以TrueType為例談字形描述
以TrueType為例談字形描述
作者:哲思
時間:2022.9.17
GitHub:zhe-si (哲思) (github.com)
一、前言
在深入理解「字元編碼模型」中,我們瞭解了字元完整的建模過程,但還留了一個懸念——如何從抽象字元轉換為我們視覺所看到的「字形」。
本文以 TrueType 字型為例,再和大家聊一聊如何描述字元的字形。
二、什麼是字形
「字形」故名思意,是字元的形體。字元本身是一種抽象的概念,代表了一種特定的符號。為了讓我們可以從視覺上感知這個抽象字元,需要將它以某種形體畫出來,這個形體就是「字形」。
字元與字形不是一對一的關係,而是多對多的關係。每個字元都可能有不同的寫法,比如漢字「山」有楷書、行書、草書、隸書等風格的字形,如下圖;l(小寫L)和I(大寫i)在很多風格的字形上十分接近(甚至相同)。

每種風格的字形,我們將它們整合在一起對某個抽象字元集進行描述,就是字型。
三、如何描述字形
字形的概念很容易理解,那麼該如何描述字形呢?
3.1 點陣
我們都知道,顯示屏其實是由許多小點組成的,小點越密集,就說解析度越高,圖案就越清晰。字元的字形在顯示屏上顯示,也要轉化為用無數個小點組成的描述形式,我們稱它為點陣。點陣用一個元素為0/1的方陣表述,字形所經過的地方用1表示,空白處用0表示,如下圖。

點陣描述字形的好處在於簡單直接,可以直接對映到顯示屏、印表機等裝置上列印出來而無需二次轉換(當然,還需要縮放、上色等步驟)。但該描述形式在不同解析度下只能對點陣的每一個點進行縮放,在更高的解析度下會出現模糊、失真等問題。同時,該描述所佔空間隨著解析度的增加呈幾何提升,描述效率較低。
3.2 曲線向量
為了更高效、準確的描述字形,人們提出了使用曲線向量對字形進行描述。曲線向量本身描述了字形的輪廓,基於向量的某種規則(如:順時針填充,逆時針為空)描述填充範圍。
曲線向量一般採用數學方程(樣條函數曲線)進行描述,如:Type1 使用三次貝塞爾曲線來描述字形,TrueType 使用二次貝塞爾曲線描述。
眾所周知,兩點確定一條直線。而在兩點之間新增一個曲線外點即可描述一條拋物曲線,曲線上的兩點為曲線的終點,曲線外點為控制點,三點共同控制曲線的形狀。
上述曲線中,比較有代表性的是二次貝塞爾曲線,形式如下圖。
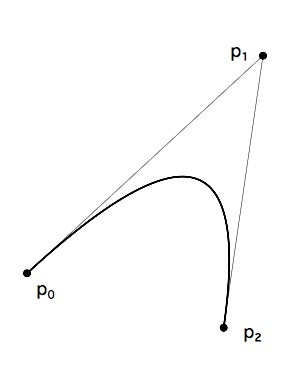
該曲線定義如下:給定三個點 p0、p1、p2,它們定義了從點 p0 到點 p2 的曲線,其中 p1 是曲線外點,位於曲線在 p0 的切線與曲線在 p2 的切線的交點處。也就是說,直線 p0p1 相切曲線於 p0,直線 p2p1 相切曲線於 p2。該曲線從 p0 到 p2 的引數方程如下:
多條相連的二次貝塞爾曲線可以表示更復雜的曲線。當兩條曲線在連線點一階連續(兩曲線連線點的切線共線)時,如下圖,
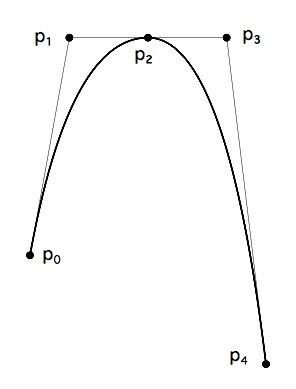
可以去除點 p2 來簡化對曲線的描述,並在需要的時候根據其他點的資訊對 p2 點進行重建。
通過組合曲線和直線,形成閉合曲線,即可描述複雜字形的輪廓,如下圖所示:
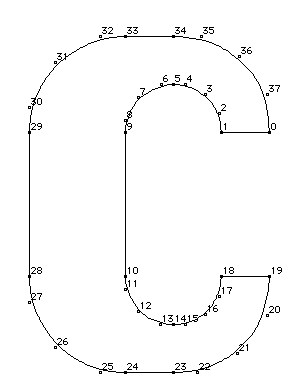
其中,黑色小圓點表示在曲線上的點,空心圓圈表示曲線外點。
但光是這樣就可以描述所有的字形了嗎?比如下圖使用曲線描述字元「B」的情況,
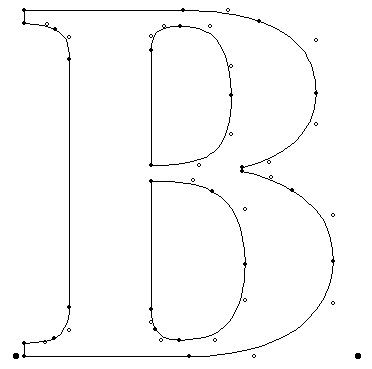
相信機制的小夥伴已經發現,在外輪廓內部還存在內輪廓。由於在字形「C」中只有單一的一個閉合圖形,所以填充範圍比較明確,讓我們忽略了填充的問題。但在存在多層輪廓的字形中,基於這些封閉圖形的輪廓,需要考慮哪部分需要填充、哪部分需要空白。
設計字形描述的前輩自然考慮到了這個問題,所以我們從一開始就說我們使用向量描述的輪廓,也就是說輪廓存在方向性,有起點和終點。基於該方向性即可定義規則確定填充範圍,比如:順時針填充/逆時針空白、非零繞組數規則等。
當然,即使採用曲線向量描述字形,在顯示屏或印表機將字形渲染出來時,也要轉化為點陣描述,但總是可以根據實際解析度以最佳清晰度展示。
四、字形描述的典範——TrueType
到這裡,我們已經對字形的描述有了整體的認識。接下來,我們以 TrueType 為例來看看字形描述的具體實現方式。
4.1 TrueType簡介
TrueType 是 Apple 公司開發的輪廓字型標準,以為字型開發人員提供高度控制,可在不同字型大小下正確顯示著稱。現已成為 mac os、windows 等作業系統上最常見的字型格式。一般的檔案拓展名為「.ttf」。
為了提高不同字型間相同字形的複用率,拓展 TrueType 字型格式,將多種字型組合到一個檔案中,稱為 TrueType Collection,常見的拓展名為「.ttc」。
4.2 TrueType的基本格式
TrueType 字型標準採用二進位制資料描述,內部分成多個表格來描述不同種類的資料。這裡的表格,類似一個個物件,在表格的第一個欄位說明自身的資料種類,每種資料都有著對應的欄位內容和順序。在讀取時,先確定表格對應哪個種類,在按照該種類表格的資料格式進行讀取。
TrueType 的第一個表格是字型目錄,一個特殊的表,在載入字型時首先被讀取(可能部分讀取),進而基於該目錄存取其他的表格。字型目錄分為兩部分:Offset Subtable 和 Table Directory。
第一部分 Offset Subtable 的格式如下,
| 型別 | 名稱 | 描述 |
|---|---|---|
| uint32 | scaler type | 指示用於光柵化此字型的 OFA 縮放器的標籤 |
| uint16 | numTables | 當前字型的表格數(除字型目錄) |
| uint16 | searchRange | (maximum power of 2 <= numTables)*16 |
| uint16 | entrySelector | log2(maximum power of 2 <= numTables) |
| uint16 | rangeShift | numTables*16-searchRange |
- scaler type 為 0x74727565(「true」,在蘋果的系統)或者0x00010000(在 Windows 系統或者 Adobe 產品)都表示 TTF 格式。
- 我們基於 numTables 進而讀取對應數目 Table Directory 的資料。
- 後三個欄位用於使用二分搜尋提高搜尋 Table Directory 速度。
緊跟著 Offset Subtable 是 Table Directory,有 numTables 個目錄項,分別對應字型中除字型目錄外的每個表格,同時根據標籤採用升序排序,方便二分快速搜尋。每個表項格式如下,
| Type | Name | Description |
|---|---|---|
| uint32 | tag | 4 位元組的表型別識別符號 |
| uint32 | checkSum | 該表的校驗和 |
| uint32 | offset | 該表在檔案中的偏移量 |
| uint32 | length | 該表的長度 |
TTF 格式要求,必須要在字型的正文存在以下 9 種表格,來描述 TTF 字型所必須的資訊:
| 標籤 | 標籤名稱 | 描述 |
|---|---|---|
'cmap' |
字元到字形對映 | 將字元程式碼對映到字形索引。特定字型的編碼取決於預期平臺使用的約定。若要在不同編碼約定的平臺執行字型,需要多個編碼表,每一種編碼約定對應一個「cmap」子表。 |
'head' |
字型頭 | 包含有關字型的全域性資訊。它記錄了字型版本號、建立和修改日期、修訂號和適用於整個字型的基本排版資料等以及驗證字型資料完整性的校驗和。 |
'hhea' |
水平佈局頭 | 包含佈局其字元水平書寫的字型所需的資訊,如:從左到右或從右到左、基於基線上升/下降、傾斜等。 |
'hmtx' |
水平度量 | 包含字型中每個字形的水平佈局的度量資訊。 |
'glyf' |
字形資料 | 描述每個字形外觀,包括構成字形輪廓的點以及該字形對應的指令。支援簡單字形和複合字形。 |
'loca' |
位置索引 | 儲存每個字形相對於「glyf」表起始的偏移位置,來提供對特定字形資料的快速隨機存取。字形資料的長度可通過下一個字形的偏移計算得到。 |
'maxp' |
最大指標 | 確定了字型的記憶體要求。它以表版本號開頭,描述了字形的數量和許多引數的最大限制。 |
'name' |
命名 | 包含人類可讀的功能和設定名稱、版權宣告、字型名稱、樣式名稱以及其他字型相關的資訊。 |
'post' |
PostScript | 包含在 PostScript 印表機上使用 TrueType 字型所需的資訊。 |
4.3 從抽象字元到字形
瞭解了 TrueType 的基本格式,我們來進一步研究 TrueType 是如何實現抽象字元到字形的對映的。
從抽象字元到字形的對映要解決兩個主要問題:字元碼位到字形索引的對映、字形的描述。
4.3.1 字元碼位到字形索引對映
邏輯上我們是在抽象字元的基礎上描述字形,但由於計算機使用數位描述字元,所以實際採用字元的編碼(碼位)來代指字元。由於在字型檔案中我們不總是要描述所用字元集中所有的字元,同時針對不同字元集的編碼順序也不盡相同,為了解耦字元編碼與字形索引,字形索引要單獨編碼,所以字型檔案首先要描述字元碼位到字形索引的對映關係。
TTF 使用 「cmap」 表格描述這種對映關係。由於一個字元檔案需要適配多種字元編碼方式,所以會包含多個編碼子表分別描述這些字元編碼到字形索引的對映。「cmap」 以表的版本號開頭,後跟編碼子表的數量,如下:
| 型別 | 名稱 | 描述 |
|---|---|---|
| UInt16 | version | 版本號(設定為零) |
| UInt16 | numberSubtables | 編碼子表數 |
接下來是按照平臺識別符號和平臺內的編碼識別符號升序排序的編碼子表(平臺識別符號和平臺內編碼識別符號共同描述了一種編碼方式),如下:
| 型別 | 名稱 | 描述 |
|---|---|---|
| UInt16 | platformID | 平臺識別符號,對應 Unicode、Windows等 |
| UInt16 | platformSpecificID | 特定於平臺的編碼識別符號,如在 Unicode 下的各個版本 |
| UInt32 | offset | 實際對映表的偏移量 |
目前「cmap」的字元編碼到字形索引的對映表有九種可用的格式,分別對應不同場景下的對映描述,這裡介紹一種比較有代表性的格式:format 4。
format 4
一種兩位元組編碼格式。用於字型包含的字元碼位落在幾個連續的範圍內的場景,來最大程度壓縮多個連續的區間。
具體格式如下:
| Type | Name | Description |
|---|---|---|
| UInt16 | format | 格式編號設定為 4 |
| UInt16 | length | 子表的長度(以位元組為單位) |
| UInt16 | language | 語言程式碼 |
| UInt16 | segCountX2 | 2 * segCount(段數) |
| UInt16 | searchRange | 2 * (2**FLOOR(log2(segCount))) |
| UInt16 | entrySelector | log2(searchRange/2) |
| UInt16 | rangeShift | (2 * segCount) - searchRange |
| UInt16 | endCode[segCount] | 每個段的結束字元程式碼,last = 0xFFFF |
| UInt16 | reservedPad | 此值應為零 |
| UInt16 | startCode[segCount] | 每個段的起始字元程式碼 |
| UInt16 | idDelta[segCount] | 段中所有字元程式碼到字形索引的增量 |
| UInt16 | idRangeOffset[segCount] | glyphIndexArray 的下標偏移量,或 0(一般為0,表示不使用 glyphIndexArray) |
| UInt16 | glyphIndexArray[variable] | 字形索引陣列 |
該格式描述了 segCount 個分段的字元編碼到字形索引的對映。核心描述欄位為:
- endCode[segCount]:字元編碼分段的結束碼位
- startCode[segCount]:字元編碼分段的開始碼位
- idDelta[segCount]:字元編碼到字形索引的增量
因此,根據分段的開始和結束碼位確定分段,則:該段某字元的字形索引 = 字元碼位 + idDelta。
以官方的例子進行說明:
| Name | Segment 1 Chars 10-20 | Segment 2 Chars 30-90 | Segment 3 Chars 100-153 | Segment 4 Missing Glyph |
|---|---|---|---|---|
| endCode | 20 | 90 | 153 | 0xFFFF |
| startCode | 10 | 30 | 100 | 0xFFFF |
| idDelta | -9 | -18 | -27 | 1 |
| idRangeOffset | 0 | 0 | 0 | 0 |
-
找碼位為12的字形索引
12 在 [10, 20] 區間內,偏移為 -9,所以:字形索引 = 12 - 9
-
字元碼位 [30, 90] 區間 --對映到-> 字形索引 [12, 72] 區間
12 = 30 - 18
72 = 90 - 18
4.3.2 字形描述
第二個問題就是字形的描述。TTF 採用上文介紹的二次貝塞爾曲線向量描述字形,同時輔助字形調整指令來完善字形的最終展示。
TTF 使用 「glyf」 表格來描述某個字元的字形。我們通過字元編碼在 「cmap」 表格查詢到了對應字形的索引,通過字形索引進一步在 「loca」 字形索引表格查詢,可以得到該字形對應的 「glyf」 字形描述表格的起始偏移位置和表格長度,讀取該 「glyf」 表得到對應字形的描述。
以下是簡單和複合字形通用的 「glyf」 表資料定義。
| 型別 | 名稱 | 描述 |
|---|---|---|
| int16 | numberOfContours | 如果輪廓數為正數或零,則為單個字形; 如果輪廓數小於零,則字形為複合字形 |
| FWord | xMin | 座標資料的最小 x |
| FWord | yMin | 座標資料的最小 y |
| FWord | xMax | 座標資料的最大 x |
| FWord | yMax | 座標資料的最大 y |
以下是簡單字形的資料定義,主要通過 xCoordinates、yCoordinates、endPtsOfContours 和 flags 確定字形的每個輪廓已經向量方向,然後通過 instructionLength、instructions 描述的指令調整字形的最終顯示。
| 型別 | 名稱 | 描述 |
|---|---|---|
| uint16 | endPtsOfContours[n] | 每個輪廓的最後一個點的陣列;n 是輪廓的數量;陣列項是每個點的索引 |
| uint16 | instructionLength | 指令所需的總位元組數 |
| uint8 | instructions[instructionLength] | 此字形的指令陣列 |
| uint8 | flags[variable] | 標誌陣列,描述是否在曲線上、是否重複等情況 |
| uint8 或 int16 | xCoordinates[] | x 座標陣列;第一個是相對於(0,0),其他是相對於前一點 |
| uint8 或 int16 | yCoordinates[] | y 座標陣列;第一個是相對於(0,0),其他是相對於前一點 |
複雜字形的描述暫不討論。
4.3.3 小結
深入理解「字元編碼模型」中,我們完成了對抽象字元的建模,可以在抽象字元到計算機底層儲存間相互對映。而 TrueType 等字型則是在抽象字元的基礎上向上建模,描述字元如何轉化為人類視覺理解上的字形圖案。至此,我們已經明白了從人類直觀看到的字元到計算機底層對字元描述的完整建模鏈路,如下圖,
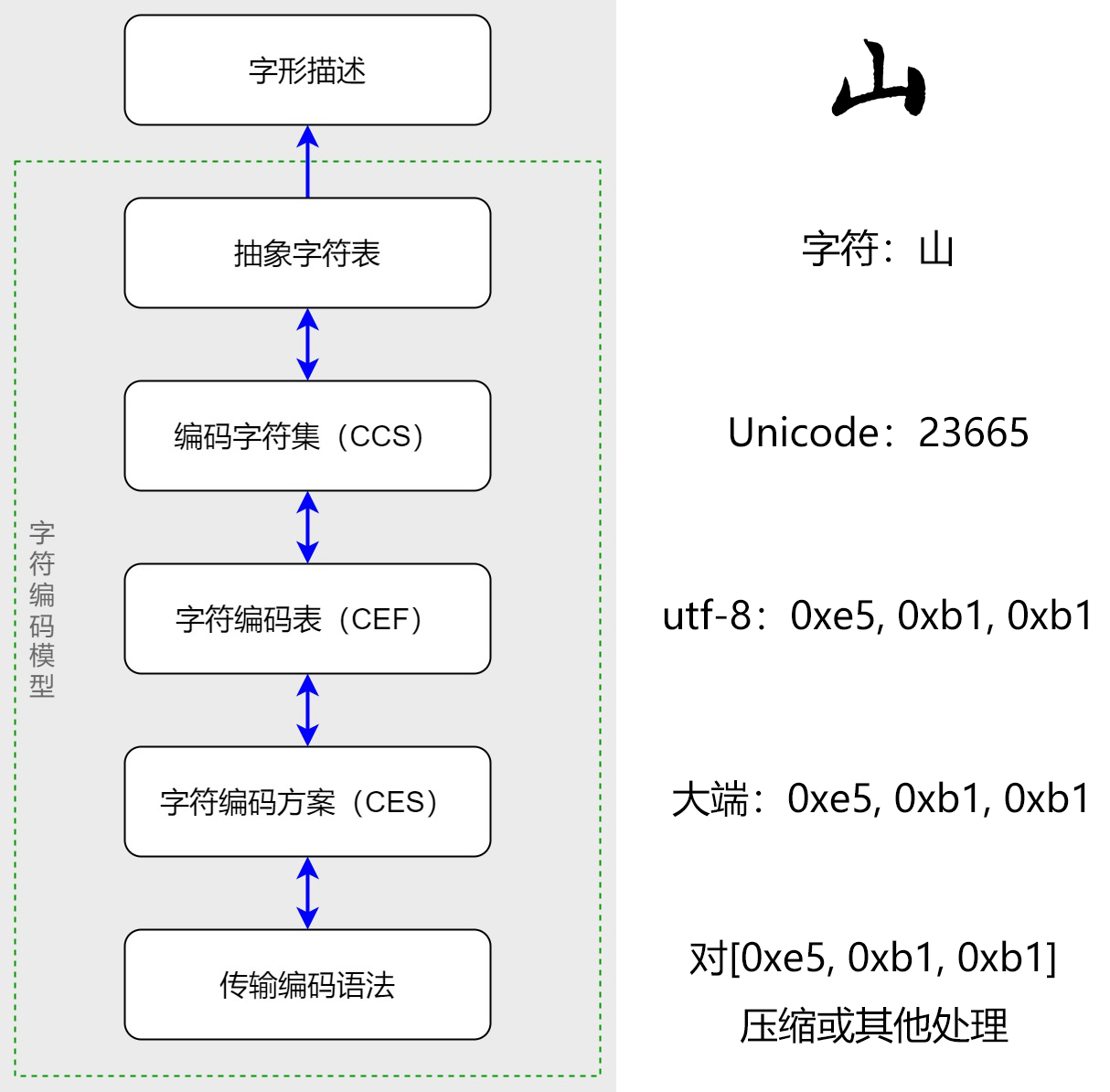
細心的小夥伴會發現,從「抽象字元表」到「字形描述」是單向轉換,這是因為字元與字形間是多對多關係,字元到字形的對映是在字型中明確定義的,但從字形到字元的對映需要一種對字形的「理解」,無法直接簡單根據字形對映到字元。而仿照人的思維對圖案進行處理,就涉及到一個非常熱門的領域——人工智慧(計算機視覺),屬於文字識別(OCR)任務。
五、後記
終於把深入理解「字元編碼模型」留的坑給填上了。經過本次學習和總結,對字元這個概念有了系統的認識,也為電子檔案的學習打下了堅實的基礎。
有個小夥伴問我,為啥要研究字元建模的這些東西?可能是想下次做檔案生成時更得心應手,可能是想舉一反三學習計算機建模的思想,也可能只是對這些觸手可及的東西到底是怎麼實現的一點點好奇心罷了。
本文來自部落格園,作者:_哲思,轉載請註明原文連結:https://www.cnblogs.com/zhe-si/p/16712194.html