分散式ID詳解(5種分散式ID生成方案)

分散式架構會涉及到分散式全域性唯一ID的生成,今天我就來詳解分散式全域性唯一ID,以及分散式全域性唯一ID的實現方案@mikechen
什麼是分散式系統唯一ID
在複雜分散式系統中,往往需要對大量的資料和訊息進行唯一標識。
如在金融、電商、支付、等產品的系統中,資料日漸增長,對資料分庫分表後需要有一個唯一ID來標識一條資料或訊息,資料庫的自增ID顯然不能滿足需求,此時一個能夠生成全域性唯一ID的系統是非常必要的。
分散式系統唯一ID的特點
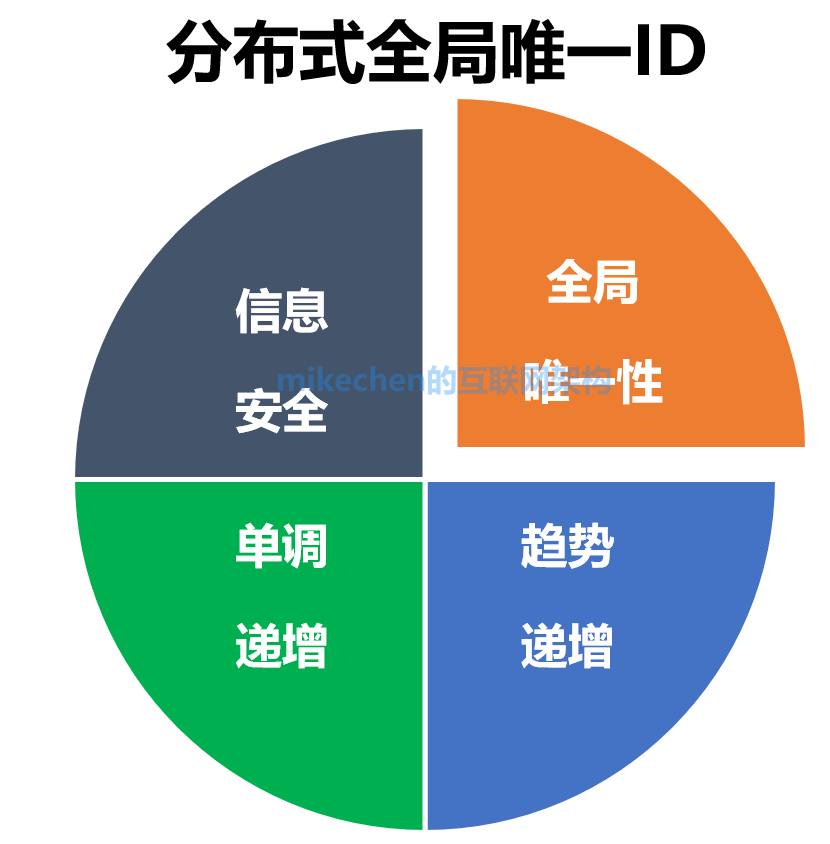
- 全域性唯一性:不能出現重複的ID號,既然是唯一標識,這是最基本的要求。
- 趨勢遞增:在MySQL InnoDB引擎中使用的是聚集索引,由於多數RDBMS使用B-tree的資料結構來儲存索引資料,在主鍵的選擇上面我們應該儘量使用有序的主鍵保證寫入效能。
- 單調遞增:保證下一個ID一定大於上一個ID,例如事務版本號、IM增量訊息、排序等特殊需求。
- 資訊保安:如果ID是連續的,惡意使用者的扒取工作就非常容易做了,直接按照順序下載指定URL即可;如果是訂單號就更危險了,競對可以直接知道我們一天的單量。所以在一些應用場景下,會需要ID無規則、不規則。
同時除了對ID號碼自身的要求,業務還對ID號生成系統的可用性要求極高,想象一下,如果ID生成系統癱瘓,這就會帶來一場災難。
由此總結下一個ID生成系統應該做到如下幾點:
- 平均延遲和TP999延遲都要儘可能低;
- 可用性5個9;
- 高QPS
分散式系統唯一ID的實現方案
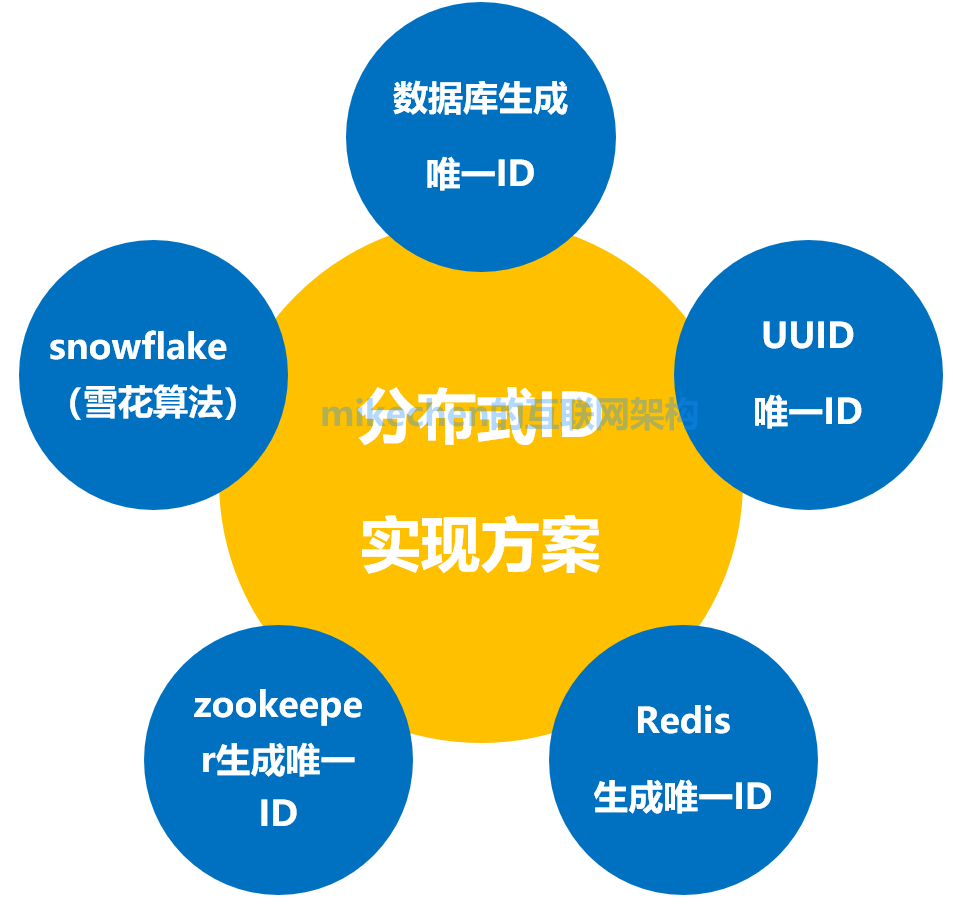
1.UUID
UUID(Universally Unique Identifier)的標準型式包含32個16進位制數位,以連字號分為五段,形式為8-4-4-4-12的36個字元,範例:550e8400-e29b-41d4-a716-446655440000,到目前為止業界一共有5種方式生成UUID,詳情見IETF釋出的UUID規範 A Universally Unique IDentifier (UUID) URN Namespace。
UUID優點:
- 效能非常高:本地生成,沒有網路消耗。
UUID缺點:
- 不易於儲存:UUID太長,16位元組128位元,通常以36長度的字串表示,很多場景不適用;
- 資訊不安全:基於MAC地址生成UUID的演演算法可能會造成MAC地址洩露,這個漏洞曾被用於尋找梅麗莎病毒的製作者位置;
- ID作為主鍵時在特定的環境會存在一些問題,比如做DB主鍵的場景下,UUID就非常不適用。
2.資料庫生成ID
以MySQL舉例,利用給欄位設定auto_increment_increment和auto_increment_offset來保證ID自增,每次業務使用下列SQL讀寫MySQL得到ID號。
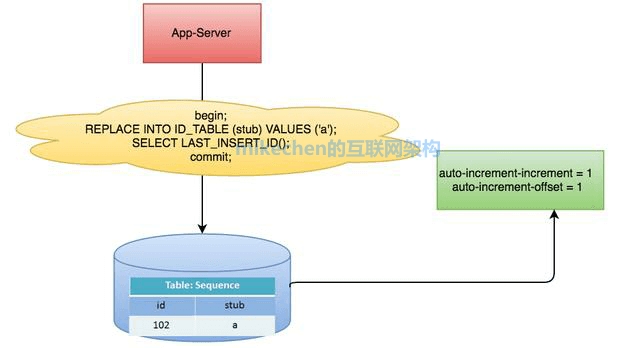
資料庫生成ID優點:
- 非常簡單,利用現有資料庫系統的功能實現,成本小,有DBA專業維護。
- ID號單調自增,可以實現一些對ID有特殊要求的業務。
資料庫生成ID缺點:
- 強依賴DB,當DB異常時整個系統不可用,屬於致命問題。設定主從複製可以儘可能的增加可用性,但是資料一致性在特殊情況下難以保證。主從切換時的不一致可能會導致重複發號。
- ID發號效能瓶頸限制在單臺MySQL的讀寫效能。
3.Redis生成ID
當使用資料庫來生成ID效能不夠要求的時候,我們可以嘗試使用Redis來生成ID。
這主要依賴於Redis是單執行緒的,所以也可以用生成全域性唯一的ID。可以用Redis的原子操作 INCR和INCRBY來實現。
比較適合使用Redis來生成每天從0開始的流水號。比如訂單號=日期+當日自增長號。可以每天在Redis中生成一個Key,使用INCR進行累加。
Redis生成ID優點:
1)不依賴於資料庫,靈活方便,且效能優於資料庫。
2)數位ID天然排序,對分頁或者需要排序的結果很有幫助。
Redis生成ID缺點:
1)如果系統中沒有Redis,還需要引入新的元件,增加系統複雜度。
2)需要編碼和設定的工作量比較大。
4.利用zookeeper生成唯一ID
zookeeper主要通過其znode資料版本來生成序列號,可以生成32位元和64位元的資料版本號,使用者端可以使用這個版本號來作為唯一的序列號。
很少會使用zookeeper來生成唯一ID。主要是由於需要依賴zookeeper,並且是多步呼叫API,如果在競爭較大的情況下,需要考慮使用分散式鎖。因此,效能在高並行的分散式環境下,也不甚理想。
5.snowflake雪花演演算法生成ID
這種方案大致來說是一種以劃分名稱空間(UUID也算,由於比較常見,所以單獨分析)來生成ID的一種演演算法,這種方案把64-bit分別劃分成多段,分開來標示機器、時間等,比如在snowflake中的64-bit分別表示如下圖(圖片來自網路)所示:
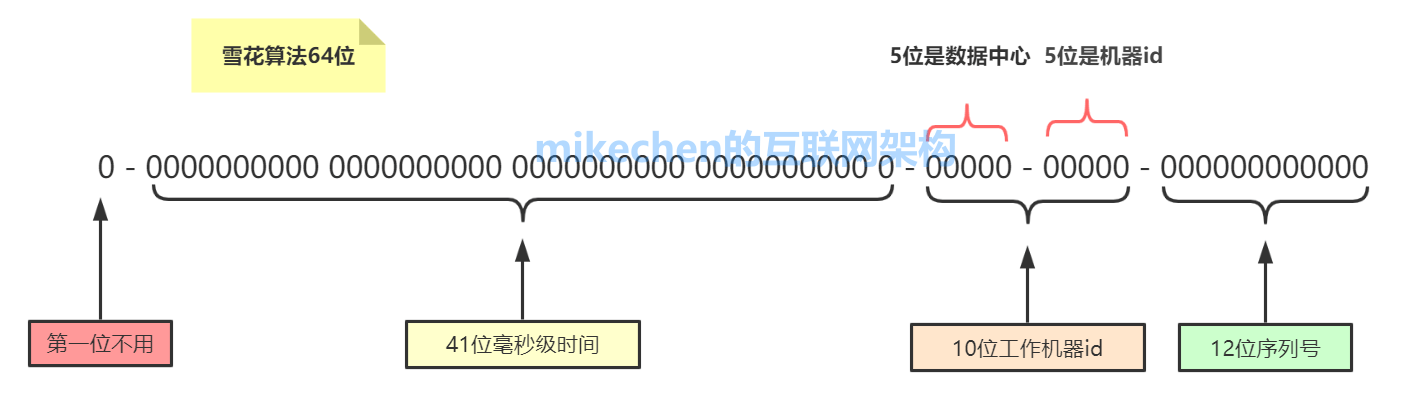
41-bit的時間可以表示(1L<<41)/(1000L*3600*24*365)=69年的時間,10-bit機器可以分別表示1024臺機器。如果我們對IDC劃分有需求,還可以將10-bit分5-bit給IDC,分5-bit給工作機器。這樣就可以表示32個IDC,每個IDC下可以有32臺機器,可以根據自身需求定義。12個自增序列號可以表示2^12個ID,理論上snowflake方案的QPS約為409.6w/s,這種分配方式可以保證在任何一個IDC的任何一臺機器在任意毫秒內生成的ID都是不同的。
雪花演演算法ID優點:
- 毫秒數在高位,自增序列在低位,整個ID都是趨勢遞增的。
- 不依賴資料庫等第三方系統,以服務的方式部署,穩定性更高,生成ID的效能也是非常高的。
- 可以根據自身業務特性分配bit位,非常靈活。
雪花演演算法ID缺點:
- 強依賴機器時鐘,如果機器上時鐘回撥,會導致發號重複或者服務會處於不可用狀態。
以上
作者簡介
陳睿|mikechen,10年+大廠架構經驗,《BAT架構技術500期》系列文章作者,專注於網際網路架構技術。
閱讀mikechen的網際網路架構更多技術文章合集
Java並行|JVM|MySQL|Spring|Redis|分散式|高並行