論文解讀(FedGAT)《Federated Graph Attention Network for Rumor Detection》
論文資訊
論文標題:Federated Graph Attention Network for Rumor Detection
論文作者:Huidong Wang, Chuanzheng Bai, Jinli Yao
論文來源:2022, arXiv
論文地址:download
論文程式碼:download
1 Introduction
現有的謠言檢測模型都是為單一的社交平臺構建的,這忽略了跨平臺謠言的價值。本文將聯邦學習正規化與雙向圖注意網路謠言檢測模型相結合,提出了用於謠言檢測的聯邦圖注意網路(FedGAT)模型。
對於資料安全和隱私保護,不同組織之間的資料通常不能互操作,而且它們不能很容易地聚合和處理,這種無法共用資料的情況被稱為 isolated data island problem。
2 Preliminaries
2.1 Problem statement and notation
許多社群網路很難合作解決謠言傳播的問題,傳統的謠言檢測是在單一的社群網路平臺進行,通常只是獲得某個組織的使用者資料,然後建立一個模型來確定一個時間是否釋出了虛假的謠言貼文。本文構建的謠言檢測模型主要針對不同社交平臺之間謠言資料的互操作性,建立了跨平臺資料聚合的模型,以提高社群網路中虛假謠言事件的檢測效率。
Table 1 總結了本文中使用的一些符號的定義,並將需要處理的謠言檢測問題描述如下。
假設有 $k$ 個平臺,他們對應的謠言資料集是 $\left\{D_{i}\right\}_{i=1, \ldots, k}^{m}$,其中 ,$D_{i}$ 代表第 $i$ 個平臺的謠言資料集。假設 第 $i$ 個平臺擁有 $m$ 個 post event,它可以表示為 $\left\{C_{1}, C_{2}, \ldots, C_{m}\right\}$ 。謠言檢測的目的是對事件來源貼文的內容是否可靠進行分類,即根據現有知識判斷是否為虛假謠言。
2.2 Graph Attention Network
注意力係數計算:
${\Large \alpha_{i j}=\frac{\exp \left(\text { LeakyReLU }\left(a^{T}\left[W \cdot h_{i} \| W \cdot h_{j}\right]\right)\right)}{\sum_{j \in N_{i} \cup i} \exp \left(\operatorname{LeakyReLU}\left(a^{T}\left[W \cdot h_{i} \| W \cdot h_{j}\right]\right)\right)}} \quad\quad\quad(1)$
多頭注意力:
${\Large h_{i}^{\prime}=\|_{h e a d=1}^{H e a d s} \sigma\left(\sum\limits_{j \in i \cup i} \alpha_{i j}^{h e a d} W^{h e a d} h_{j}\right)} $
2.3 Federated Learning
聯邦學習旨在建立一個基於分散式資料集的聯邦學習模型。它通常包括兩個過程:模型訓練,和模型推理。在模型訓練中,各方之間可以進行與模型相關的資訊交換。聯邦學習是一種演演算法框架,用於構建具有以下特徵的機器學習模型。首先,兩個或兩個以上的聯合學習參與者共同作業構建一個共用的機器學習模型,每個參與者都有幾個訓練資料,可以用來訓練該模型。第二,在聯邦學習模型的訓練過程中,每個參與者擁有的資料不會離開參與者,即資料不會離開資料所有者。與聯邦學習模式相關的資訊可以在雙方之間以加密的方式傳輸和交換,需要確保沒有參與者能夠推斷出其他方的原始資料。此外,聯邦學習模型的效能必須能夠完全接近理想模型的效能,這意味著通過收集和訓練所有訓練資料而獲得的機器學習模型。
我們使用水平聯邦學習,它在樣本資料不同的情況下處理具有相同特徵 $X$ 和標籤資訊 $Y$ 的跨平臺資料,因此它適用於我們所研究的謠言檢測情況。在典型的聯邦學習正規化中,第 $i$ 個使用者端的區域性目標函數如 $\text{eq.3}$ 所示。 其中 $D_i$ 為第 $i$ 個使用者端的本地資料集,$f$ 為引數為 $w$ 的模型的損失函數,$n_i$ 為第 $i$ 個使用者端的資料量。
${\large F_{i}(w)=\frac{1}{n_{i}} \sum\limits _{j \in D_{i}} f_{j}(w)} \quad\quad\quad(3)$
中心伺服器目標函數 $F(w)$ 通常計算為 $\text{eq.4}$ 。其中 $m$ 為參與培訓的使用者端裝置總數,$n$ 為所有使用者端資料量之和。
${\Large \min _{w} F(w)=\sum\limits _{i=1}^{m} \frac{n_{i}}{n} F_{i}(w)} \quad\quad\quad(4)$
3 FedGAT model
整體框架如下:
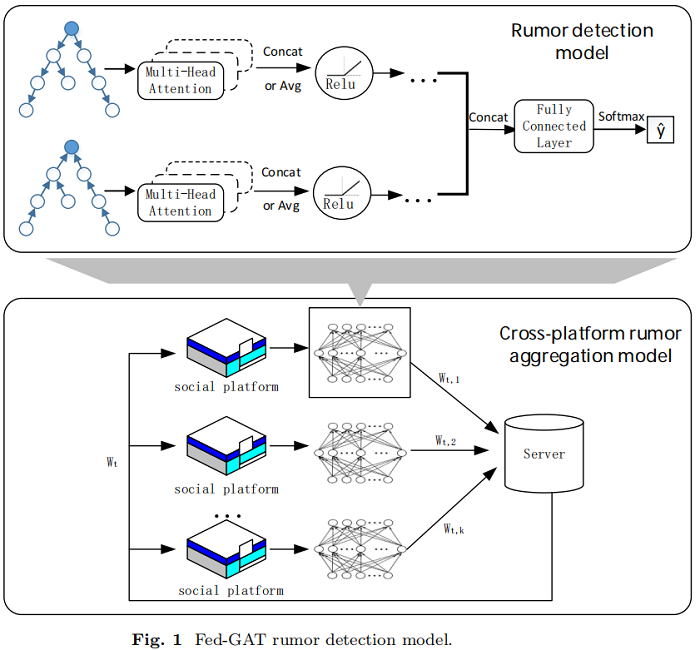
每個社交平臺都在本地使用專有資料進行謠言檢測,並將檢測模型訓練過程中生成的模型引數傳送到終端伺服器進行聚合處理。伺服器端的全域性模型將處理後的模型引數返回給本地模型,然後本地模型根據跨平臺資訊對自己模型的引數進行微調。
本文提出的跨平臺謠言檢測模型包括區域性謠言檢測模型和跨平臺資料處理的聯邦學習正規化兩部分,我們將詳細介紹我們的 FedGAT模型。
根據經驗,貼文的內容資訊可以通過源貼文和轉發的貼文之間的內容來反反映。此外,對於每個事件,第一個貼文的原始內容資訊往往是最重要的,而後續的轉發貼文是對原始貼文內容的評論。所以本文使用 雙向圖注意網路 作為本文的謠言檢測模型的基礎,其中,雙向模型可以綜合謠言資訊沿自頂向下和自底向上的傳播方向,且GAT模型可以增強對源貼文資訊的關注。
3.1 Preprocessing of rumor data
首先,對謠言資料中的文字資訊進行詞向量處理,並使用 TF-IDF 計算文字中單詞的頻率作為初始特徵。每個單詞向量的維度是 5000,每個維數的值表示文章中某個單詞的頻率。
然後,根據貼文之間的轉發關係構建圖結構 $\operatorname{Graph}_{i}=\left(V_{i}, E_{i}\right)$。
定義:
-
- $\operatorname{Graph}_{i}^{T D}=\left(V_{i}, E_{i}^{T D}\right)$
- $Graph_{i}^{B U}=\left(V_{i}, E_{i}^{B U}\right)$
- $A_{i}^{T D}=\left(A_{i}^{B U}\right)^{T}$
- $H_{i}=\left[h_{i, 0}^{T}, h_{i, 1}^{T}, \ldots, h_{i, n_{i}}^{T}\right]$
3.2 Local model training on social platform
多頭注意力:
${\large h_{i}^{T D^{\prime}}=\operatorname{Re} L U\left(\underset{h e a d=1}{5} \sigma\left(\sum_{j \in{ }_{i} \cup i} \alpha_{i j}^{T \text { Dhead }} W^{T D h e a d} h_{j}^{T D}\right)\right)} \quad\quad\quad(5)$
${\large h_{i}^{\mathrm{BU}}=\operatorname{Re} L U\left(\underset{h e a d=1}{5} \sigma\left(\sum\limits_{j \in_{i} \cup i} \alpha_{i j}^{\mathrm{BUhead}} W^{\mathrm{BUhead}} h_{j}^{\mathrm{BU}}\right)\right)} \quad\quad\quad(6)$
最後,拼接 top-down 和 bottom-up directions 的嵌入矩陣,最後使用 softmax 函數對輸出的分類結果進行處理,如 $\text{Eq.7}$ 所示:
$\hat{y}=\operatorname{softmax}\left(F C\left(\left(H^{T D^{\prime}}, H^{B U^{\prime}}\right)\right)\right) \quad\quad\quad(7)$
3.3 Aggregate model parameters on terminal server
水平聯合學習的終端伺服器是對不同社交平臺的模型訓練資料進行聚合,在更新全域性模型後,將更新後的引數變化傳送回這些本地社交平臺。在這裡的設定中,我們設定了每輪訓練的使用者端數量和迭代次數等組態檔,並將之前定義的 Bi-GAT 謠言檢測模型作為伺服器端的初始模型。該模型用於接收所有使用者端訓練引數資訊。
本部分我們選擇的聚合函數是經典的 FedAvg 演演算法,其計算公式如 $\text{Eq.8}$ 所示:
$G^{t+1}=G^{t}+\frac{1}{m} \sum_{i=1}^{m}\left(F_{i}^{t+1}-G^{t}\right) \quad\quad\quad(8)$
其中 $G$ 和 $F$ 分別表示全域性模型和區域性模型,$t$ 表示第 $t$ 輪訓練。它的主要功能是在定義了建構函式後,使用使用者端上傳的接收模型來更新全域性模型。
在伺服器上進行引數更新後,社交平臺將根據返回的引數資訊調整其本地模型。我們將伺服器端設定的設定資訊複製到本地端。從伺服器接收到全域性模型的優化引數後,對每個社交平臺使用者端的謠言檢測模型進行修改,如 $\text{Eq.9}$ 所示
$F_{i}^{t+1}=(1-\lambda) F_{i}^{t}+\lambda G^{t} \quad\quad\quad(9)$
其中,$\lambda$ 是一個超引數,用來表示其他社交平臺資料對其本地模型的影響程度,並且參與聯邦學習的多個社交平臺越相似,$\lambda$ 的價值就越大。
4 Experiments
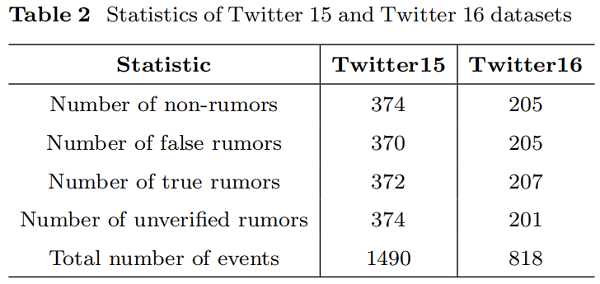
Dataset
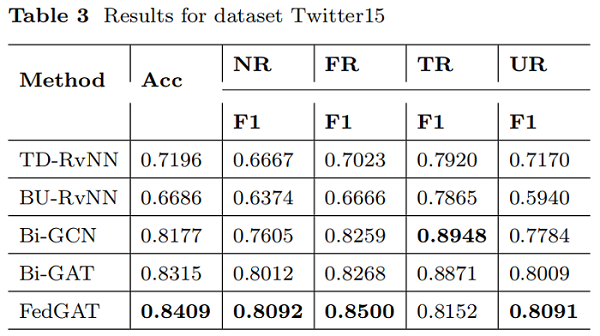
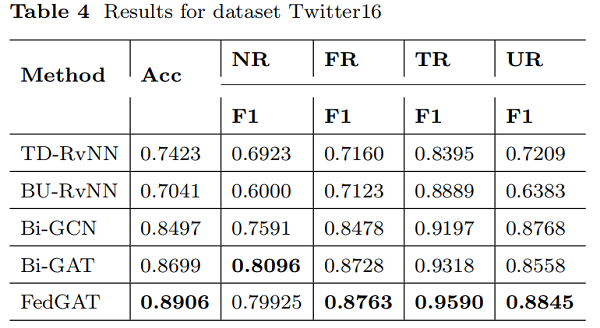
結果
$F 1=\frac{2 \cdot \text { Precision } \cdot \text { Recall }}{\text { Precision }+\text { Recall }}$
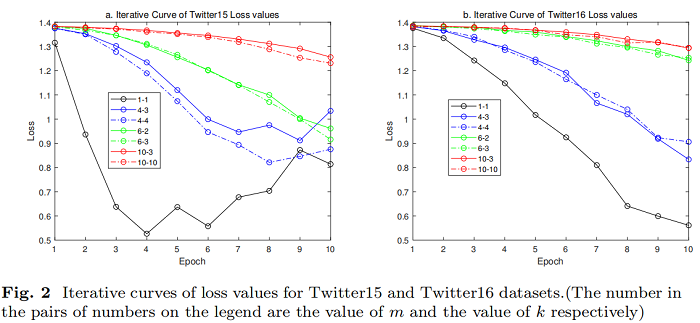
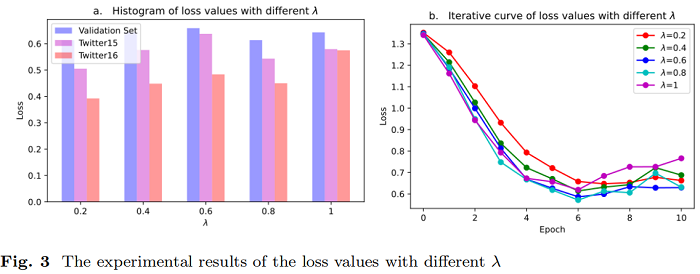
引數分析
5 Conclusion
跨不同社交平臺的謠言檢測問題是一個值得研究的領域。本文將聯邦學習框架與雙向圖注意網路謠言檢測模型相結合,構建了聯邦圖注意網路模型。它可以解決不同社交平臺上的謠言檢測中的資料島隔離問題,並可以安全可靠地進行跨平臺的謠言檢測。可以從模擬實驗結果使用公共Twitter謠言檢測資料集提出的 FedGAT 模型可以實現優秀的結果在處理資料集從不同平臺的同時,可以發現謠言檢測非常適合建立一個模型基於圖關注網路。此外,我們還分析了模型中 m、k、λ 等引數的影響。我們發現,模型在不同λ水平下所能達到的最小損失值沒有太大差異,但對模型的模型優化率有影響。λ越大,模型訓練的損失值可以減小得越快。平臺總數 m 的增加不利於更準確的謠言預測。在每個謠言檢測訓練中,每個訓練階段都應該使用盡可能多的客戶資料。
由於本文的實驗只是人工構建了資料集來模擬不同社交平臺的謠言資料,因此可能與實際的跨平臺謠言檢測資料集存在一些差異。我們期望跨平臺謠言檢測FedGAT模型在未來能夠基於現實生活中的多社交平臺場景進行模型優化。此外,本文中使用的Bi-GAT模型也可以被現有的優秀謠言檢測模型所取代,水平聯邦學習正規化也可以進行相應的修改。我們期待著在未來對謠言檢測進行更多的研究。
因上求緣,果上努力~~~~ 作者:關注我更新論文解讀,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/16731135.html