組合總和 II
組合總和 II
題目介紹
給定一個候選人編號的集合 candidates 和一個目標數 target ,找出 candidates 中所有可以使數位和為 target 的組合。
candidates 中的每個數位在每個組合中只能使用 一次 。
注意:解集不能包含重複的組合。
範例:
輸入: candidates = [10,1,2,7,6,1,5], target = 8,
輸出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
範例:
輸入: candidates = [2,5,2,1,2], target = 5,
輸出:
[
[1,2,2],
[5]
]
問題分析
方法一
在這道問題當中我們仍然是從一組資料當中取出資料進行組合,然後得到指定的和,但是與前面的組合總和不同的是,在這個問題當中我們可能遇到重複的數位而且每個數位只能夠使用一次。這就給我們增加了很大的困難,因為如果存在相同的資料的話我們就又可能產生資料相同的組合,比如在第二個例子當中我們產生的結果[1, 2, 2]其中的2就可能來自candidates當中不同位置的2,可以是第一個,可以是第三個,也可以是最後一個2。但是在我們的最終答案當中是不允許存在重複的組合的。當然我們可以按照正常的方式遍歷,然後將得到的複合要求的結果加入到一個雜湊表當中,對得到的結果進行去重處理。但是這樣我們的時間和空間開銷都會加大很多。
在這個問題當中為了避免產生重複的集合,我們可以首先將這些資料進行排序,然後進行遍歷,我們拿一個資料來進行舉例子:[1, 2 1],現在我們將這個資料進行排序得到的結果為:[1, 1, 2],那麼遍歷的樹結構如下:
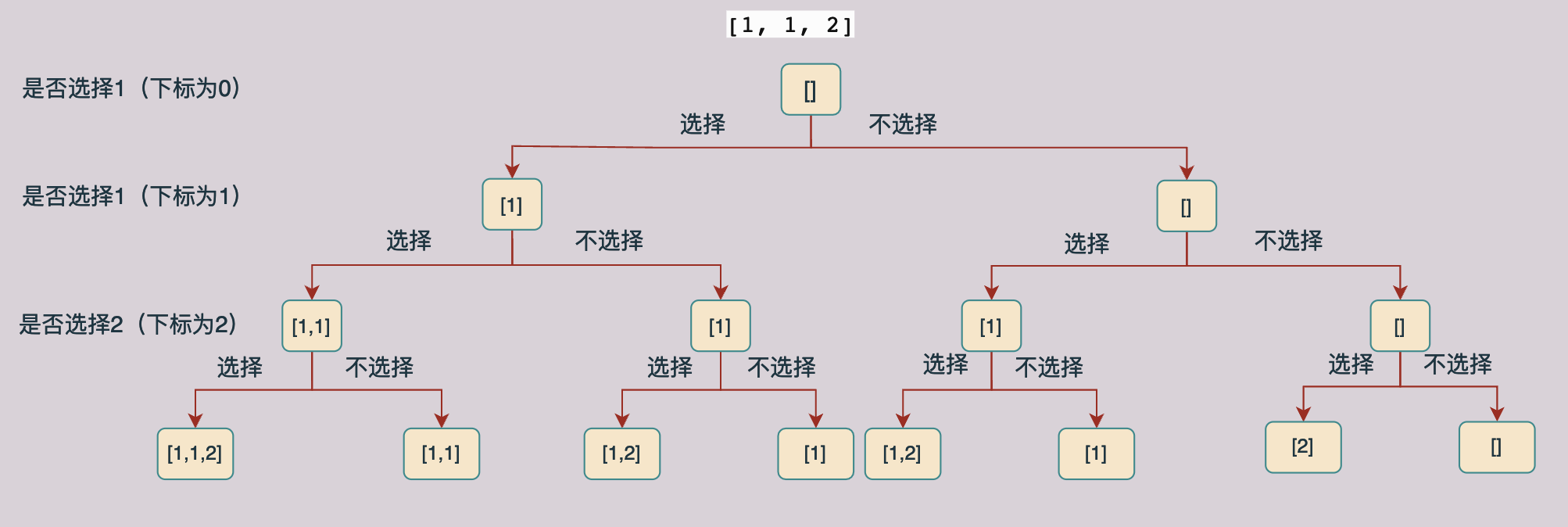
上圖表示[1, 1, 2]的遍歷樹,每一個資料都有選和不選兩種情況,根據這種分析方式可以構造上面的解樹,我們對上面的樹進行分析我們可以知道,在上面的樹當中有一部分子樹是有重複的(重複的子樹那麼我們就回產生重複的結果,因此我們要刪除重複的分支,也就是不進行遞迴求解),如下圖所示:
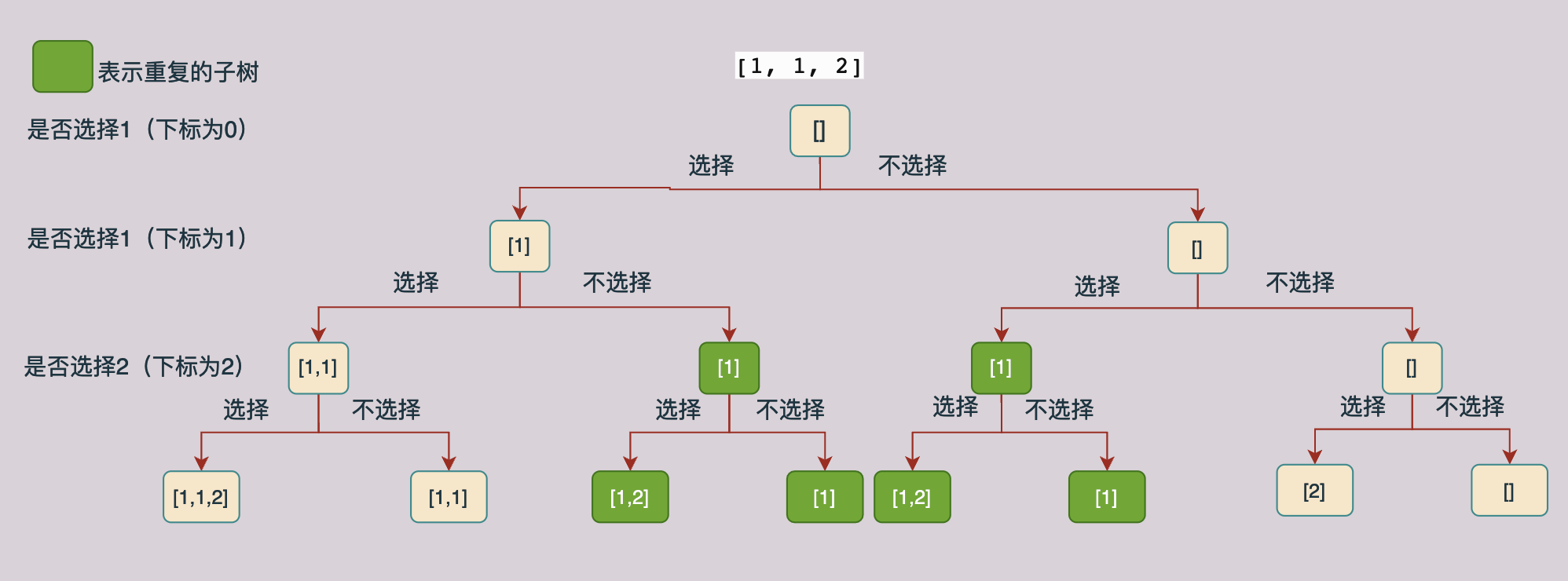
我們現在來分析一下上面圖中產生重複子樹的原因,在一層當中選1的到第二層不選1的子樹和第一層不選1而第二層選1的樹產生了重複,因此我們可以在第一層不選1第二層選1的子樹當中停止遞迴。
根據上面的例子我們可以總結出來,在同一層當中,如果後面的值等於他前面一個值的話,我們就可以不去生成「選擇」這個分支的子樹,因為在他的前面已經生成了一顆一模一樣的子樹了。
現在我們的問題是如何確定和上一個遍歷的節點是在同一層上面。我們可以使用一個used陣列進行確定,當我們使用一個資料之後我們將對應下標的used陣列的值設定為true,當遞迴完成進行回溯的時候在將對應位置的used值設定為false,因此當我們遍歷一個資料的時候如果他前面的一個資料的used值是false的話,那麼這個節點就和前面的一個節點在同一層上面。
根據上面的分析我們可以寫出如下的程式碼:
class Solution {
vector<vector<int>> ans;
vector<int> path;
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
vector<bool> used(candidates.size(), false);
backtrace(candidates, target, 0, 0, used);
return ans;
}
void backtrace(vector<int>& candidates, int target, int curIdx,
int curSum, vector<bool>& used) {
if (curSum == target) { // 滿足條件則儲存結果然後返回
ans.push_back(path);
return;
} else if (curSum > target || curIdx >= candidates.size()) {
return;
}
if (curIdx == 0) {
// 選擇分支
path.push_back(candidates[curIdx]);
used[curIdx] = true;
backtrace(candidates, target, curIdx + 1, curSum + candidates[curIdx], used);
// 在這裡進行回溯
path.pop_back();
used[curIdx] = false;
// 不選擇分支
backtrace(candidates, target, curIdx + 1, curSum, used);
}else {
if (used[curIdx - 1] == false && candidates[curIdx - 1] ==
candidates[curIdx]) { // 在這裡進行判斷是否在同一層,如果在同一層並且值相等的話 那就不需要進行選擇了 只需要走不選擇的分支及即可
backtrace(candidates, target, curIdx + 1, curSum, used);
}else{
// 選擇分支
path.push_back(candidates[curIdx]);
used[curIdx] = true;
backtrace(candidates, target, curIdx + 1, curSum + candidates[curIdx], used);
// 在這裡進行回溯
path.pop_back();
used[curIdx] = false;
// 不選擇分支
backtrace(candidates, target, curIdx + 1, curSum, used);
}
}
}
};
方法二
在回溯演演算法當中我們一般有兩種選擇情況,這一點我們在前面組合問題當中已經介紹過了,一種方法是用選擇和不選擇去生成解樹,這樣我們將生成一顆二元樹的解樹,另外一種是多叉樹,下面我們來看一下後者的解樹:
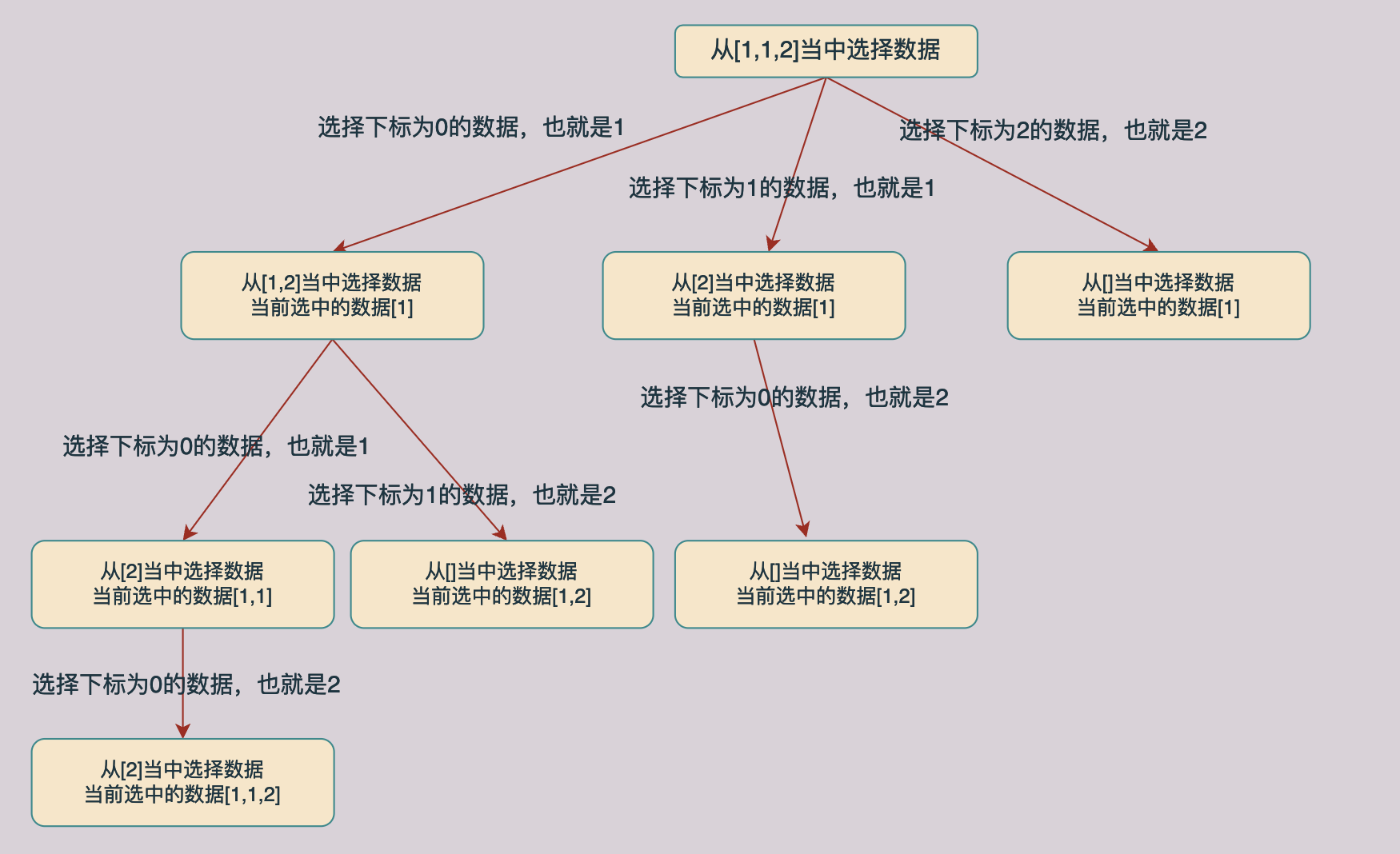
同樣對上面的解樹進行分析我們回發現同樣的也存在相同子樹的情況,如下圖所示,途中綠色的節點就時相同的節點:
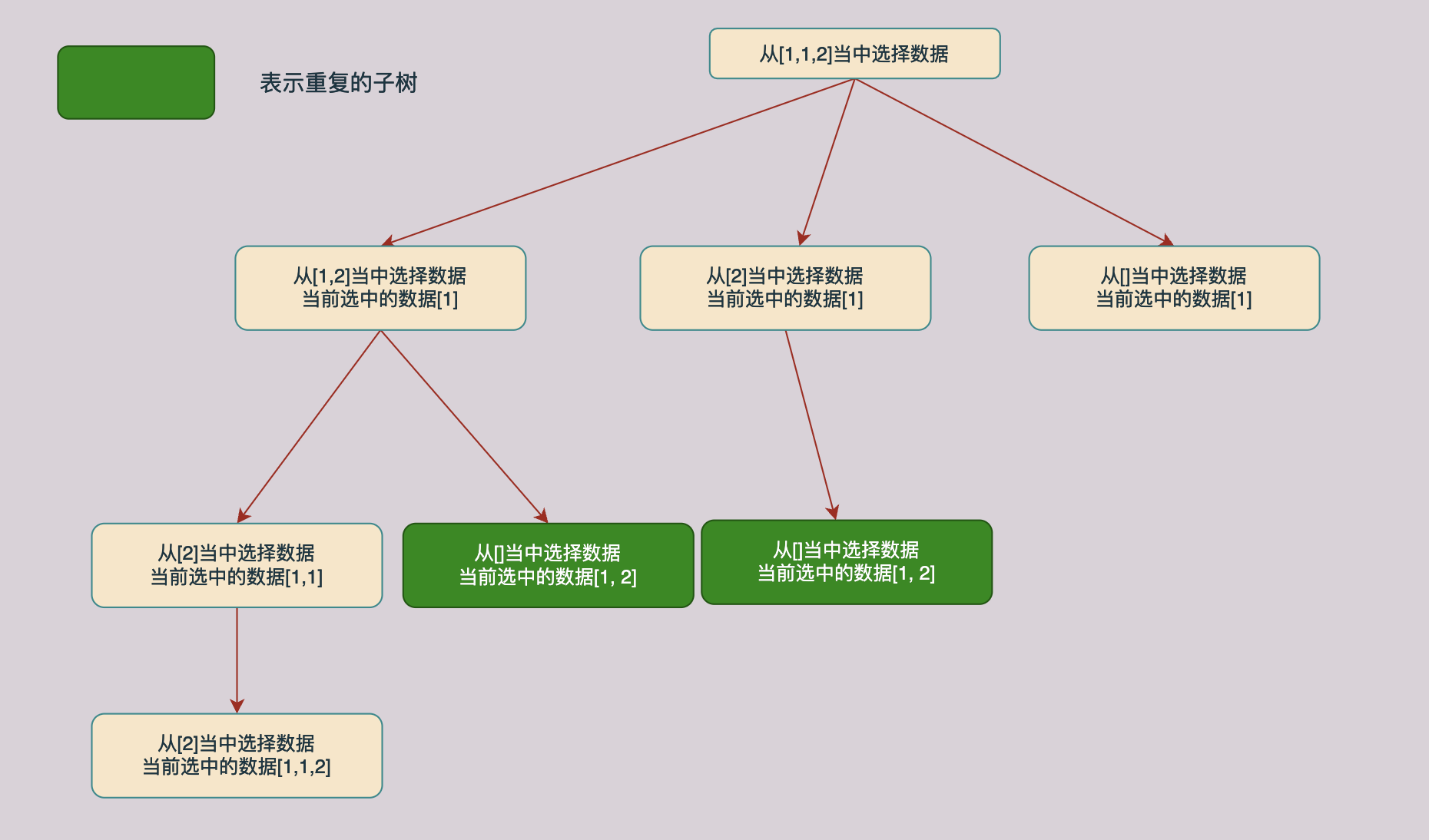
與前一種方法分析一樣,噹噹前的資料和同一層上面的前一個資料相同的時候我們不需要進行求解了,可以直接返回跳過這個分支,因為這個分支已經在前面被求解過了。具體的分析過程如下圖所示:
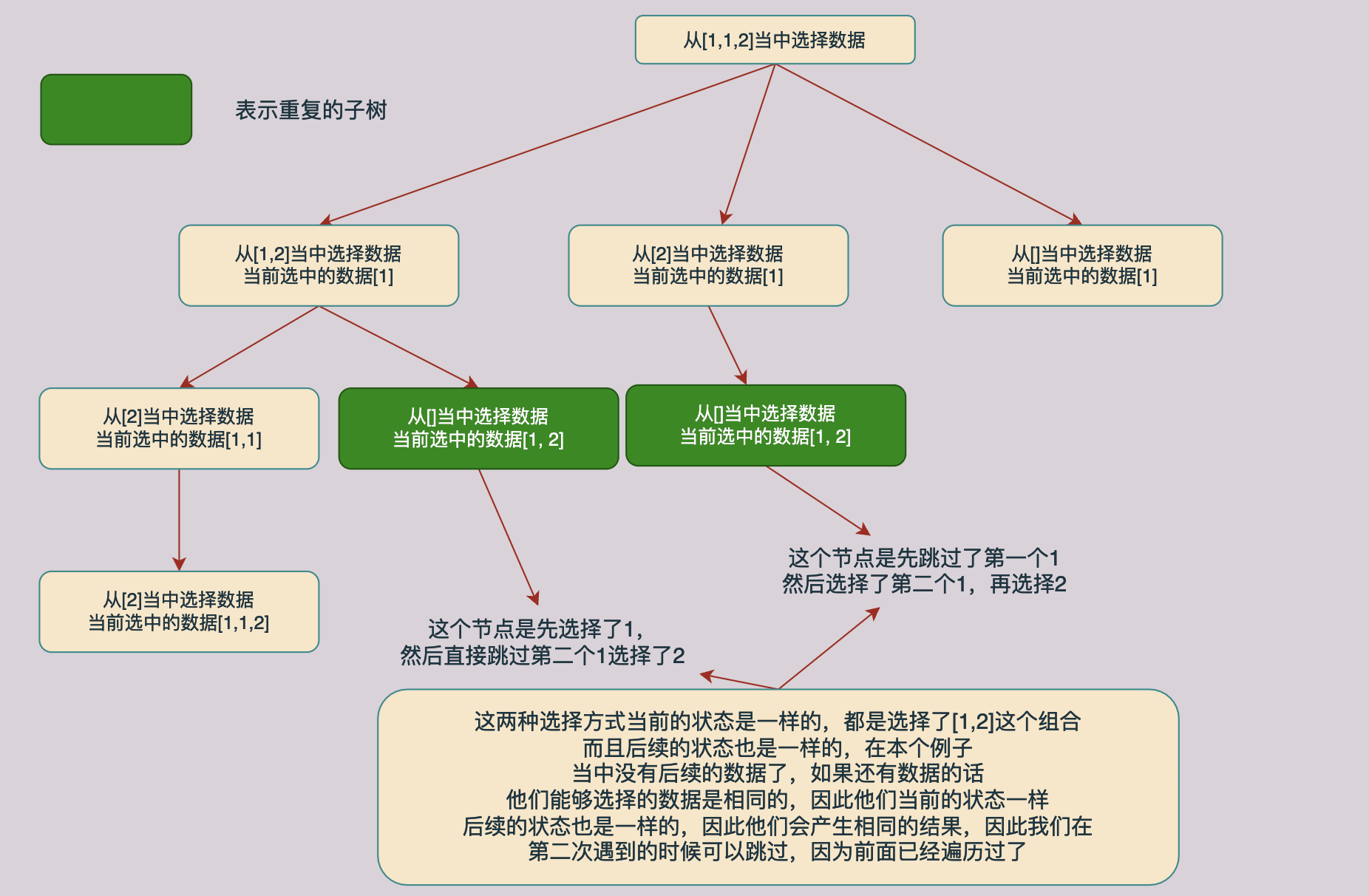
因此和第一種方法一樣,我們也需要一個used陣列去儲存資料是否被存取過,但是在這個方法當中我們還可以根據遍歷時候下標去實現這一點,因此不需要used陣列了,程式碼如下所示:
Java程式碼
class Solution {
private List<List<Integer>> res = new ArrayList<>();
private ArrayList<Integer> path = new ArrayList<>();
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);
backtrace(candidates, target, 0, 0);
return res;
}
public void backtrace(int[] candidates, int target, int curSum,
int curPosition) {
if (curSum == target) // 達到條件則儲存結果然後返回
res.add(new ArrayList<>(path));
for (int i = curPosition;
i < candidates.length && curSum + candidates[i] <= target;
i++) {
// 如果 i > curPosition 說明 i 對應的節點和 curPosition 對應的節點在同一層
// 如果 i == curPosition 說明 i 是某一層某個子樹的第一個節點
if (i > curPosition && candidates[i] == candidates[i - 1])
continue;
path.add(candidates[i]);
curSum += candidates[i];
backtrace(candidates, target, curSum, i + 1);
// 進行回溯操作
path.remove(path.size() - 1);
curSum -= candidates[i];
}
}
}
C++程式碼
class Solution {
vector<vector<int>> ans;
vector<int> path;
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
backtrace(candidates, target, 0, 0);
return ans;
}
void backtrace(vector<int>& candidates, int target, int curIdx, int curSum) {
if (curSum == target) {
ans.push_back(path);
return;
} else if (curSum > target || curIdx >= candidates.size()) {
return;
}
for(int i = curIdx; i < candidates.size() && curSum + candidates[i] <= target; ++i) {
if (i > curIdx && candidates[i] == candidates[i - 1])
continue;
path.push_back(candidates[i]);
backtrace(candidates, target, i + 1, curSum + candidates[i]);
path.pop_back();
}
}
};
總結
在本篇文章當中主要給大家介紹了組合問題II,這個問題如果仔細進行分析的話會發現裡面還是有很多很有意思的細節的,可能需要大家仔細進行思考才能夠領悟其中的精妙之處,尤其是兩種方法如何處理重複資料結果的情況。
以上就是本篇文章的所有內容了,我是LeHung,我們下期再見!!!更多精彩內容合集可存取專案:https://github.com/Chang-LeHung/CSCore
關注公眾號:一無是處的研究僧,瞭解更多計算機(Java、Python、計算機系統基礎、演演算法與資料結構)知識。