利用Kafka的Assign模式實現超大群組(10萬+)訊息推播
2022-09-22 15:01:57
引言
IM即時通訊場景下,最重要的一個能力就是推播:線上的直接通過長連線閘道器服務轉發,離線的通過APNS或者極光等系統進行推播。
本文主要是針對線上使用者推播場景來進行總結和探討:如何利用Kafka的Assign模式,解決百萬級長連結海量訊息的路由廣播問題?如何解決超大聊天室成員(超過10萬)的訊息推播問題?
問題背景
考慮到使用者體驗和一些技術限制,通常一些社交軟體都會限制群成員的上限,比如微信是500,QQ是2000。但是某些特定的場景下,希望突破這個上限,需要怎麼實現呢?
如下圖,這是一個遊戲社交類App,傳統的群被重新定義成了房間(有點類似直播聊天室),你可以不加入房間,僅接收訊息。如果需要發言,就必須加入房間,後續邏輯和玩法就和QQ類似了。
那麼,這種超過 10 萬成員的房間(或者叫聊天群)的實時訊息推播要怎麼實現呢?
接下來,暫且拋開儲存、分散式ID生成等等不談,我們只從長連線閘道器層面來看看都有哪些可能的問題和挑戰。
問題分解
這個裡面,主要有3個問題。
1)長連線閘道器要支援10萬+使用者線上
這個問題好解決,使用epoll i/o複用模型即可單機輕鬆支援1-10萬並行,取中位數5萬計算。支援10萬+使用者只需要部署2-3個節點即可。
另外,go在linux下就是封裝了epoll模型實現的網路通訊,按照peer connection peer go routine的指導思想,很容易就能開發出一個高效能的websocket長連線服務。這裡有一個範例:websocket example
2)群ID到成員列表的轉換
上游儲存訊息不管是寫擴散還是讀擴散,至少都應該是以groupId來儲存和查詢歷史訊息的。那麼在推播廣播給所有群成員的時候,勢必需要進行一次從group到群成員列表的查詢轉換。
考慮到成員可以動態加入或者退出,以及分散式下資料一致性的問題,可能最簡單做法就是每發一條訊息,從mysql查詢一次成員列表(頂多在redis中冗餘一下成員列表),然後再檢查哪些使用者線上,再把需要推播的userId列表發給長連線閘道器。
這裡的問題:每一次發訊息,都需要從mysql查群成員列表,很容易成為瓶頸。
所以,群和成員的關係需要下沉到長連線閘道器動態維護,來降低資料庫的查詢壓力,這一塊也不是什麼大問題。
3)長連線閘道器之間的路由通訊問題
閘道器叢集部署,然後群和成員的關係下沉到長連線閘道器處理。那麼,當一個房間的成員會分佈在多個閘道器節點上時,那麼一個使用者發訊息,就需要廣播給所有閘道器,閘道器再根據room-member關係進行轉發廣播才行。
所以,在該場景下,長連線閘道器之間的路由問題變成了瓶頸,我們來看一下能想到的解決方案。
解決方案
1)連線池
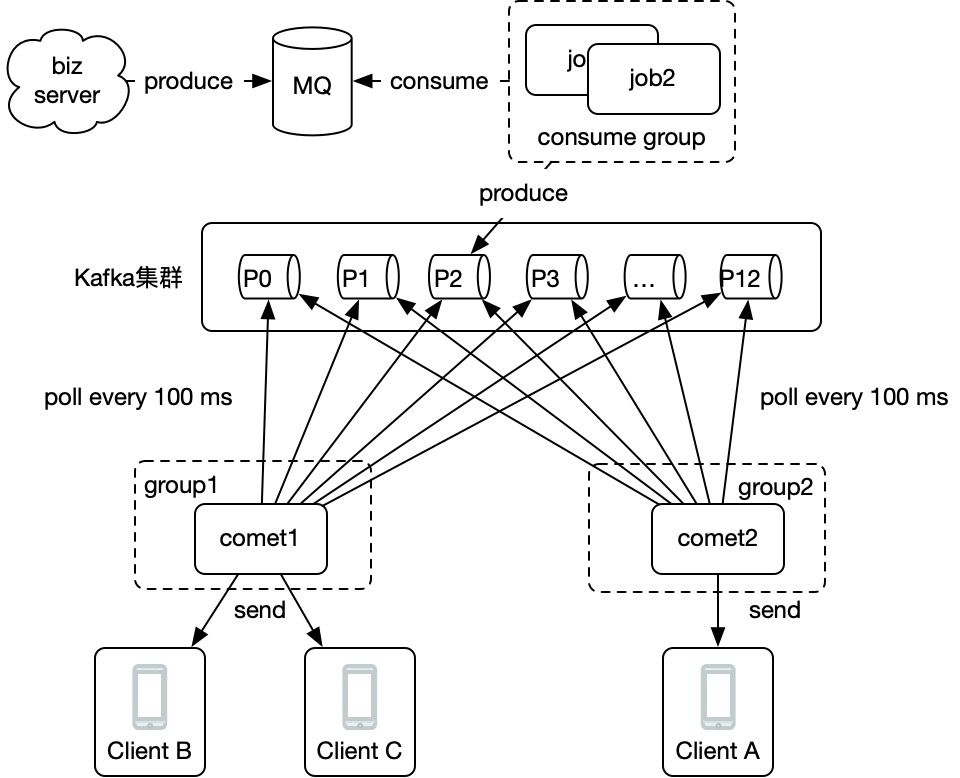
以 goim 舉例,goim是b站開源的一個能支援百萬級並行的聊天室伺服器端,它的架構如下:
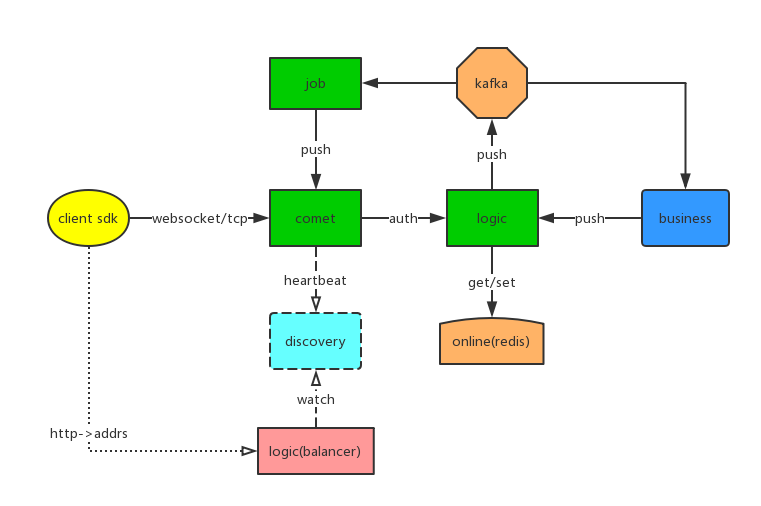
comet是websocket長連線閘道器,job和comet之間的通訊是本文所說的問題所在(多對多)。那麼它是怎麼實現的呢?
實際上,goim通過服務發現監聽了一個事件,每當有新的comet啟動就會觸發,從而建立和新的comet的grpc連線,流程示意如下圖:
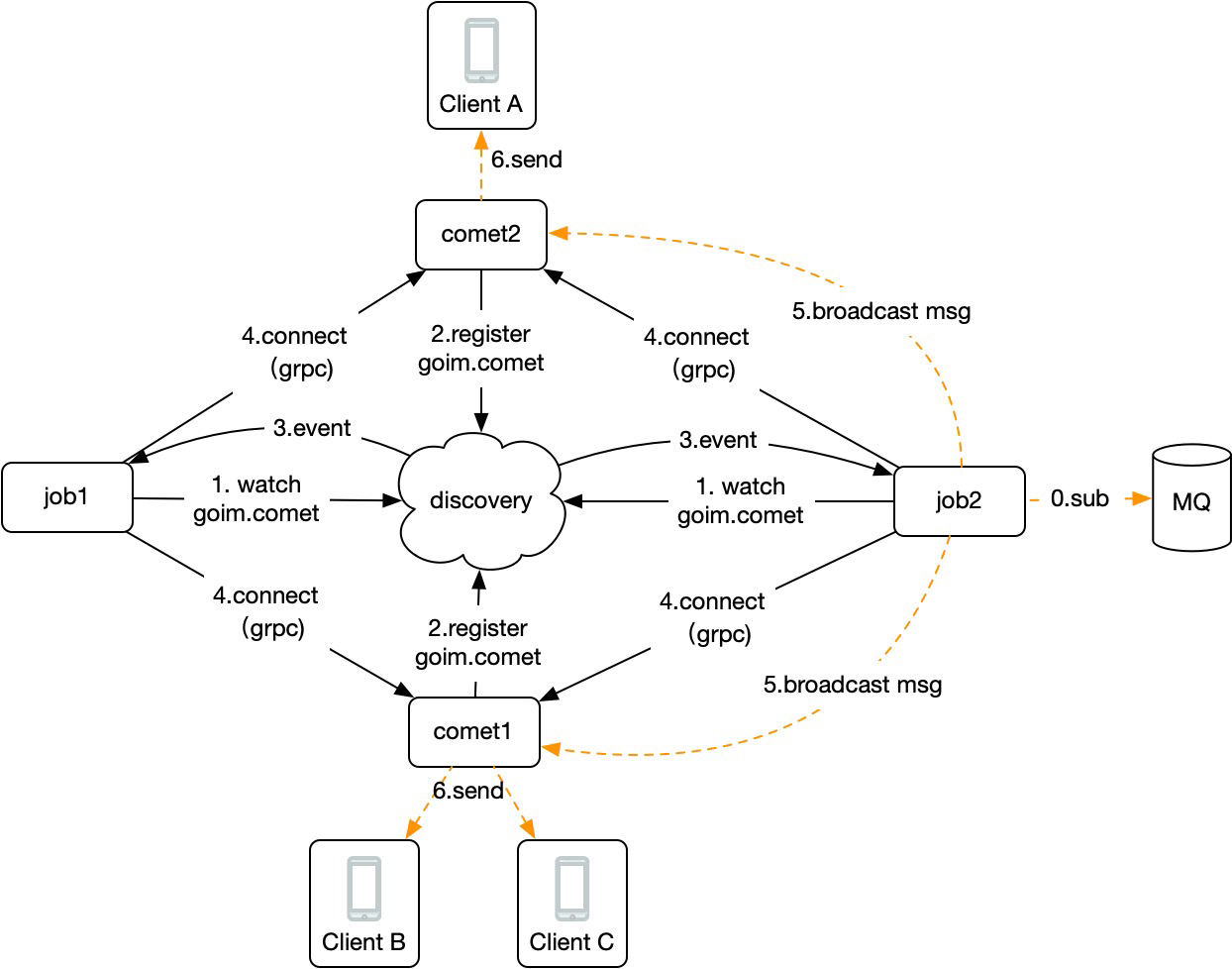
那麼,當上遊logic生產一條訊息到kafka時,consume group確保只有一個job能消費到該訊息,然後job通過本地維護的所有comet的連線進行便利傳送,達到廣播目的。
而comet本地也維護了room和user的關係,這樣一套流程下來,就解決了上述問題,實現了超大房間的成員訊息推播以及房間成員下沉到長連線閘道器管理。程式碼可以檢視:https://github.com/Terry-Mao/goim/blob/master/internal/job/job.go
PS:額外多說一句,TeamTalk開源專案中把p2p的連線提取成了router server,所有comet都連線到router server上,job需要廣播訊息直接發到router server即可。看起來更簡單,但是這很明顯就是有狀態的服務,要確保router server的可用性也需要額外花費很多精力,比如使用haproxy,自己做主從等等,各有利弊吧。
2)kafka實現
服務直連總是會涉及到連線的維護和管理,需要額外的開發成本。
另外,你仔細研究會發現這裡是推模型,那麼如果資料量足夠大,大到下游處理不過來,就會丟訊息(我猜測一般人應該遇不到這種場景,故也無需考慮)。
如果部署在不同機房,很可能還會遇到網路中斷或者延遲等問題,此時推模型就會丟很多訊息,所以,kafka作為巨量資料必備的組建,為什麼採用拉模型,我推測這可能是原因之一吧。
這裡介紹2種使用kafka 來實現廣播的目的的方案,相比goim的方案更簡潔,經過實踐,線上執行良好。
方式一:使用consumer group
《Kafka權威指南》對Consumer Group介紹的很細,我們可以不同consumer group可以重複消費的特性,建立對應數量的consumer group,裡面只啟動一個閘道器就能實現廣播的目的。
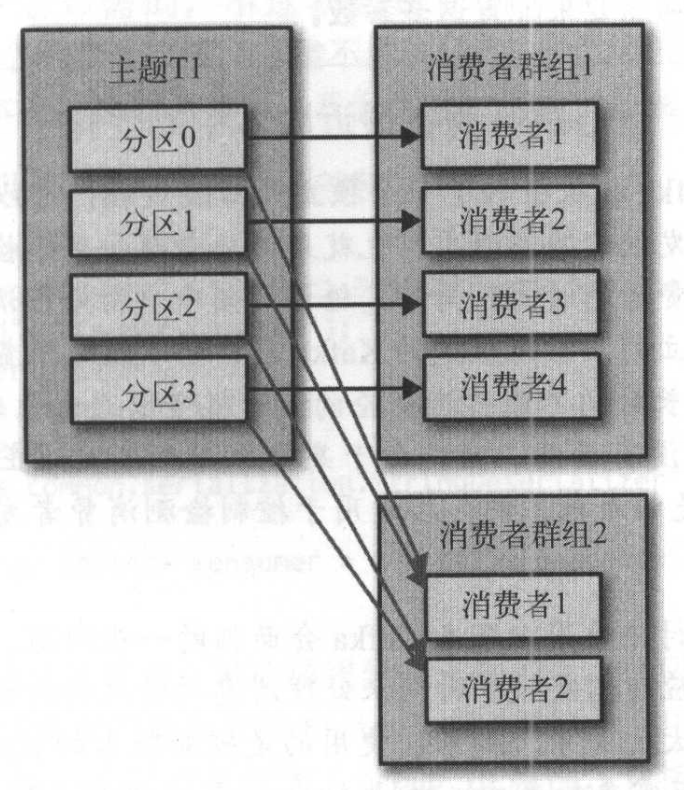
如下圖,我們讓每個消費組只有1個消費者就是我們要的模型:
看起來很好像是那麼回事對吧?
實際使用時,比如阿里雲就對consumer group的數量有限制:

這將導致,長連線閘道器不能動態指定consumer group的名字。所以,還需要開發一個服務,給閘道器分配可用的consumer group,這也是一個麻煩的地方。
方式二:使用assign,手動訂閱所有分割區,不使用consumer group
那麼能不能不指定consumer group,自己手動訂閱所有分割區消費所有訊息呢?答案是可以的!
看下圖:
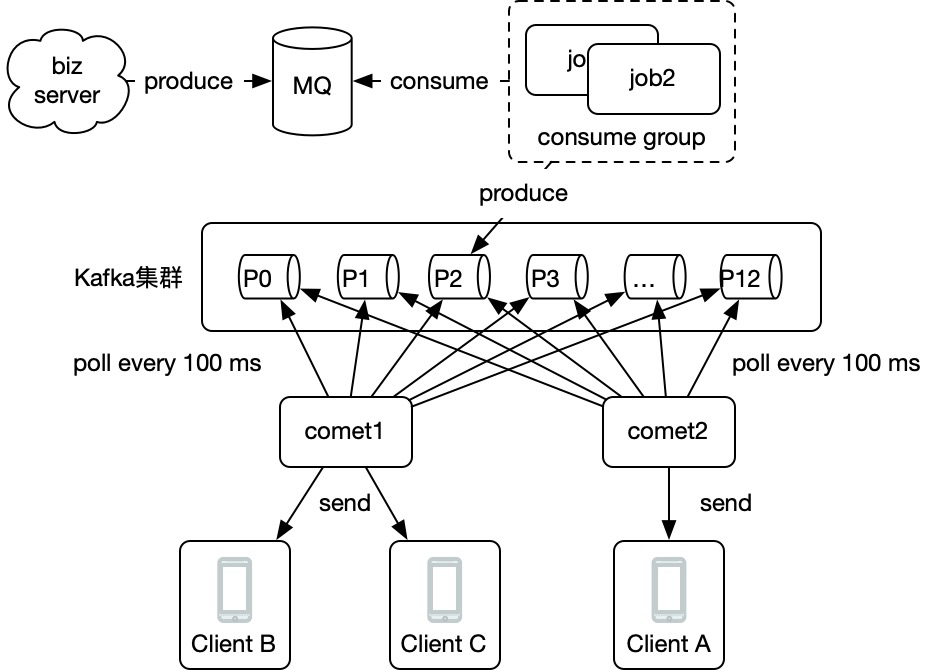
每個comet都訂閱所有broker上的所有partition,當上圖P2分割區生產一條訊息後,comet1和comet2都能拉取到,也就達到了廣播的目的。
consumer group vs assign模式
最後,總結一下2種模式實現廣播的優劣。
一個程序一個consumer group:
- 優點:分割區的管理通過group自動實現,不用考慮新分割區建立、新消費者加入等等情況。在kafka中還能很方便的看到每一個消費者的消費情況。
- 缺點:受限於雲產品的group數量限制,再加上k8s動態啟動容器,故需要開發額外的group name分配服務來動態分配提前建立好的group name。
使用assign自動手動訂閱所有分割區:
- 優點:不需要建立consumer group,簡單方便。
- 缺點:由於是程式自己管理分割區,故 kafka tools 等工具上看不到消費情況,訊息堆積情況等等。另外如果新增分割區,要麼重啟程式,要麼程式中定時拉取,kafka需要預先就估算建立好分割區數量,有一定難度。
到底使用consumer group還是assign手動訂閱,取決於你的場景。建議使用assign模式,根據業務估算並行,一次性建立好分割區數量。另外,一般情況下我們也很少會動態建立新的分割區,因為一旦如此,IM中的訊息亂序也會是一個問題。
Assign模式程式碼實現
assign模式由來
在java的client api中,KafkaConsumer類提供了2個方法:
- subscribe:為consumer自動分配partition,有內部演演算法保證topic-partition以最優的方式均勻分配給同group下的不同consumer
// Subscribe to the given list of topics to get dynamically assigned partitions. void subscribe(Collection<String> topics, ConsumerRebalanceListener listener)
- assign:為consumer手動、顯示的指定需要消費的topic-partitions,不受group.id限制,相當於指定的group無效(this method does not use the consumer's group management)
// Manually assign a list of partitions to this consumer. void assign(Collection<TopicPartition> partitions)
正常情況下,都是使用subscribe,這樣kafka client sdk會自動為我們均衡的分配分割區,當建立新的分割區或者有新的消費者加入時,rebanlance重均衡操作會進行重新分配,確保每個消費者分到恰當數量的分割區:
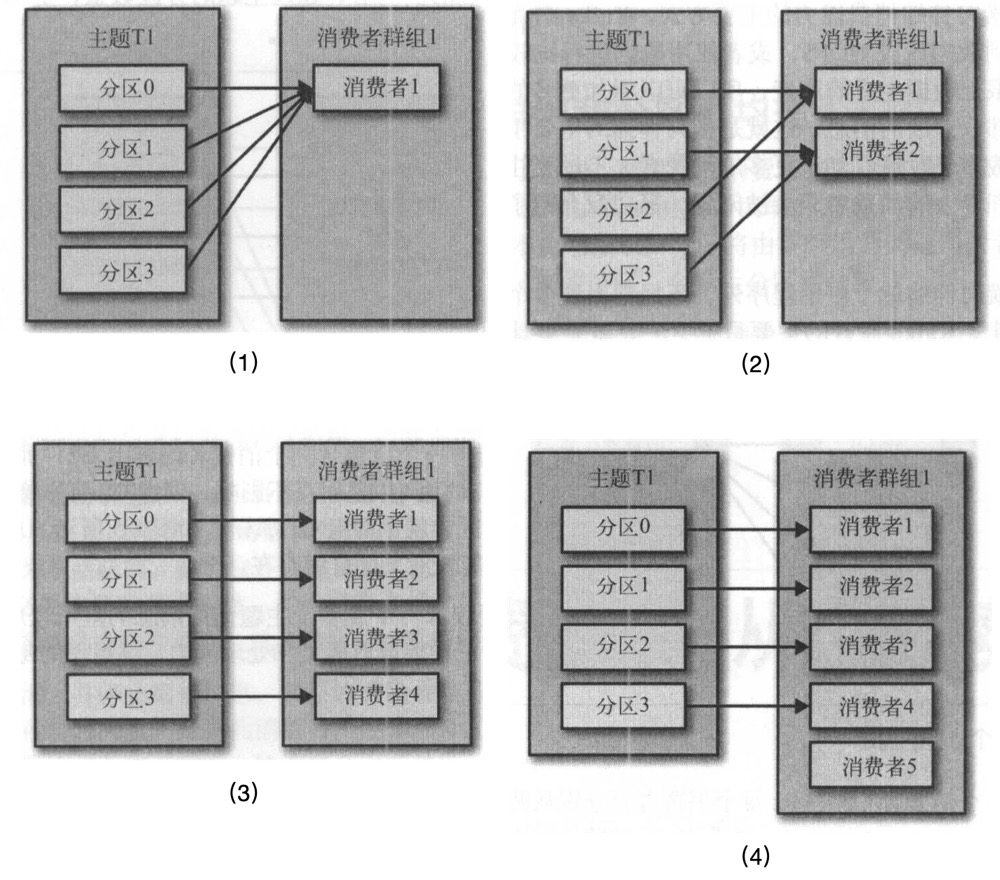
如果使用assign模式手動消費對應的分割區,也就沒有了上述的特性,如果分割區新建立了,需要手動處理。當啟動多個範例時,如果只希望消費某個topic一次,也需要自己管理控制哪些範例消費哪些分割區。當同一個服務的不同範例分配到一個分割區時,訊息將會被重複消費多次(請觀察上圖,同一個消費組下,一個partition同時只被一個範例消費,這也是實現消費一次的關鍵所在!!!)。
但是,這恰恰是我們需要的!就是要讓一個mq訊息,被所有長連線閘道器消費!
go中程式碼實現
所謂的assign模式是指java中的 KafkaConsumer.assign() 方法,在go中,如果你使用的是Sarama包,那就是對應 consumer.go,java的KafkaConsumer.subscribe() 方法對應go sarama包中的consumer_group.go。
所以,我們只需要啟動一個 Consumer ,然後消費指定分割區就能實現廣播的效果啦!
封裝一個consumer.go:
package main
import (
"context"
"sync"
"time"
"github.com/Shopify/sarama"
)
type ConsumerHandler func(partition int32, partitionConsumer sarama.PartitionConsumer, message *sarama.ConsumerMessage)
func NewConsumer(addrs []string, config *sarama.Config) (sarama.Consumer, error) {
if config == nil {
config = sarama.NewConfig()
// Aliyun kafka version 2.2.0
config.Version = sarama.V2_0_0_0
}
return sarama.NewConsumer(addrs, config)
}
// Consume start consume, will block until exit, call in `goroutine`
// note: `handle` called in `goroutine`
func Consume(ctx context.Context, consumer sarama.Consumer, topic string, handle ConsumerHandler) error {
defer consumer.Close()
// 獲取所有分割區
partitions, err := consumer.Partitions(topic)
if err != nil {
return err
}
// 消費所有分割區
waitGroup := sync.WaitGroup{}
for k, part := range partitions {
p, err := consumer.ConsumePartition(topic, part, sarama.OffsetNewest)
if err != nil {
return err
}
waitGroup.Add(1)
go func(partition int32, partitionConsumer sarama.PartitionConsumer) {
defer waitGroup.Done()
defer partitionConsumer.AsyncClose()
for {
select {
case <-ctx.Done():
return
case m := <-partitionConsumer.Messages():
handle(partition, partitionConsumer, m)
default:
time.Sleep(time.Millisecond)
}
}
}(int32(k), p)
}
waitGroup.Wait()
return nil
}
main.go中使用:
func main() {
// create and start consumer
consumer, err := NewConsumer(kafkaAddr, nil)
if err != nil {
panic(err)
}
for {
log.Println("consumer is running...")
// will block
err := Consume(context.Background(), consumer, topic, func(partition int32, partitionConsumer sarama.PartitionConsumer, message *sarama.ConsumerMessage) {
log.Println("consumer new mq, paritition=", partition, ",topic:", message.Topic, ",offset:", message.Offset)
})
if err != nil {
log.Println(err)
} else {
log.Println("consume exit")
}
time.Sleep(time.Second * 3)
}
}
producer程式碼:
func startProducer(addrs []string, topic string) {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true
producer, err := sarama.NewSyncProducer(addrs, config)
if err != nil {
panic(err)
}
for i := 0; i < 1000; i++ {
p, offset, err := producer.SendMessage(&sarama.ProducerMessage{
Key: sarama.StringEncoder(strconv.Itoa(i)),
Value: sarama.StringEncoder("hello" + strconv.Itoa(i)),
Topic: topic,
})
if err != nil {
log.Println(err)
} else {
log.Println("produce success, partition:", p, ",offset:", offset)
}
time.Sleep(time.Second)
}
log.Println("exit producer.")
}
效果如下:
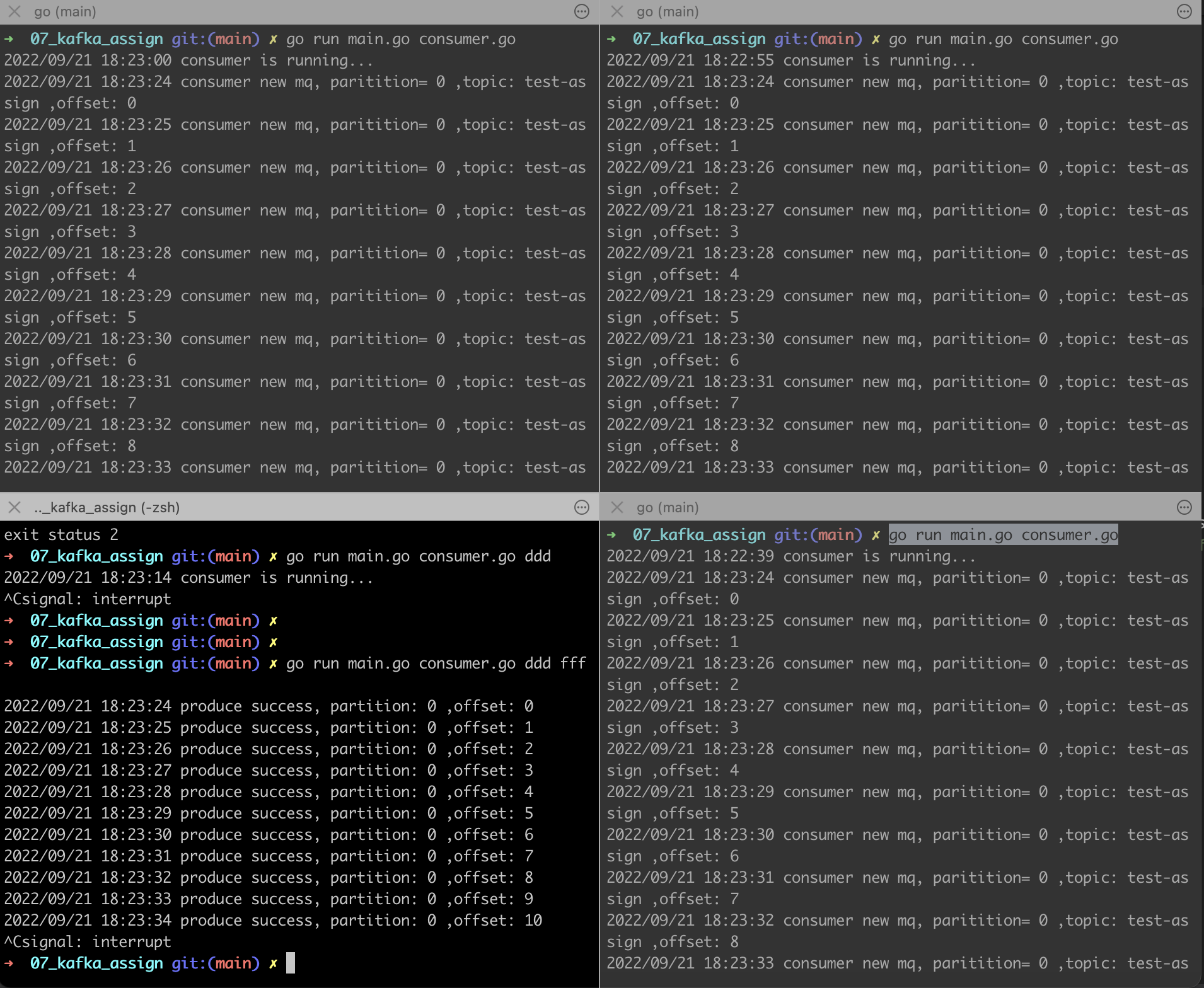
左下角是生產者,其他3個是消費者,我們看到都能消費到,達到了廣播的效果!
當然,kafka 上面看不到消費者的情況:
加餐:epoll和連線池的應用以及其侷限
1)單體效能
為了充分發揮單臺機器的效能,我們可以使用epoll I/O複用技術,來實現單機1-10萬的長連結並行線上支援。在該場景下,我們只需要維護好原生的連線和使用者關係即可,如下圖:
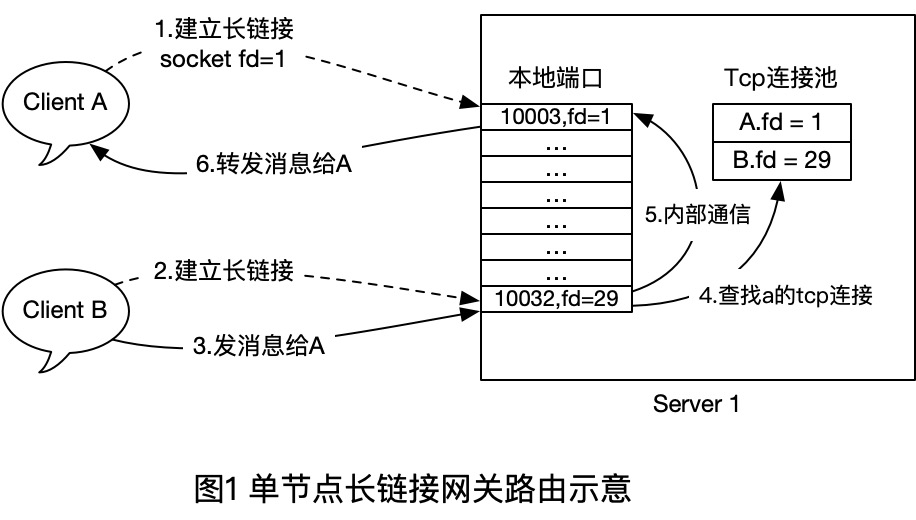
- 首先使用者端A和B都和Server1建立TCP長連線,建立時,Server1在記憶體中插入一條 `User - TcpConn` 的關係,斷開時,移除一個對應的關係。
- 當B 給 A發訊息時,伺服器端直接使用本地維護的路由表(連線池)來查詢對方的soket控制程式碼,然後Send()到對方的Tcp連線即可。
通過上面的一個流程,就完成了支援IM即時通訊場景中最基本的私聊功能,群聊也是類似,多了一層 `Group - User - TcpConn` 的轉換而已。
附:
這裡說的路由表就是一個 map而已,讀者不用糾結 `路由表` 字眼,明白其用途即可。
map[int64]tcp.Conn
2)水平擴充套件和資訊孤島
現在,假設我們要支援10萬用戶線上,單機按5萬最大使用者支援計算,那麼只需要部署2-3臺閘道器即可。
這個時候,有一個新的問題:A在Server1上,C在Server2上,他們之間要如何通訊(A和C無法發訊息聊天)?也就是說,Server之間要如何通訊?
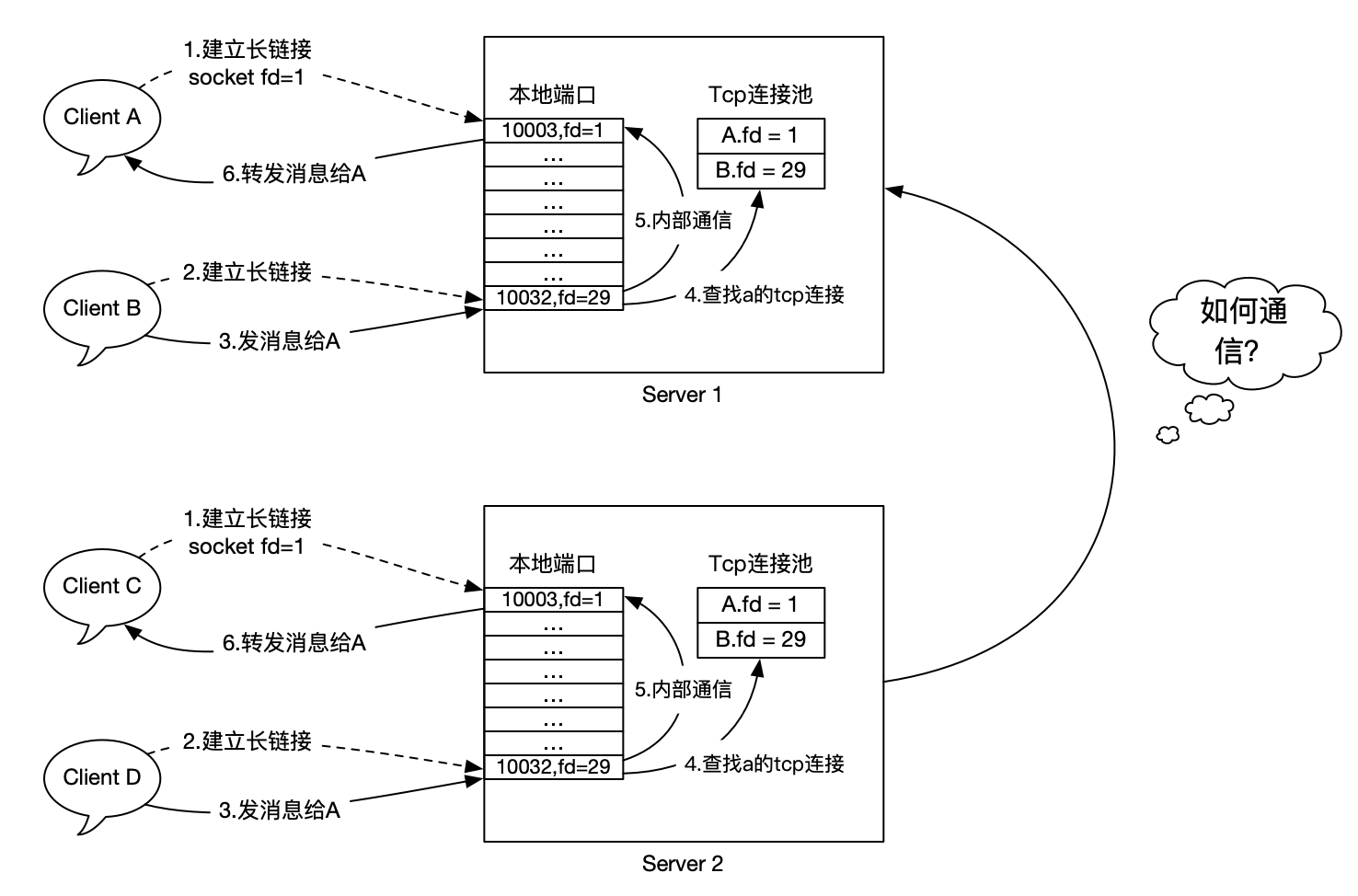
這個其實就是我們玩遊戲時候選擇的大區,一個大區和另外一個大群的使用者不能聊天,只能在一個服裡面玩,除非進行跨伺服器互通才行,那要如何實現呢?
大體有2個解決方案:
- 分散式路由表。在某個地方統一存放使用者登入的節點,推播的時候倒查即可。
- 服務廣播。給所有伺服器廣播訊息,那麼在該伺服器上的使用者自然也能收到。
上文主要是圍繞服務廣播來進行討論,分散式路由可以簡單理解為使用redis記錄使用者所在閘道器位置,然後動態查詢進行鍼對性的推播,不過細節較多,暫不討論。
總結
通過 Kafka Assign模式,我們能很方便的實現程序間廣播的效果,如果你已經再使用Kafka,又不想引入額外的服務發現元件或者是自行管理grpc連線,那麼將是一個很好的選擇!
Reference