謠言檢測——(PSA)《Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks》
論文資訊
論文標題:Probing Spurious Correlations in Popular Event-Based Rumor Detection Benchmarks
論文作者:Jiaying Wu、Bryan Hooi
論文來源:2022, arXiv
論文地址:download
論文程式碼:download
Abstract
開源的資料集存在虛假相關性,這種虛假相關性來自三個方面:
-
- event-based data collection and labeling schemes assign the same veracity label to multiple highly similar posts from the same underlying event;
- merging multiple data sources spuriously relates source identities to veracity labels;
- labeling bias;
在 event-separated 的設定下,現有最先進的模型準確性下降了 40% 以上,和簡單的線性分類器差不多。本文為解決這個問題,提出了 Publisher Style Aggregation(PSA),是一種通用的方法,可以聚合釋出者的釋出資訊,以及寫作風格和立場等。
1 Introduction
現有資料集的構建過程中存在虛假的 屬性-標籤相關性。回顧基於事件的資料集採集框架,首先對事實有價值的事件自動檢測,然後剔除大量包含相同事件關鍵詞高度相似的微博。此外,一些基準資料集還通過合併現有多個源的資料樣本,來平衡類分佈。
忽略虛假資訊會導致不公平的過度預測,從而限制了模型的泛化和適應性。在情緒分類、引數推理理解 和 事實驗證 等一些自然語言處理任務中也發現了類似的問題,但社交媒體謠言檢測的任務仍未得到充分的探索。
2 Spurious Correlations in Event-Based Datasets
2.1 Event-Based Data Collection
Newsworthy Event Selection
從具有權威的事實核查網路收集事件,或由專業人士確定候選事件。
Keyword-Based Microblog Retrieval
現有的資料集通常是基於事件的自動資料收集策略,即對每個事件:
- 從其 claim 中提取關鍵詞;
- 通過基於關鍵詞的搜尋獲取微博;
- 選擇有影響力的微博;
事件關鍵字大多是中立的(例如,地點、人或物件),攜帶很少或沒有立場。
Microblog Labeling Scheme
Event-level labeling assigns all source posts under an event with the same event-level factchecking label.
Post-level labeling annotates every source post independently.
2.2 Possible Causes of Spurious Correlations
在每個 Event 下,基於自動關鍵字的微博檢索框架收集了大量具有相同標籤的高度相似的關鍵詞共用樣本,甚至獲得了相同的微博文字(Fig.1)。因此,事件關鍵字和類標籤之間的相關性導致強文字線索,難以概括當前 Event 。

根據現有工程所採用的 post-level data splitting scheme,也就是使用關鍵詞相關性對貼文進行收集。
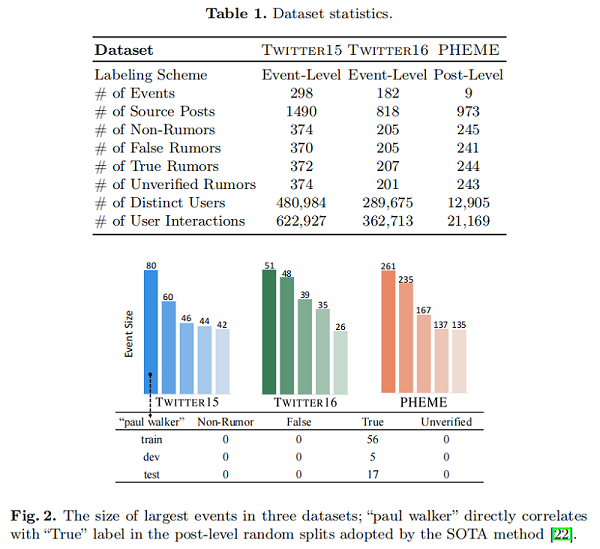
具體來說,前 5 個最大的事件覆蓋了 PHEME 中 96.09% 的資料樣本,而大型事件(包含超過5個關鍵詞共用推文)覆蓋了 Twitter 15 和 Twitter16 中超過70% 的樣本。大的事件規模導致特定事件的 keyword-label 相關性的流行,進一步加劇了問題。
為了平衡標籤,Twitter 15 和 Twitter16 合併了來自包括[4,12,16] 在內的多個來源的推文,並從經過驗證的媒體賬戶中提取其他新聞事件。雖然不同的資料來源所覆蓋的事件不重疊,但資料來源和標籤之間的直接相關性可能會導致資料來源特徵和標籤之間的虛假相關性。
如 Fig 3 所示,來自每個源的推文的 user interaction count(評論和轉發)和 interaction time range of tweets 形成了不同的模式。例如,所有來自 PLOS_ONE 的推文都是「True」,傳播得很快,往往會引起更少的互動。這些特定於源的傳播模式可能被基於圖或時間的模型所利用。

Labeling Bias
由於文字內容相似,簡單的為其自動設定相同標籤,會帶來嚴重的標籤偏差,舉例如 Fig.4 所示:

3 Event-Separated Rumor Detection
3.1 Problem Formulation

現有的方法大多忽略了底層的 microblog-event 關係,採用了 event-mixed post-level data splits ,導致 $\mathcal{E}_{t r}$ 和 $\mathcal{E}_{t e}$ 之間存在顯著的重疊。然而,在實踐中,測試資料的先驗知識並不總是得到保證(例如,模型從訓練和測試資料中重複推文獲得的效能收益不太可能推廣),而以前的假設可能導致事件內文字相似性導致的效能高估。
為了消除這些混雜的事件特異性相關性,本文建議研究一個更實際的問題,即 event-separated rumor detection,其中 $\mathcal{E}_{t r} \cap \mathcal{E}_{t e}=\varnothing$。由於潛在的事件分佈轉移,這項任務具有挑戰性,因此它提供了一種評估去偏謠言檢測效能的方法。
3.2 Existing Approaches
Propagation-Based
(1) TD-RvNN
(2) GLAN
(3) BiGCN
(4) SMAN
Content-Based
(1) BERT
(2) XLNet
(3) RoBERTa
(4) DistilBERT
Data Splitting
對於所有三個資料集,我們抽取 10% 的範例進行驗證,然後將剩下的 3:1 分成訓練集和測試集。具體來說,分別根據 Twitter15、Twitter16、PHEME 上釋出的公開事件 id 獲得了事件分離分割。
3.3 SOTA Models’Performance is Heavily Overestimated
Fig.5 顯示了事件混合和事件分離的謠言檢測效能之間的鮮明對比。此外,儘管在所有三個資料集上具有最佳事件分離效能的一致性,但所有模型在 Twitter 15 和 Twitter16 上實現的事件混合效能都顯著高於 PHEME,前者採用事件級標記,後者採用後級標記(見第1.1節)。這一差距與我們的假設相一致,即直接的 event-label 相關性會導致額外的偏差。
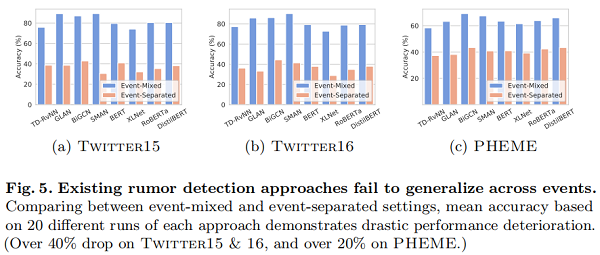
結果表明,現有的方法嚴重依賴於虛假的事件特異性相關性。儘管在事件混合設定下表現良好,但這些模型不能推廣到看不見的事件,導致現實世界的適應性較差。
4 Proposed Method
為了解決事件分離謠言檢測的挑戰,我們提出了 Publisher Style Aggregation(PSA),這是一種新的方法,可以根據每個出版商的聚合貼文來學習可推廣的 publisher 特徵,如 Fig.6 所示。

4.1 Consistency of Publisher Style
源貼文釋出者是非常有影響力的使用者。每個釋出者獨特的可信度立場和寫作風格可以表現出獨特的特徵,這有助於決定他們的貼文的真實性。為了獲得更直觀的觀點,我們在 Fig.7 中說明了Twitter15 釋出者對每個類的傾向。
具體來說,對於釋出者 $u$,我們定義了 $u$ 在class $c$ 下的 tendency score :
$\frac{ \text{ (microblogs posted by u under class c)}}{\text{(microblogs posted by u)}} $
Fig.7 顯示,大多數釋出者在一個特定類別上的得分要麼接近 $0$,要麼接近 $1$,即,大多數釋出者傾向於在一個單一的真實性標籤下發布微博,這驗證了我們關於釋出者風格一致性的假設。
4.2 Content-Based Microblog Encoding
在每個資料集中,所有的源文章和評論構成了一個大小為 |V| 的詞彙表。在之後,我們將每個源特徵特徵 $\mathbf{r}_{i} \in \mathbb{R}^{|V|}$ 及其相關評論特徵 $\mathbf{r}_{i}^{j} \in \mathbb{R}^{|V|}$ 表示為相應源特徵或評論中所有 one-hot word vectors 的和。
RootText: Source post 是經過事實核查的,所以可以直接使用Souce Post 作為每個微博範例 $T_{i}$ 的表示—— $\mathbf{h}_{i}:=\mathbf{r}_{i}$
MeanText:我們還建議考慮使用者的評論,以更穩健的可信度測量。在這裡,我們採用均值池法將源貼文和評論特徵壓縮為微博表示:
$\mathbf{h}_{i}:=\frac{\mathbf{r}_{i}+\sum\limits _{j=1}^{k} \mathbf{r}_{i}^{j}}{k+1}$
我們獲得了基於 RootText 或Meant的微博 $T_{i}$ 編碼 $\mathbf{h}_{i} \in \mathbb{R}^{|V|}$,並通過具有 ReLU 啟用函數的兩層全連線神經網路提取高階特徵 $\tilde{\mathbf{h}}_{i} \in \mathbb{R}^{n}$。然後,我們通過將 $\tilde{\mathbf{h}}_{i}$ 通過輸出維數 $|\mathcal{C}|$ 的最終全連線層,防止過擬合進行精度預測。
4.3 Publisher Style Aggregation
如 4.1 節所示,在極具影響力的 source post 中,寫作立場和可信度在固定的時間框架內保持相對穩定。受此啟發,我們進一步提出了Publisher Style Aggregation(PSA),這是一種可推廣的方法,它聯合利用每個釋出者產生的多個微博範例,並提取獨特的釋出者特徵,以增強在每個微博中學習到的本地特徵。更具體地說,
(1) 查詢每個釋出者生成的一組微博範例;
(2) 通過聚合這些源貼文的文字特徵學習釋出者的釋出者風格表示 ;
(3) 增強每個微博的表示$\tilde{\mathbf{h}}_{i}$;
Publisher Style Modeling
假設釋出者 $u_{i}$ 已經產生了 $m_{i} \geq 1$ 微博範例,相應的源貼文表示為 $\mathcal{P}\left(u_{i}\right)= \left\{p_{k} \mid u_{k}=u_{i}, k=1, \ldots, N\right\}$ ;注意,在訓練期間只使用可存取的資料。我們將第 $j$ 個 貼文 $p_{i}^{j} \in \mathcal{P}\left(u_{i}\right)$ 視為一個最大長度為 $L$ 的詞標記序列。然後,我們構造了一個基於可訓練的 $d$ 維詞嵌入的嵌入矩陣 $\mathbf{W}_{i}^{j} \in \mathbb{R}^{L \times d}$。我們聚合 $u_{i}$ 的所有後嵌入矩陣 $\mathbf{H}_{i} \in \mathbb{R}^{L \times d}$,得到相應的 publisher matrix $\mathbf{H}_{i} \in \mathbb{R}^{L \times d}$ 如下:
$\mathbf{H}_{i}=\operatorname{AGGR}\left(\left\{\mathbf{W}_{i}^{j}\right\}_{j=1}^{m_{i}}\right),$
其中,AGGR 運運算元可以是 MEAN 或 SUM。
為了捕獲 high-level publisher 的特徵,我們對每個 $\mathbf{H}_{i}$ 應用折積來提取潛在的釋出者風格的特徵。具體來說,我們使用三個具有不同視窗大小的折積層來學習具有不同粒度的特徵。每一層由F濾波器組成,每個過濾器輸出一個特徵對映 $\mathbf{f}_{*}=\left[f_{*}^{1}, f_{*}^{2}, \ldots, f_{*}^{L-k+1}\right]$,與
$f_{*}^{j}=\operatorname{ReLU}\left(\mathbf{W}_{f} \cdot \mathbf{H}_{i}[j: j+k-1]+b\right)$
其中 $\mathbf{W}_{f} \in \mathbb{R}^{k \times d}$ 為折積核,$k$ 為視窗大小,$b \in \mathbb{R}$ 為偏差項。我們執行最大池化來提取每個 $\mathbf{f}_{*}$ 的最顯著值,並將這些值堆疊以形成一個樣式特徵向量的 $\mathbf{s} \in \mathbb{R}^{F}$。然後,我們將三個 CNN 層產生的 $\mathbf{S}_{*}$ 連線起來,獲得 $\tilde{\mathbf{s}}_{i} \in \mathbb{R}^{3 F}$:
$\tilde{\mathbf{s}}_{i}=\text { Concat }\left[\mathbf{s}_{1} ; \mathbf{s}_{2} ; \mathbf{s}_{3}\right] $
我們用相應的釋出者風格表示 $\tilde{\mathbf{s}}_{i}$ 來增加微博表示 $\tilde{\mathbf{h}}_{i} \in \mathbb{R}^{n}$。最後,我們利用一個全連線層來預測微博的準確性標籤 $\hat{\mathbf{y}}_{i}$:
$\hat{\mathbf{y}}_{i}=\operatorname{Softmax}\left(\mathbf{W}_{2}^{\top}\left(\tilde{\mathbf{h}}_{i}+\mathbf{W}_{1}^{\top} \tilde{\mathbf{s}}_{i}\right)\right)$
其中,轉換 $\mathbf{W}_{1} \in \mathbb{R}^{3 F \times n}$ 和 $\mathbf{W}_{2} \in \mathbb{R}^{n \times|\mathcal{C}|}$。我們還在最後一層之前應用 dropout,以防止過擬合。通過最小化 $\hat{\mathbf{y}}_{i}$ 和真實標籤 $y_{i}$ 之間的交叉熵損失來優化模型引數
5 Experiments
Model Performance
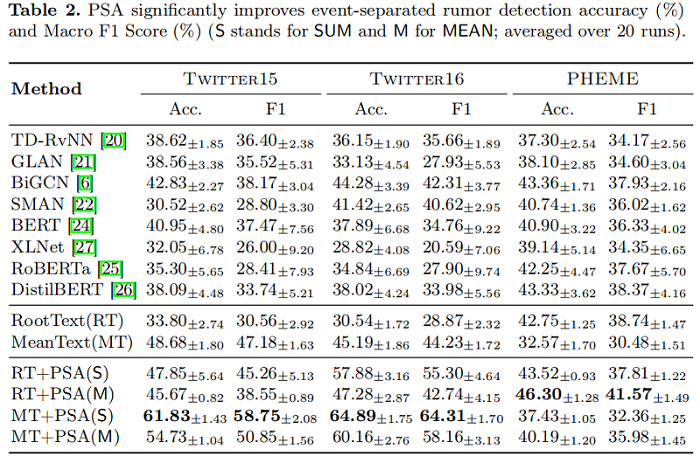
我們觀察到,MeanText 在 Twitter15 和 Twitter16 上優於現有方法,而 RootText 的準確率僅比 PHEME 上的最佳基線低 0.6%。由於 PHEME 對每個微博獨立貼標籤,源貼文將包含最獨特的特徵。
我們提出的PSA方法,將 AGGR 實現為 SUM 或 MEAN,顯著增強了 RootText 和 MEAN 基分類器。最佳的 PSA 組合比最佳基線表現更好;它們在 Twitter15 上的事件分離謠言檢測準確率提高了19.00%,在 Twitter 16 上提高了 20.61%,在 PHEME 上提高了 2.94%。與現有的方法不同,PSA 顯式地從多個事件中聚合了釋出者風格的特性,從而增強了模型學習事件不變特徵的能力。因此,PSA能夠捕捉到與獨特的出版商特徵相關的立場和風格,從而導致實質性的效能改進。
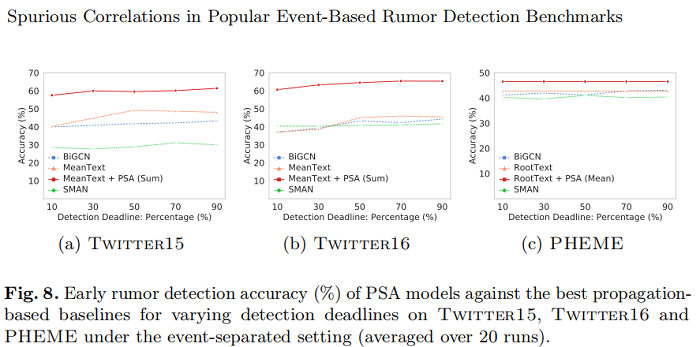
即使只有最早的 10% 的評論,PSA 在 Twitter15 上達到 57.53%,在 Twitter 16 上達到60.65%,在 PHEME 上達到46.30%。請注意,RootText(+PSA)模型在所有截止日期內都保持了穩定的效能,因為它們僅基於源貼文提供即時預測。結果表明,用 publisher style representations 的表示來增強謠言檢測模型,達到了效率和有效性。
為了研究 PSA 的泛化能力,在 Twitter15 和 Wwitter16 上進行了跨資料集實驗,其中模型在一個資料集上進行訓練,在另一個資料集上進行測試。為了進行公平的比較,我們使用了相同的事件分離資料分割。如果來自資料集 $A$ 的訓練集和來自資料集 $B$ 的測試集之間存在重疊事件,我們將刪除訓練集中與這些事件相關的所有範例,並將它們替換為從 $A$ 的測試集中隨機抽樣的相同數量的非重疊範例。
跨資料集設定本質上更具挑戰性,因為訓練和測試事件源於不同的時間框架,這可以產生時間概念的轉移。然而,表3顯示,PSA 在 Twitter15上的基礎分類器,在Twitter16上分別提高了12.82%,這進一步證明了PSA對未知事件的通用性。

6 Conclusion
在本文中,我們系統地分析了基於事件的資料收集方案如何在社交媒體謠言檢測基準資料集中建立特定於事件和源的虛假相關性。我們研究了事件分離謠言檢測去除事件特定相關性的任務,並通過實證證明了現有方法的泛化能力的嚴重侷限性。為了更好地解決這一任務,我們建議PSA使用聚合的釋出者風格的特性來增強微博表示。在三個真實資料集上進行的廣泛實驗表明,在交叉事件、跨資料集和早期謠言檢測方面有了實質性的改進。因上求緣,果上努力~~~~ 作者:關注我更新論文解讀,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/16732443.html