JAVA中容器設計的進化史:從白盒到黑盒,再到躋身為設計模式之一的迭代器
大家好,又見面了。
在我們的專案編碼中,不可避免的會用到一些容器類,我們可以直接使用List、Map、Set、Array等型別。當然,為了體現業務層面的含義,我們也會根據實際需要自行封裝一些專門的Bean類,並在其中封裝集合資料來使用。
看下面的一個場景:
在一個企業級的研發專案事務管理系統裡面,包含很多的專案,每個專案下面又包含很多的具體需求,而每個需求下面又會被拆分出若干的具體事項。
上面的範例場景中,對應的資料結構邏輯可以用下圖來表示出來:
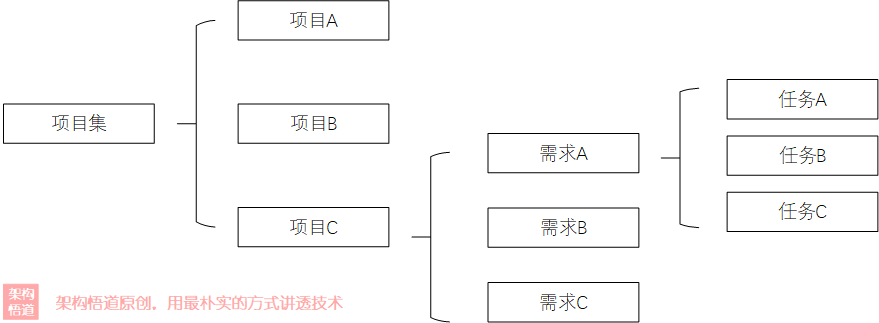
按照常規思路,我們會怎麼去建模呢?為了簡化描述,我們僅以專案--需求--任務這個維度來說明下。
首先肯定會去建立Project(專案)、Requirement(需求)、Task(任務)三個類,然後每個類中會包含一個子物件的集合。比如對於Project而言,會包含一個Requirement的集合:
@Data
public class Project {
private List<Requirement> requirements;
private int status;
private String projectName;
// ...
}
同樣道理,我們定義Requirement的時候,也會包含一個Task的集合:
@Data
public class Requirement {
private List<Task> tasks;
private int status;
private String requirementName;
private Date createTime;
private Date closeTime;
// ...
}
上述的例子中,Project、Requirement便是兩個典型的「容器」,容器中會儲存著若干具體的元素物件。對容器而言,遍歷容器內的元素是無法繞過的一個基本操作。
按照上面的容器物件定義實現,在業務邏輯程式碼中,需要獲取某個Project中所有已關閉的需求事項列表,並按照建立時間降序排列,我們要如何做:先從容器中取出所有的需求集合,然後自行對此需求集合進行過濾、排序等操作。
public List<Requirement> getAllClosedRequirements(Project project) {
return project.getRequirements().stream()
.filter(requirement -> requirement.getStatus() == 1)
.sorted((o1, o2) -> (int) (o2.getCreateTime().getTime() - o1.getCreateTime().getTime()))
.collect(Collectors.toList());
}
或者,也可能會寫成如下更為通俗的處理邏輯:
public List<Requirement> getAllClosedRequirements(Project project) {
List<Requirement> requirements = project.getRequirements();
List<Requirement> resultList = new ArrayList<>();
for (Requirement requirement : requirements) {
if (requirement.getStatus() == 1) {
resultList.add(requirement);
}
}
resultList.sort((o1, o2) -> (int) (o2.getCreateTime().getTime() - o1.getCreateTime().getTime()));
return resultList;
}
很司空見慣的邏輯,的確也沒有什麼問題。但是,其實我們僅僅只是需要遍歷容器中所有的元素,然後找出符合需要的內容,而Project類通過getRequirements()方法將整個內部儲存List物件給出來讓呼叫方直接去操作,存在一定的弊端:
-
呼叫方通過
project.getRequirements()方法獲取到專案下全部的需求列表的List儲存物件,然後便可以對List中的元素進行任意的處理,比如新增元素、刪除元素甚至是清空List,從可靠性角度而言,我們其實並不希望任何呼叫方都可以去隨意操作所有內容,不確定性太大、難以維護。 -
某些允許呼叫方進行遍歷並刪除元素的場景,容器直接通過
project.getRequirements()給出具體的集合物件,然後任由呼叫方自行遍歷並刪除,一些呼叫方可能會處理的不夠完善,容易踩坑,存在隱患。可以參見我之前一篇檔案《JAVA中簡單的for迴圈竟有這麼多坑,你踩過嗎》裡的詳細說明。
進一步思考下,其實我們只是想要遍歷獲取到容器中的元素,是否有更優雅的方式能夠實現這一簡單訴求,並且還能順帶解決上述這幾個小遺憾呢?
帶著疑問,我們一起來梳理下容器的演進歷程,聊聊作為一個容器應該具備怎樣的自我修養吧。

最直白的白盒容器
如上文中所提供的例子場景。範例中直接通過get方法將容器內管理的元素集合給暴露出去,任由呼叫方自行去處理使用。呼叫端需要知道這是一個元素集合是一個List型別還是一個Map型別,然後再根據不同型別,決定應該如何去遍歷其中的元素,去對其中的元素進行操作。

白盒容器是一個典型的甩手掌櫃式的容器,因為它要做的事情非常簡單:給個get方法即可!任何呼叫方都可以直接獲取到容器內部的真正元素儲存集合,然後自行去對集合做各種操作,而容器則完全不管。
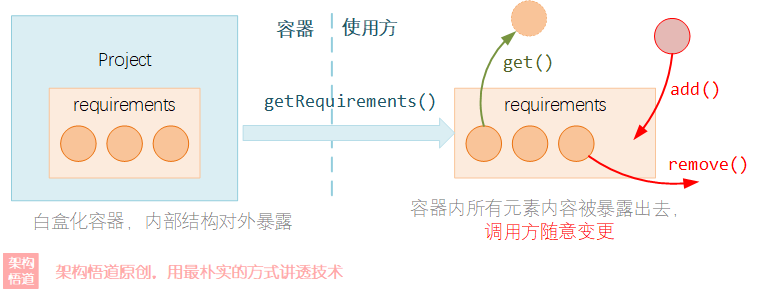
這樣有一定的優勢:
-
呼叫方限制較小,可以按照自己訴求隨意發揮,實現自己各種訴求
-
容器實現簡單,容器與業務解耦,就是個純粹的容器,不夾雜任何的業務邏輯
但是呢,原本我們只是想遍歷下容器中所有的元素內容,但是容器卻直接將整個家底都交了出來。這就好比小王去小李家想看看小李家的豬裡面有幾隻是母豬,而小李直接將豬圈丟給了小王,讓小王自己進豬圈去數一樣,這也太不把小王當外人了不是,誰知道小王進去是不是僅僅只是去數了下有幾隻母豬呢?
由此帶來的弊端也就很明顯了:
- 將容器內部的結構完全暴露給外部,業務邏輯中耦合了容器的具體實現細節,後面如果容器需要改造的時候,會導致業務呼叫邏輯必須跟著改動,影響較大,牽一髮動全身。
舉個簡單的例子:
當前Project中採用List來儲存專案下所有的需求資料,而所有的呼叫端都是按照List的格式來處理需求資料。如果現在需要將Project中改為使用Map來儲存需求資料,則原先所有通過project.getRequirements()獲取需求資料的地方,都需要配套修改。
- 對容器內資料的管控力太弱。容器將資料全盤給出,任由呼叫方隨意的去新增、刪除元素、甚至是清空元素集合,而容器卻無法對其進行約束。
還是上面的例子:
業務呼叫方使用project.getRequirements()拿到List物件後,便可以對List進行add、remove、clear等各種操作。而很多時候,我們是需要保證對元素的內容的變更或者增減都在統一的地方去實行,這樣可以保證資料的準確、也可以做一些統一處理,比如統一記錄建立需求的紀錄檔之類的。而寫操作入口變得不確定,使得整個資料的維護就存在很大的漏洞。
白盒向黑盒的演進
既然甩手掌櫃式的白盒容器有著種種弊端,那麼我們將其變為一個黑盒容器,不允許將內部的元素集合和盤托出,這樣的話,不就解決上述所有的問題了嗎?這個思路是正確的,但是對於一個黑盒容器來說,又該如何讓呼叫端能實現對內部託管的元素的逐個遍歷獲取呢?
回答這個問題前,我們先來想一個問題:我們對List或者Array是怎麼遍歷的?可以通過記錄下標的方式,按照下標所示的位置去逐個獲取下標對應位置的元素,然後將下標往後移動,再去讀取下一個位置的元素,一直到最後一個。對應程式碼我們再熟悉不過了:
public void dealWithRequirements(Project project) {
List<Requirement> requirements = project.getRequirements();
for (int i = 0; i < requirements.size(); i++) {
// ...
}
}
上述處理邏輯中,有兩個關鍵的資料對遍歷的動作起著決定作用。一個是下標索引i,用來標記當前遍歷到的元素位置;另一個則是集合的總長度,決定著遍歷操作是繼續還是終止。

回到當前討論的黑盒容器中,如果呼叫方拿不到集合自己去遍歷,就需要我們在黑盒容器中代替呼叫方將上述迴圈邏輯給自行實現。那麼容器自身就需要知曉並記錄當前遍歷到哪個元素下標位置(也可以將其稱為遊標位置)。而同樣由於黑盒的原因,容器內元素集合的總元素個數、當前遍歷到的下標位置等資訊,都在黑盒內部,呼叫方無法知曉,那就需要容器給個介面,告訴呼叫方是否已經遍歷完了(是否還有元素沒遍歷的)
等等,越說這玩意就越覺得眼熟有木有?這不就是一個迭代器(Iterator)嗎?
不錯,對一個黑盒容器而言,迭代器可以完美實現對其內部元素的遍歷訴求,且不會暴露容器內部的資料結構。迭代器的兩個關鍵方法:
- hasNext()
告訴呼叫方是否還有元素可以繼續遍歷,如果沒有了,則遍歷結束,否則繼續遍歷。
- next()
獲取一個新的元素內容。
這樣,對於呼叫方而言,無需關注到底容器內部是怎麼儲存集合資料的,也無需知道到底有多少個集合元素,只需要使用這兩個方法,便可以輕鬆完成遍歷。
我們按照迭代器的思路,對Project類進行黑盒化改造,如下:
public class Project {
private List<Requirement> requirements;
// ...
private int cursor;
public boolean hasNext() {
return cursor < requirements.size();
}
public Requirement next() {
return requirements.get(cursor++);
}
}
接著,業務方可以按照下面的方式去遍歷:
public void dealWithIterator(Project project) {
while (project.hasNext()) {
Requirement requirement = project.next();
// ...
}
}
這樣的話,在Project內部List型別的requirements物件沒有暴露給呼叫方的情況下,依舊可以完成對Project中所有的Requirement元素的遍歷處理,也自然就不用擔心呼叫方會對集合進行元素新增或者刪除操作了。此外,後續如果有需要,可以方便地將Project當前內部使用的List型別變更為需要的其它型別,比如Array或者Set等,而不用擔心需要同步修改所有外部的呼叫方處理邏輯。
黑盒往迭代器的跨越
黑盒容器的出現,有效的增強了容器內部資料結構的隱藏,但是容器也需要自己去實現對應的元素遍歷邏輯提供給呼叫方使用。
還是以上面的Project類的實現為例,除了當前支援的正序遍歷邏輯,若現在還需要提供一個倒序遍歷的邏輯,那麼應該怎麼辦呢?
似乎也沒那麼難回答,再增加個遍歷邏輯就好了嘛。很快,程式碼就改好了:
public class Project {
private List<Requirement> requirements;
// ...
private int cursor;
private int reverseCursor = Integer.MIN;
public boolean hasNext() {
return cursor < requirements.size();
}
public Requirement next() {
return requirements.get(cursor++);
}
public boolean reverseHasNext() {
if (reverseCursor == Integer.MIN) {
reserseCursor = requirements.size() - 1;
}
return reverseCursor >= 0;
}
public requirement reverseNext() {
return requirements.get(reverseCursor--);
}
}
如果需要正序遍歷,就hasNext()與next()兩個方法結合使用,而通過reverseHasNext()與reverseNext()組合使用便可以實現逆序遍歷。
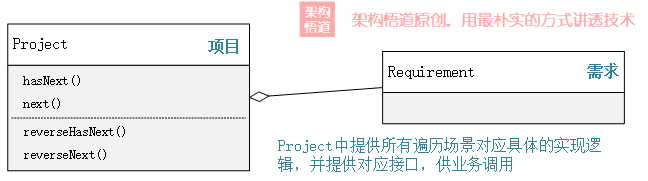
回頭再來看下Project類,作為一個容器,它似乎又變得不那麼純粹了。試想一下,如果後面再有新的訴求,除了需要正序遍歷、逆序遍歷之外,還需要僅遍歷偶數位置的元素,我們是不是還得再在容器中增加兩個新的方法?
我們說白盒容器是一個純粹的容器、但是存在一些明顯弊端,而黑盒容器解決了白盒容器的一些資料隱藏與管控方便的問題,卻又讓自己變得冗脹、變得不再純粹了。應該如何選擇呢?
話說,小孩子才要做選擇,成年人總是貪婪地全要!如何才能既保持一個容器本身的純粹、又可以實現內部資料的隱藏與管控呢? —— 將遍歷的邏輯外包出去唄!這裡的外包員工就要登場了,它便是我們姍姍來遲的主角:迭代器。
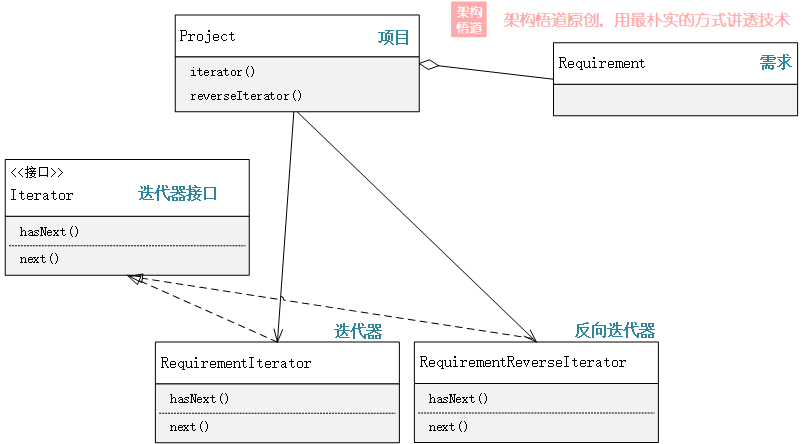
繼續前面的場景,我們可以將正序遍歷、逆序遍歷封裝為2個不同的迭代器,都實現相同的Iterator介面。
- 正序遍歷
public class RequirementIterator implements Iterator<Requirement> {
private List<Requirement> requirements;
private int cursor;
public RequirementIterator(List<T> requirements) {
this.requirements = requirements;
this.cursor = 0;
}
@Override
public boolean hasNext() {
return this.cursor < this.requirements.size();
}
@Override
public Requirement next() {
return this.requirements.get(cursor++);
}
}
- 逆序遍歷
public class ReverseRequirementIterator implements Iterator<Requirement> {
private List<Requirement> requirements;
private int cursor;
public ReverseRequirementIterator(List<T> requirements) {
this.requirements = requirements;
this.cursor = requirements.size() - 1;
}
@Override
public boolean hasNext() {
return this.cursor > 0;
}
@Override
public Requirement next() {
return this.requirements.get(cursor--);
}
}
在容器裡,提供不同的迭代器獲取操作,將迭代器提供給呼叫方即可。
public class Project {
private List<Requirement> requirements;
public RequirementIterator iterator() {
return new RequirementIterator(this.requirements);
}
public ReverseRequirementIterator reverseIterator() {
return new ReverseRequirementIterator(this.requirements);
}
}
這樣,我們便完成了將具體的遍歷邏輯從容器中剝離「外包」給第三方來實現了。
呼叫方使用時候,直接向容器獲取對應的迭代器,然後直接用迭代器提供的固定的hasNext()以及next()方法進行遍歷即可。選擇使用哪種迭代器,便可以按照此迭代器提供的遍歷邏輯進行遍歷,業務無需關注與區分。
比如需要按照逆序遍歷元素並進行處理的時候,我們就可以這樣來呼叫:
public void dealWithIterator(Project project) {
ReverseIterator reverseIterator = project.reverseIterator();
while (reverseIterator.hasNext()) {
Requirement requirement = reverseIterator.next();
// ...
}
}
按照上面的實現策略:
-
對呼叫方而言,只需要保證
Iterator介面不變即可,根本不關注Project容器內部的結構或者具體遍歷邏輯實現細節; -
對容器而言,內部的實際儲存邏輯完全
private私有,有效的控制了外部對其內容的隨意增刪、也降低了與外部耦合,後續想修改或者變更的時候只需要配合修改下迭代器實現即可。 -
對迭代器而言,承載了容器中剝離的遍歷邏輯,保持了容器的純粹性,自身也只需要實現特定的能力介面,使自己成為了容器的合格搭檔。
更安全的遍歷並刪除操作
將容器變為黑盒,並藉由「第三方」迭代器來專門提供容器內元素的遍歷策略,除了程式碼層面更為清晰獨立,還有一個很重要的原因,就是可以在迭代器裡面進行一些增強處理操作,這樣可以保證容器的遍歷動作不會因為容器內元素出現變更而導致異常,使得程式碼更加的穩健。
以最常見的ArrayList為例,在我之前的檔案《JAVA中簡單的for迴圈竟有這麼多坑,你踩過嗎》裡,有專門講過這方面的一個處理。比如在遍歷並且刪除元素的場景,如果由使用方自行去遍歷且在遍歷過程中執行刪除操作,可能會出現異常報錯或者是結果與預期不符的情況。而使用ArrayList提供的迭代器去執行此操作,就不會有任何問題。為什麼呢?因為ArrayList的迭代器裡面已經對此操作邏輯做了充足的支援,可以保證呼叫方無感知的情況下安全的執行。
看下ArrayList的Iterator中提供的next方法是怎麼做的。首先是remove操作中增加了一些額外處理,在remove掉list本身的元素之後,也順便的更新了下輔助維護引數:
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
而在執行next()操作的時候,也會先通過checkForComodification()執行校驗,確保資料是符合預期的情況下才會進一步的執行後續邏輯:
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
而上述的邏輯,對於呼叫方而言是感知不到的 —— 實際上也無需去感知、但是卻可以保證他們獲取到想要的效果。
設計模式中的一席之地 —— 迭代器模式
編碼工作一向都是個逐步改進優化的過程。開始的時候,我們主要面向我們當前的訴求進行編碼實現;到後面遇到一些類似場景或者關聯場景訴求的時候,就會需要我們去對原先的程式碼做變更、做擴充套件、或者是修改並使其可複用。針對不同應用場景,一些良好的實現策略,經過長期的實踐驗證後脫穎而出,併成為了大家普遍認同的優秀實踐。也便是軟體開發設計中所謂的「設計模式」。
在23種設計模式中,迭代器模式作為其中的行為型設計模式之一,也算是一種比較常見且比較古老的模式了。其對應的實現UML類圖如下所示:
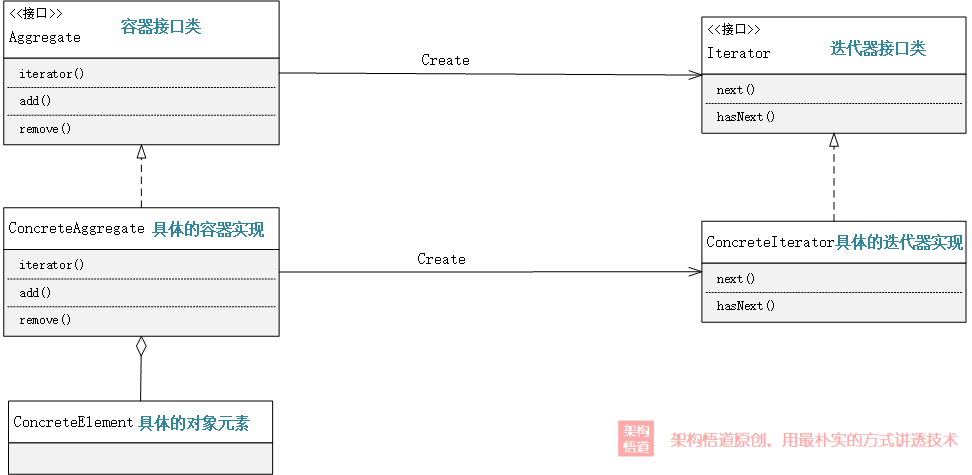
相比於上一章節中我們針對具體的Project客製化實現的迭代器,這裡衍生出來的迭代器設計模式,更加註重的是後續的可複用、可延伸 —— 這也是設計模式存在的意義之一,設計模式永遠不是面向與解決某一個具體問題,而是面向某一類場景,關注讓這一類場景都按照統一的策略實施,以支援相同的能力、更好的複用性、更靈活的擴充套件性。
原始碼中無處不在的迭代器
迭代器作為容器元素遍歷的得力幫手,幾乎成了JDK中各種容器類的標配,像大家比較熟悉的ArrayList、HashMap中的EntrySet等都提供了配套的Iterator實現類,基於Iterator類,可以實現對元素的逐個遍歷。
下面可以看幾個JDK原始碼或者其他優秀框架原始碼中的迭代器應用實踐。
JDK中的迭代器
JDK中定義了一個Iterator介面,一些常見的集合類都有提供實現Iterator的具體迭代器實現類,來提供迭代遍歷的能力。
先看下Iterator介面類的定義:
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
其中hasNext()與remove()是最長被使用的,也是具體迭代器實現類必須要自行實現的方法。如果一些場景需要支援迭代過程中刪除元素,則可以選擇實現remove()方法,而對於Java8之後的場景,也可通過實現forEachRemaining()方法,來支援傳入一個函數式介面的方式來對每個元素進行處理,可以簡化我們的編碼。
按照前面章節我們的描述,一個容器雷伊根據不同的遍歷訴求,提供多種不同的迭代器。這一點在JDK原始碼的各集合類中也普遍被使用。還是以ArrayList為例,作為編碼中最常使用的一種集合類,ArrayList也提供了多個不同的Iterator實現類,可以實現對List中元素的遍歷操作的差異化訴求。
比如原始碼中我們可以看到其提供了兩個獲取迭代器的方法:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// ...
public Iterator<E> iterator() {
return new Itr();
}
public ListIterator<E> listIterator() {
return new ListItr(0);
}
}
其中ListIterator介面是繼承自Iterator介面的子介面,相比於Iterator介面,提供了更為豐富的能力、不僅支援讀取、也支援寫操作,還支援向前向後遍歷:
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
void set(E e);
void add(E e);
}
實際使用中,呼叫方可以根據自身的訴求,決定具體應該使用ArrayList提供的哪一種迭代器,可以大大降低呼叫方的使用成本。
迭代器在資料庫操作中的身影
在專案中,經常會遇到一些場景,需要我們將資料庫表中全量資料讀取到記憶體中並進行一些處理。比如需要將DB資料重新構建ES索引的時候,我們需要逐條處理DB記錄,然後將其寫入到ES中進行索引儲存以方便後續搜尋。如果表中資料量特別大,比如有1000萬條記錄的時候,逐條去資料庫查詢的方式速度太慢、全量載入到記憶體中又容易撐爆記憶體,這個時候就會涉及到批次獲取的場景。
在批次獲取的場景中,往往會涉及到一個概念,叫做遊標。而我們本文中提到的迭代器設計模式,很多場景中也有人稱之為遊標模式。藉助遊標,我們也可以將DB當做一個黑盒,然後對其元素進行遍歷獲取。JAVA中的資料庫操作框架很多,SpringData JPA作為SpringData家族中用於關係型資料庫處理的一個封裝框架,可以極大簡化開發編碼過程中對於簡單資料庫操作的編碼。
先看下實際使用SpringData JPA進行表資料載入到ES的處理邏輯:
private <F> void fullLoadToEs() {
try {
long totalLoadedCount = 0L;
Pageable pageable = PageRequest.of(0, 1000);
do {
Slice<F> entitySilce = repository.findAll(pageable);
List<F> contents = entitySilce.getContent();
// do something here...
if (!entitySilce.hasNext()) {
break;
}
pageable = entitySilce.nextPageable();
} while (true);
} catch (Exception e) {
log.error("error occurred when load data into es", e);
}
}
其實和前面介紹的迭代器使用邏輯很相似,通過hasNext()判斷是否還有剩餘的資料待獲取,如果有則nextPageable()可以獲取到下一個分頁查詢條件,然後拿著新的分頁條件,去載入下一個的資料。
可以看下Slice類的原始碼UML類圖:

會發現其實現了個Iterable介面,此介面定義原始碼如下:
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
可以發現,其最終也是要求實現類對外提供具體的迭代器實現類,也即最終也是基於迭代器的模式,來實現對DB中資料的遍歷獲取。
總結回顧
好啦,關於容器設計的相關探討與思路分享,這裡就給大家介紹到這裡了。適當的場景中使用迭代器可以讓我們的程式碼在滿足業務功能訴求的同時更具可維護性,是我們實現容器類的時候的一個好幫手。那麼,你對迭代器的使用有什麼自己的看法或者觀點嗎?你在專案中有使用過迭代器嗎?歡迎大家留言一起探討交流下。
我是悟道,聊技術、又不僅僅聊技術~
如果覺得有用,請點贊 + 關注讓我感受到您的支援。也可以關注下我的公眾號【架構悟道】,獲取更及時的更新。
期待與你一起探討,一起成長為更好的自己。

本文來自部落格園,作者:架構悟道,歡迎關注公眾號[架構悟道]持續獲取更多幹貨,轉載請註明原文連結:https://www.cnblogs.com/softwarearch/p/16718935.html