爬蟲與反爬蟲技術簡介
vivo 網際網路安全團隊- Xie Peng
網際網路的巨量資料時代的來臨,網路爬蟲也成了網際網路中一個重要行業,它是一種自動獲取網頁資料資訊的爬蟲程式,是網站搜尋引擎的重要組成部分。通過爬蟲,可以獲取自己想要的相關資料資訊,讓爬蟲協助自己的工作,進而降低成本,提高業務成功率和提高業務效率。
本文一方面從爬蟲與反反爬的角度來說明如何高效的對網路上的公開資料進行爬取,另一方面也會介紹反爬蟲的技術手段,為防止外部爬蟲大批次的採集資料的過程對伺服器造成超負載方面提供些許建議。
爬蟲指的是按照一定規則自動抓取全球資訊網資訊的程式,本次主要會從爬蟲的技術原理與實現,反爬蟲與反反爬蟲兩個方面進行簡單的介紹,介紹的案例均只是用於安全研究和學習,並不會進行大量爬蟲或者應用於商業。
一、爬蟲的技術原理與實現
1.1 爬蟲的定義
爬蟲分為通用爬蟲和聚焦爬蟲兩大類,前者的目標是在保持一定內容質量的情況下爬取儘可能多的站點,比如百度這樣的搜尋引擎就是這種型別的爬蟲,如圖1是通用搜尋引擎的基礎架構:
-
首先在網際網路中選出一部分網頁,以這些網頁的連結地址作為種子URL;
-
將這些種子URL放入待抓取的URL佇列中,爬蟲從待抓取的URL佇列依次讀取;
-
將URL通過DNS解析,把連結地址轉換為網站伺服器對應的IP地址;
-
網頁下載器通過網站伺服器對網頁進行下載,下載的網頁為網頁檔案形式;
-
對網頁檔案中的URL進行抽取,並過濾掉已經抓取的URL;
-
對未進行抓取的URL繼續迴圈抓取,直至待抓取URL佇列為空。
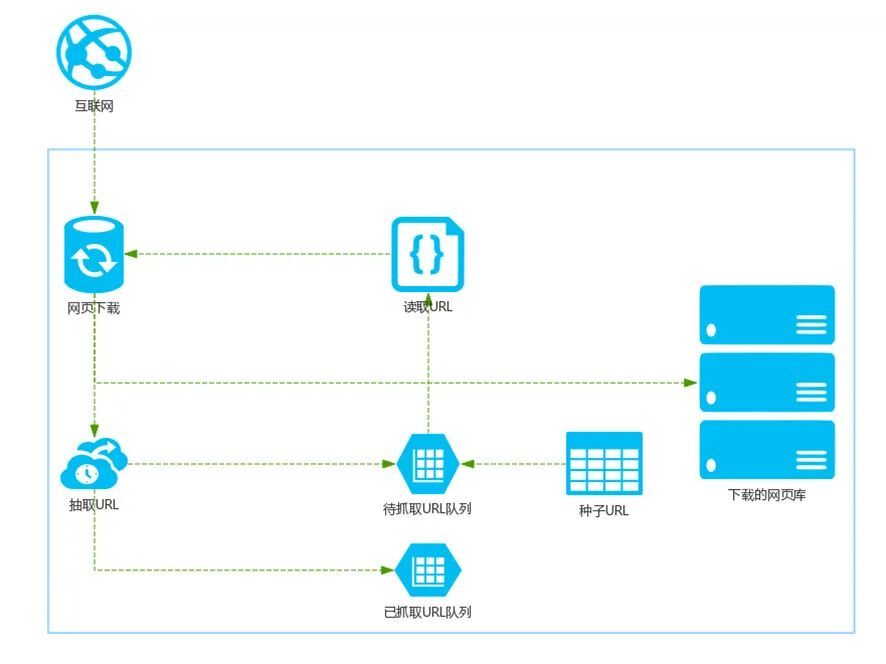 圖1.通用搜尋引擎的基礎架構
圖1.通用搜尋引擎的基礎架構
爬蟲通常從一個或多個 URL 開始,在爬取的過程中不斷將新的並且符合要求的 URL 放入待爬佇列,直到滿足程式的停止條件。
而我們日常見到的爬蟲基本為後者,目標是在爬取少量站點的情況下儘可能保持精準的內容質量。典型的比如圖2搶票軟體所示,就是利用爬蟲來登入售票網路並爬取資訊,從而輔助商業。

瞭解了爬蟲的定義後,那麼應該如何編寫爬蟲程式來爬取我們想要的資料呢。我們可以先了解下目前常用的爬蟲框架,因為它可以將一些常見爬蟲功能的實現程式碼寫好,然後留下一些介面,在做不同的爬蟲專案時,我們只需要根據實際情況,手寫少量需要變動的程式碼部分,並按照需要呼叫這些介面,即可以實現一個爬蟲專案。
1.2 爬蟲框架介紹
常用的搜尋引擎爬蟲框架如圖3所示,首先Nutch是專門為搜尋引擎設計的爬蟲,不適合用於精確爬蟲。Pyspider和Scrapy都是python語言編寫的爬蟲框架,都支援分散式爬蟲。另外Pyspider由於其視覺化的操作介面,相比Scrapy全命令列的操作對使用者更加友好,但是功能不如Scrapy強大。
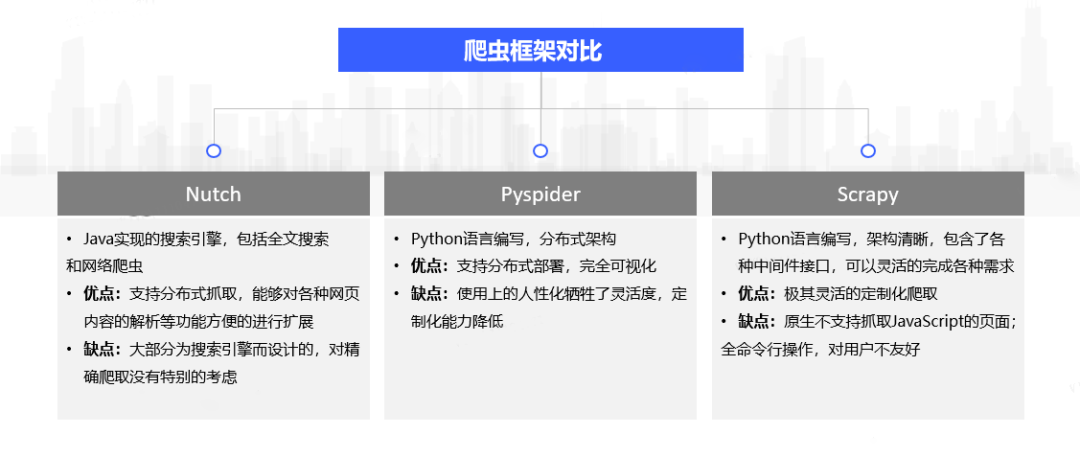
圖3.爬蟲框架對比
1.3 爬蟲的簡單範例
除了使用爬蟲框架來進行爬蟲,也可以從頭開始來編寫爬蟲程式,步驟如圖4所示:
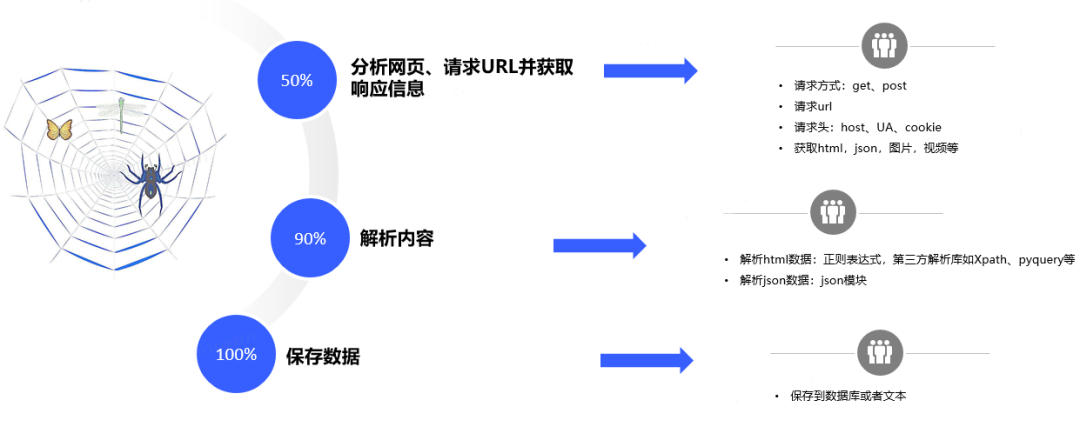
圖4.爬蟲的基本原理
接下來通過一個簡單的例子來實際演示上述的步驟,我們要爬取的是某應用市場的榜單,以這個作為例子,是因為這個網站沒有任何的反爬蟲手段,我們通過上面的步驟可以輕鬆爬取到內容。


網頁與其對應的原始碼如圖5所示,對於網頁上的資料,假定我們想要爬取排行榜上每個app的名稱以及其分類。
我們首先分析網頁原始碼,發現可以直接在網頁原始碼中搜尋到「抖音」等app的名稱,接著看到app名稱、app類別等都是在一個<li>標籤裡,所以我們只需要請求網頁地址,拿到返回的網頁原始碼,然後對網頁原始碼進行正則匹配,提取出想要的資料,儲存下來即可,如圖6所示。
#獲取網頁原始碼 def get_one_page(url): try: response = requests.get(url) if response.status_code == 200: return response.text return None except RequestException: return None #正則匹配提取目標資訊並形成字典 def parse_one_page(html): pattern = re.compile('<li>.*?data-src="(.*?)".*?<h5>.*?det.*?>(.*?)</a>.*?p.*?<a.*?>(.*?)</a>.*?</li>',re.S) items = re.findall(pattern, html) j = 1 for item in items[:-1]: yield {'index': str(j), 'name': item[1], 'class':item[2] } j = j+1 #結果寫入txt def write_to_file(content): with open(r'test.txt', 'a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False)+'\n')

圖6.爬蟲的程式碼以及結果
二、反爬蟲相關技術
在瞭解具體的反爬蟲措施之前,我們先介紹下反爬蟲的定義和意義,限制爬蟲程式存取伺服器資源和獲取資料的行為稱為反爬蟲。爬蟲程式的存取速率和目的與正常使用者的存取速率和目的是不同的,大部分爬蟲會無節制地對目標應用進行爬取,這給目標應用的伺服器帶來巨大的壓力。爬蟲程式發出的網路請求被運營者稱為「垃圾流量」。開發者為了保證伺服器的正常運轉或降低伺服器的壓力與運營成本,不得不使出各種各樣的技術手段來限制爬蟲對伺服器資源的存取。
所以為什麼要做反爬蟲,答案是顯然的,爬蟲流量會提升伺服器的負載,過大的爬蟲流量會影響到服務的正常運轉,從而造成收入損失,另一方面,一些核心資料的外洩,會使資料擁有者失去競爭力。
常見的反爬蟲手段,如圖7所示。主要包含文字混淆、頁面動態渲染、驗證碼校驗、請求籤名校驗、巨量資料風控、js混淆和蜜罐等,其中文字混淆包含css偏移、圖片偽裝文字、自定義字型等,而風控策略的制定則往往是從引數校驗、行為頻率和模式異常等方面出發的。

圖7.常見的反爬蟲手段
2.1 CSS偏移反爬蟲
在搭建網頁的時候,需要用CSS來控制各類字元的位置,也正是如此,可以利用CSS來將瀏覽器中顯示的文字,在HTML中以亂序的方式儲存,從而來限制爬蟲。CSS偏移反爬蟲,就是一種利用CSS樣式將亂序的文字排版成人類正常閱讀順序的反爬蟲手段。這個概念不是很好理解,我們可以通過對比兩段文字來加深對這個概念的理解:
-
HTML 文字中的文字:我的學號是 1308205,我在北京大學讀書。
-
瀏覽器顯示的文字:我的學號是 1380205,我在北京大學讀書。
以上兩段文字中瀏覽器顯示的應該是正確的資訊,如果我們按之前提到的爬蟲步驟,分析網頁後正則提取資訊,會發現學號是錯的。
接著看圖8所示的例子,如果我們想爬取該網頁上的機票資訊,首先需要分析網頁。紅框所示的價格467對應的是中國民航的從石家莊到上海的機票,但是分析網頁原始碼發現程式碼中有 3 對 b 標籤,第 1 對 b 標籤中包含 3 對 i 標籤,i 標籤中的數位都是 7,也就是說第 1 對 b 標籤的顯示結果應該是 777。而第 2 對 b 標籤中的數位是 6,第 3 對 b 標籤中的數位是 4,這樣的話我們會無法直接通過正則匹配得到正確的機票價格。
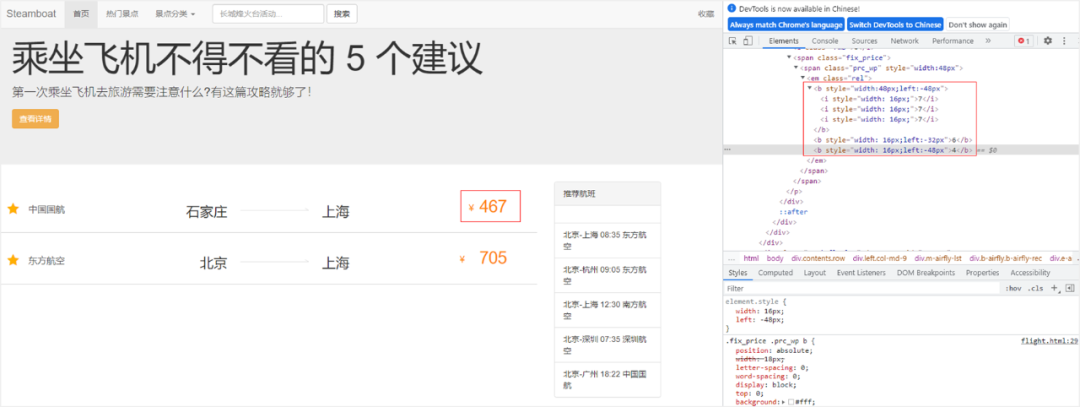
圖8.CSS 偏移反爬蟲例子
2.2 圖片偽裝反爬蟲
圖片偽裝反爬蟲,它的本質就是用圖片替換了原來的內容,從而讓爬蟲程式無法正常獲取,如圖9所示。這種反爬蟲的原理十分簡單,就是將本應是普通文字內容的部分在前端頁面中用圖片來進行替換,遇到這種案例可以直接用ocr識別圖片中的文字就可以繞過。而且因為是用圖片替換文字顯示,所以圖片本身會相對比較清晰,沒有很多噪聲干擾,ocr識別的結果會很準確。
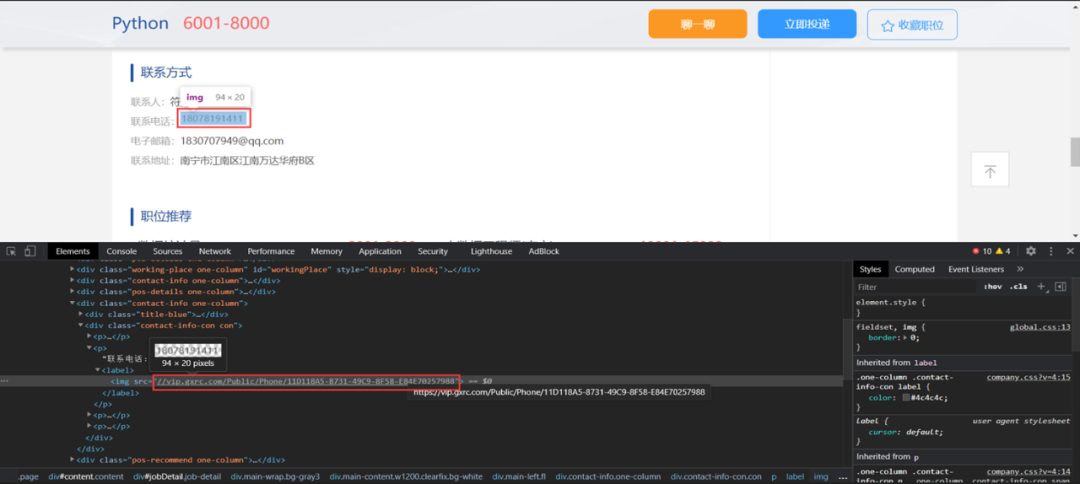
圖9. 圖片偽裝反爬蟲例子
2.3 自定義字型反爬蟲
在 CSS3 時代,開發者可以使用@font-face為網頁指定字型。開發者可將心儀的字型檔案放在 Web 伺服器上,並在 CSS 樣式中使用它。使用者使用瀏覽器存取 Web 應用時,對應的字型會被瀏覽器下載到使用者的計算機上,但是我們在使用爬蟲程式時,由於沒有相應的字型對映關係,直接爬取就會無法得到有效資料。
如圖10所示,該網頁中每個店鋪的評價數、人均、口味、環境等資訊均是亂碼字元,爬蟲無法直接讀取到內容。
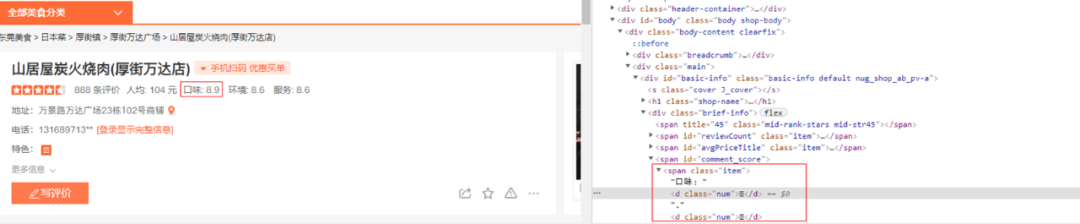
圖10. 自定義字型反爬蟲例子
2.4 頁面動態渲染反爬蟲
網頁按渲染方式的不同,大體可以分為使用者端和伺服器端渲染。
-
伺服器端渲染,頁面的結果是由伺服器渲染後返回的,有效資訊包含在請求的 HTML 頁面裡面,通過檢視網頁原始碼可以直接檢視到資料等資訊;
-
使用者端渲染,頁面的主要內容由 JavaScript 渲染而成,真實的資料是通過 Ajax 介面等形式獲取的,通過檢視網頁原始碼,無有效資料資訊。
使用者端渲染和伺服器端渲染的最重要的區別就是究竟是誰來完成html檔案的完整拼接,如果是在伺服器端完成的,然後返回給使用者端,就是伺服器端渲染,而如果是前端做了更多的工作完成了html的拼接,則就是使用者端渲染。
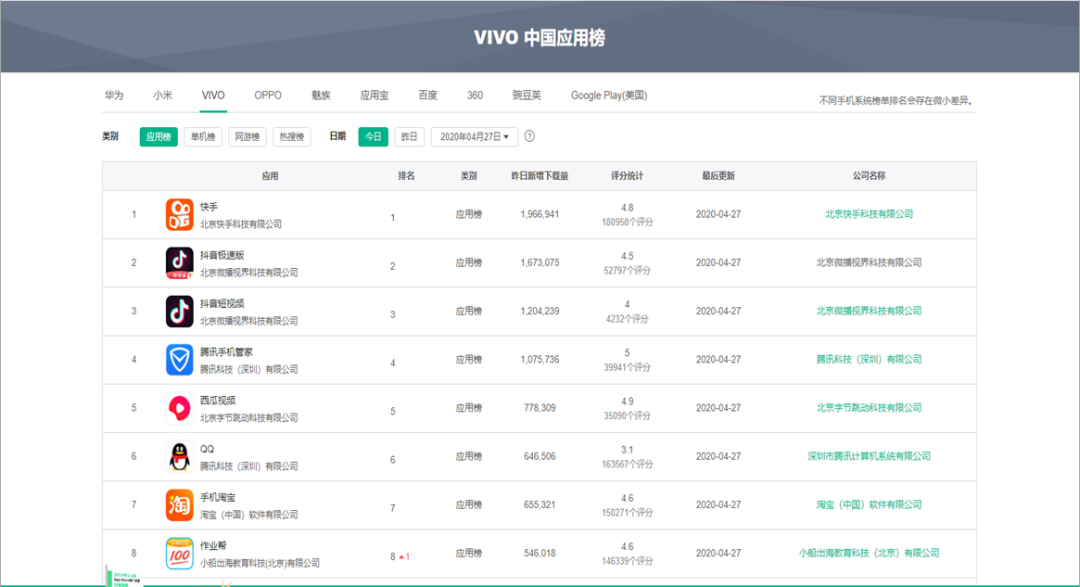
圖11.使用者端渲染例子
2.5 驗證碼反爬蟲
幾乎所有的應用程式在涉及到使用者資訊保安的操作時,都會彈出驗證碼讓使用者進行識別,以確保該操作為人類行為,而不是大規模執行的機器。那為什麼會出現驗證碼呢?在大多數情形下是因為網站的存取頻率過高或者行為異常,或者是為了直接限制某些自動化行為。歸類如下:
-
很多情況下,比如登入和註冊,這些驗證碼幾乎是必現的,它的目的就是為了限制惡意註冊、惡意爆破等行為,這也算反爬的一種手段。
-
一些網站遇到存取頻率過高的行為的時候,可能會直接彈出一個登入視窗,要求我們登入才能繼續存取,此時的驗證碼就直接和登入表單繫結在一起了,這就算檢測到異常之後利用強制登入的方式進行反爬。
-
一些較為常規的網站如果遇到存取頻率稍高的情形的時候,會主動彈出一個驗證碼讓使用者識別並提交,驗證當前存取網站的是不是真實的人,用來限制一些機器的行為,實現反爬蟲。
常見的驗證碼形式包括圖形驗證碼、行為驗證碼、簡訊、掃碼驗證碼等,如圖12所示。對於能否成功通過驗證碼,除了能夠準確的根據驗證碼的要求完成相應的點選、選擇、輸入等,通過驗證碼風控也至關重要;比如對於滾軸驗證碼,驗證碼風控可能會針對滑動軌跡進行檢測,如果檢測出軌跡非人為,就會判定為高風險,導致無法成功通過。
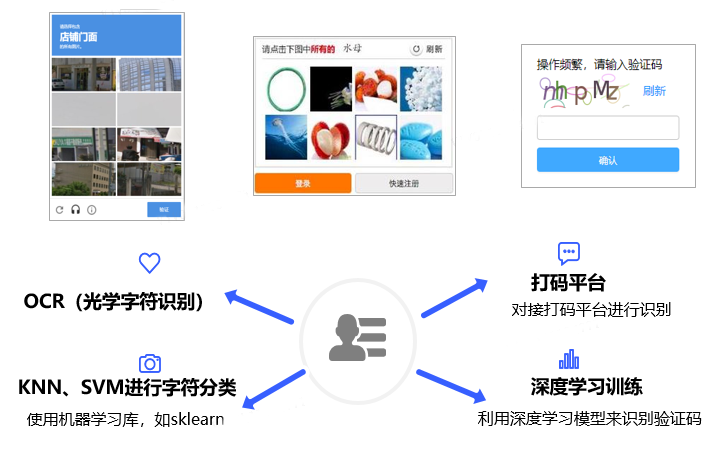
圖12.驗證碼反爬蟲手段
2.6 請求籤名校驗反爬蟲
簽名驗證是防止伺服器被惡意連結和篡改資料的有效方式之一,也是目前後端API最常用的防護方式之一。簽名是一個根據資料來源進行計算或者加密的過程,使用者經過簽名後會一個具有一致性和唯一性的字串,它就是你存取伺服器的身份象徵。由它的一致性和唯一性這兩種特性,從而可以有效的避免伺服器端,將偽造的資料或被篡改的資料當初正常資料處理。
前面在2.4節提到的網站是通過使用者端渲染網頁,資料則是通過ajax請求拿到的,這種在一定程度上提升了爬蟲的難度。接下來分析ajax請求,如圖13所示,會發現其ajax請求是帶有請求籤名的,analysis就是加密後的引數,而如果想要破解請求介面,就需要破解該引數的加密方法,這無疑進一步提升了難度。

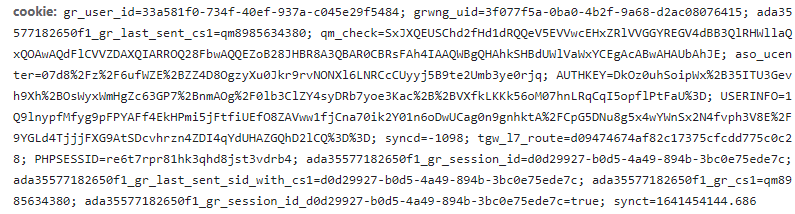
圖13. 請求榜單資料的ajax請求
2.7 蜜罐反爬蟲
蜜罐反爬蟲,是一種在網頁中隱藏用於檢測爬蟲程式的連結的手段,被隱藏的連結不會顯示在頁面中,正常使用者無法存取,但爬蟲程式有可能將該連結放入待爬佇列,並向該連結髮起請求,開發者可以利用這個特點區分正常使用者和爬蟲程式。如圖14所示,檢視網頁原始碼,頁面只有6個商品,col-md-3的 <div>標籤卻有 8 對。該 CSS 樣式的作用是隱藏標籤,所以我們在頁面只看到 6 件商品,爬蟲程式會提取到 8 件商品的 URL。
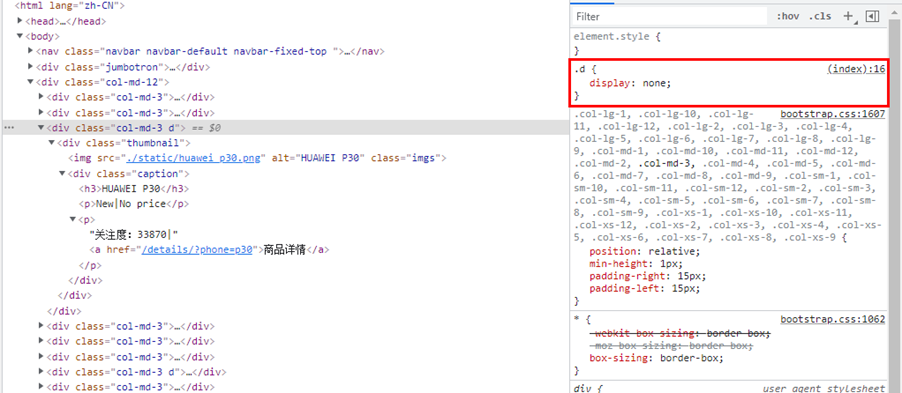
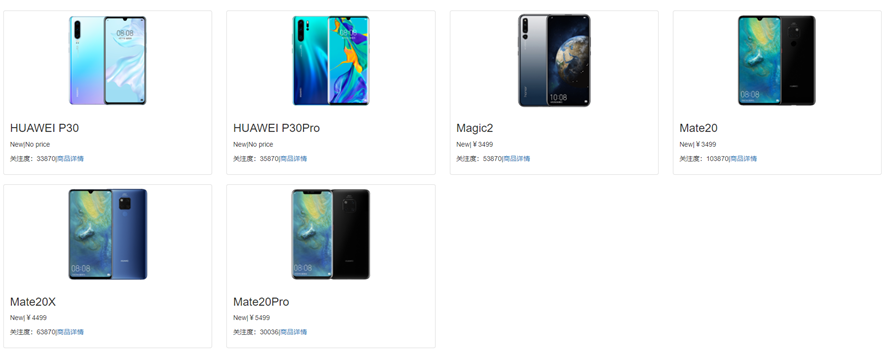
圖14.蜜罐反爬蟲例子
三、反反爬相關技術
針對上一節提到的反爬蟲相關技術,有以下幾類反反爬技術手段:css偏移反反爬、自定義字型反反爬、頁面動態渲染反反爬、驗證碼破解等,下面對這幾類方法進行詳細的介紹。
3.1 CSS偏移反反爬
3.1.1 CSS偏移邏輯介紹
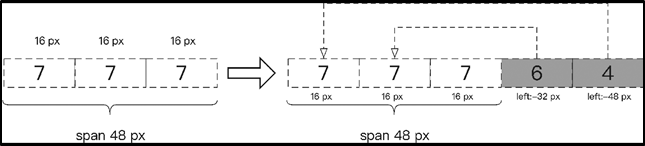
那麼對於以上2.1css偏移反爬蟲的例子,怎麼才能得到正確的機票價格呢。仔細觀察css樣式,可以發現每個帶有數位的標籤都設定了樣式,第 1 對 b 標籤內的i 標籤對的樣式是相同的,都是width: 16px;另外,還注意到最外層的 span 標籤對的樣式為width:48px。
如果按照 css樣式這條線索來分析的話,第 1 對 b 標籤中的 3 對 i 標籤剛好佔滿 span 標籤對的位置,其位置如圖15所示。此時網頁中顯示的價格應該是 777,但是由於第 2 和第 3 對 b 標籤中有值,所以我們還需要計算它們的位置。由於第 2 對 b 標籤的位置樣式是 left:-32px,所以第 2 對 b 標籤中的值 6 就會覆蓋原來第 1 對 b 標籤中的中的第 2 個數位 7,此時頁面應該顯示的數位是 767。
按此規律推算,第 3 對 b 標籤的位置樣式是 left:-48px,這個標籤的值會覆蓋第 1 對 b 標籤中的第 1 個數位 7,最後顯示的票價就是 467。
3.1.2 CSS偏移反反爬程式碼實現
因此接下來我們按以上css樣式的規律來編寫程式碼對該網頁爬取獲取正確的機票價格,程式碼和結果如圖16所示。
if __name__ == '__main__': url = 'http://www.porters.vip/confusion/flight.html' resp = requests.get(url) sel = Selector(resp.text) em = sel.css('em.rel').extract() for element in range(0,1): element = Selector(em[element]) element_b = element.css('b').extract() b1 = Selector(element_b.pop(0)) base_price = b1.css('i::text').extract() print('css偏移前的價格:',base_price) alternate_price = [] for eb in element_b: eb = Selector(eb) style = eb.css('b::attr("style")').get() position = ''.join(re.findall('left:(.*)px', style)) value = eb.css('b::text').get() alternate_price.append({'position': position, 'value': value}) print('css偏移值:',alternate_price) for al in alternate_price: position = int(al.get('position')) value = al.get('value') plus = True if position >= 0 else False index = int(position / 16) base_price[index] = value print('css偏移後的價格:',base_price)

3.2 自定義字型反反爬
針對於以上2.3自定義字型反爬蟲的情況,解決思路就是提取出網頁中自定義字型檔案(一般為WOFF檔案),並將對映關係包含到爬蟲程式碼中,就可以獲取到有效資料。解決的步驟如下:
發現問題:檢視網頁原始碼,發現關鍵字元被編碼替代,如

分析:檢查網頁,發現應用了css自定義字元集隱藏
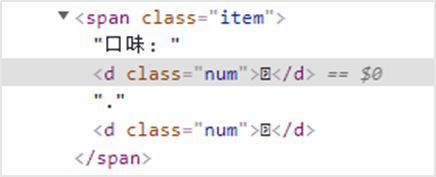
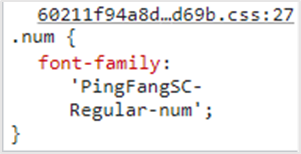
查詢:查詢css檔案url,獲取字元集對應的url,如PingFangSC-Regular-num
查詢:查詢和下載字元集url

比對:比對字元集中的字元與網頁原始碼中的編碼,發現編碼的後四位與字元對應,也即網頁原始碼對應的口味是8.9分

3.3 頁面動態渲染反反爬
使用者端渲染的反爬蟲,頁面程式碼在瀏覽器原始碼中看不到,需要執行渲染並進一步獲取渲染後結果。針對這種反爬蟲,有以下幾種方式破解:
-
在瀏覽器中,通過開發者工具直接檢視ajax具體的請求方式、引數等內容;
-
通過selenium模擬真人操作瀏覽器,獲取渲染後的結果,之後的操作步驟和伺服器端渲染的流程一樣;
-
如果渲染的資料隱藏在html結果的JS變數中,可以直接正則提取;
-
如果有通過JS生成的加密引數,可以找出加密部分的程式碼,然後使用pyexecJS來模擬執行JS,返回執行結果。
3.4 驗證碼破解
下面舉例一個識別滾軸驗證碼的例子,如圖17所示,是使用目標檢測模型來識別某滾軸驗證碼缺口位置的結果範例,這種破解滾軸驗證碼的方式對應的是模擬真人的方式。不採用介面破解的原因一方面是破解加密演演算法有難度,另一方面也是加密演演算法可能每天都會變,這樣破解的時間成本也比較大。

圖17. 通過目標檢測模型識別滾軸驗證碼的缺口
3.4.1 爬取滾軸驗證碼圖片
因為使用的目標檢測模型yolov5是有監督學習,所以需要爬取滾軸驗證碼的圖片並進行打標,進而輸入到模型中訓練。通過模擬真人的方式在某場景爬取部分驗證碼。

3.4.2 人工打標
本次使用的是labelImg來對圖片人工打標籤的,人工打標耗時較長,100張圖片一般耗時40分鐘左右。自動打標程式碼寫起來比較複雜,主要是需要分別提取出驗證碼的所有背景圖片和缺口圖片,然後隨機生成缺口位置,作為標籤,同時將缺口放到對應的缺口位置,生成圖片,作為輸入。

3.4.3 目標檢測模型yolov5
直接從github下clone yolov5的官方程式碼,它是基於pytorch實現。
接下來的使用步驟如下:
-
資料格式轉換:將人工標註的圖片和標籤檔案轉換為yolov5接收的資料格式,得到1100張圖片和1100個yolov5格式的標籤檔案;
-
新建資料集:新建custom.yaml檔案來建立自己的資料集,包括訓練集和驗證集的目錄、類別數目、類別名;
-
訓練調優:修改模型組態檔和訓練檔案後,進行訓練,並根據訓練結果調優超引數。
轉換xml檔案為yolov5格式的部分指令碼:
for member in root.findall('object'): class_id = class_text.index(member[0].text) xmin = int(member[4][0].text) ymin = int(member[4][1].text) xmax = int(member[4][2].text) ymax = int(member[4][3].text) # round(x, 6) 這裡我設定了6位有效數位,可根據實際情況更改 center_x = round(((xmin + xmax) / 2.0) * scale / float(image.shape[1]), 6) center_y = round(((ymin + ymax) / 2.0) * scale / float(image.shape[0]), 6) box_w = round(float(xmax - xmin) * scale / float(image.shape[1]), 6) box_h = round(float(ymax - ymin) * scale / float(image.shape[0]), 6) file_txt.write(str(class_id)) file_txt.write(' ') file_txt.write(str(center_x)) file_txt.write(' ') file_txt.write(str(center_y)) file_txt.write(' ') file_txt.write(str(box_w)) file_txt.write(' ') file_txt.write(str(box_h)) file_txt.write('\n') file_txt.close()
訓練引數設定:
parser = argparse.ArgumentParser() parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path') parser.add_argument('--cfg', type=str, default='./models/yolov5s.yaml', help='model.yaml path') parser.add_argument('--data', type=str, default='data/custom.yaml', help='data.yaml path') parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path') # parser.add_argument('--epochs', type=int, default=300) parser.add_argument('--epochs', type=int, default=50) # parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs') parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs') parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes') parser.add_argument('--rect', action='store_true', help='rectangular training') parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training') parser.add_argument('--nosave', action='store_true', help='only save final checkpoint') parser.add_argument('--notest', action='store_true', help='only test final epoch') parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check') parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters') parser.add_argument('--bucket', type=str, default='', help='gsutil bucket') parser.add_argument('--cache-images', action='store_true', help='cache images for faster training') parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training') parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%') parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class') parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer') parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode') parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify') parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers') parser.add_argument('--project', default='runs/train', help='save to project/name') parser.add_argument('--entity', default=None, help='W&B entity') parser.add_argument('--name', default='exp', help='save to project/name') parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') parser.add_argument('--quad', action='store_true', help='quad dataloader') parser.add_argument('--linear-lr', action='store_true', help='linear LR') parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon') parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table') parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B') parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch') parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used') opt = parser.parse_args()
3.4.4 目標檢測模型的訓練結果
模型基本在50次迭代的時候在precision和recall以及mAP上已經達到了瓶頸。預測結果也有如下問題:大部分能夠是能夠準確框出缺口,但也出現少量框錯、框出兩個缺口、框不出缺口的情況。
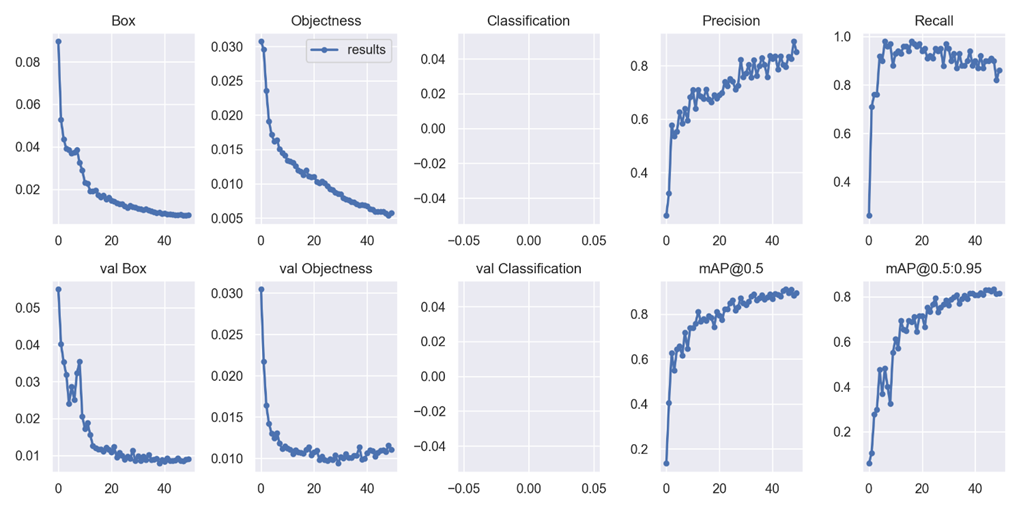

圖20. 上:模型的訓練結果走勢圖;下:模型對部分驗證集的預測結果
四、總結
本次簡單對爬蟲以及反爬蟲的技術手段進行了介紹,介紹的技術和案例均只是用於安全研究和學習,並不會進行大量爬蟲或者應用於商業。
對於爬蟲,本著爬取網路上公開資料用於資料分析等的目的,我們應該遵守網站robots協定,本著不影響網站正常執行以及遵守法律的情況下進行資料爬取;對於反爬蟲,因為只要人類能夠正常存取的網頁,爬蟲在具備同等資源的情況下就一定可以抓取到。所以反爬蟲的目的還是在於能夠防止爬蟲在大批次的採集網站資訊的過程對伺服器造成超負載,從而杜絕爬蟲行為妨礙到使用者的體驗,來提高使用者使用網站服務的滿意度。