深入剖析堆原理與堆排序
堆的介紹
- 完全二元樹:完全二元樹是滿二元樹去除最後N個節點之後得到的樹(\(N \geq0, N \in N^*\))
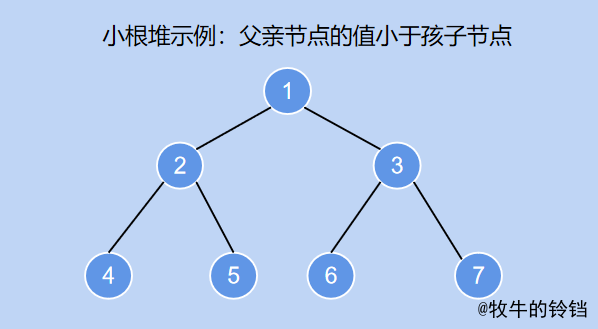
- 大根堆:節點的父親節點比自身節點大,比如根節點的值為\(8\),比其子節點 \(7\), \(6\)大,其餘的類似。
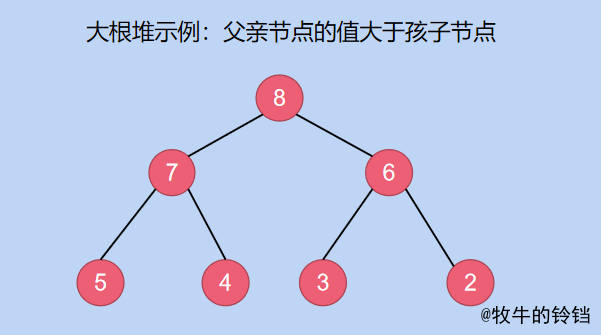
- 小根堆:節點的父親節點比自身節點小,比如根節點的值為\(1\),比其子節點\(2\), \(3\)的值要小,其餘的也類似。
堆的實現
如何儲存一個堆
堆的儲存是使用陣列實現的,下標從0開始從左至右從上到下,依次遞增,例如上述的小根堆儲存在陣列中就是
[1, 2, 3, 4, 5, 6, 7]
對應的下標為 \(0, 1, 2, 3, 4, 5, 6\)
如何將一個陣列變成一個堆
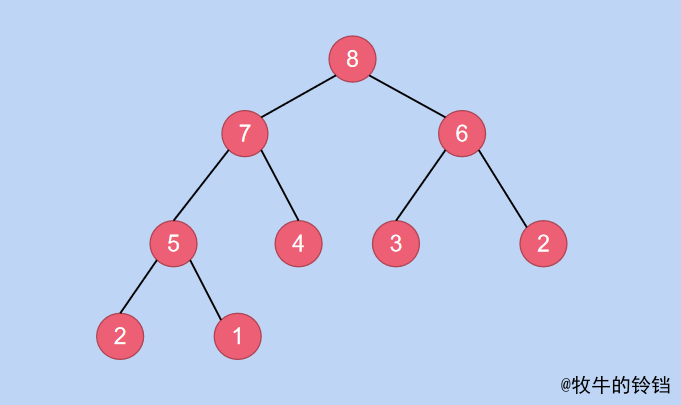
從最後一個有孩子節點 (節點下標為\(M\))的元素開始,先將以該元素為根節點的子樹變成一個堆,然後下標減 \(1\),再將下標為\(M - 1\)的節點所對應的子樹變成堆,依次遞減進行,直到根節點。範例如下(以小根堆為例):
-
找到第一個有孩子節點的,由上圖容易知道,第一個有孩子節點的值為\(5\),其下標為\(3\),它對應的子樹為:
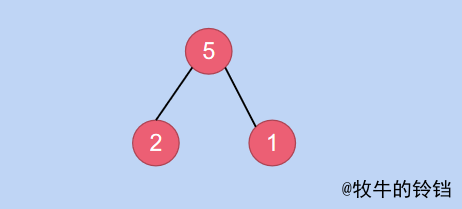
如果需要將上面的子樹變成一顆小根堆,只需要將\(5\)和\(1\)對應節點互換位置即可(不能和\(2\)換,如果和\(2\)換 \(2>1\)不符合小根堆的性質),換完之後的結果為:
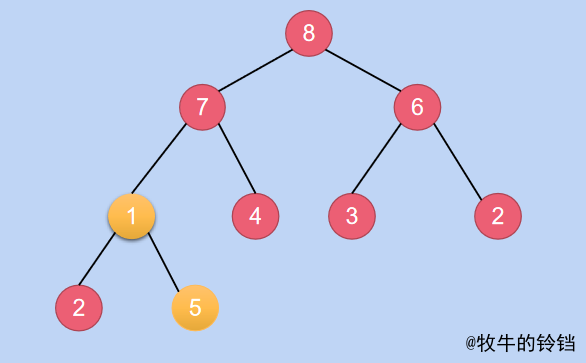
-
然後將下標減\(1\),即為\(2\),對應的元素為\(6\),現在也需要將其對應的子樹變成一顆小根堆,即需要將\(6\)和\(2\)互換,互換之後的結果為:
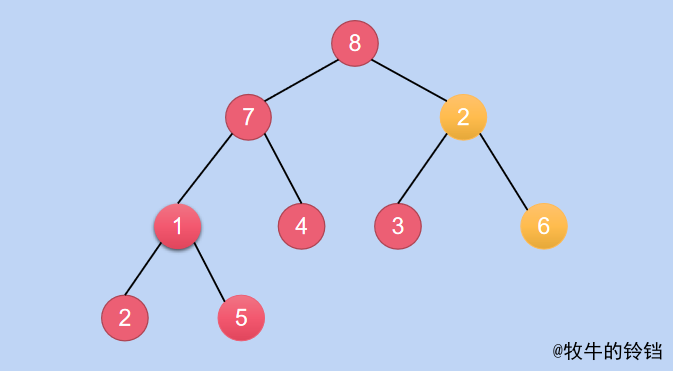
-
繼續將下標減\(1\),然後進行相同的操作,很容易知道將\(7\)和\(1\)互換位置,互換之後的結果為:
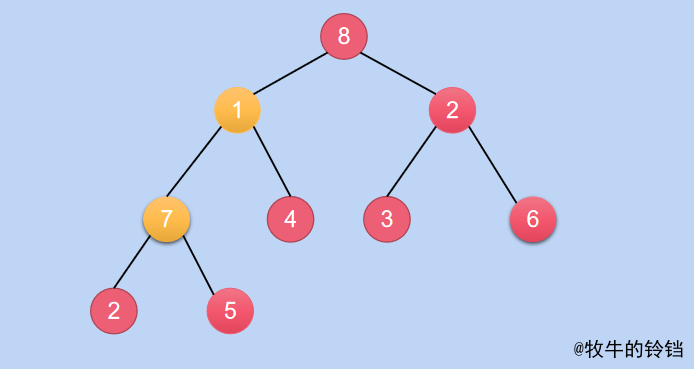
從上面的圖可以知道,當\(1\)和\(7\)互換之後,子樹\([7, 2, 5]\)不是一顆小根堆了,那怎麼辦?再將子樹\([7, 2, 5]\)變成小根堆即可,所以再進行一次小根堆操作即可,將\(7\), \(2\)進行互換即可,交換之後的結果為:
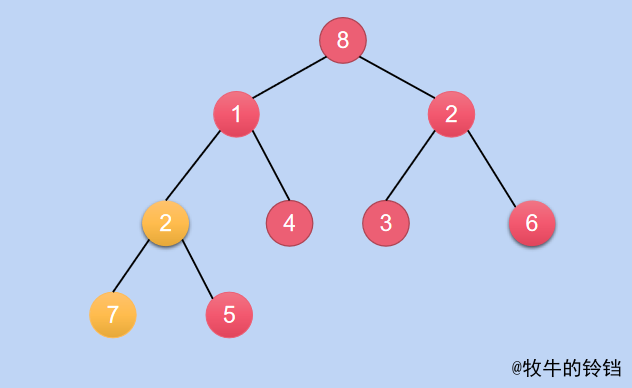
在上述的樹中,交換過程已經完成了,但是如果節點的數目非常大,或者說下面的子樹可能又出現了不符合小根堆的情況怎麼辦?那就一直迴圈走下去,直到沒有孩子節點或者已經滿足小根堆的性質。我們將上述操作定義為下沉(down)操作
-
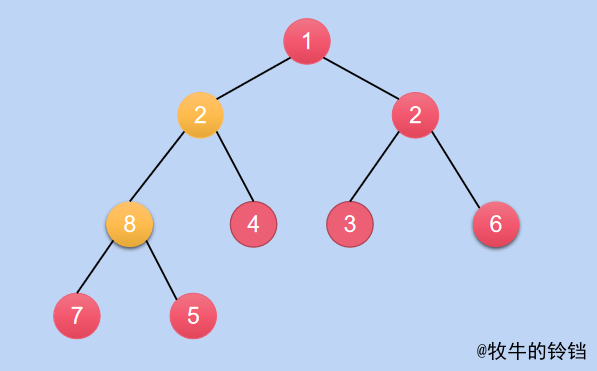
最後再對節點\(8\)進行相關操作,得到的結果如下:

-
再對子樹進行堆化\((heapify)\)操作:
-
在進行堆化,得到最終結果
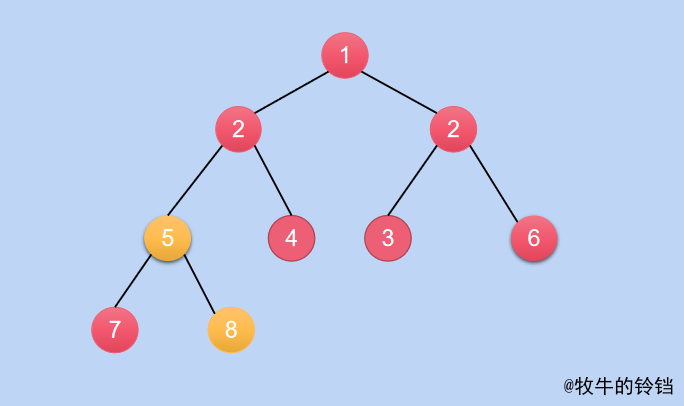
以上就是將一個完全二元樹變成一顆小根堆的過程,大根堆的過程非常類似,即將較大的數作為父親節點即可,就不在進行陳述~~~
程式碼實現
首先我們清楚堆的儲存資料結構是陣列,那麼就有對應的下標,那麼父親節點和孩子節點的位置對應關係是什麼呢?
如果父親節點的下標為\(i\)那麼它對應的做孩子的下標為\(2*i+1\)對應右孩子的下標為\(2*i+2\),如果孩子節點的下標為\(i\),則對應的父親節點的下標為\(\lfloor \frac{i - 1}{2} \rfloor\),可以參考下圖進行計算。
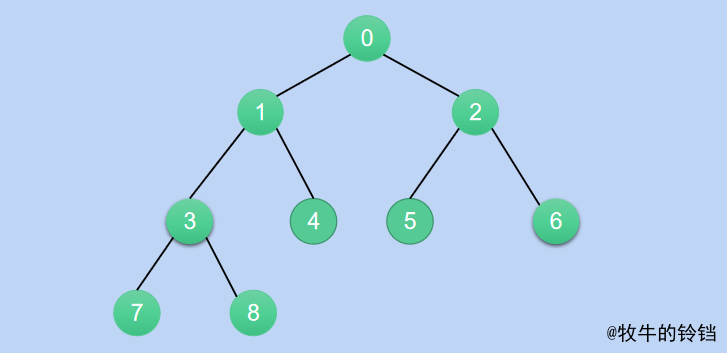
根據上面的分析我們可以知道,如果想把一個陣列變成一個堆,那麼需要從最後一個有孩子的節點開始進行下沉操作,直到根節點。
下沉操作的具體步驟,如果是小根堆,就將當前節點的值和左右孩子節點進行比較,如果當前節點\(V\)比左右孩子節點都小的話則停止,或者當前節點沒有孩子節點也停止,如果子節點的值比當前節點小,則需要選取子節點中較小的值,然後和當前節點互換,然後在置換後對\(V\)重新進行上述操作。如果是大根堆則選取孩子節點中較大的值。具體程式碼如下:
#include <cstdio>
#include <cstring>
#include <stdlib.h>
#include <time.h>
#define True 1
#define False 0
#define NUM 9
#define MAX_VALUE 100
void swap(int * array, int idx1, int idx2) {
/*交換陣列的兩個元素*/
int t = array[idx1];
array[idx1] = array[idx2];
array[idx2] = t;
}
void down(int * array, int length, int start, int big=False) {
/* array 是堆陣列,length 為陣列的長度,start 是當前需要下沉的元素的下標,big 表示是否為大根堆 */
while(start < length) {
int left_child = 2 * start + 1;
int right_child = 2 * start + 2;
int idx = left_child;
if (left_child > length - 1)
/* 如果做孩子對應的下標超出陣列元素個數則需要跳出迴圈 */
break;
if(right_child < length) {
if (!big) {
if(array[right_child] < array[left_child])
idx = right_child;
} else {
if(array[right_child] > array[left_child])
idx = right_child;
}
}
if(!big) {
if(array[start] > array[idx]){
swap(array, idx, start);
start = idx;
} else{
break;
}
} else {
if(array[start] < array[idx]){
swap(array, idx, start);
start = idx;
} else{
break;
}
}
}
}
/* 定義對整個陣列的堆化過程 */
void heapify(int * array, int length, int start=-2, int big=True) {
/* start 的預設值為 -2 表示從最後一個有孩子節點的元素開始 */
if(start == -1)
/* 最後一個元素的下標為0 再減1則為-1 在這裡設定遞迴出口*/
return;
if (start == -2) {
start = (length - 2) / 2;
}
down(array, length, start, big);
/* 當前元素進行下沉操作之後 再對他的上一個元素進行 下沉操作*/
heapify(array, length, start - 1, big);
}
int main() {
int data[NUM] = {0, 1, 2, 3, 4, 5, 6, 7, 8};
heapify(data, NUM);
for(int i=0; i < NUM; i++) {
printf("%d ", data[i]);
}
return 0;
}
/* output : 8 7 6 3 4 5 2 1 0 */
堆的應用
堆排序
對於陣列array = {0, 7, 3, 5, 1, 6, 2, 4, 8}對應的堆如下圖所示,如果想使用堆排序,首先需要將陣列變成一個堆,使用上面的heapify函數即可。

先將陣列變成大根堆,變換過程如下圖所示:
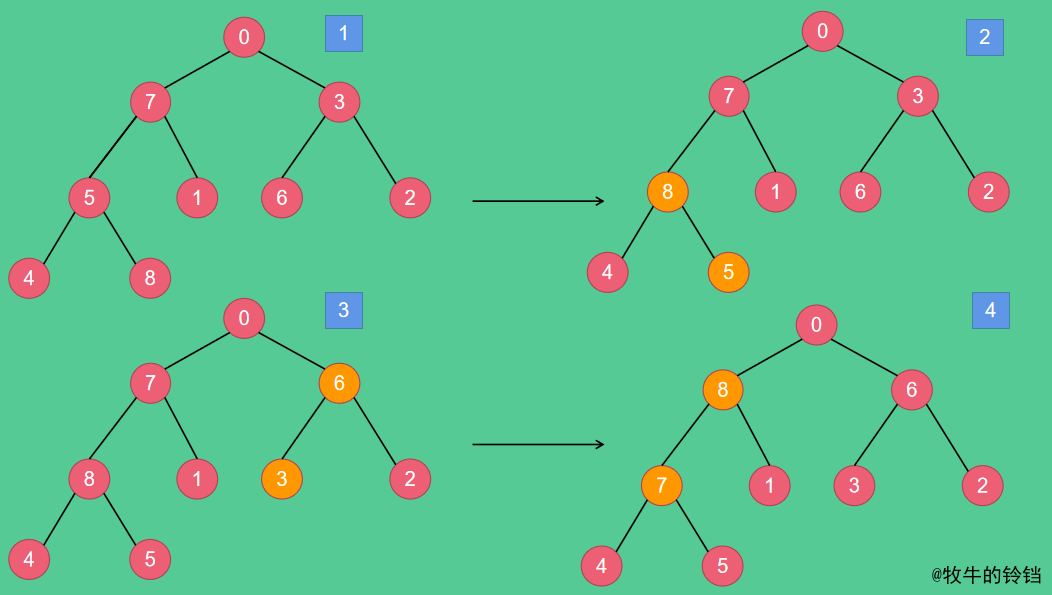
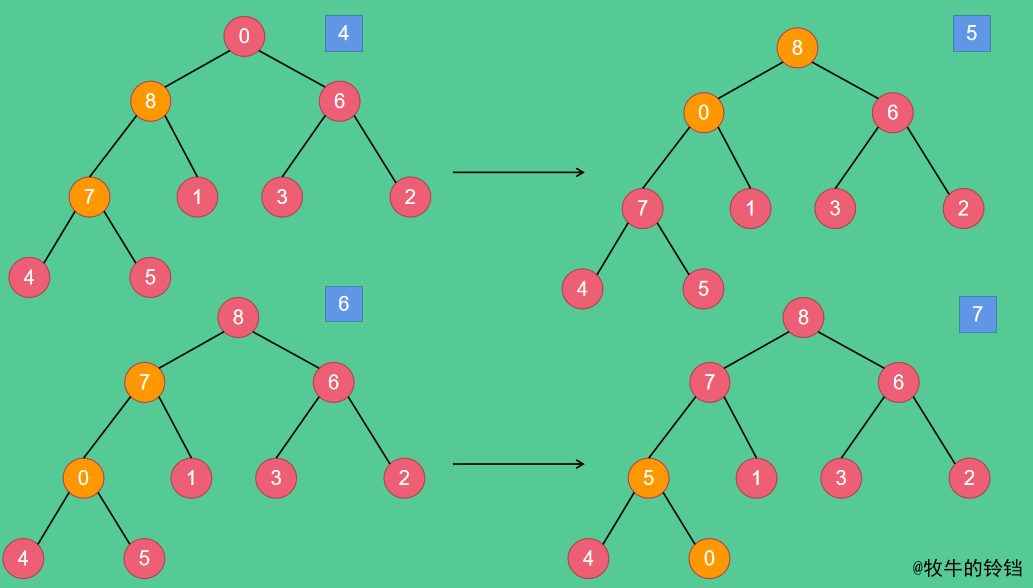
最終得到的大根堆如圖7所示。得到一個大根堆之後怎麼排序呢?我們知道對於一個大根堆來說,根節點的孩子節點都比他小,所以根節點一定是堆中值最大的元素,現在將根節點和最後一個節點互換位置,置換後的結果如下圖所示:
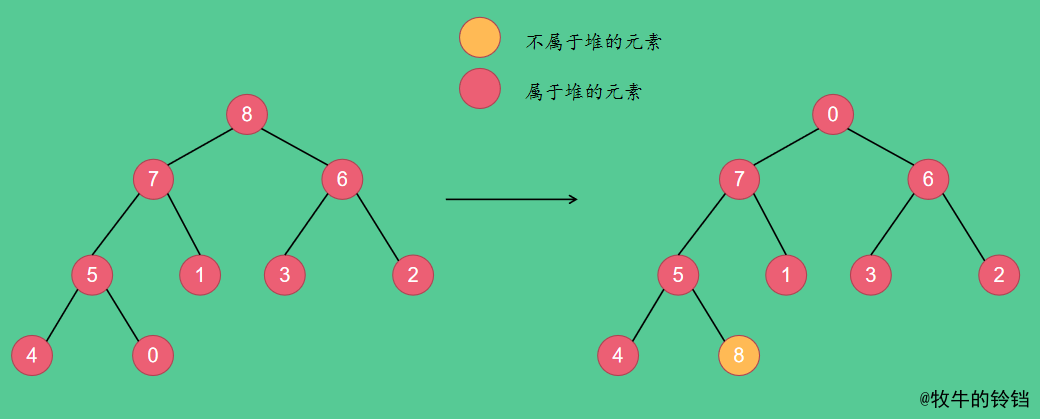
現在已經將陣列中最大的元素放到陣列的最後一個元素了,現在我們將最後一個元素從堆中剔除,對於這個操作我們只需要將堆的長度減1,對於儲存在陣列中的資料不需要改動,即現在堆中的元素只有{0, 7, 6, 5, 1, 3, 2, 4},但是實際在陣列中的元素仍然為{0, 7, 6, 5, 1, 3, 2, 4, 8}。現在對元素0進行下沉操作。操作過程如下圖所示:

最終會得到結果V,因為元素8已經不在堆中了,因此不會和8置換,這樣堆中最大的元素就在陣列最後一個位置,再對剩餘元素組成的堆執行上述操作,又會將其中最大的元素放在倒數第二個位置,再對根節點的元素進行下沉操作,如此進行下去就可以排好序了。進行過程如下圖所示:
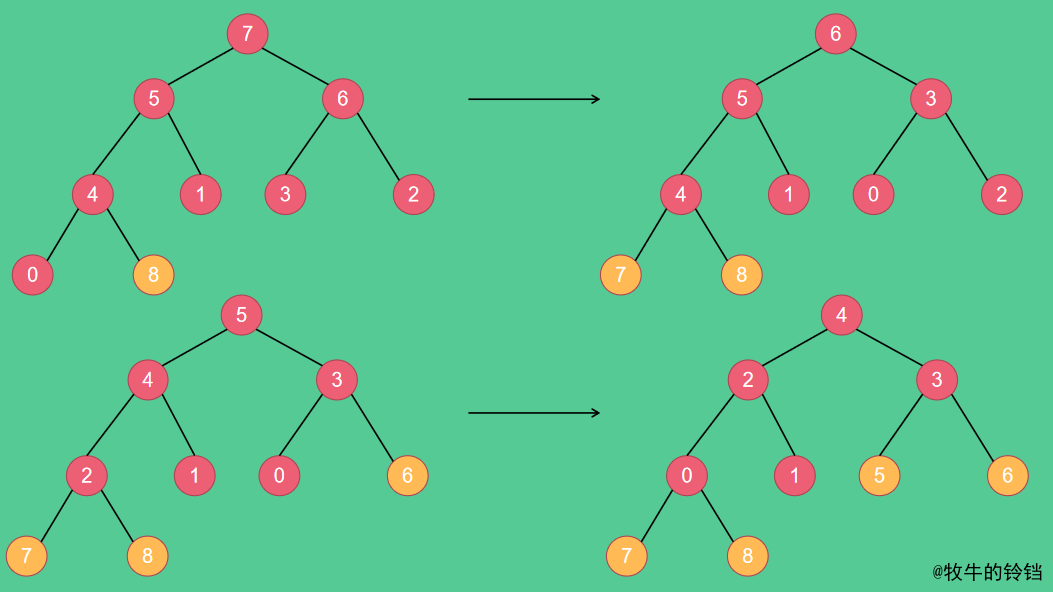
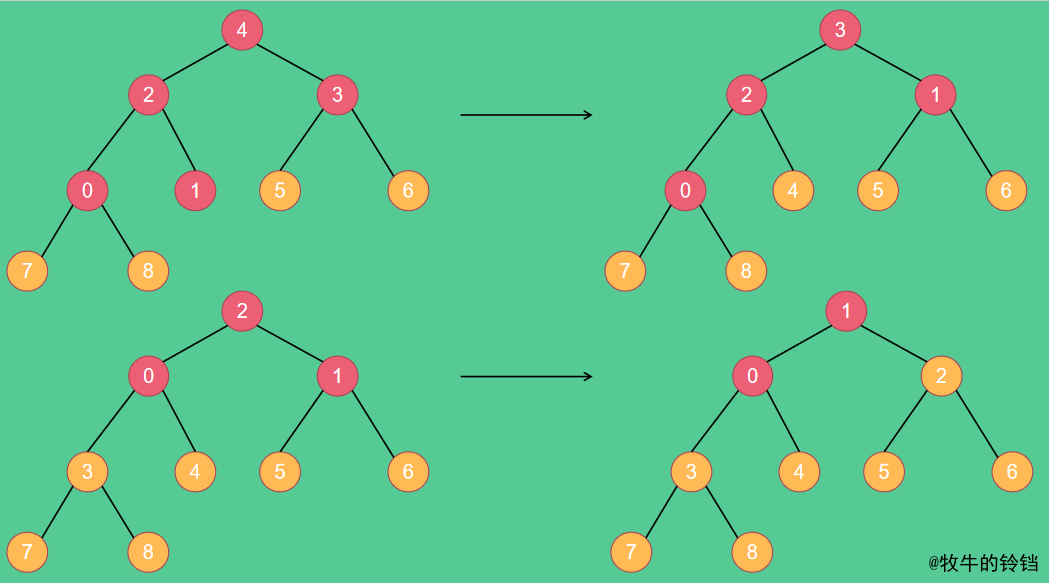
最後再將最後得到的堆(只有兩個元素)互換位置即可,這樣就是得到一個有序的陣列了。從上述過程我們發現,如果初始堆是大根堆我們得到的是升序陣列,如果是小根堆的話得到的將是降序陣列。
堆排序程式碼實現
從上述分析過程可以直到每次置換根節點和堆最後一個節點,然後將堆長度減1,然後堆根節點的元素進行下沉操作即可,如此進行下去,直到最後堆中只有一個元素,則排序完成。具體程式碼如下:
#include <cstdio>
#include <cstring>
#include <stdlib.h>
#define True 1
#define False 0
#define NUM 9
void swap(int * array, int idx1, int idx2) {
/* 交換陣列的兩個元素 */
int t = array[idx1];
array[idx1] = array[idx2];
array[idx2] = t;
}
void down(int * array, int length, int start, int big=False) {
while(start < length) {
int left_child = 2 * start + 1;
int right_child = 2 * start + 2;
int idx = left_child;
if (left_child > length - 1)
break;
if(right_child < length) {
if (!big) {
if(array[right_child] < array[left_child])
idx = right_child;
} else {
if(array[right_child] > array[left_child])
idx = right_child;
}
}
if(!big) {
if(array[start] > array[idx]){
swap(array, idx, start);
start = idx;
} else{
break;
}
} else {
if(array[start] < array[idx]){
swap(array, idx, start);
start = idx;
} else{
break;
}
}
}
}
void heapify(int * array, int length, int start=-2, int big=True) {
if(start == -1)
return;
if (start == -2) {
start = (length - 2) / 2;
}
down(array, length, start, big);
heapify(array, length, start - 1, big);
}
void heap_sort(int * array, int length, bool reverse=False) {
for(int i = length - 1; i >=0; i--) {
swap(array, i, 0);
down(array, i, 0, !reverse);
}
}
int main() {
int data[NUM] = {0, 7, 3, 5, 1, 6, 2, 4, 8};
heapify(data, NUM);
for(int i=0; i < NUM; i++) {
printf("%d ", data[i]);
}
heap_sort(data, NUM);
printf("\nAfter sorted !!!\n");
for(int i=0; i < NUM; i++) {
printf("%d ", data[i]);
}
return 0;
}
堆的時間複雜度
從上面堆的結構容易知道,堆是一種二元樹結構,如果當前堆中有元素\(N\)個,則向堆中插入一個元素的時間複雜度為\(O(log(N))\),它在下沉的時候,資料交換的次數不會大於\(log(N)\)。如果一個陣列(堆)中有\(N\)個元素,那麼它需要進行\(N\)次,根元素和堆的最後一個元素進行交換,然後資料進行下沉,每一次下沉的資料交換次數不會\(log(N)\),而且越往後交換的次數距離\(log(N)\)越大,即交換的次數越來越少,因此堆排序的最大時間複雜度為\(O(Nlog(N))\)。
優先順序佇列
佇列就是一種先進先出的資料結構,優先順序佇列就是在佇列中優先順序最高的先出。如果用一個大於0的整型數位來代表,資料的優先順序的話(即數位越小優先順序越高)我們可以用小根堆來處理資料,因為小根堆的堆頂元素一定是一個堆中最小的,那麼每次進行pop操作,即從佇列中拿出一個元素的時候就可以將堆頂的元素和最後一個元素進行交換,然後再將新的堆頂的元素進行下沉操作即可,如果有一個新的元素進行堆,那麼它可以現在放在陣列最末的位置,然後進行上浮操作,其實這個操作很簡單原理和下沉操作一模一樣,連停止條件都差不多,他們正好相反,下沉的操作噹噹前節點是葉子節點或者小於子節點的元素(對於小根堆來說)停止下沉,而上浮操作是噹噹前節點是根節點或者當前節點的值大於父親節點就停下來。下面看一個具體的操作過程。
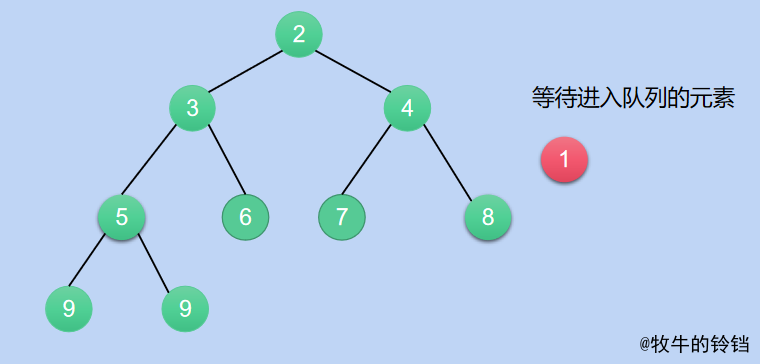

上述一個簡單的操作過程。其實很簡單,只要掌握了下沉操作這個過程就很容易理解了,以上就是關於堆的所有內容了,如果對你有所幫助,三連~~~
以上就是本篇文章的所有內容了,我是LeHung,我們下期再見!!!更多精彩內容合集可存取專案:https://github.com/Chang-LeHung/CSCore
關注公眾號:一無是處的研究僧,瞭解更多計算機(Java、Python、計算機系統基礎、演演算法與資料結構)知識。