Elasticsearch6.2伺服器升配後的bug
本篇文章記錄最近一次生產伺服器硬體升級之後引起叢集不穩定的現象,希望可以幫到有其它人避免採坑。
一、問題描述
升級後出現的異常如下:
- 出現限流紀錄檔:stop throttling indexing: numMergesInFlight=8, maxNumMerges=9
- 應用寫入叢集的rt耗時變高,同時叢集監控的indexing的時長也變高
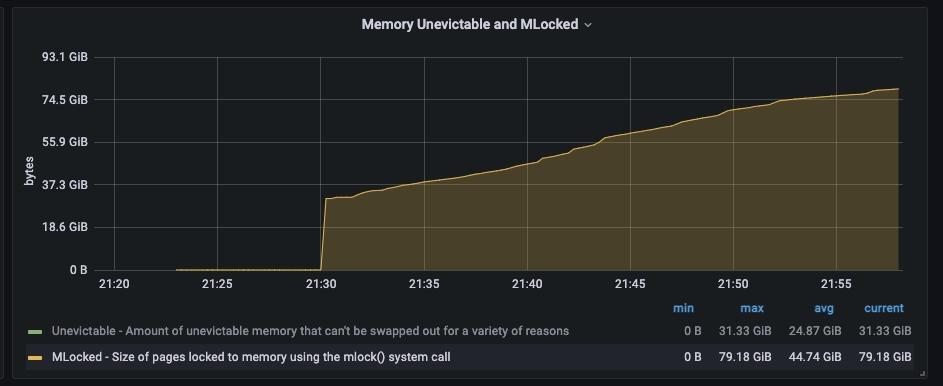
- mlocked的記憶體呼叫一直在增長
二、升級過程
升配前
ES version:6.2.4
設定:32C64G
環境:阿里雲ecs自建
gc:cms
jvm:30GB
升配後
ES version:6.2.4
設定:64C128G
環境:阿里雲ecs自建
gc:cms
jvm:30GB
三、處理步驟
升配之後第二天首先應用表現出異常,寫入ES的耗時變高了好十幾倍,從40ms上升到600ms;升配導致叢集變慢還是頭一次遇到。通過對叢集監控分析叢集整體負載正常比升配之前有所下降,但是indexing的寫入耗時監控確實比升配之前增長了很多。在ES的輸出紀錄檔中出現了異常紀錄檔"stop throttling indexing: numMergesInFlight=8, maxNumMerges=9";
1.限流處理
當時懷疑應該是這個限流導致,ES的限流的主要目的是出於對叢集的保護避免產生過多的段影響效能,說白了就是段的合併跟不上寫入的速度,所以先來解決這個限流的問題,
由於組態檔沒有設定最大執行緒數和最大的合併執行緒數,所以這兩個值是用的是預設值
Spinning media has a harder time with concurrent I/O, so we need to decrease the number of threads that can concurrently access the disk per index. This setting will allow max_thread_count + 2 threads to operate on the disk at one time, so a setting of 1 will allow three threads. index.merge.scheduler.max_thread_count The maximum number of threads on a single shard that may be merging at once. Defaults to Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)) which works well for a good solid-state-disk (SSD). If your index is on spinning platter drives instead, decrease this to 1.
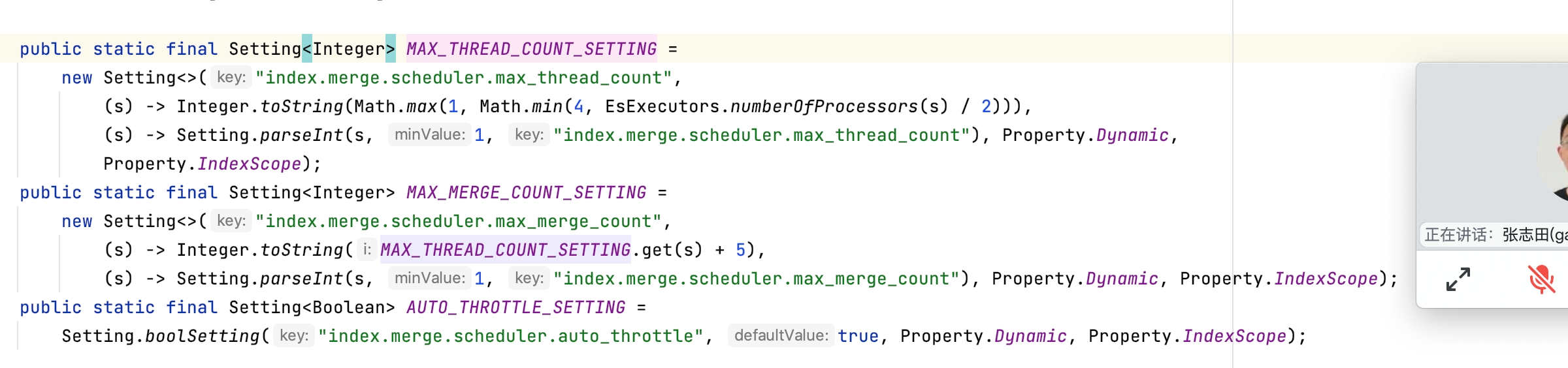
注意:在6.x版本之後已經取消了"indices.store.throttle.max_bytes_per_sec",所以現在只能通過調整max_thread_count,max_merge_count,預設max_thread_count最小是1最大是4,如果是機械盤推薦設1如果是ssD槽可以設成4或者更高,max_merge_count預設等於max_thread_count+5,也可以單獨設定
可以通過命令檢視預設的叢集引數設定:
GET _settings/?include_defaults
可以設定到組態檔當中,也可以通過以下命令針對索引進行動態設定:
PUT index_name/_settings { "index.merge.scheduler.max_thread_count": 4, "index.merge.scheduler.max_merge_count": 20 }
2.mlock
通過修改執行緒數之後,限流的問題解決了,但是應用的寫入rt耗時問題還是沒有得到解決 。通過對"hot_threads"進行分析發現主要的耗時還是在merge和index兩大塊,並且通過os層面的監控發現mlock的佔用記憶體一直在增長,啟動引陣列態檔設定在記憶體鎖定「bootstrap.memory_lock: true」不明白為什麼還會出現mlock的增長。
處理辦法:
將硬體設定降回到32C64G問題解決,增加一副本來提升查詢效能
4、總結
經過3天問題排查,網上也沒有找到類似的案例,網上更多的還是限流相關的案例,總結下來應該還是當前版本對於大記憶體的處理相關的bug,在7.x版本沒有出現類似的記憶體問題
|
備註: 作者:pursuer.chen 部落格:http://www.cnblogs.com/chenmh 本站點所有隨筆都是原創,歡迎大家轉載;但轉載時必須註明文章來源,且在文章開頭明顯處給明連結。 《歡迎交流討論》 |