏈路。
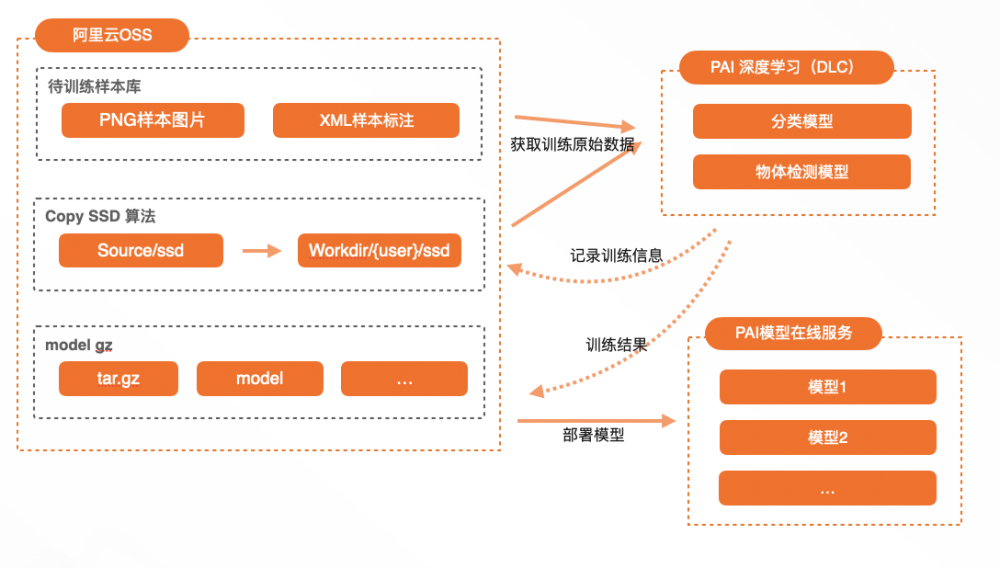
通過OSS作為中間集,進行資料和模型部署,實現了整體的模型訓練鏈路。
基於以上模型訓練鏈路,在Dumbo的fusion場景中訓練多種模型,包括整頁模型、表單模型、圖表模型、詳情頁模型、Icon模型等多個模型用於識別服務。
識別過程同時採用了遞迴識別和組合識別。這是為了提高小元件的識別準確率。同時將識別任務拆分到多個模型中,可降低各個模型的訓練難度。
03 「智慧出碼」:一鍵生成前端程式碼
通過上述的智慧識別,可以瞭解到Dumbo的全部訓練和識別過程,識別產物非前端程式碼,需要根據邊緣雲前端框架及阿里雲規範,對識別資料進行處理,最終生成前端同學可複用的佈局和邏輯程式碼程式碼,從而提高研發效率。
下圖是具體出碼實現步驟:
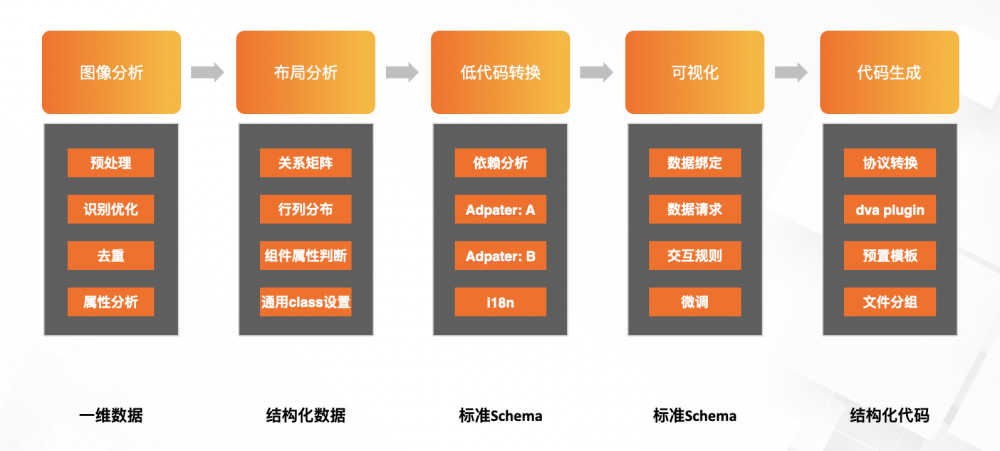
影象分析
「目標檢測 + 分類」看似能基本cover控制檯視覺稿的識別,然而理想很美好, 現實不夠理想。
在大量驗證過程中,發現僅通過模型預測的結果精確度偏低,一些情況下預測結果位置資訊存在一些偏差。同時為了模型收斂,也存在主體分類粒度不夠,導致無法更好的完成後續的還原工作。
為了提高識別的準確率及視覺還原度,所以採用深度學習結合傳統影象分析的方式,優化AI識別內容,豐富元件識別特徵度,提供給上游鏈路更豐富有效的資料資訊。
➢ 預處理:通過邊界判斷頁面padding情況,是否需要切割和補充padding來規範預測圖片內容、優化識別效果。
➢ 資料處理:在資料處理階段做一個初步的去重操作,該操作主要判斷:當兩個元件沒有父子關係且重疊閾值(交併比)大於某個值(這裡根據經驗取的 0.8), 刪除置信度較低的元件。本步驟主要為了解決AI對同一個物體識別為多個不同標籤的情況。
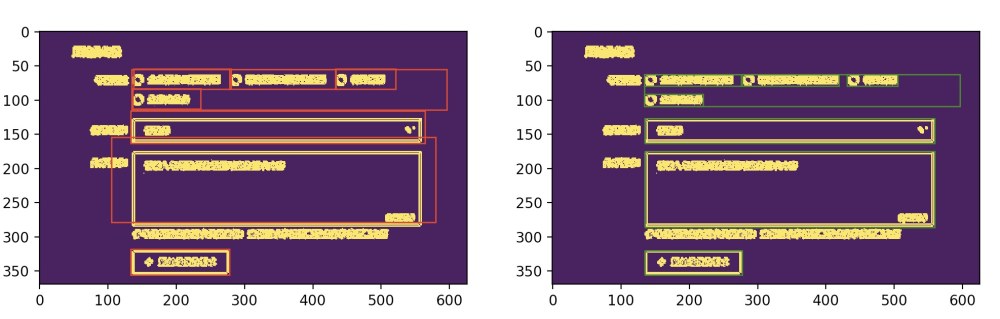
➢ 位置優化:主要通過OpenCV 進行影象分析輪廓識別,在比對輪廓的重疊閥指,收斂輪廓大小使輪廓區域和實際影象更加貼合。處理結果前後對比如下:
➢ 屬性檢測:主要通過OpenCV的顏色判斷,來區分元件的屬性型別,類似分析Message元件背景色,判斷Type值為Success、Error、 Notice、Warning等。通過簡單的CV分析,可以不斷豐富元件識別特徵度,不斷提升還原度。
➢ 關係矯正:對於有父子巢狀關係的元件,識別優化無法處理巢狀關係異常的情況,需要加入邏輯判斷。例如radioGroup/radio則為父子關係元件,當有父子關係巢狀不完整時,需要進一步處理判斷radio 的siblings 節點,並糾正父元件的位置,將其siblings 包裹完整。
佈局分析
視覺稿還原的主要目標是:佈局還原準確、減少冗餘重複程式碼,最大程度的貼合人工還原始碼,所以需要對影象分析處理後的資料進行資料分析,增加部分節點資料,方便後續DSL轉換和出碼。
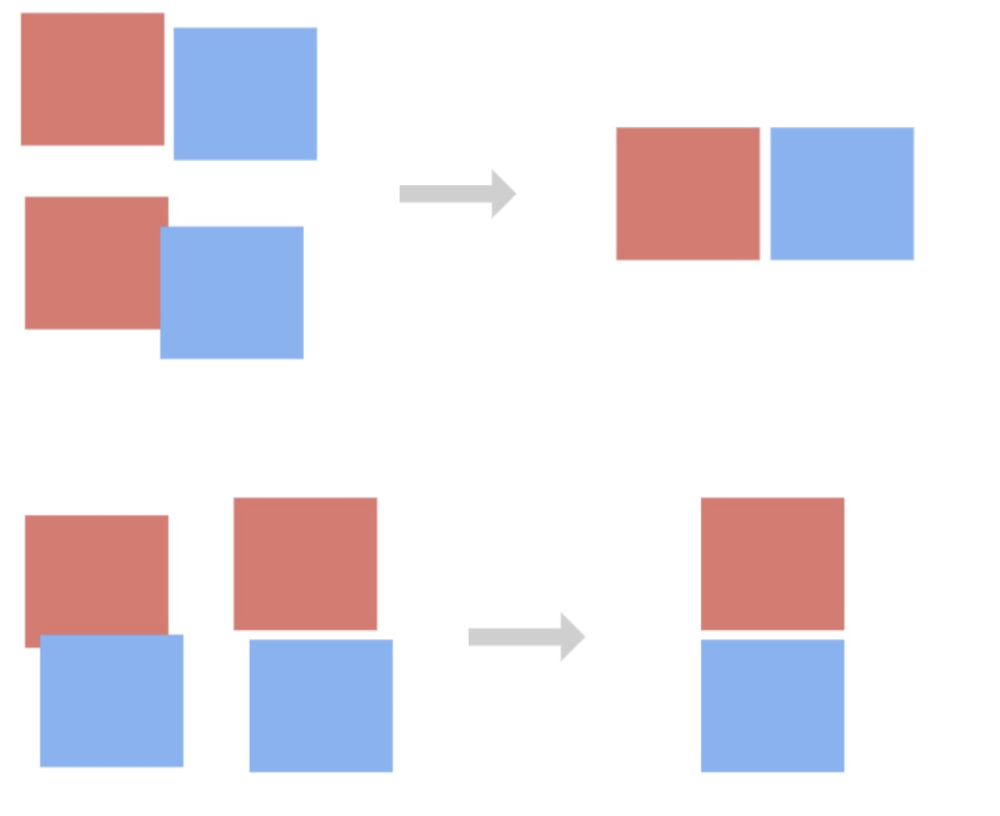
➢ 關係矩陣:分析其位置資訊(x, y, width, height),將其生成一個N維關係矩陣。判斷關係矩陣時,對行列位置進行了的閾值設定,規定在水平垂直等方向xOverlap、yOverlap 重疊閾值小於某個值可忽略重疊部分。具體示意圖如下:
➢ 行列生成:主要目的是將關係矩陣結構轉換成節點樹,同時使用柵格化的方式處理行列結構佈局。用Row節點表示一行, Col節點表示一列,遞迴呼叫transfer2Grid 方法,生成節點樹。注意:此過程需要考慮到基於元件化佈局方式特點。從而定義componentsInline 陣列,包括'Button', 'Radio', 'Checkbox' 等。
➢ 元件設定:在此步驟中,以外掛化的方式判斷不同的類庫包括Fusion樣式屬性,轉換樣式,設定元件屬性及通用樣式類。維護一個config 屬性名稱對映,對節點進行樣式相關屬性檢測及設定,同時根據位置資訊判斷一些浮動、邊距樣式等,設定通用className。這種方式有利於佈局還原始碼可讀性,可維護性。
DSL轉換
智慧識別的資料是一份平面化資料,需要還原為立體、有結構的DSL資料。轉換DSL主要通過識別文字的預處理工作,依賴分析、和各個元件的Adapter組成,最終產出一份結構化的schema資料。
預處理:Dumbo的文字識別之後產生的是一個Text節點資料,包含中英文屬性,但是文案中可能會存在一些影響最終展示的特殊符號,比如●、丫等,這些符號的誤識別會導致最終展示上出現不理想的情況,也有可能會出現長文字被截斷成為多個文位元組點的情況,需要把這些文位元組點進行合併處理等。然後對生成的元件進行國際化處理。
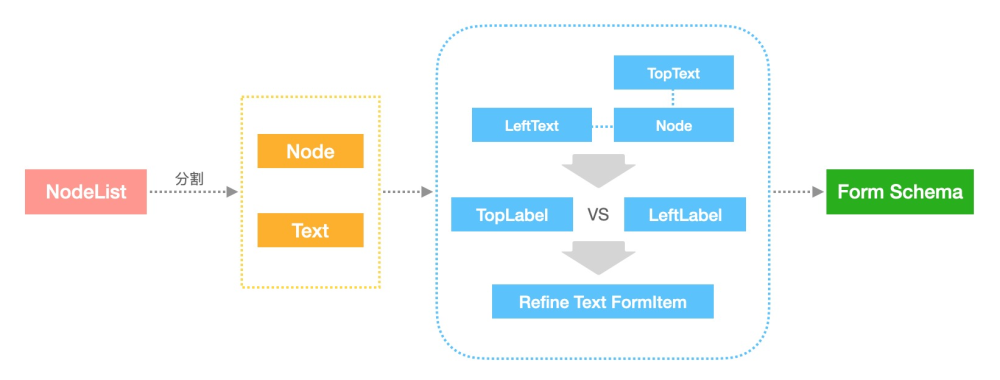
Adapter(以Form元件為例子)
首先,進行節點分割,分割為文位元組點和元件節點;
其次,根據Form特性,一般以元件作為FormItem的children,Text作為label屬性,優先進行元件節點判斷,通過遍歷元件節點,並通過相鄰節點函數判斷,獲取到該節點的相鄰的Text, 並根據互動稿規範的相鄰閥值,進行label判斷,由於不確定FormItem的佈局情況,可能存在上下/左右2種佈局形式,所以會同時判斷TopText和LeftText,並分別放入對應的陣列中,之後進行比較。
根據Form表單的特性,一般Form的排列形式比較一致,不是上下/左右,很少存在既有上下,又有左右的形式,所以這塊直接判斷TopText和LeftText的個數來進行佈局確認。
在瞭解佈局之後,可以再次遍歷沒有被命中的文位元組點和元件節點,因為已經確定佈局型別,所以可以直接根據閥值,來判斷是否存在只有文字的FormItem元件,進一步完善元件內容及屬性,並且可以把一部分識別不是很準確的RadioGroup等進行合併處理。
最後,進行元件的FormItem組裝,輸出給一個完成的結構化資料。
依賴分析:識別資料通過Adapter轉換之後,獲取到的Schema並不包含依賴關係,和集團的規範存在出入,依賴提取的後處理部分,就是通過對Schema的遍歷,提取使用到的元件資訊,通過對應的模版依賴庫,載入對應的依賴關係。
在視覺化微調上,基於集團的Low-Code引擎,建立了一套Fusion物料元件,支援識別資料的視覺化微調,進一步提升出碼準確率。
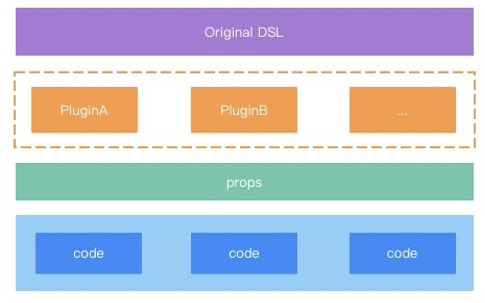
程式碼生成
對於程式碼生成,則主要圍繞著集團最新的搭建協定,通過場景的一系列編排,最終完成一個元件的生成。其結構大體可描述為:
在出碼處主要處理的內容,是將機器遞迴遍歷給出的字串,重進編排整合,使其具有維護的能力。主要解決的問題為:程式碼拆分/整合、狀態管理、國際化、樣式。
首先,對於程式碼的拆分和整合。目前主要根據 DSL 中的節點型別進行拆分。對於 BLOCK 、 Component 節點,直接劃分為通用的場景,以供其他頁面或者模組使用。
其次,是狀態管理。目前開發中,dva 已經成為團隊統一的狀態管理工具,在遍歷過程中會對頁面的 state 、 effects 進行提取,通過對映,完成組裝。
然後,是國際化相關的內容。在集團的搭建協定中,可以看到最新版本的國際化內容已經被替換成如下形式。

整合後的 DSL 中 i18n 的內容會被單獨提取出來,對於呼叫處是一個表示式。而目前團隊的國際化方案更多的是自有風格,所以在處理國際化節點時需要做響應的替換。
最後,是樣式相關。通過之前的佈局分析,通過一系列的計算,最終每個元件節點都被賦予了柵格化的 ClassName 。所以此處只要把佈局所需要的基礎css 檔案作為依賴引入到頁面檔案中即可。
目前來說,「前端智慧化」 Dumbo平臺已接入眾多公有云控制檯應用 ,其中新控制檯接入頁面覆蓋率大於50%,研發效率感官提效約30%,在整體識別率、準確率上滿足了業務的基本要求,而在場景覆蓋、智慧化程度、智慧互動等方面,也在探索更多的提升空間。
後續,計劃進一步收斂場景規範、擴大使用場景覆蓋面的同時,不斷豐富資料模型能力,從靈活性、識別特徵度、模型準確率等多維度考慮,提高「智慧化」能力。同時,繼續讓「智慧化」和「低程式碼」進行結合,讓使用者可以通過簡單的介面設定,實現頁面線上執行。
未來的智慧化不止於程式碼,還在向端雲協同方向做更多滲透。
「視訊雲技術」你最值得關注的音視訊技術公眾號,每週推播來自阿里雲一線的實踐技術文章,在這裡與音視訊領域一流工程師交流切磋。公眾號後臺回覆【技術】可加入阿里雲視訊雲產品技術交流群,和業內大咖一起探討音視訊技術,獲取更多行業最新資訊。